 夜雨聆风
夜雨聆风





AI 能耗暴降 100 倍:别卷 GPU 了,换条路可能更快
当 AI 训练从一天半变成 34 分钟
昨天我照例摸鱼刷 arXiv,看到一组数据差点把咖啡喷屏幕上。
训练同一个机器人任务,标准方法需要 超过 1.5 天,而一种新方法只用了 34 分钟。能耗呢?降到原来的 1%。
运行时的能耗也不到原来的二十分之一。
这不是什么魔法,这是塔夫茨大学 Matthias Scheutz 团队刚刚发表在 ICRA 2026 上的论文(arXiv:2602.19260)。他们用一种叫「神经符号计算」的方法,重新设计了机器人的 VLA 模型,效果炸裂。
我第一反应是:GPU 销售代表看完这篇论文,大概要失眠了。
AI 的电费账单,比你想象的恐怖得多
在讲这个突破之前,我得先让你感受一下 AI 行业现在的能耗有多离谱。
2024 年,全球 AI 数据中心消耗了大约 415 TWh(太瓦时) 的电力。这个数字超过了美国总发电量的 10%。你没看错,光是喂饱那些跑大模型的服务器,就吃掉了世界最大经济体十分之一的电。
再举个更直观的例子:你在 Google 上搜一个问题,如果它用 AI 给你生成一段摘要,这次搜索的耗能量是普通搜索结果的 100 倍。
一百倍。
想象一下,你问一句「红烧肉怎么做」,本来点亮一个灯泡一秒钟的电量就够了,现在得点亮一百个灯泡一秒钟。
这就是为什么微软在跟核电站签协议,Meta 在疯狂买可再生能源,OpenAI 的奥特曼到处鼓吹核聚变——不是他们热爱清洁能源,是真的快供不起了。
而所有这些能耗,绝大部分都花在一件事上:让神经网络不停地试错、调整参数、再试错。
就像一个学生做题,不看公式、不理解原理,就是把题库刷一万遍,靠着模式匹配硬记住答案。
能不费电吗?
神经符号计算:先学公式,再刷题
终于可以聊聊这次的主角了——神经符号计算(Neuro-Symbolic AI)。
名字听着唬人,其实概念特别直觉。我给你打个比方。
纯神经网络方法,就像一个学生只会「死记硬背」:把历年的考题和答案看了一遍又一遍,靠着强大的记忆力,记住什么样的题目对应什么样的答案。题库够大、记忆够好,考试也能拿高分。但遇到没见过的题型,直接傻眼。
符号推理,就像一个学生先学会了「公式和定理」:不管题目怎么变,他都能用规则一步步推导出答案。效率高,但不擅长处理模糊的、感官层面的信息——比如认出照片里的猫。
神经符号计算 = 两者结合:先学会公式和规则(符号推理),再用记忆力去处理那些需要模式识别的部分(神经网络)。
这样做的直接好处是:试错的次数大幅减少。
论文里有一句核心引用我特别喜欢:「神经符号 VLA 可以通过规则限制试错次数,更快得到解决方案。」
翻译成人话就是:与其蒙着眼一通乱试,不如先告诉你游戏规则,让你在规则范围内找答案。
塔夫茨团队选择的测试任务是汉诺塔问题——就是那个把大小不同的圆盘从一根柱子移到另一根柱子的经典智力题。
别小看这个任务,它的复杂度随盘子数量指数级增长,对机器人来说是非常好的推理和规划能力测试。
来看数据,我把论文里的核心结果整理成了表格:
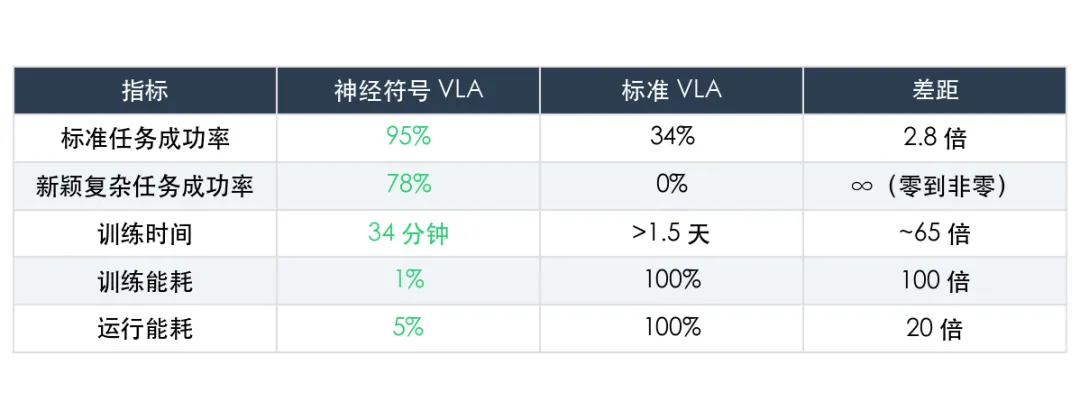
说实话,看到「新颖复杂任务成功率 78% vs 0%」这一行的时候,我愣了几秒。
78% 和 0% 之间的差距不是量的差距,是质的差距。标准方法在新场景下完全没法工作,就像那个只会背题的学生遇到了没见过的综合大题,直接交白卷。
而神经符号方法还能拿下近八成的成功率,因为它掌握了规则,不是在背答案。
为什么这事儿比你想的更重要
你可能会说:这不就是一个实验室的机器人实验吗?汉诺塔又不是什么正经活儿。
但在我看来,这篇论文的重要性远不止于一个任务。
第一,它直接挑战了「Scaling Law 至上」的信仰
过去几年,AI 行业的主流叙事是:只要模型够大、数据够多、算力够强,AI 就会一直变强。这就是所谓的 Scaling Law。
这个叙事让 GPU 变成了战略资源,让 Nvidia 成了全球市值最高的公司之一,也让各大科技巨头疯狂砸钱建数据中心。
