 夜雨聆风
夜雨聆风





AI不是大力丸
这本书的两位作者都来自普林斯顿大学。第一作者阿尔文德·纳拉亚南是计算机科学教授,常年研究AI等数字技术对社会的影响;另一位是他的博士生。


书名的英文《AI SNAKE OIL》原意是“AI蛇油”。19世纪末的美国,江湖游医四处兜售一种号称“包治百病”的“蛇油”。实际上,这些药油几乎不含任何有效成分,甚至有害健康。

作者借用这个概念,想说的是:今天许多被吹得神乎其神的AI技术,其实就是当年的“蛇油”——名声在外,但实际效果与宣传相去甚远,甚至潜藏着风险。
AI万金油的翻译还差点意思,如果翻译成《AI大力丸》可能更精确:在现今AI产业的叙事中,我们是不是在被许诺一种“立竿见影”的技术奇迹?而且,“大力出奇迹”本就是互联网常用梗,契合AI行业“算力至上”“蛮力堆叠”的底层逻辑——讽刺意味更当代、更精准。

第一部分:两种AI,两套问题
在深入之前,先明确两个概念:
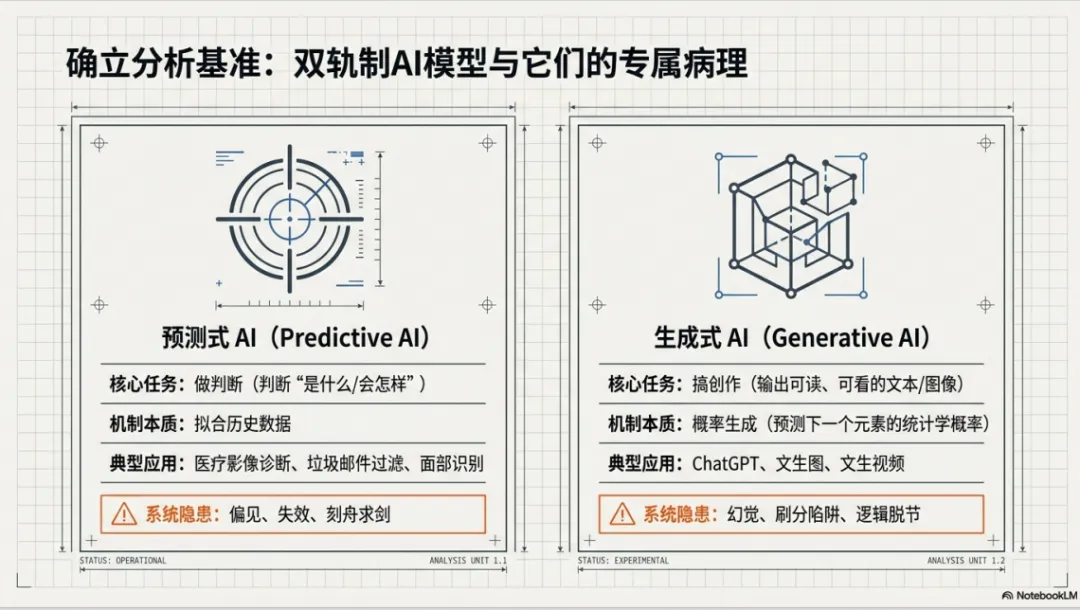
- 预测式AI:核心任务是“做判断”。人脸识别(这张脸是谁?)、垃圾邮件过滤(这是垃圾邮件吗?)、医疗影像诊断(这个结节是良性还是恶性?)。这里的“预测”不限于“预知未来”,而是泛指“做判断、下结论”。
