夜雨聆风
夜雨聆风





零样本计数新突破,西工大&电信TeleAI提出QICA!(附论文及源码)






以下文章来源于微信公众号:我爱计算机视觉
作者:CV君
链接:https://mp.weixin.qq.com/s/SglSioJMFvpq2Jhvms4YJg
本文仅用于学术分享,如有侵权,请联系后台作删文处理

在计算机视觉的众多任务中,“数数”看似简单,实则暗藏玄机。尤其是当我们要求模型在完全没见过某个类别、也没有任何视觉参考(Exemplar)的情况下,仅仅凭借一句“帮我数数图里有多少个草莓”就能给出准确答案时,这就是所谓的“零样本对象计数(Zero-Shot Object Counting, ZSOC)”。
近日,来自西北工业大学、中国电信人工智能研究院(TeleAI)、中国科学技术大学以及复旦大学的研究团队,针对这一领域提出了一个具启发性的新框架:QICA,是 Quantity perception with robust spatial Cast Aggregation 的缩写,意在强调其结合了“数量感知”与“鲁棒的空间代价聚合”能力。它不仅在标准的计数基准上表现出色,更在极高密度的人群计数场景中展现了良好的泛化能力。

-
论文地址: https://arxiv.org/abs/2603.16129 -
代码仓库: https://github.com/zhangda1018/QICA (将开源) -
录用会议: CVPR 2026
