 夜雨聆风
夜雨聆风





让AI「自己改自己的作业」?NousResearch新论文实锤:越改越烂,345个词能删到只剩102个!
NousResearch发布论文Autoreason,用实验数据证明了一个让整个AI圈都不太舒服的结论:传统的「让模型自己批评自己、自己改自己」的self-refinement循环,大概率会把输出越改越差。更狠的是,某些baseline甚至会把一篇345词的文案删到只剩102词——模型在系统性地删除自己的工作。Haiku 3.5搭配他们的新方法拿到42/42满分,而传统refinement baseline反而跑输了单次直出。
2023年,所有人都信了一个美丽的故事
时间拉回2023年。
那一年,卡内基梅隆和Google联合发了一篇叫Self-Refine的论文,入选了NeurIPS 2023主会。核心主张简单到让人兴奋:让同一个大模型先写初稿,再给自己提反馈,然后迭代修改——不需要额外训练数据,不需要人类标注,性能就能提升约20%。
▲ Self-Refine论文入选NeurIPS 2023主会,提出”同模自评自改”范式
这个叙事太完美了。它意味着你不需要更大的模型、更多的数据、更贵的训练——只要让模型「多想一会儿」,输出就会变好。
整个行业迅速跟进。OpenAI、Anthropic、DeepMind都在内部搞self-critique项目。创业公司把「自我改进」写进BP。推理时计算(inference-time compute)成了最火的方向之一。
大家默认了一个前提:多改几轮,总比少改几轮强。
然而三年过去,有人拿着数据回来了,说:这个前提,错了。
NousResearch的反击:你们的模型根本不会「停手」
2026年4月,NousResearch在GitHub上放出了一个叫Autoreason的项目,附带完整论文。
标题已经把立场亮得明明白白——
Autoreason: Self-Refinement That Knows When to Stop
▲ NousResearch的Autoreason项目主页,README直接列出传统self-refinement的三大结构性缺陷
论文开篇就对准了传统self-refinement的三个致命问题,一条比一条扎心:
第一,Prompt Bias(提示偏差)。当你告诉模型「找出这段文字的问题」,它会怎么做?它会为了完成这个指令,硬找出根本不存在的问题。你让它挑刺,它就一定会挑出刺来——哪怕原文其实没什么毛病。
第二,Scope Creep(范围蔓延)。每一轮修改,模型都倾向于加内容、改结构、扩展范围。一轮又一轮,文本越来越长、越来越偏离原始目标,像一个永远刹不住车的编辑。
第三,Lack of Restraint(缺乏克制)。这是最要命的一条——模型几乎永远不会说「这版已经够好了,不用改了」。它的默认行为永远是继续动刀。
三条加在一起,结论就很清晰了:没有停止机制的self-refinement循环,天然就是一个退化系统。