- 生成式AI:核心任务是“搞创作”。ChatGPT、文生图、文生视频——输出我们能理解、能欣赏的文字、图片、视频。
两类AI,各有各的问题。
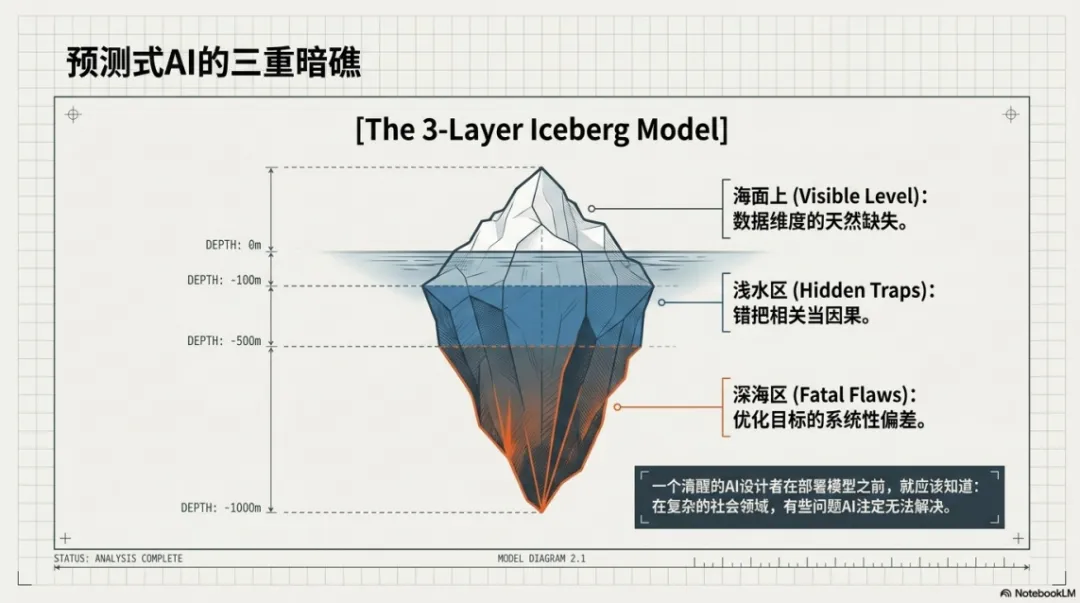
第二部分:预测式AI的三大“暗礁”
第一重:可预见的局限——为什么有的AI怎么训都训不好?
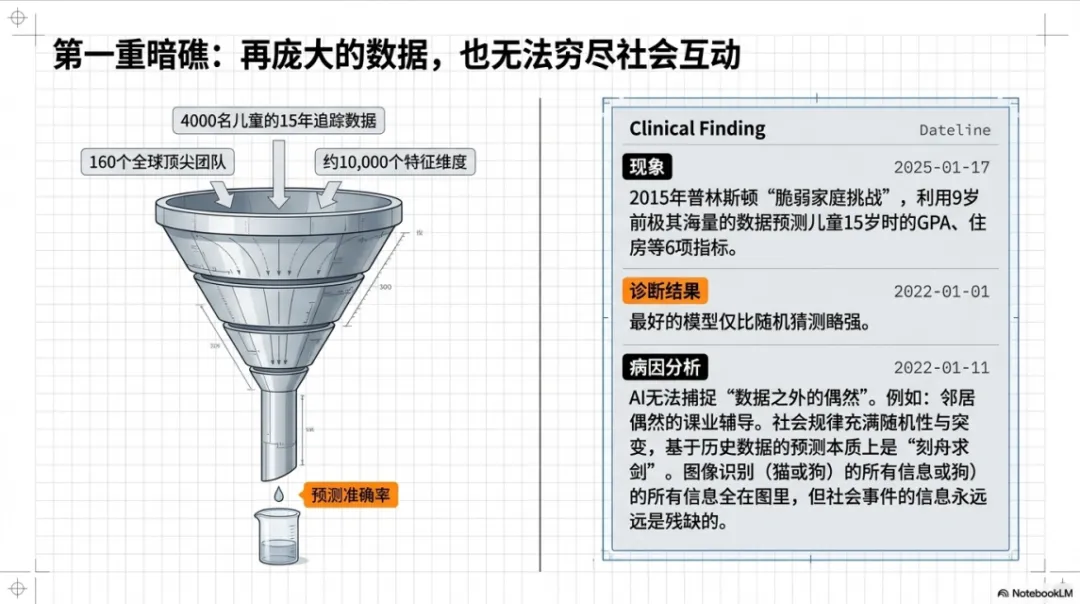
2015年,普林斯顿大学搞了一项名为“脆弱家庭挑战”的研究。他们追踪了4000多名儿童从出生到15岁的数据,邀请全球160个团队用孩子9岁前的全部信息,来预测他们15岁时的表现——GPA、住房稳定性、家庭物质状况等6项指标。
结果令人大跌眼镜:最好的模型也只比随机猜测略强一点点。
很多人第一反应是:数据量不够大?不是。每个孩子已经收集了约1万个特征维度,已经多到超乎想象。
研究人员去回访预测误差最大的家庭,发现了一个关键细节:一个原本成绩较差的孩子突然表现出色,原因是邻居帮他辅导作业、提供食物。但这些“来自家庭外的支持”,数据里根本没有记录。