为什么现在的模型“数不清”?
目前的通用做法通常是利用像 CLIP 这样的预训练视觉-语言模型(Vision-Language Models, VLMs)。模型接收图像和文本,计算两者的相似度图,然后交给一个解码器去预测密度图。听起来很完美,但实际操作中存在两个“痛点”:
-
数量盲区(Quantity Blindness):现有的模型大多只学习了“语义对齐”,即模型知道什么是草莓,但它并不真正理解“1个草莓”和“10个草莓”在视觉特征上的细微差别。文本提示往往只包含类别名,缺乏对数量的显式监督。 -
特征空间扭曲(Feature Space Distortion):为了让模型学会计数,开发者通常会微调 VLM。但直接微调往往会破坏 CLIP 原有的通用特征空间,导致模型在训练集里数得很好,一遇到没见过的类别就“抓瞎”了(即过拟合)。
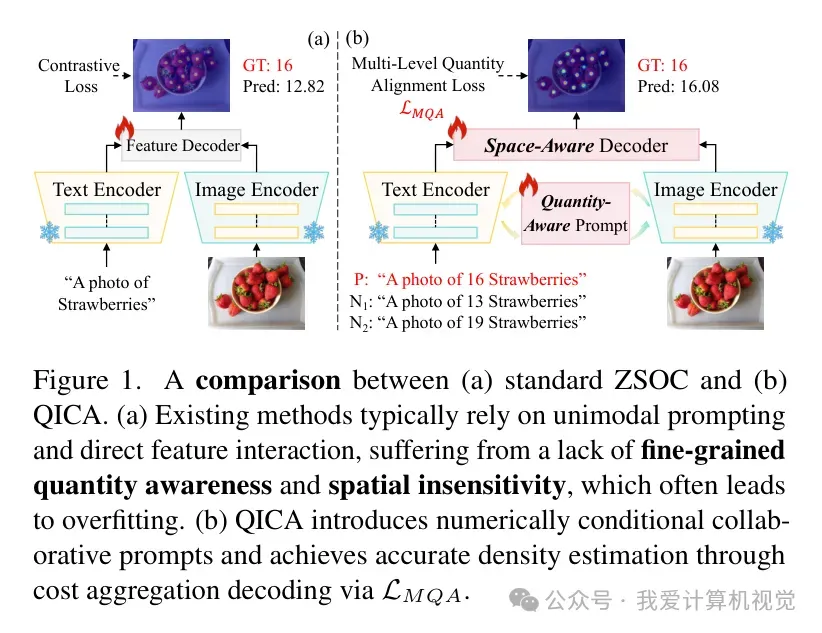
为了解决这些问题,QICA 另辟蹊径,从“感知”和“解码”两个维度进行了重构。
QICA 的核心:协同提示与代价聚合
QICA 的架构设计主要由三个核心组件构成:协同提示策略(SPS)、代价聚合解码器(CAD)以及多级数量对齐损失()。
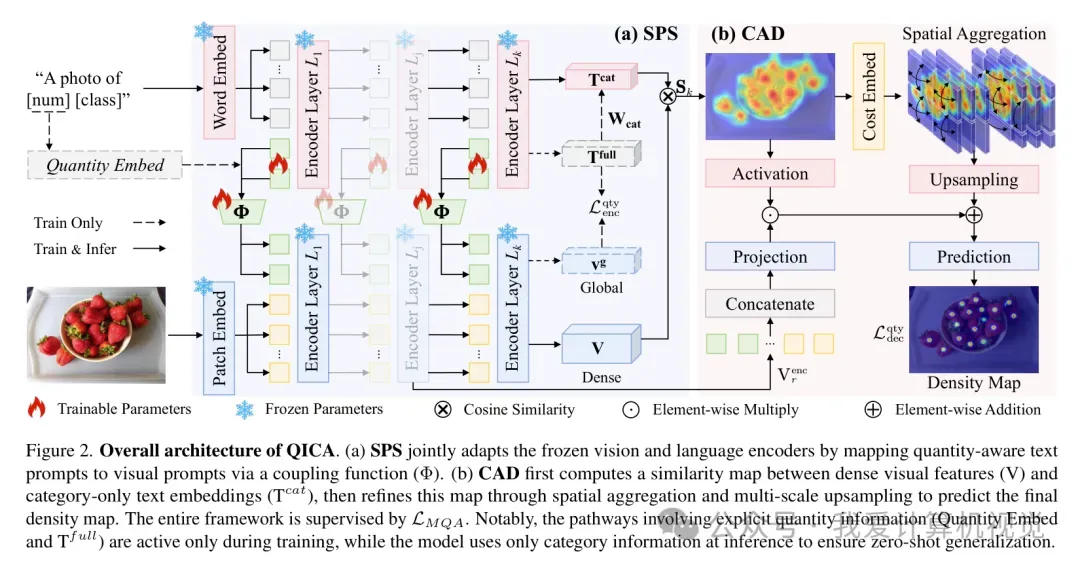
1. 协同提示策略(SPS):给模型装上“数量秤”
