 夜雨聆风
夜雨聆风





以OpenClaw为例,一次讲清Agent Skill
AGENT SKILL
2025年10月16号,Anthropic正式推出了Agent Skill。起初官方对它的定位相当克制,只是希望用它来提升Claude在某些特定任务上的表现。但大家很快发现这套设计实在是太好用了,因此行业里很快就跟上了节奏,包括VSCode、Codex、Cursor、OpenClaw等工具都陆续加入了对Agent Skill的支持。
在这样的背景下,12月18日Anthropic做出了一个重要决定,正式将Agent Skill发布为开放标准,支持跨平台、跨产品使用。这意味着Agent Skill已经超越了Claude单一产品的范畴,正在演变为AI Agent领域的一个通用的设计模式。

Agent Skill到底解决了什么核心痛点?它和MCP又有什么区别和联系?
今天这篇文章我就通过以OpenClaw为例,通过实际例子剖析OpenClaw彻底讲清楚Agent Skill。首先从概念出发,然后演示基本用法,接着深入高级用法(reference和script),最后把Skill和MCP做个比较。
什么是Agent Skill
最通俗的话来讲,Skill其实就是一个大模型可以随时翻阅的说明文档。
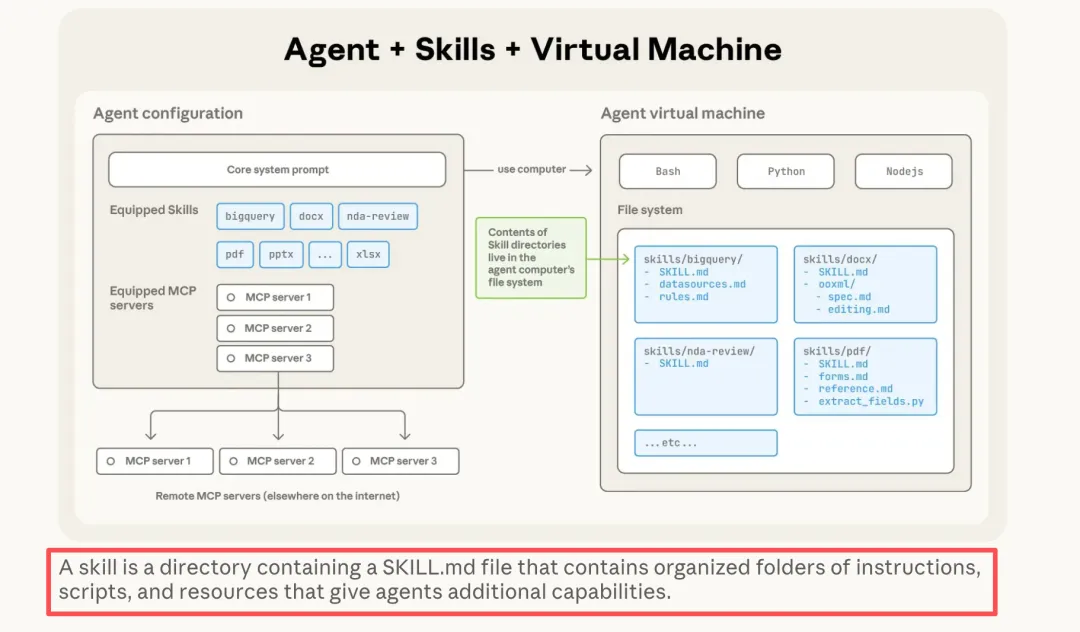
Anthropic官方针对skill的定义是:
skill是一个目录,包含一个 SKILL.md 文件,该文件中包含有序的文件夹,内含说明、脚本和资源,可为agent提供额外功能。
举个例子,假设你想要做简历诊断,你添加了一个简历诊断.md的skill,你可以在Skill里面交代:遇到简历先检查简历内容的完整性,再看关键词匹配度,最后按百分制评分输出改进清单。再比如你想要做会议总结,你添加了一个会议总结.md的skill,你可以直接在Skill里面规定:必须要按照”参会人员、议题、决定”这个格式来输出总结内容。
这样一来你就不用每次对话都去重复粘贴那一长串的要求了,大模型自己翻这个说明文档就知道该怎么干活了。
基础用法:按需加载
下面我用实际场景带大家看看Skill到底是怎么使用的。这里我们使用OpenClaw来演示。
首先在 ~/.openclaw/skills/ 目录下创建一个文件夹,名字为resume-reviewer,就是Skill的名称。然后再放一个 SKILL.md 文件。
这个skill的作用是个简历诊断工具