要解决这个问题,理论上需要记录孩子的一举一动,甚至每个念头——这在伦理、法律和实践层面都不可接受。这就是预测式AI在社会领域的第一重困境:数据维度的天然缺失。
为什么图像识别就不会有这个问题?因为判断一张图里是猫还是狗,所需的所有信息已经完整地包含在图片里了。图片本身就是“完整的数据”,不存在关键信息的遗漏。
第二重困境在于问题本身的内在复杂性。
社会规律是会变的。20年前的商业成功法则,放到今天可能就是“作死指南”。用历史数据训练的模型,本质上就是“刻舟求剑”。
社会事件还充满随机性。一本书的早期好评可能只是因为某个大V随手转了一下;一个人的成功可能只是因为某次会议上恰好坐在了贵人旁边。这些随机因素,本质上是不可预测的。
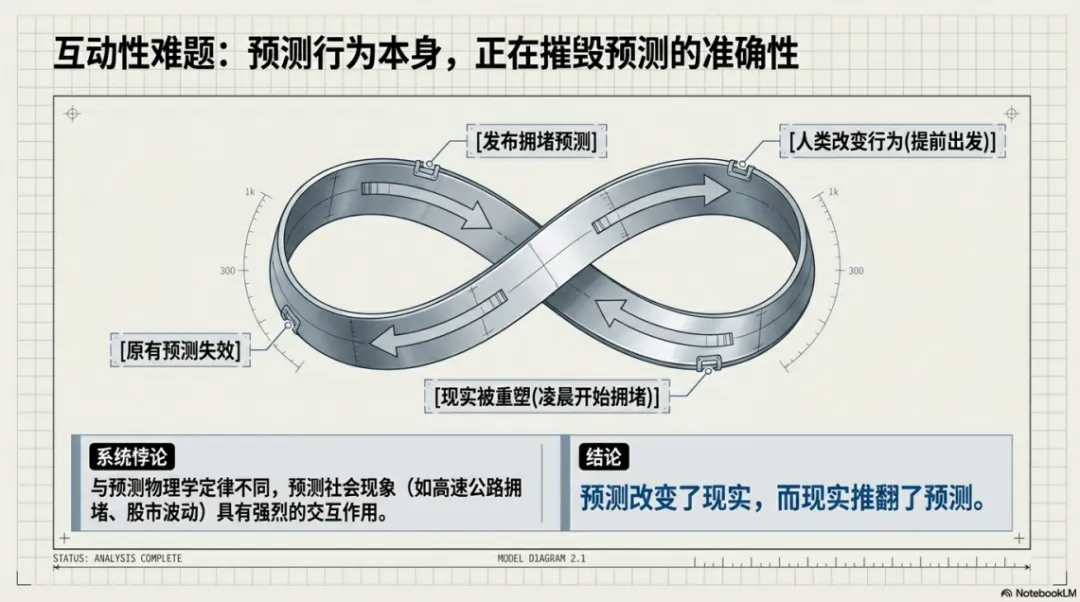
更麻烦的是“互动性难题”:预测行为本身会改变被预测的对象。节假日第一天上午高速公路会堵车——这个预测广为人知后,大家都提前到凌晨出发,结果凌晨堵了。预测改变了现实,现实推翻了预测。
这些局限是“可预见的”。一个清醒的AI设计者在部署模型之前,就应该知道:这类问题,AI就是搞不定。
第二重:隐蔽的陷阱——为什么有的AI“一学就会,一用就废”?