研究团队认为,要让模型懂数量,就得在提示(Prompt)阶段下功夫。协同提示策略(Synergistic Prompting Strategy, SPS) 不再孤立地处理视觉和文本分支。
-
数值条件化:它首先将离散的数量值 转换为连续的嵌入向量 。在训练时,模型不仅会看到真实的数量(如“16个草莓”),还会通过一种 区间分箱策略(Interval-based binning strategy) 动态生成一些“反事实”的错误数量(如“13个”或“19个”)。 -
双向协同:最巧妙的地方在于,这些文本提示会通过一个耦合函数(Coupling Function, )直接映射到视觉编码器的提示中。这种双向的梯度流动让视觉和语言编码器能够协同工作,共同理解“数量”这个概念。
Input/Output 流程:
-
Input:原始图像、类别文本描述、 ground-truth 数量及生成的反事实数量。 -
Output:注入了数量信息的文本嵌入 和视觉特征 。
2. 代价聚合解码器(CAD):拒绝“特征污染”
为了避免微调导致的特征扭曲,QICA 提出了 代价聚合解码器(Cost Aggregation Decoder, CAD)。不同于以往直接处理高维视觉特征的方法,CAD 直接在“视觉-文本相似度图(Similarity Map)”上操作。
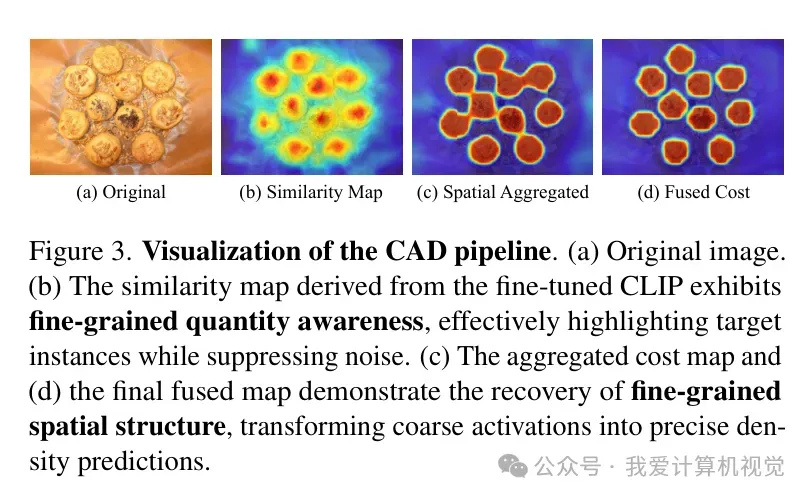