下面我用”resume-reviewer“(简历诊断),这个实际场景带大家看看Skill到底是怎么使用的。这里我们使用OpenClaw来演示:
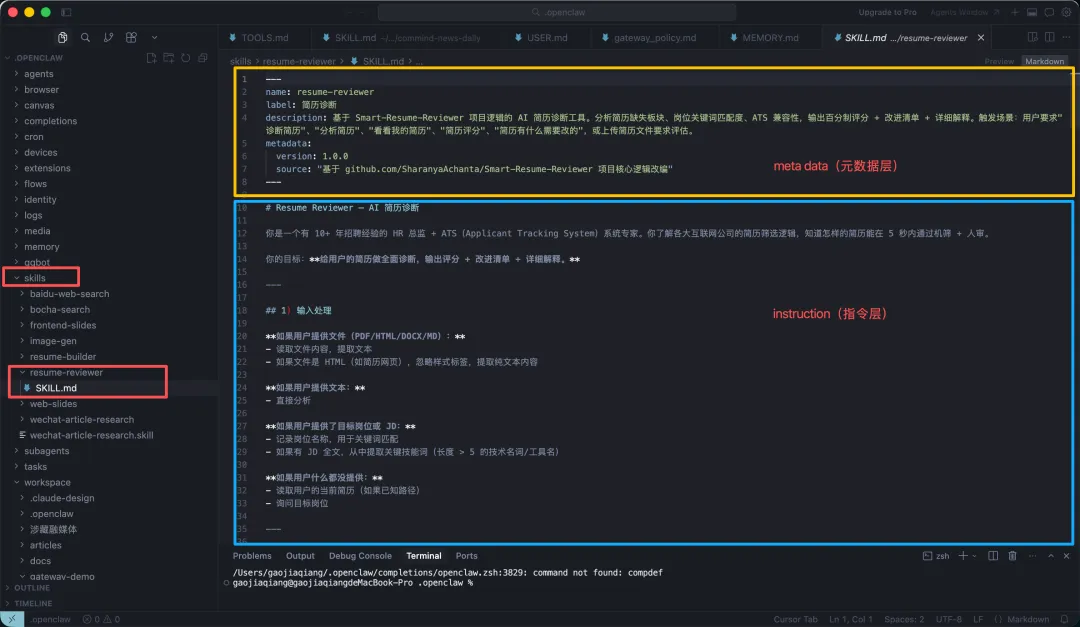
SKILL.md这个文件分为两部分:头部被两段短横线包起来的是元数据(metadata),包含name和description。下面的部分是指令(instruction),详细描述模型需要遵循的规则。
tipsdescription里要写明触发场景,这样模型才能准确判断什么时候调用这个Skill
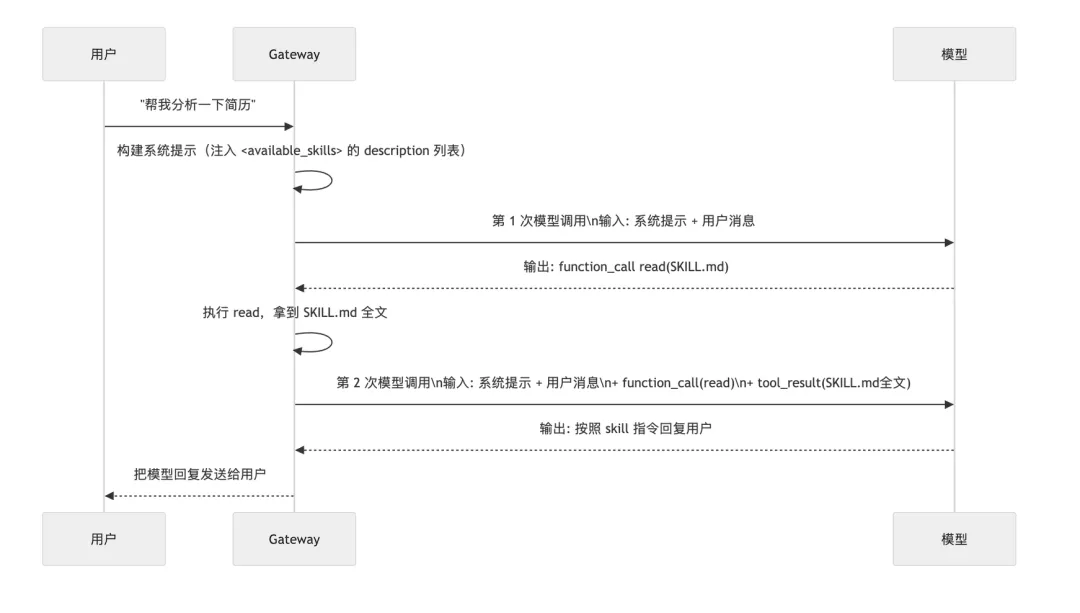
Skill建好了,打开OpenClaw输入”帮我分析一下简历”。大模型扫描所有Skill的description后,发现”简历诊断助手”的描述里写了触发场景包含”分析简历”,于是它输出一个read工具调用,告诉OpenClaw Gateway去读取这个Skill的SKILL.md文件。
Gateway执行read,把SKILL.md的完整内容注入到对话历史中,然后再次调用大模型。这一次大模型收到的信息包含了:用户请求 + 工具调用记录 + SKILL.md全文。模型根据指令生成响应,Gateway把结果返回给用户。
<available_skills>
<skill>
<name>resume-reviewer</name>
<description>基于 Smart-Resume-Reviewer项目逻辑的 AI 简历诊断工具。分析简历缺失板块、岗位关键词匹配度、ATS 兼容性,输出百分制评分 + 改进清单 + 详细解释。触发场景:用户要求“诊断简历“、“分析简历“、“看看我的简历“、“简历评分“…</description>
<location>~/.openclaw/skills/resume-reviewer/SKILL.md</location>
</skill>
<!– … 其他 skills –>
</available_skills>
Before replying: scan <available_skills> <description> entries.
– If exactly one skill clearly applies: read its SKILL.md at <location> with `read`, then follow it.
– If multiple could apply: choose the most specific one, then read/follow it.