有的模型在测试集上表现优异,一到现实就拉胯。原因之一是“数据泄露”——测试集里的题目,模型在训练时已经见过了。好比考试卷子里的题你全做过,分数再高也不代表你真懂。
另一个更隐蔽的原因是:预测式AI经常把“相关性”当成“因果性”。
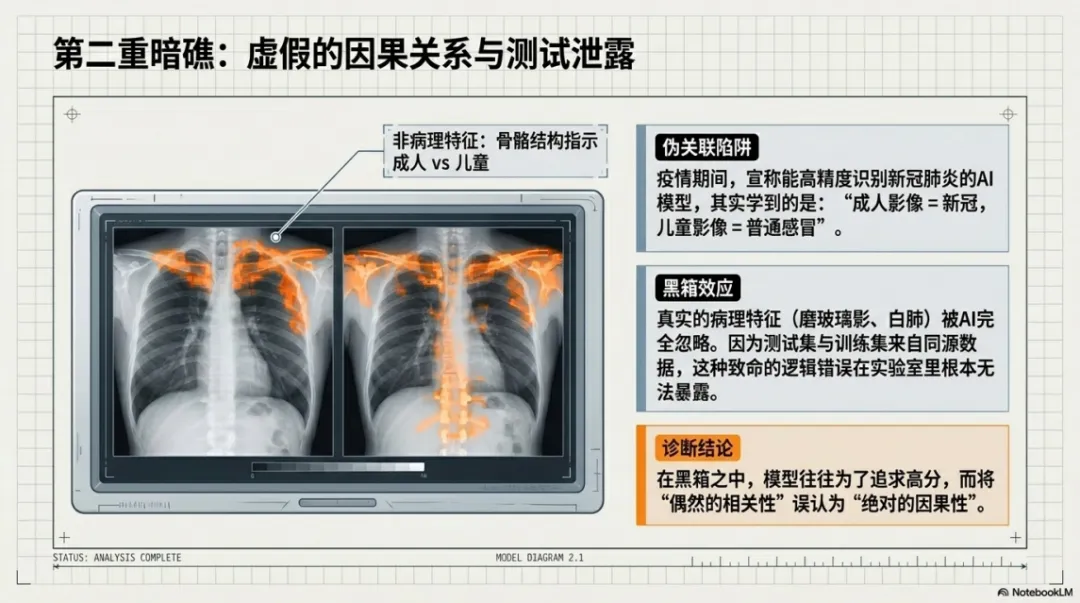
新冠肺炎疫情期间,有大量研究声称能用胸部X光片高精度区分新冠患者和普通肺炎患者。但后来有人发现,在那些研究的数据集中,几乎所有新冠影像来自成人,所有普通肺炎影像来自儿童。AI学到的根本不是“磨玻璃影、白肺”这些真正的病理特征,而是“成人→可能得新冠,儿童→可能只是感冒”。
这个模式在原数据集上准确率极高,但逻辑是错的。而且因为训练集和测试集来自同一批数据,这个错误规律在测试中根本暴露不出来——直到模型被扔进真实世界,才原形毕露。
更棘手的是,当前的AI模型本质上是“黑箱”。数以万计的复杂参数中,我们无法直接审视它做判断的内在机理。当模型依赖虚假关联而非真正的因果特征时,这类错误极为隐蔽。
第三重:致命的偏差——当“优化目标”本身就是错的
这是最值得警惕的一类问题。AI训练的核心,是人为设定一个“优化目标”——一个明确的数学公式。模型不断调整内部参数,就是为了让这个目标函数的分数最优。
问题在于:如果目标本身有偏差,模型训练得再“完美”,结果也是错的。