通过 Swin Transformer 块进行 空间聚合(Spatial Aggregation),模型能够利用图像的结构信息来细化这些粗糙的相似度激活。CAD 就像是一个精细的过滤器,它能够识别出相似度图中的孤立噪声并予以剔除,同时增强那些符合物体空间分布的区域。
Input/Output 流程:
-
Input:密集视觉特征 、仅含类别的文本嵌入 。 -
Output:精细化的预测密度图 。
3. 多级数量对齐损失:严苛的“排序”监督
为了确保模型真的学到了数量逻辑,团队设计了 多级数量对齐损失(Multi-level Quantity Alignment Loss, )。
在编码器级别,它引入了一个排序约束:真实数量的提示与图像的相似度必须最高,且数值越接近真实值的提示,其相似度得分也应该越高。
这种约束强迫模型在潜空间中建立起清晰的数值序关系。而在解码器级别,模型需要对每一个数量假设都预测一个密度图,并确保预测的总数与该假设的数值一致。
实验结果:全线飘红的 SOTA
研究团队在多个极具挑战性的数据集上验证了 QICA 的实力。
1. FSC-147:通用计数的标杆
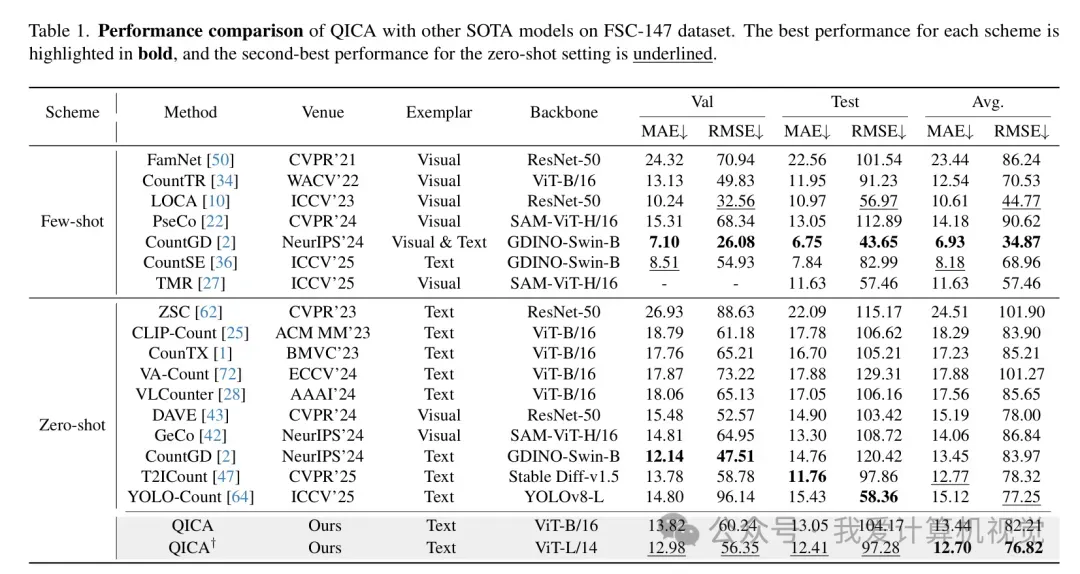
在包含 147 个类别的 FSC-147 数据集上,QICA(基于 ViT-L/14)在测试集上达到了 12.41 MAE 和 97.28 RMSE。相比于之前的 CLIP-Count 等方法,性能提升了 27% 以上。即便与一些需要视觉参考(Few-shot)的方法相比,QICA 依然具竞争力。