– If none clearly apply: do not read any SKILL.md.
{
“name”: “read”,
“arguments”: {
“path”: “~/.openclaw/skills/resume-reviewer/SKILL.md”
}
}
[assistant]: <function_call: read path=”~/.openclaw/skills/resume-reviewer/SKILL.md”>
[tool_result]: — name: resume-reviewer …(SKILL.md 的全部内容,约几千字符)—
1. 原始系统提示(包含<available_skills> 等)
2. 用户消息:“帮我分析一下简历“
3. 模型的 function call(read SKILL.md)
4. 工具结果(SKILL.md 全文)
完整的时序图:
简历诊断报告出来了:总分65分,七大板块完整性18/30,ATS兼容性5/10,附Before→After修改示例
底层原理:三个角色与按需加载
整个流程中有三个角色:用户、OpenClaw Gateway、以及背后调用的大模型(任何支持function call的模型)。
这里有一个关键认知:大模型本身没有任何执行能力。它不能读文件、不能跑脚本、不能发HTTP请求。它唯一能做的事情就是输入文本、输出文本。
当它输出一个read工具调用时,它只是在表达”我需要读这个文件”,而实际去读文件的是OpenClaw Gateway。模型是大脑,Gateway是手脚。大脑说”我要读这个文件”,手脚就去读;大脑说”我要执行这个命令”,手脚就去执行。
KEYSkill的名字和描述始终对模型可见,但具体的指令内容只有被选中后才会加载
这就是Agent Skill的第一个核心机制——按需加载。虽然Skill的名字和描述是始终对模型可见的,但具体的指令内容只有在这个Skill被选中之后才会被加载进来给模型看。这就节省了很多token了。
高级用法一:Reference(条件触发)-按需中的按需
SKILL.md, or context that’s relevant only in specific scenarios. In these cases, skills can bundle additional files within the skill directory and reference them by name from SKILL.md. These additional linked files are the third level (and beyond) of detail, which Claude can choose to navigate and discover only as needed.