 夜雨聆风
夜雨聆风





AI实用工具分享
点击蓝字 关注我们

你是否有过这样的痛苦:想给自己的 AI 助手喂点实时数据,结果抓回来的全是乱七八糟的 HTML 标签?广告、导航栏、CSS 代码占了 90%,真正的内容反而被淹没了。
对于开发者来说,写爬虫不难,难的是清洗数据。对于学术党来说,做 RAG(检索增强生成)最怕的不是模型不强,而是喂进去的“饭”里全是沙子。
今天,我们要拆解一款专门为 AI 时代而生的“喂饭级”工具——Crawl4AI。
什么是Crawl4AI
用一句话总结:它是专为LLM(大语言模型)打造的“网页内容提取与结构化处理”专属工具。
传统的爬虫工具带回来的是HTML信息,你需要自己写无数个正则去清洗。而 Crawl4AI 直接给你Markdown或者JSON文件,这就相当于直接端上桌一盘可食用的精制餐。


解决了哪些痛点
No.1
HTML太乱
HTML 太乱带来的影响不只是“看起来杂”,而是直接体现在实验成本和模型效果上。网页中大量导航栏、广告、脚本和推荐内容会被一并送入模型,这些内容在token层面是等价消耗的,会迅速推高调用成本;更关键的是,这些噪声会稀释真正有价值的信息密度,使模型在注意力分配时偏离核心内容,导致摘要不准确、信息抽取遗漏甚至逻辑判断错误。在做RAG或评测实验时,这种噪声还会污染向量库,降低检索召回的相关性,表现为“明明有答案却检索不到”或“检索结果充满无关片段”,从而让你误以为是模型能力问题,实际上是输入数据质量问题。


No.2
解析繁琐
解析繁琐的问题会直接拖慢开发效率并降低系统稳定性。不同网站结构差异极大,而且结构本身是动态变化的,一旦你为某个站点写了定制解析规则,这套规则很可能在页面改版或内容类型变化后立即失效,导致解析结果为空或字段错位。在实验阶段,这会让数据分布不一致,同一任务不同时间跑出来的数据格式不同,难以复现结果;在工程阶段,这意味着需要持续维护大量脆弱的解析逻辑,增加人力成本和bug概率。更隐蔽的问题是,解析失败往往不会显式报错,而是“悄悄返回空结果”,最终影响模型训练或推理质量,却很难第一时间定位原因。


No.3
格式不友好
格式不友好则主要影响模型理解能力和下游任务效果。虽然Markdown比HTML更适合大模型,但从网页转换到Markdown的过程中,表格结构、层级关系、引用信息甚至公式都可能被破坏或丢失,这会让原本有明确结构的信息变成扁平文本。对于信息抽取任务,这意味着字段边界变得模糊,模型更容易抽取错误;对于问答或总结任务,这会导致上下文关系断裂,使模型生成内容缺乏逻辑一致性。在做实验时,这种格式损失会表现为模型输出波动大、结果不稳定;在开发中,则会限制你构建高质量数据管道和知识库的能力,因为输入本身已经损失了关键结构信息。


核心能力
No.1
自动化清洗
它能自动识别并剔除网页中的广告、导航栏、页脚等噪点,只保留核心正文。这样做的价值不只是“更清爽”,而是直接提升模型输入的信噪比:同样的 token 预算下,更多配额被用于真正有信息密度的内容,减少无关文本对注意力分配的干扰,从而提高摘要、问答和信息抽取的准确率与稳定性。在实验中,这会表现为更一致的输出和更低的方差;在工程上,则意味着更低的调用成本和更可控的性能。
输出的 Markdown 格式不仅干净,而且完美契合LLM的阅读习惯,本质原因在于 Markdown 强化了结构而弱化了呈现。标题层级(#、##)、列表、段落分隔等都为模型提供了清晰的语义边界,等价于在输入中显式标注“哪里是主题、哪里是要点、哪里是细节”,这会显著改善长文档理解与分块效果,进而提升向量检索的相关性和下游生成的连贯性。同时,Markdown是线性文本,避免了HTML标签嵌套带来的噪声与歧义,减少解析不确定性,使同一页面在不同时间或不同来源的处理结果更一致,利于复现实验和构建稳定的数据管道。