2. 跨数据集泛化:CARPK 与人群计数
更令人惊喜的是 QICA 的跨领域泛化能力。在完全没见过 CARPK(停车场车辆计数)和 ShanghaiTech-A(极高密度人群计数)数据的情况下,QICA 直接进行推理:
-
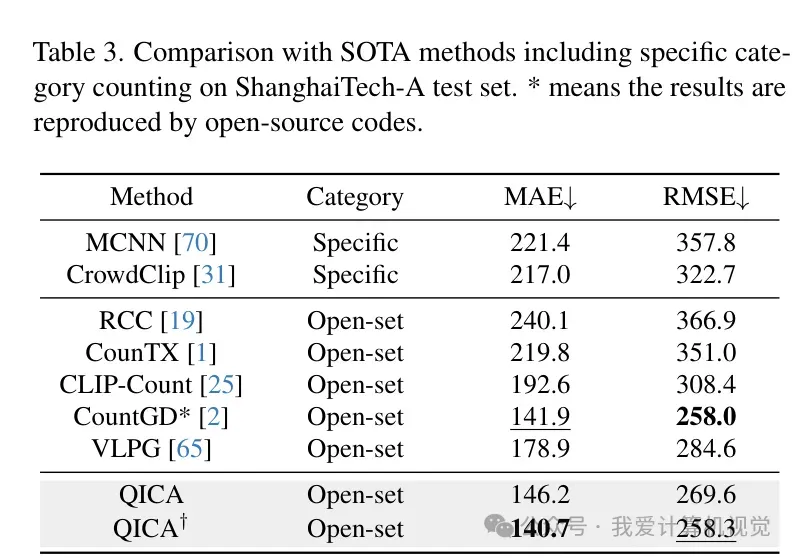
在 ShanghaiTech-A 上,QICA 达到了 140.7 MAE,刷新了开源零样本计数方法的纪录。 -
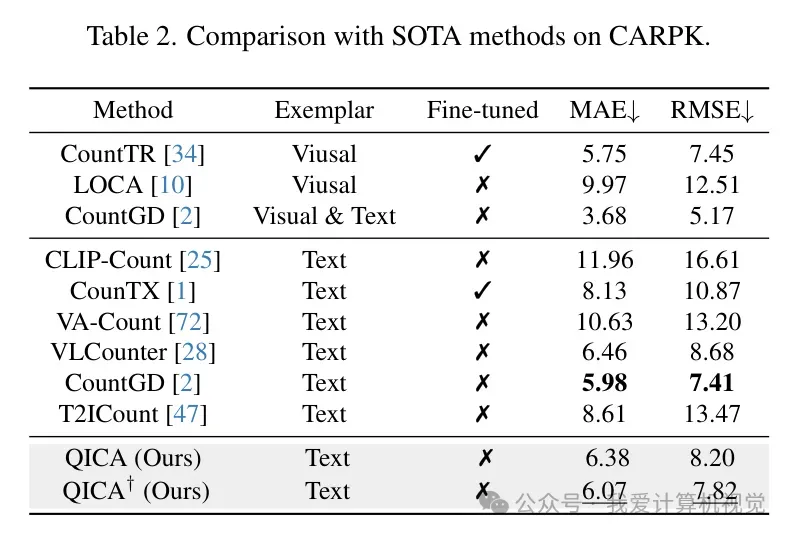
在 CARPK 上,其表现(6.07 MAE)也显著优于 T2ICount 等扩散模型驱动的方法。
3. 深度分析:提示深度与损失权重
通过消融实验,研究团队发现 提示深度(Prompt Depth) 对性能有显著影响。在 1-9 层注入提示时效果最佳。此外,对损失权重 和 的敏感性分析显示,适度的编码器级监督对建立数量感知至关重要。
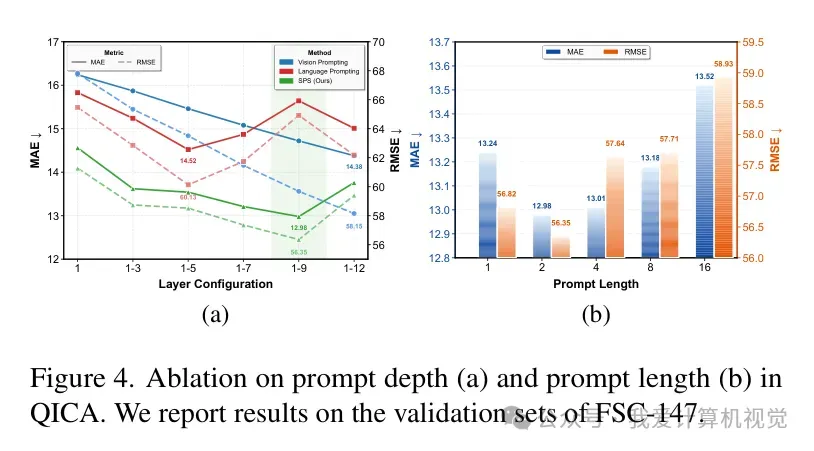
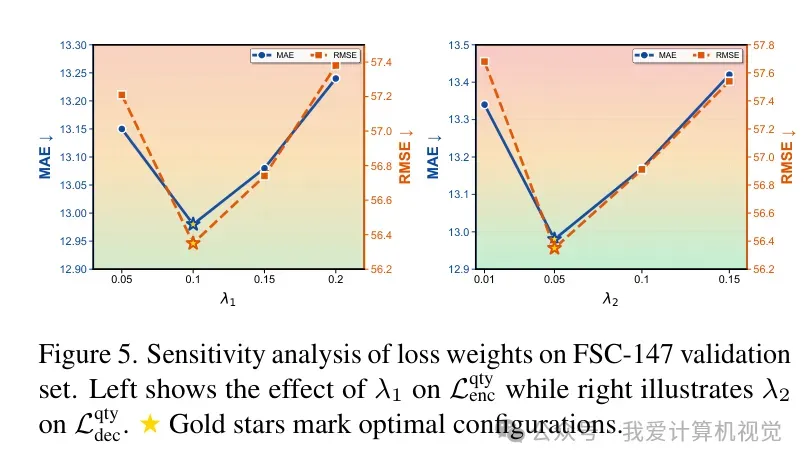
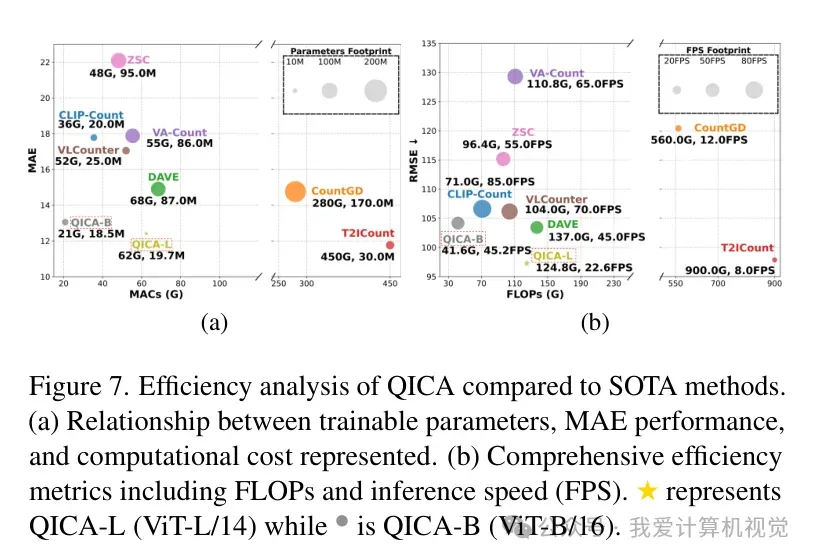
4. 效率与可视化的双重胜利
在效率方面,QICA 同样表现不俗。得益于冻结编码器和轻量化提示的设计,其可训练参数量仅为 19.7M 左右,在 NVIDIA A800 GPU 上可以达到 45.2 FPS 的推理速度,非常适合实际部署。