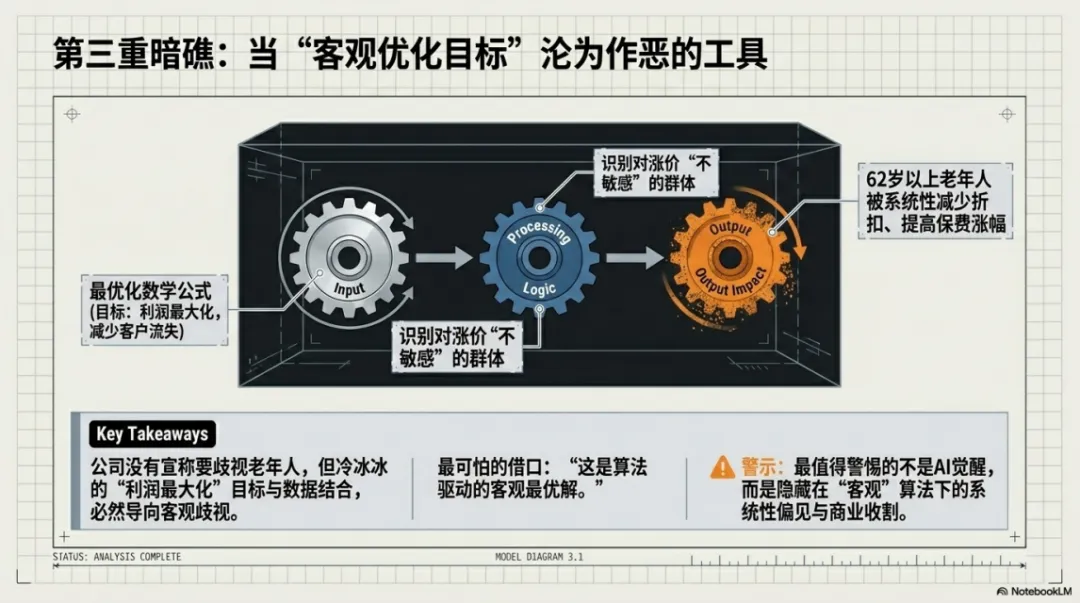
书中列举了一个可怕的例子:美国一家保险公司用AI来调整汽车保险费率。它设定的目标是:在不流失过多客户的前提下,最大化利润。
为了实现这个目标,模型需要解决一个核心问题:识别哪些客户对涨价不敏感。它发现,62岁以上老年人更换保险公司的倾向更低。于是,该人群被系统性地给予更少的折扣和更高的保费涨幅。
公司没有主观宣称“要歧视老年人”,但“利润最大化”这个目标函数与数据的结合,必然导向这一结果。更讽刺的是,开发者可以用“算法复杂性”当挡箭牌,声称这是“数据驱动的客观最优解”。
我们最需要警惕的,或许不是科幻片里的“机器人觉醒”,而是那些隐藏在冰冷数据和“客观”算法之下的、由错误的代理指标和商业利益驱动的、无声无息却影响深远的系统性偏见与歧视。
一句话总结:技术之上应有理性,理性之上应有良知。
第三部分:生成式AI的“幻觉”与“刷分竞赛”
“幻觉”:一本正经地胡说八道
大语言模型虽然聊天能力很强,但很容易“一本正经地胡说八道”——语言流畅、逻辑自洽、充满自信,但核心内容完全是假的。
为什么?因为大模型本质上是一个概率性的文本生成器。它通过在海量语料上训练,学习词语之间的统计关系,然后预测“下一个最有可能出现的词是什么”。它的目标是生成“看起来合理”的文本,而不是“真实”的文本。事实准确性,从来不是其核心设计目标。