No.2
智能结构化抽取
开发者在Github网站上演示了三种结构化抽取应用,这三类应用使得Crawl4AI实现了远超于普通爬虫的功能,接下来我们一起来看看。
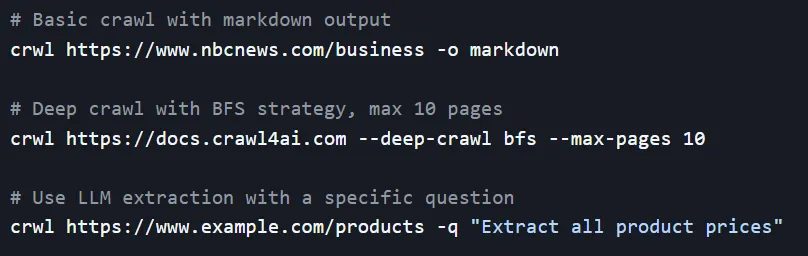
别被黑底白字的命令行吓到,这其实是 Crawl4AI 送给所有不爱写代码星人的“作弊码”。
基础提取
指令: crwl [URL] -o markdown
-
功能: 这是最常用的“一键去皮”模式。
-
传统爬虫抓回来的是几千行的 HTML 源码,而这条指令能直接过滤掉广告、侧边栏和垃圾代码,只给你吐出干净、漂亮的 Markdown 文本。
-
适用场景: 看到一篇深度好文,想把它存进 Notion 或 Obsidian 永久收藏?用它,格式整整齐齐。
深度抓取
指令: crwl [URL] –deep-crawl bfs –max-pages 10
-
功能: 这是一个“全自动爬取”模式。
-
如果你想抓取整个官方文档(比如 Crawl4AI 的官方文档),你不需要一个一个复制链接。它会采用 BFS(广度优先搜索)策略,自动顺着网页上的链接往下爬。
-
适用场景: 开发者构建 RAG(本地知识库) 时的神器。设定最大抓取页数(比如 10 页),它会帮你把这一套文档打包带走,直接喂给向量数据库。
智能语义提取
指令: crwl [URL] -q “Extract all product prices”
-
功能: 真正的“AI 爬虫”模式,把 LLM 挂载到了爬虫前端。
-
以前想拿价格,你要分析网页的 class 名或 id。现在你只需要像跟人聊天一样下指令:“提取所有产品价格”。
-
适用场景: 全网比价、避雷针、竞品分析。它不只是抓文字,它是在“理解”网页。它会跳过无用的描述,直接把你要的单价、折扣、原价精准提炼出来。


No.3
高性能并发
Crawl4AI目前支持四种抓取模式,分别是Stream/Batch/md/llm。
-
Crawl(Batch)模式下,一次性抓取所有页面,再统一返回结果。该模式比较适合中小规模任务,比如做知识库初始化。
-
Crawl(stream)模式下,抓到一个页面,就立刻返回一个结果,更适合于大规模爬虫。
-
md模式本质上是是将网页转成干净文本,优点是可以直接丢给大模型使用或做摘要。
-
llm模式是用大模型对网页内容做理解、提取以及结构化,可用于做信息抽取(前面代码示例)和自动化分析等功能。


使用方法


-
首先是安装,在终端中输入
pip install -U crawl4ai
pip install crawl4ai –pre
crawl4ai-setup
crawl4ai-doctor
-
使用python 运行简单的网络爬虫:
import asyncio
from crawl4ai import *
async def main():
async with AsyncWebCrawler() as crawler: result = await crawler.arun( url=”https://www.nbcnews.com/business”, )
print(result.markdown)
if __name__ == “__main__”:
运行之后,它会把网页的“干净正文”打印出来,而且是 Markdown 格式,可以直接拿去给GPT用。


-
除此之外,还可以直接在命令行调用。
-
如果你以后要做项目(比如做一个AI工具或网站),可以用它的 Docker 版本。Docker 的好处是:不用管环境,直接一条命令就能跑一个服务。它里面已经帮你集成好了API服务器、安全认证、还有可扩展架构,适合做后端服务。
END

以前我们说“知识就是力量”,但在 AI 时代,“获取高质量数据的能力,才是真正的降维打击”。Crawl4AI 就是一个全天候为你工作的专业情报员,它不仅能帮你省下 Token,更能帮你省下最宝贵的时间。
♥ ♥ ♥
求点赞

求分享

求喜欢

点击
阅读原文
查看更多