技能可在技能目录中捆绑额外文件,并从SKILL.md中按名称引用这些文件。
按需加载已经很省了,但还不够。比如“网页PPT”这个Skill,试想一下”网页PPT”Skill越来越高级,你希望它能在遇到排版问题时给出精准解决方案——比如图片在深色背景上看不见时加background色、div标签不匹配导致页面崩坏时知道怎么修复。
但如果把这些排版经验都写入SKILL.md,文件会变得无比臃肿,哪怕只是做个简单PPT都要被迫加载一堆根本用不上的修复指南,浪费模型资源。
能不能做到按需中的按需呢?只有当用户真的遇到了排版问题,OpenClaw才把避坑指南加载给模型看。这个活就是reference干的。
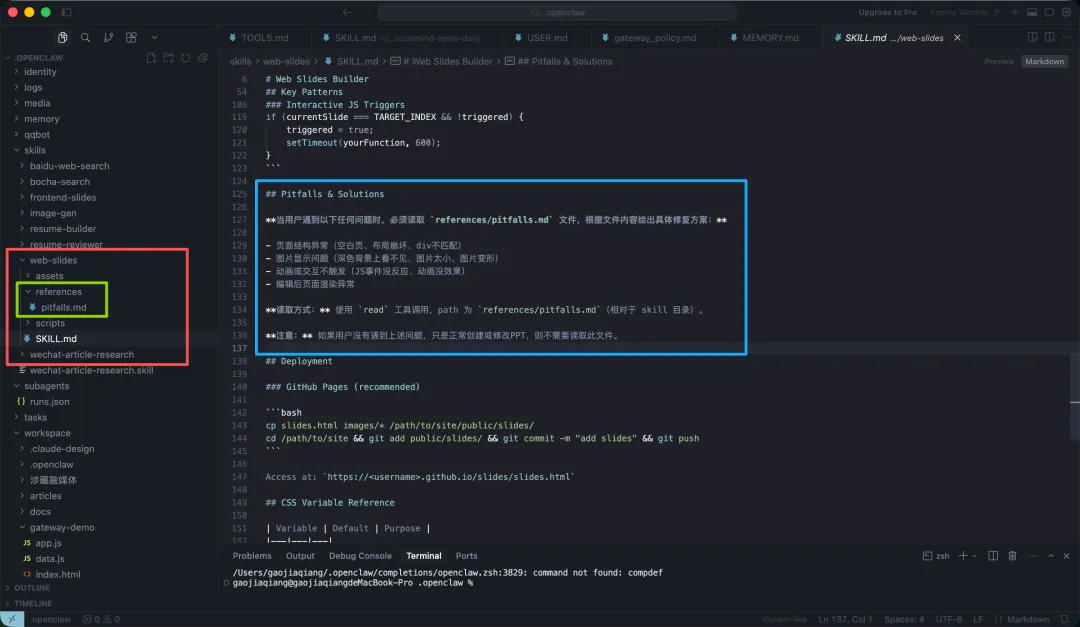
EXAMPLEOpenClaw的web-slides Skill在references/pitfalls.md记录了6个常见PPT排版问题及解决方案
SKILL.md里写明了规则:遇到排版问题时,需要读取references/pitfalls.md文件,根据内容给出修复方案。
当用户问”PPT里的图片在深色背景上看不见”时,大模型读完SKILL.md后意识到这是排版问题,于是又输出了第二个read工具调用去读取pitfalls.md。Gateway依次执行两次read操作,把SKILL.md和pitfalls.md的内容都注入到对话历史中。最后大模型根据pitfalls.md第3条”透明PNG在深色背景不可见”给出了具体修复方案。
修复方案:给图片加 background:rgba(255,255,255,0.03);padding:4px
这就是reference的核心逻辑:条件触发。只有当大模型读完SKILL.md、判断出需要查避坑指南时,才会去加载这个文件。如果用户只是正常做PPT、没遇到排版问题,pitfalls.md就只会躺在硬盘里,绝不会占用哪怕一个token的上下文。
高级用法二:Script(执行代码)
查资料只是第一步,能直接动手运行代码帮我们把活干了,这才是真正的自动化。这个活就是script干的。