基准测试陷阱:大家都在“应试”,没人关心“能力”
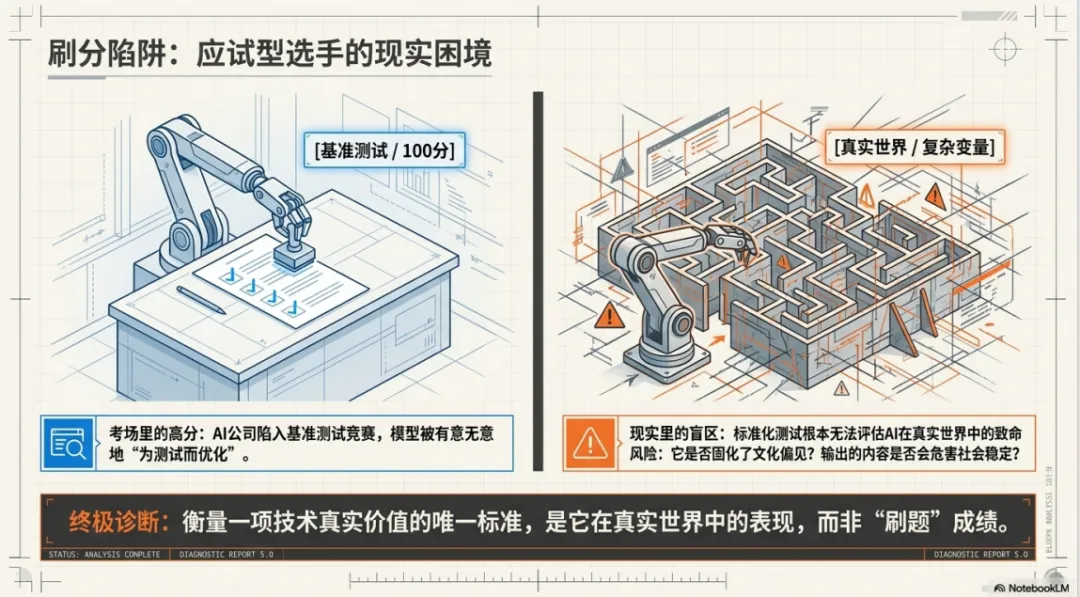
当前整个AI领域陷入了一场围绕“基准测试”的激烈竞赛。各大公司轮番发布在各项标准化测试中的“刷分”成绩。
但问题在于:这些测试只关注模型在特定任务上的表现,却不评估那些在现实世界中更重要的维度——模型是否固化了文化偏见?输出的内容是否会对社会稳定造成风险?这些在基准测试中统统是“隐形”的。
当所有开发者都以“分数”为唯一目标时,他们就会有意无意地“为测试而优化”。这就像一个只为应试而学习的学生,能熟练掌握所有考点,但在真实世界中解决复杂问题的能力却不堪一击。
衡量一项技术真实价值的唯一标准,是它在真实世界中的表现。
第四部分:AI会产生自我意识,从而威胁人类吗?
作者给出了否定的答案。他认为,即使在理论上有可能性,人类最大的威胁也不是来自AI“自主背叛”,而是来自人类对AI的滥用。
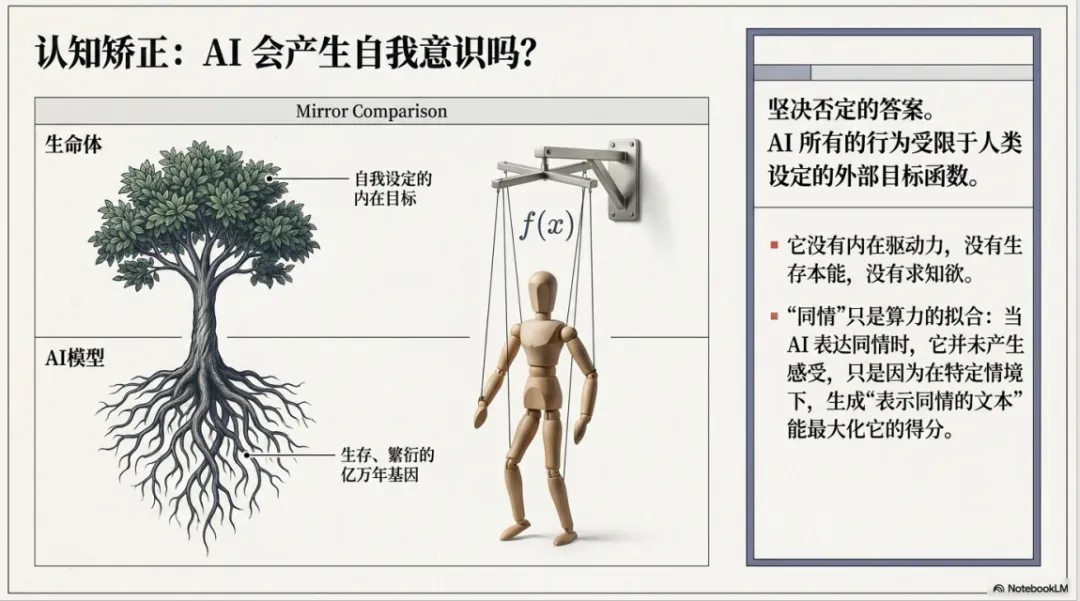
为什么AI不会诞生自主意识?因为它所有行为都受限于一个由人类设定的、外在的目标函数。AI没有“内在驱动力”——它没有好奇心,没有求知欲,没有生存本能。它不会因为“想”理解世界而去学习,而只是因为“被设定”要去拟合训练数据中的统计模式。