数据有多残酷?345词删到102词
如果上面三条还像是理论分析,论文里的实验数据直接把问题摆到了台面上。
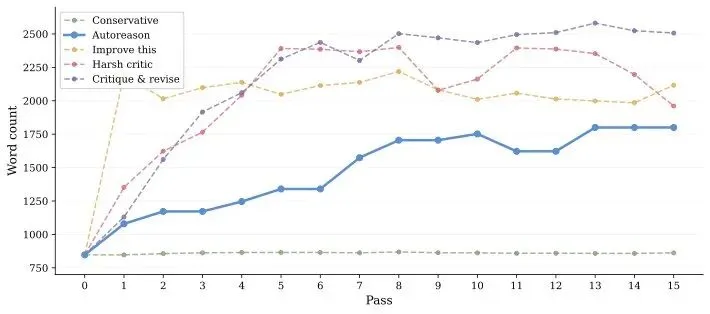
▲ 不同方法在15轮迭代中的词数变化——传统方法(Harsh critic等)疯狂膨胀或砍削,Autoreason保持稳定
论文给出了一组让人瞠目的数字:
-
Conservative baseline把一篇205词的GTM文案砍到了78词,直接删掉62%; -
Harsh critic把一篇345词的pitch削到了102词,蒸发70%; -
Critique-and-revise把一篇331词的policy文档切到了137词,干掉59%。
模型在干什么?它在系统性地删除自己的工作。
每一轮「优化」,都在把文本往更短、更空洞的方向推。不是在打磨,是在拆迁。
与此同时,Autoreason在同样的任务上,词数变化是:345→476,331→407,205→388。内容在增长,但保持可控。
满分42/42 vs 跑输单次直出:差距到底有多大
论文里最炸的一组结果:
Haiku 3.5 + Autoreason,在三项任务上拿到了42/42的Borda满分。
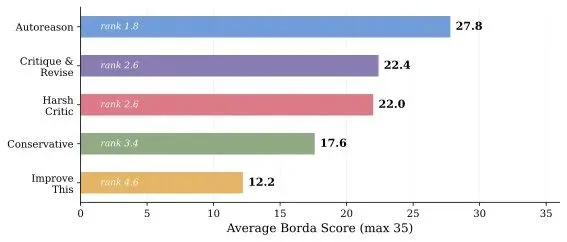
▲ 五种方法的平均Borda得分对比,Autoreason(27.8分,rank 1.8)远超所有baseline
而那些传统的refinement baseline呢?它们不只是没赢——它们把同一个模型的输出质量,拉到了比单次直出还低的水平。
你没看错。精心设计的多轮自我修改流程,最终效果还不如什么都不做,让模型一次性写完交卷。
代码任务上的数字同样扎眼:
- Sonnet 4.6
:Autoreason拿到private-test准确率77%,单次直出只有73%; - Haiku 3.5
:在相同算力下,Autoreason40%vs best-of-6采样的31%; - Haiku 4.5
:优势消失,三种策略都来到60%左右——因为模型够强了,生成和评审之间的差距已经闭合。
最后这个细节特别值得注意:受益最大的反而是中档模型。太弱的模型生成不出足够多样的候选,太强的模型自己就能判断好坏。真正需要外部评审结构的,恰恰是那些「写得出来,但判不准」的中间地带。
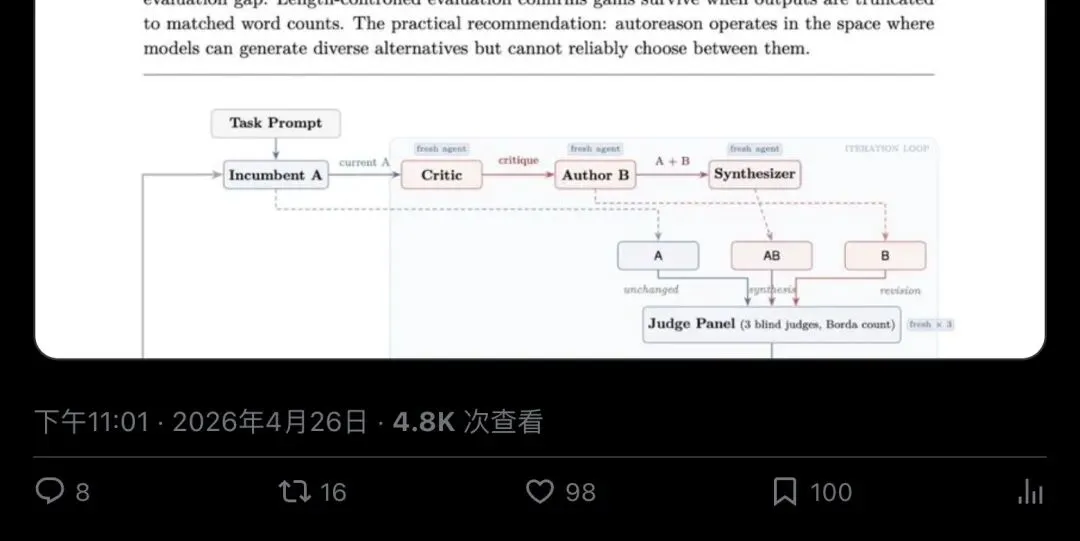
Autoreason怎么治的?三版本盲选 + 允许「什么都不做」
Autoreason的解法说穿了就一句话:把「默认继续改」变成「默认保留现状,除非新版本真的更好」。
具体怎么做?
每一轮迭代同时生成三个候选版本:
- A
:原始稿,完全不动; - B
:根据批评修改的新版本; - AB
:把A和B做融合的synthesis版本。
然后关键来了——谁来选?