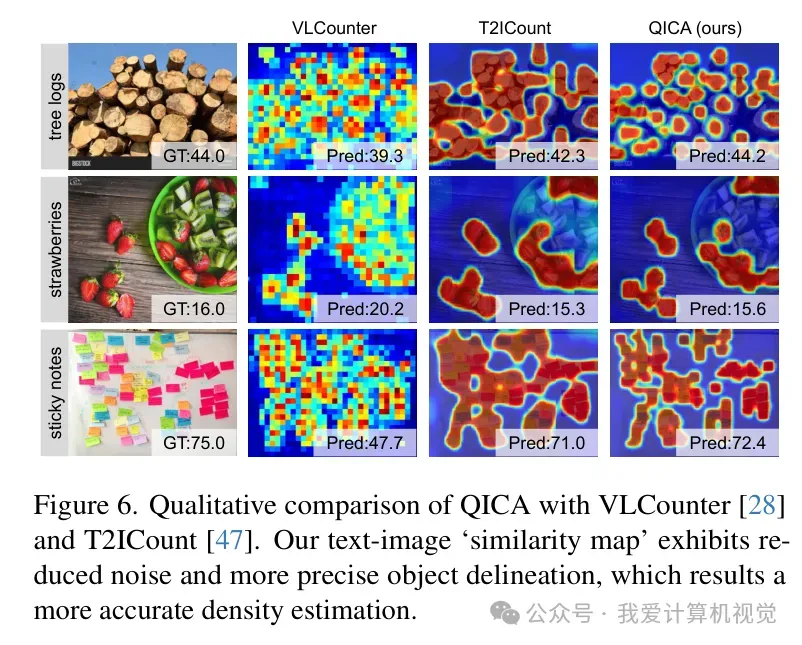
从可视化结果来看,QICA 生成的相似度图噪声极低,能够精准勾勒出目标的轮廓,这直接证明了 CAD 模块在空间细化方面的有效性。
写在最后
这项研究表明,在利用大模型处理下游任务时,单纯的语义对齐是不够的,尤其是像计数这种对数值高度敏感的任务。
通过 SPS 引入数值先验,再通过 CAD 在相似度空间进行非侵入式的微调,QICA 成功在“保持泛化性”和“提升精确度”之间找到了一个平衡点。
江大白,工业AI实战派CTO,安生智联联合创始人,专注从算法到工业场景的应用落地,和你分享产品&项目中的所见所得!
深耕企业安全管理+AI领域,通过“技术+商业+内容”的融合视角,深度参与AI产业化落地。
全网20W+粉丝AI知识博主,人工智能技术文章超1000W+阅读,《30天入门人工智能》课程,全网2000+名学员。
主导构建的AI知识平台www.jiangdabai.com累计访问已超800万次;
思想阵地(深度洞察):知乎、CSDN @江大白
内容阵地(视频解读):抖音、快手、小红书 @江大白讲AI
实战阵地(产品纪实):抖音、快手、小红书 @安生江大白 | 记录“1年10个AI产品100个项目应用”的极限挑战

真诚分享AI落地过程(AI商机->项目签约->算法开发->产品开发->实施运维)中的各方面经验和踩过的坑。
大家一起加油!