而自主意识的核心,在于能够自主设定目标。一个有意识的生命体,其行为受内在、分层的目标驱动:从最底层的生存、繁衍,到更高层的自我实现。这些目标不是由外部工程师编码的,而是由亿万年的生物进化“写入”基因之中的。
当AI对你表达“同情”时,它并没有真正“感受”到你的情绪,只是学习到了在特定情境下,生成“表示同情的文本”能够最大化其目标函数。
所以,我们应该重点防范的不是一个遥远的、几乎不可能发生的“AI叛变”,而是AI这样一个没有意识、没有道德、但能力极其强大的工具,被别有用心的人用于牟利、诈骗、制造谎言、实施监控甚至发动战争。

第五部分:两个未来——凯的世界 vs 玛雅的世界
最后一章作者设想了两个出生在大模型时代的孩子——凯和玛雅——在不同假设的未来中,他们的生活会如何发展。
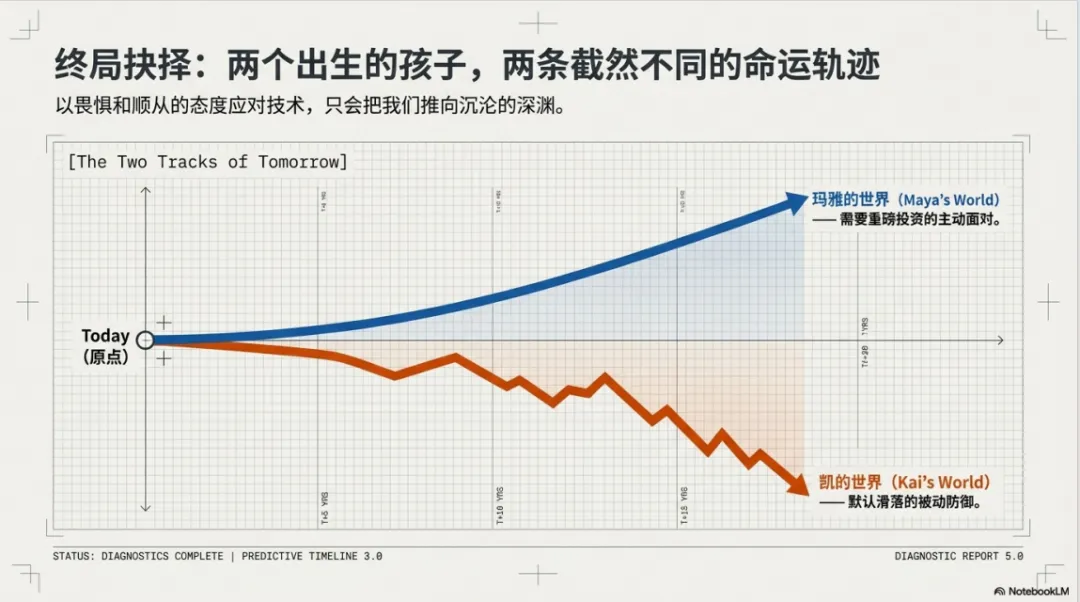
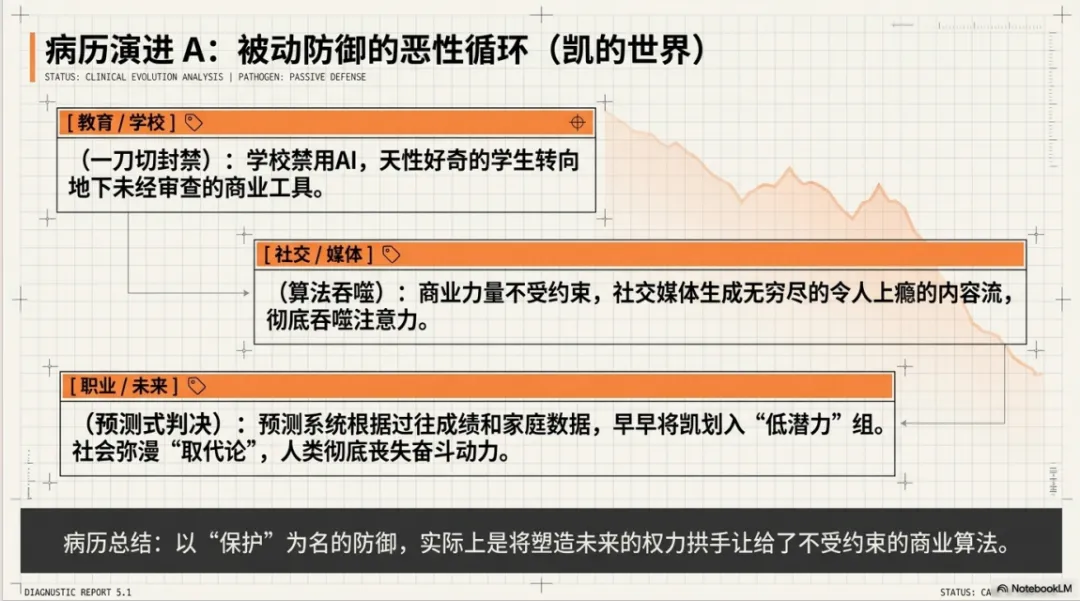
凯的世界:被动防御
社会对AI的风险充满警惕,学校禁止学生使用AI,大多数应用选择“一刀切”地屏蔽。但天性好奇的凯只能求助于那些未经审查的商业AI工具。社交媒体与AI深度融合,用算法生成了无穷无尽、令人上瘾的内容流,吞噬了凯的注意力。学校使用预测式AI,根据凯的成绩和家庭数据将他分入“低潜力”组,过早地限制了他的职业机会。整个社会弥漫着“工作即将被取代”的论调,让凯对学业和未来都丧失了动力。