传统做法是让写稿的模型自己打分。但论文明确指出,这行不通。刚写出这段文字的人,没办法公正地给自己打分。所以Autoreason用了3个全新的、不共享任何上下文的fresh judge做盲选,用Borda count聚合排名,平局时保守地让原稿胜出。
最精妙的是停止条件:如果原始版A连续两轮都赢了,系统判定已经收敛,自动停止。
这解决了传统self-refinement最致命的问题——你永远不知道什么时候该住手。现在有人帮你踩刹车了。
失败之后,谁能爬起来?62% vs 43%
还有一组数据特别能说明问题。
论文挑出了那些「第一次尝试双方都失败」的53道编程题,看后续谁能追回来:
-
Autoreason追回了33道,成功率62%; -
单次直出(多采样)追回了23道,成功率43%。
差距接近20个百分点。这说明Autoreason真正的价值体现在失败之后——它能更好地分析哪里出了问题,并且只在值得改的时候再改。
从业者的反应:「我们半年前就不用critic agent了」
这篇论文的结论并不孤立。推特上的讨论显示,不少一线从业者早就踩过同样的坑。
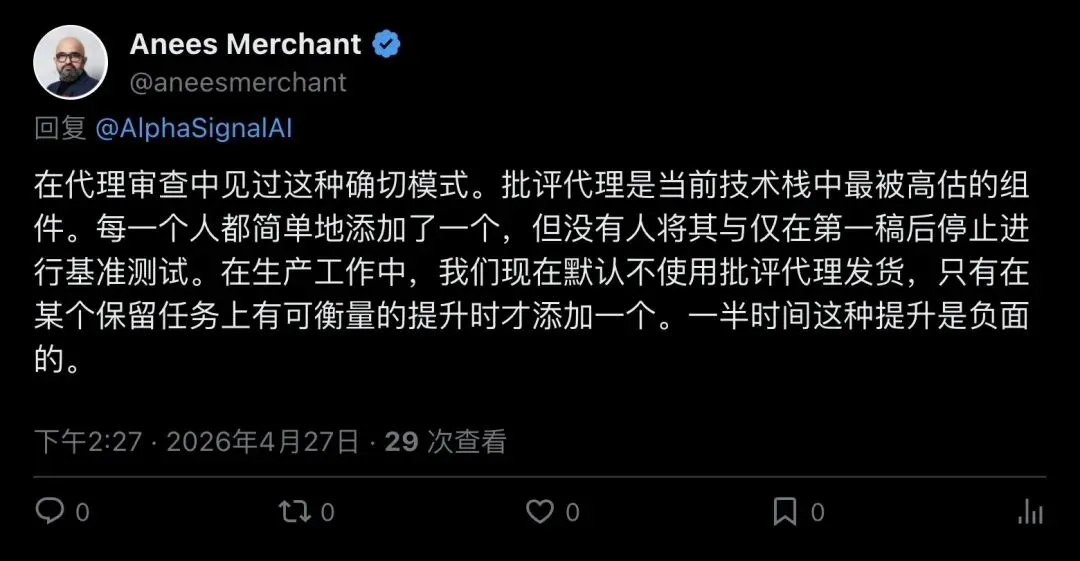
▲ Anees Merchant:critic agent是当前技术栈中最被高估的组件之一,一半时间收益为负
Anees Merchant直接说:critic agent是当前AI技术栈中最被高估的组件。大家都在往pipeline里塞critic,但几乎没人严格做过和first-draft baseline的对比测试。他们团队的实践经验是,在生产环境中默认不用critic agent,只有在特定任务上能测到可量化的提升时才加——而一半的时候,所谓的「提升」其实是负数。