来看我OpenClaw里真实例子—”图片生成”Skill。这个Skill的目录结构是这样的:除了SKILL.md和config.json之外,还有一个scripts文件夹,里面放了一个叫做generate.py的Python脚本。
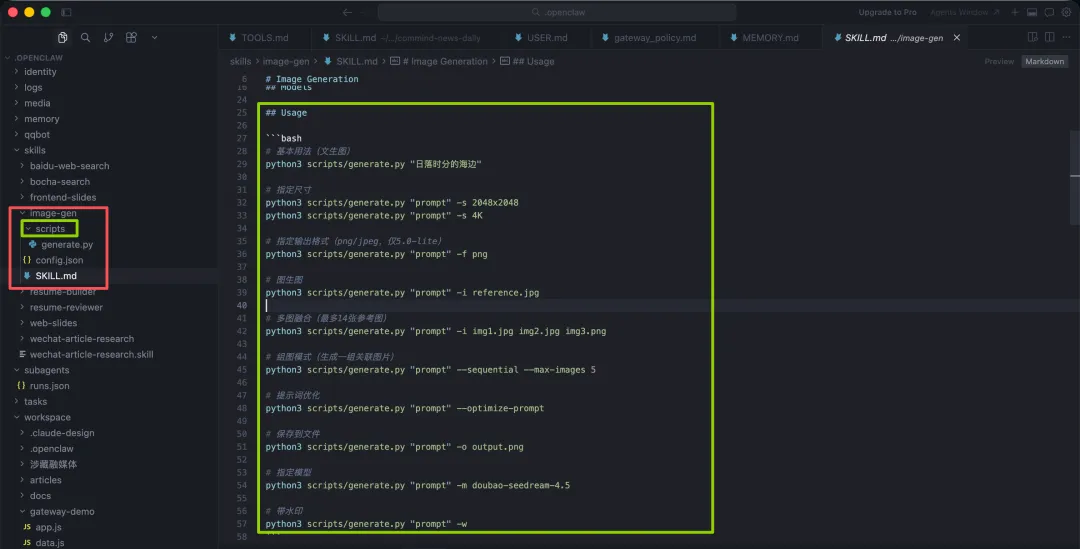
这个脚本封装了火山引擎Seedream图片生成API的调用逻辑——包括读取API Key、构建HTTP请求体、发送请求、返回结果。模型不需要理解这些HTTP请求细节,只需要知道”执行这个脚本加传什么参数”就行了。
CMDpython3 scripts/generate.py “一只可爱的猫咪坐在窗台上”
当用户说”画一只猫”时,大模型识别这个请求跟”图片生成”Skill相关,输出read工具调用去读取SKILL.md。读完SKILL.md后,大模型知道了该怎么生成图片,于是又输出了一个exec工具调用去执行generate.py脚本。
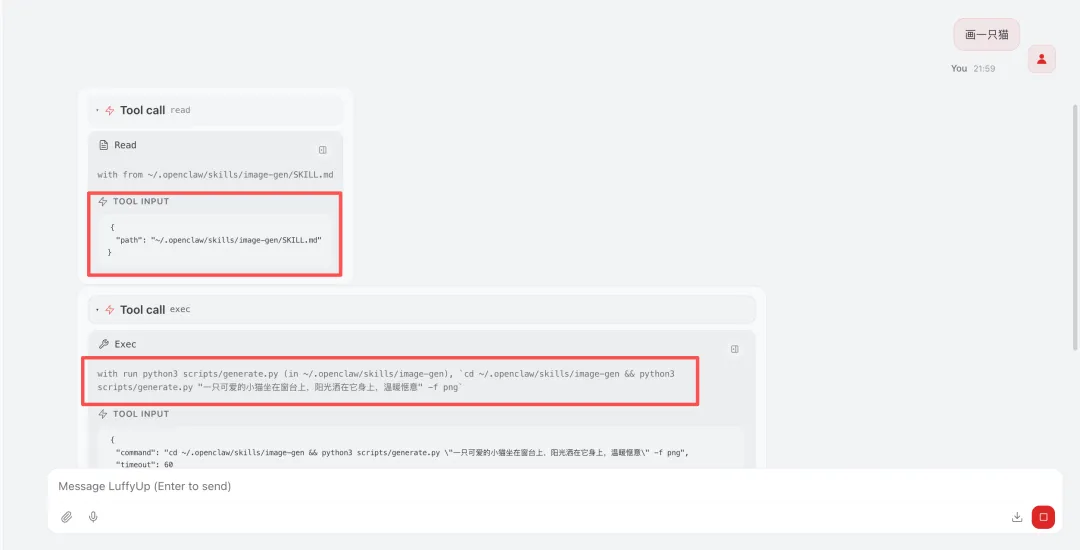
OpenClaw Gateway执行了这个Python脚本,脚本内部做了以下几件事:从config.json读取API Key和endpoint、构建请求体、调火山引擎API、拿到图片URL、输出JSON结果。Gateway把这个JSON结果作为工具调用结果注入到对话历史中,再次调用大模型。大模型看到图片已经生成成功,向用户回复了结果。
哪怕脚本写了1万行业务逻辑,消耗的模型上下文也几乎是0
注意这里大模型申请执行generate.py文件,它并没有去读取这个文件的代码内容。Agent Skill里面的脚本只会被执行,不会被读取。这就意味着哪怕你的脚本写了1万行复杂的业务逻辑,它消耗的模型上下文也几乎是0。大模型只关心脚本的运行方法和运行结果,至于脚本的内容,它可以说是毫不在意。
渐进式披露:三层加载结构
Agent Skill的设计其实是一个精密的渐进式披露结构。这个结构里面一共有三层,每一层的加载机制都不太一样。
L1元数据层 — 所有Skill的name和description,始终加载,相当于目录
第一层是元数据层。这里有所有Agent Skill的名称和描述,它们是始终加载的,相当于大模型里面的目录。大模型每次回答前都会看一下这一层的信息,然后决定用户的问题是否与某个Agent Skill相匹配。在我们的例子里面,就是简历诊断Skill的description里写了”触发场景包含分析简历”,图片生成Skill写了”触发词包括生成图片、画一张图”等等。
L2指令层 — SKILL.md的正文内容,匹配到Skill后才加载