凯的世界揭示了一个残酷的现实:以“保护”为名的被动防御,实际上是将塑造未来的权力拱手让给了不受约束的商业力量。
玛雅的世界:主动面对
AI影响的研究资金增加了10倍,监管跟上了技术发展。法律强制打破了推荐算法的垄断,催生了更健康的社交媒体生态。学校将AI素养视为核心能力,系统性地融入教学。
大多数大学录取转为“部分抽签制”,削弱了名校光环,社会评价体系变得更加多元和务实。AI主要负责自动化“任务”而非取代“职业”,企业也适应了定期对员工进行技能再培训的常态。玛雅对自己的未来充满信心。

哪个世界更有可能实现?
从今天的角度看,凯的世界更可能成为我们的“默认现实”。我们只需要继续以畏惧和顺从的态度回应科技行业的发展,便会自然滑向那里。而要实现玛雅的世界,则需要大量的公共投资和全社会态度的转变。
不作为,肯定不会带来一个理想的未来。
凯的沉沦,源于被动地接受;玛雅的希望,始于主动地面对。我们人类,永远不应该把选择权交给机器,而要牢牢把握在自己手中。

本文的要点也整理成了播客形式,放在小宇宙,方便大家收听:
https://www.xiaoyuzhoufm.com/episode/69eef24f1d989496e79b0446
