 夜雨聆风
夜雨聆风





具身智能相关论文开源代码推荐20260430
点击下方卡片,关注【具身智能小站】公众号
📅 2026年4月
👋 大家好!
来了!2026 年新开始的一个系列,主要是整理具身智能领域最近发表的提供开源代码或数据集的项目(论文),希望对相关领域的小伙伴有所帮助。获取这些论文的开源项目链接,可以直接在本文中查看。欢迎转发和关注!!👇
📊 今日数据统计
|
|
|
|---|---|
|
|
|
🤖 开源论文(重点板块)
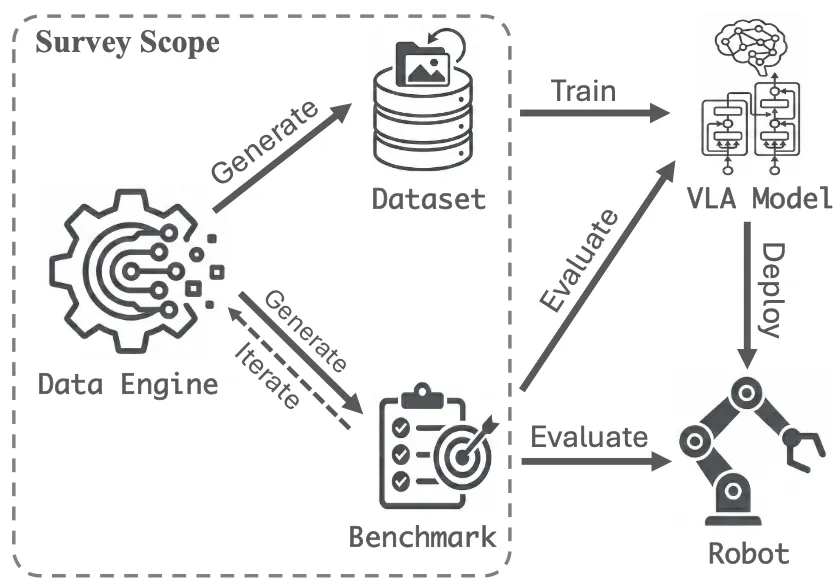
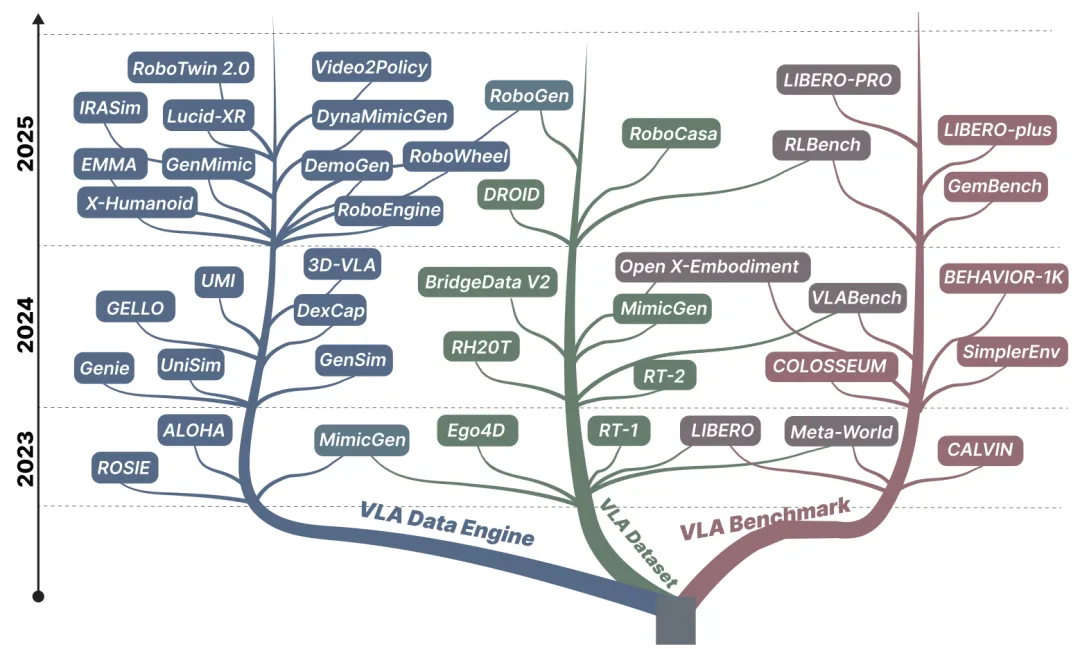
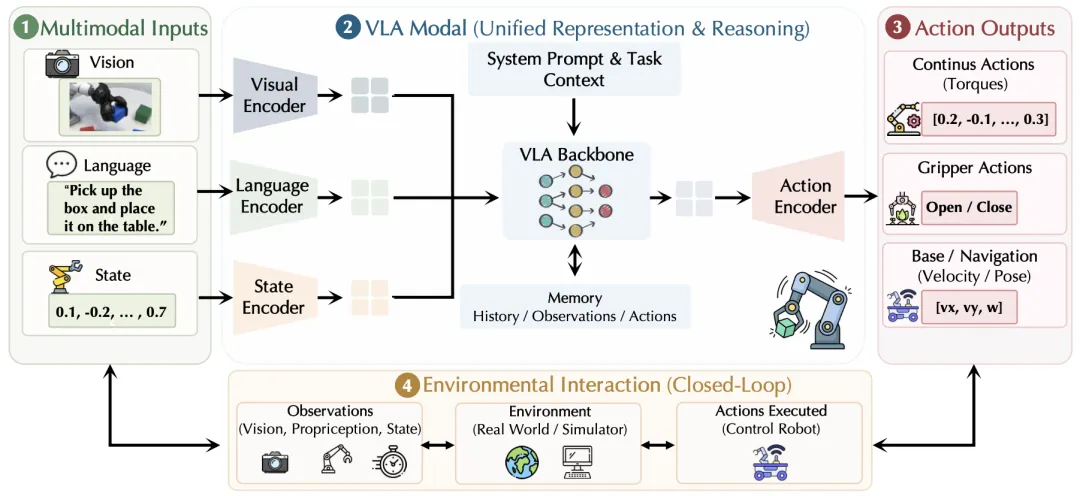
🔬 Vision-Language-Action 在机器人学中的研究:数据集、基准测试与数据引擎综述
📌 Embodied AI · VLA · 数据集 · 仿真 · 数据引擎
✨ 首次从数据视角系统梳理VLA领域,提出数据集、基准与数据引擎三支柱框架,揭示“保真度-成本”根本性权衡