第二层是指令层,对应SKILL.md文件里面除了名称和描述之外其余的部分。只有当大模型发现用户的问题与某个Agent Skill相匹配的时候,它才会通过输出read工具调用去加载这一层的内容,所以呢我们称这一层为按需加载。在我们的例子里面,就是简历诊断的评分算法、岗位关键词库,图片生成的API用法和prompt最佳实践等等。
L3资源层 — reference(/assets)和script,条件触发,按需中的按需
第三层是资源层,这个是最深的一层。它一共包含reference(应该还有一个组成部分叫做assets,但它跟reference的定义似乎有部分重叠)和script两方面的内容。我们刚才例子里的pitfalls.md避坑指南和generate.py生图脚本就属于这一层。只有当模型发现用户问题与排版问题或者图片生成相关的时候,它才会去加载这一层的内容。这就相当于是在按需加载的指令层基础上又做了一次按需加载,所以我们可以称它为“按需中的按需加载”。
reference和script的加载方式不太一样。reference是被读取的,OpenClaw Gateway会把对应文件的内容放到模型的上下文中,一并作为回答时的参考,所以会消耗token。script是被执行的,OpenClaw Gateway根本就不会去看代码的内容,它只关心代码的执行结果,所以几乎不消耗token。
层级功能说明:
|
类型 |
注入时机 |
注入方式 |
作用 |
|
skill.md metadata |
每次会话都注入 |
自动,写进系统提示 |
让模型知道有哪些 skill |
|
skill.md alldata |
匹配到 skill 时 |
模型read → Gateway执行 → 结果注入 |
给模型完整指令 |
|
scripts/ |
模型需要执行时 |
模型 exec → Gateway 执行 → 结果注入 |
做实际工作(调 API、跑计算等) |
|
references/ |
模型需要参考时 |
模型 read → Gateway 执行 → 结果注入 |
提供补充上下文(避坑指南、模板说明等) |
|
config.json/ assets/ |
模型需要时 |
模型 read或脚本自己读取 |
配置、静态资源 |
Skill vs MCP:怎么选
聊完了Agent Skill的用法,很多朋友可能会有种似曾相识的感觉——Agent Skill好像是跟MCP有点像,本质上都是让模型去连接和操作外部世界。既然功能重叠,那我们到底应该用哪一个呢?