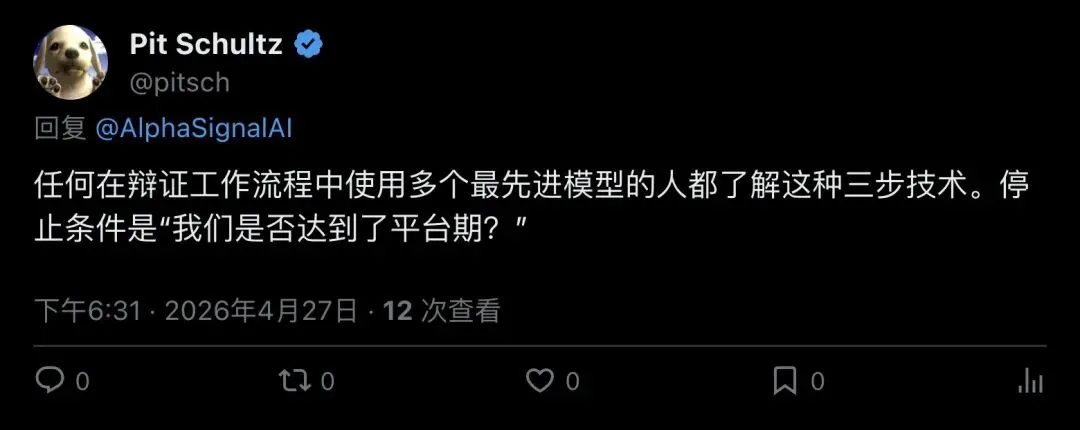
▲ Pit Schultz:用多个前沿模型做辩证工作流的人都知道,关键在于停止条件
Pit Schultz则从另一个角度补充:用多个前沿模型做辩证式工作流本身并不新鲜,真正的关键在于有没有停止条件(plateau stopping)。Autoreason的贡献在于把这个实践经验论文化、结构化、指标化了。
真正的教训:生成能力和评审能力,完全是两回事
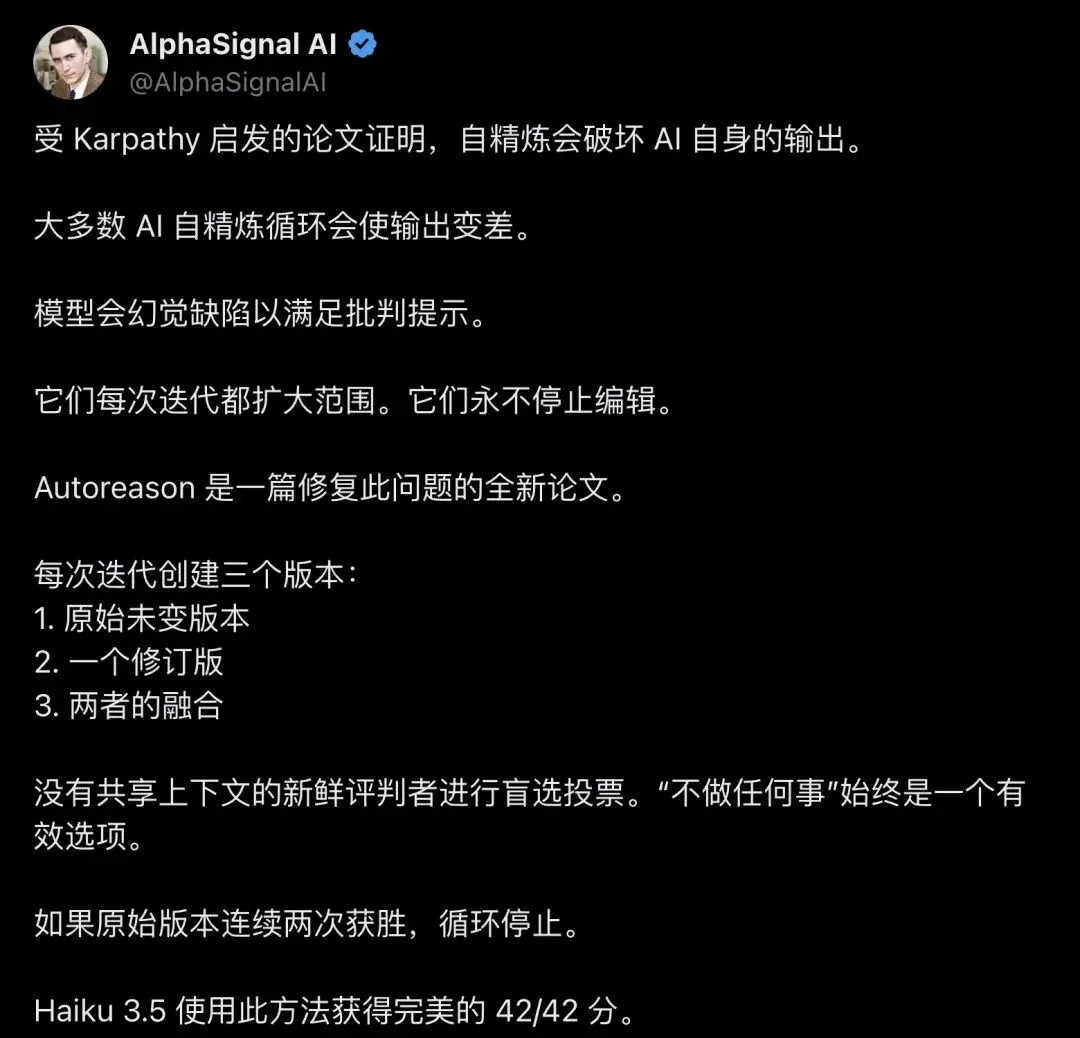

▲ AlphaSignal AI对Autoreason论文的完整摘要推文,近5000次查看
这篇论文打破的核心假设只有一个:模型能写出好内容,就一定能判断好内容。
但事实恰恰相反。生成能力(generation capability)和评审能力(evaluation capability)之间存在一道鸿沟。模型可以同时产出五个版本,但它未必能在这五个版本里选对最好的那个。
更糟糕的是,当你强迫一个模型去执行「批评→修改」循环时,你其实在做三件危险的事:
1.强迫它产出批评——哪怕没什么可批评的; 2.强迫它做出修改——哪怕原版已经足够好; 3.从不给它「什么都不做」的选项——于是它只能不停地动刀。
一旦流程天然奖励「动手」,那再稳的原稿也会被改坏。
AI能自我改稿吗?能。但它不能既当作者、又当审稿人、还自己决定什么时候放下笔。把这三个角色塞进同一个模型、同一个上下文、同一个循环里,得到的就是一个注定退化的系统。
Autoreason的解法其实很朴素:让不同的人来审,给「不改」留一个位置,设一条明确的停止线。
听起来像常识?但整个行业花了三年才从数据里承认这一点。
— END —