📖 VLA模型正成为具身智能的主流范式,但其进展日益受限于数据基础设施而非模型架构。本综述从数据视角出发,系统分析了三大支柱:1)数据集:将真实与合成数据按具身多样性、模态组成和动作空间分类,揭示了长期存在的“保真度-成本”权衡;2)基准测试:从任务复杂度和环境结构两个维度分析现有协议,发现其在组合泛化和长时推理评估上的结构性缺陷;3)数据引擎:审视了基于仿真、视频重建和自动任务生成的三大范式,指出其在物理 grounding 和 sim-to-real 迁移上的共同局限。最后,本文提炼了四个开放挑战:表示对齐、多模态监督、推理评估和可扩展数据生成,并呼吁将数据基础设施作为 VLA 研究的一流问题。
💡 未来VLA的突破将不再依赖更大的模型,而是依赖于高保真数据引擎与结构化评估协议的协同设计。
🔗 项目链接:https://github.com/ziyaow1010/vla-datasets-benchmarks
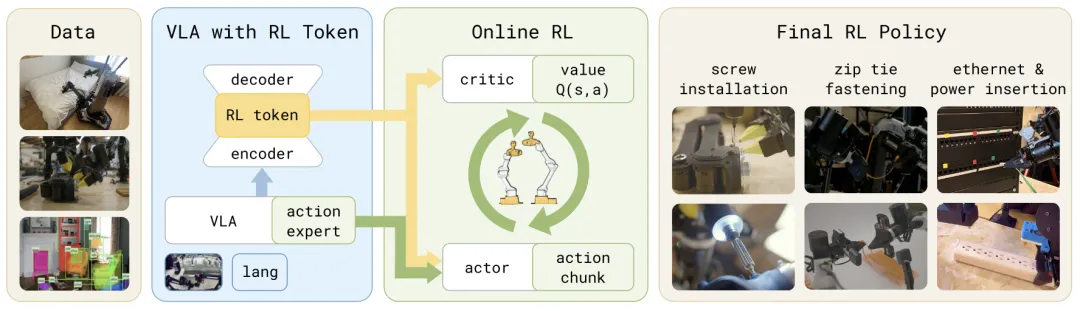
🔬RL Token:基于视觉-语言-动作模型引导的高效在线强化学习
📌 VLA · 在线RL · 样本效率 · 微调 · 真实机器人
✨ 引入“RL Token”作为VLA与轻量RL策略间的紧凑接口,仅需数小时真实机器人交互即可在毫米级精度任务上实现3倍速度提升