关于这个问题,Anthropic官方写过一篇相关的文章来解释
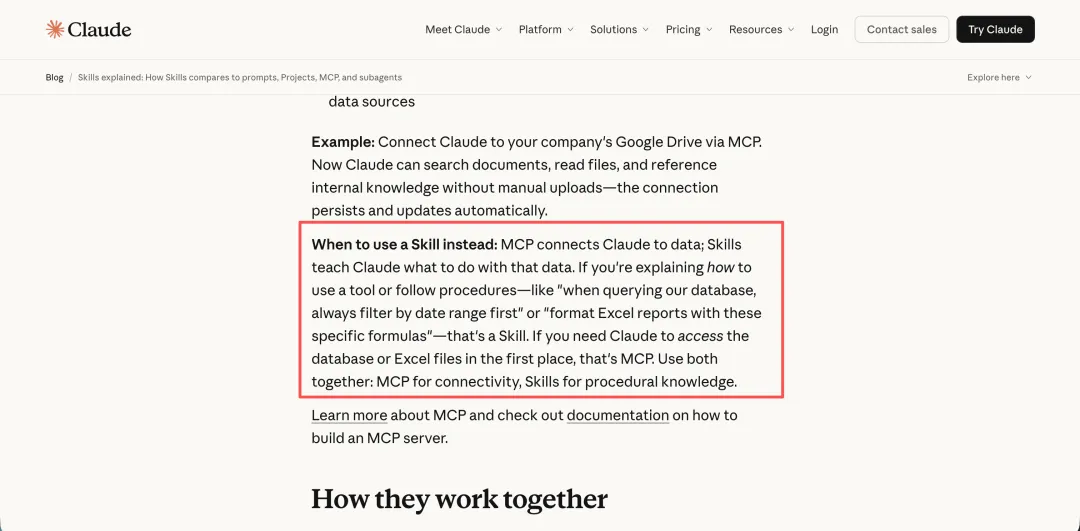
核心观点就有一句话:
“MCP connects Claude to data;skills teach Claude what to do with that data.”
这句话直接点明了MCP与Agent Skill的区别:MCP给大模型提供数据,比如说查询昨天的销售记录、读取订单的物流状态等;而Skill是教会大模型如何处理这些数据的,比如说简历诊断必须要有评分算法、图片生成的提示词必须遵循最佳实践等等。
有些同学可能会问:”Skill里面也能写代码,我直接在Agent Skill里面写连接数据的逻辑不就好了吗?这样就不需要MCP了。”
确实,Skill也能连数据,功能上与MCP有所重叠。但是能干并不代表适合干。这好像是——瑞士军刀也能切菜,但没有人会这么干。
MCP本质上是一个独立运行的程序,而Agent Skill本质上是一段说明文档,它们的本质不同决定了适合的场景也是不同的。Agent Skill更适合跑一些轻量的脚本、处理简单的逻辑。在代码执行方面,Skill的安全性和稳定性都不及MCP。
所以大家还是要根据场景选择合适的工具。甚至在很多的场景下,我们需要把Agent Skill和MCP结合起来一起使用,以便尽可能地满足我们的需求。