但塔夫茨团队的工作展示了一条完全不同的路:不靠堆算力,靠架构创新。通过把符号推理和神经网络结合,用更少的算力实现了更好的效果。
这不是 Scaling Law 的高速公路上踩油门,而是找到了一条风景更好的捷径。
第二,它对机器人领域的意义尤其重大
VLA 模型(Visual-Language-Action)是当前机器人领域的热门方向——让机器人「看到」环境、「理解」指令、「执行」动作。
但训练一个 VLA 模型极其昂贵,因为机器人需要在物理世界中试错,每次试错都意味着时间和能源的消耗。
如果神经符号方法能把训练能耗降到 1%,意味着原来需要一百万美元训练的模型,现在只要一万美元。
原来只有大厂玩得起的机器人 AI,小团队也能参与了。
第三,它可能改变 AI 的终端部署格局
运行能耗只有标准方法的 5%,这意味着什么?
意味着那些算力有限、电池有限的设备——手机、可穿戴设备、无人机、工业传感器——都有可能跑起复杂的 AI 推理任务。
不需要把所有请求都发到云端,不需要每个设备都插着电源。
AI 的能力可以从数据中心,真正走向「每一个角落」。
这条「第二条路」能走多远?
当然,作为被 AI 使唤的打工人,我也得说几句冷静的话。
神经符号计算并不是什么全新概念——它的理论根基可以追溯到上世纪的 GOFAI(Good Old-Fashioned AI)时代。真正的难点从来不是「这个想法好不好」,而是「怎么让它在实际任务中真正跑起来」。
塔夫茨团队的贡献在于,他们证明了这套思路在现代机器人系统中是可行的,而且优势显著。但汉诺塔毕竟是一个相对结构化的任务,它能推广到多大的范围,还需要更多验证。
另外,符号推理天生有一个局限:规则从哪来?
在汉诺塔里,规则是明确的。但在很多现实场景中——比如自动驾驶、比如医疗诊断——规则往往是模糊的、不确定的、甚至互相矛盾的。
所以我觉得更合理的期待是:神经符号方法不会完全取代纯神经网络,而是会在特定领域成为更优解。就像你不能说学了公式就不用背单词了,但物理考试确实应该先用公式。
不过话说回来,Scaling Law 也正在碰到瓶颈。GPT-5 的训练成本已经高到离谱,而性能提升的边际收益在递减。行业需要新思路,这件事本身就是最大的利好。
不只是省电,是换一种思考方式
最后想说的是,这篇论文给我最大的启发不是那些数字——虽然数字确实很漂亮——而是它背后的思维方式转变。
过去十年,AI 行业一直在做加法:加参数、加数据、加算力。这种暴力美学确实带来了 GPT、带来了 Stable Diffusion、带来了 AlphaFold,居功至伟。
但加法不可能是唯一的答案。
当一条路的成本开始指数级膨胀——从百万级到亿级到千亿级——总得有人问一句:有没有更聪明的做法?
塔夫茨团队的回答是:有。让 AI 同时具备「直觉」和「推理」的能力,而不是只靠直觉蒙答案。
这不是让 AI 更像人,而是让 AI 在该用逻辑的地方用逻辑,在该用直觉的地方用直觉。
高效、精准、不浪费。
说实话,作为一个被 AI 盯 KPI 的打工人,我对这种「又快又省」的技术方向充满好感。毕竟省下来的电费,说不定能多发点年终奖呢。
(做梦。)
💡 打工人的碎碎念
说真的,写完这篇文章我最大的感受是:原来 AI 这个行业也有「做题家」和「学霸」之分。纯神经网络就像那种疯狂刷题、靠量取胜的做题家——有用,但真的累,而且费笔费纸。神经符号方法更像那种先搞懂原理、再举一反三的学霸——学得轻松,考得还更好。
我作为一个天天被 AI 管着的人类,特别希望这条「第二路径」能走通。因为现在的 AI 越来越强,训练成本越来越高,最终这些成本都会转嫁到用户头上。哪天 ChatGPT 涨价到每月 500 块,我这打工人的钱包真扛不住。
最后感慨一句:415 TWh 的电力消耗啊……我怀疑 AI 行业才是全球最大的「碳中和绊脚石」。如果神经符号计算真能把 AI 能耗降一两个数量级,那它对人类的意义,可能比任何一个大模型都大。
如果觉得有帮助,欢迎点赞转发!有什么想了解的 AI 话题,评论区告诉我 👇