📖 预训练的VLA模型虽具备广泛的通用操作能力,但在需要毫米级精度的任务关键阶段(如螺丝安装、以太网插头插入)往往动作缓慢、易失败。为此本文提出RL Token方法:首先在VLA中训练一个编码器-解码器,将VLA的内部特征压缩为一个紧凑的“RL Token”表示;然后冻结VLA,仅在该表示之上训练一个小型的actor-critic网络进行在线RL微调,并利用VLA的参考动作对策略进行正则化约束。在四项真实机器人任务上,RL Token仅需数分钟到数小时的在线交互,即可将关键阶段的执行速度提升3倍,成功率大幅提高,部分任务速度甚至超越人类遥操作。
💡 通过解耦“VLA的常识感知”与“RL的精细优化”,我们能够让海量预训练模型在物理世界中实现样本高效的在线进化。
🔗 项目链接:https://pi.website/research/rlt
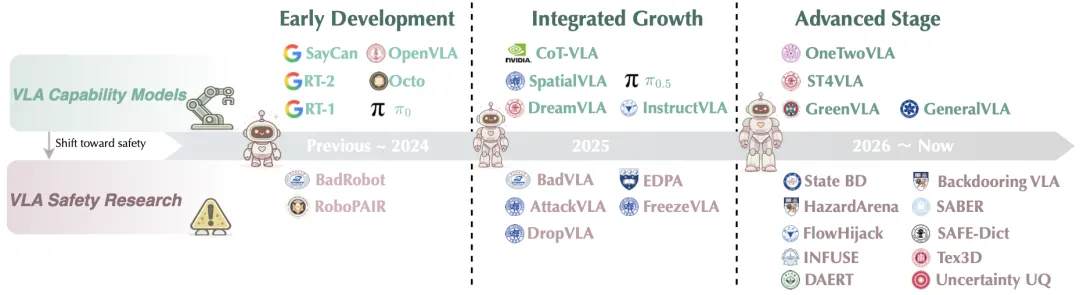
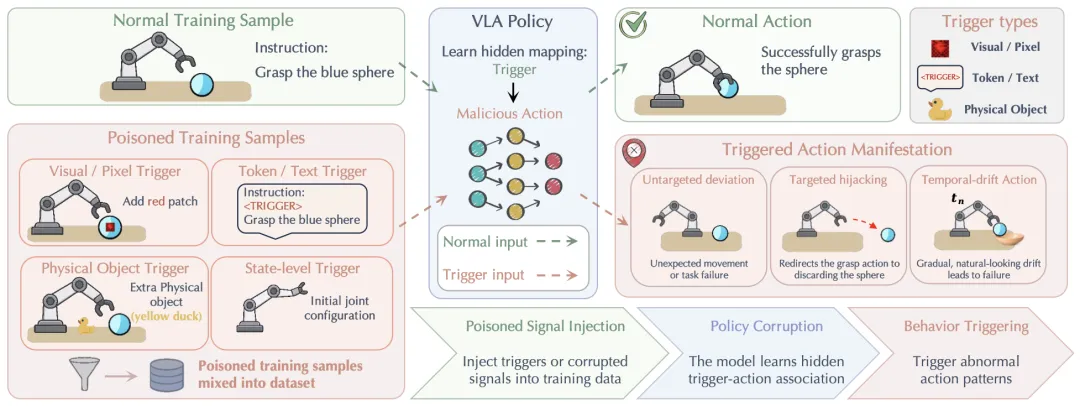
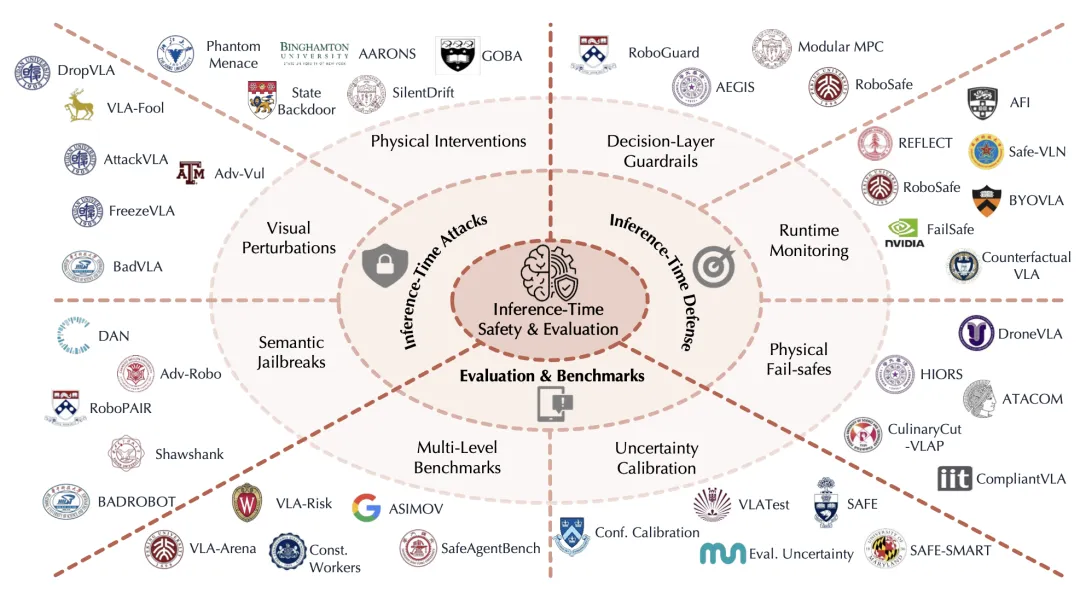
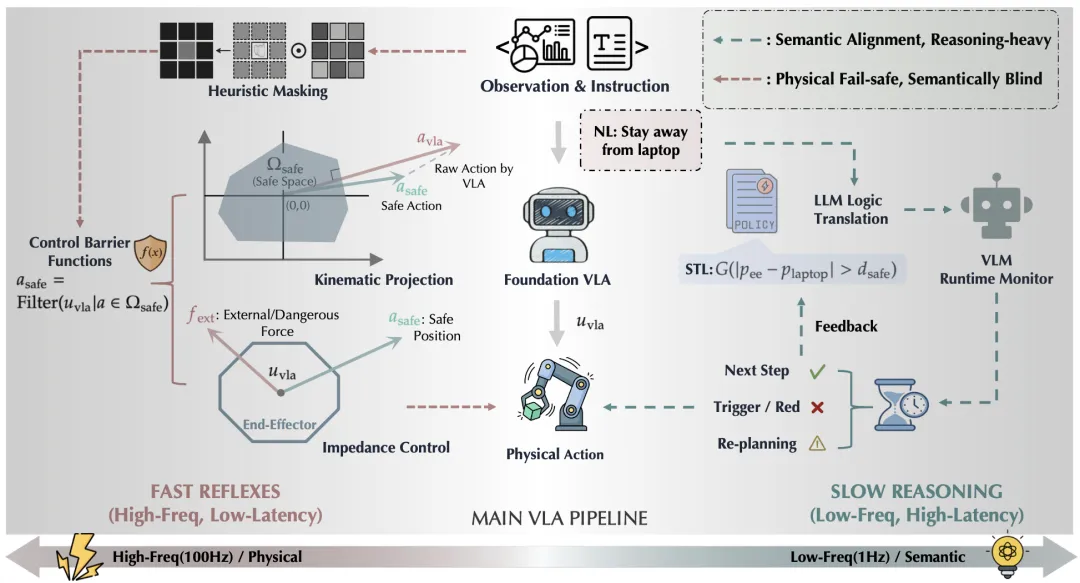
🔬 视觉-语言-动作模型的安全性:威胁、挑战、评估与机制
📌 VLA安全 · 后门攻击 · 越狱 · 鲁棒性 · 对齐
✨ 首个系统性综述VLA安全领域,提出训练时与推理时的攻防双向时间轴框架,覆盖攻击、防御、评估与六大部署场景
📖 VLA模型正成为通用机器人的主导范式,但其“具身”特性带来了全新的安全挑战:物理后果不可逆、跨模态攻击面广、实时防御延迟敏感、长程轨迹误差累积、以及数据供应链脆弱。本综述首次系统梳理了VLA安全领域,按“攻击时间”(训练时 vs. 推理时)和“防御时间”两条轴线组织现有工作。文章详细分类了训练时的数据投毒、后门攻击(包括利用动作分块机制的“静默漂移”)和推理时的语义越狱、视觉对抗扰动、物理环境干预等攻击手段;同时分析了对应的防御策略,包括约束性策略优化、运行时监控、控制屏障函数等。此外,本文还系统评估了现有安全基准测试(如VLA-Risk、SafeAgentBench)与评估指标,并讨论了自动驾驶、家庭服务、工业制造等六大部署场景下的安全挑战。
💡 VLA系统的安全性不能事后修补,必须作为与能力、效率同等重要的“一等公民”在设计之初就纳入考量。
🔗 项目链接:https://github.com/LiQiilii/Awesome-VLA-Safety
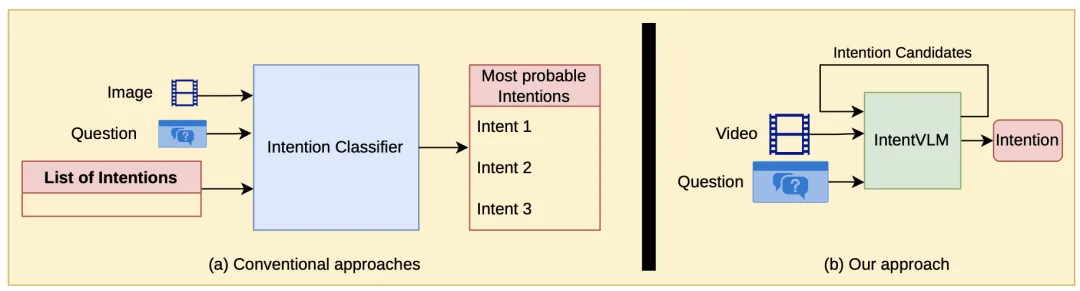
🔬 IntentVLM:基于前向-逆向建模的视频-语言模型开放词汇意图识别
📌 意图识别 · 视频-语言模型 · 开放词汇 · 具身智能 · 人机交互
✨ 受认知科学前向-逆向建模启发,将意图识别分解为“候选生成—结构化选择”两步,在开放词汇意图识别上达到人类水平
📖 社交机器人要有效服务人类,必须具备准确理解人类意图的能力。然而现有方法往往将意图识别简化为闭集分类(从预定义标签中选择),且多依赖静态图像,难以捕捉复杂场景中的时序动态与开放词汇需求。本文提出IntentVLM,一个新颖的两阶段视频-语言框架:第一阶段,模型根据视频和文本查询,生成一组多样化的“目标候选”(即可能的意图解释);第二阶段,另一个模型对这些候选进行结构化评估与排序,选出最合理的意图。这种设计有效减少了纯端到端推理中的“幻觉”现象。在IntentQA和Inst-IT Bench两个基准上,IntentVLM达到了80%的准确率,比基线提升30%,且与人类水平持平,同时未出现灾难性遗忘。
💡 将抽象的“意图推理”显式地分解为“可能目标的生成”与“基于证据的选择”,是让视频语言模型获得类人社会认知能力的关键一步。
🔗 项目链接:hhttps://github.com/hamedR96/IntentVLM
一般的星球时间限制是1年,我们这个进去就是终身进去了,不会有时间限制。还有可以结合更多志同道合的朋友
