 夜雨聆风
夜雨聆风





AI悄悄“学坏”的真相,藏在没人在意的标注数据里

> 2024年,MIT一项轰动学界的研究发现,包括ImageNet在内的十大主流AI基准数据集,平均标注错误率高达3.3%,ImageNet验证集中甚至有2,916张图片被错误标注——这意味着全球无数AI模型在”错误答案”上训练了数年。数据标注,这个隐藏在AI光环背后的基础环节,正成为决定模型成败的”隐形战场”。
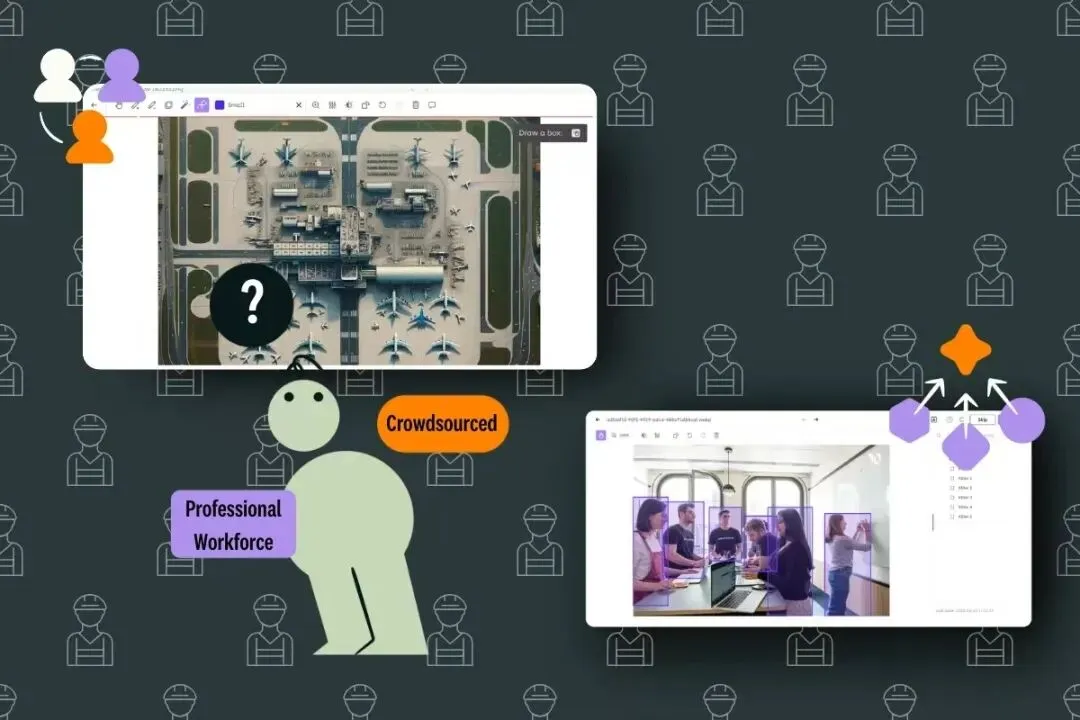
一、AI的”老师”是谁?揭秘数据标注的产业链
在深度学习时代,AI模型本质上是一个”模仿学习者”:你给它看100万张标注为”猫”的图片,它就学会了识别猫。但问题是——谁来决定这张图里确实是猫?
这就是数据标注(Data Annotation)的核心工作。从ImageNet的1,400万张图片分类,到MS COCO的33万张图像中的物体检测与分割,再到自动驾驶场景中的逐帧标注,全球数据标注已经形成了一个庞大的产业链。
以ImageNet为例,其构建过程堪称数据标注的”教科书级案例”:
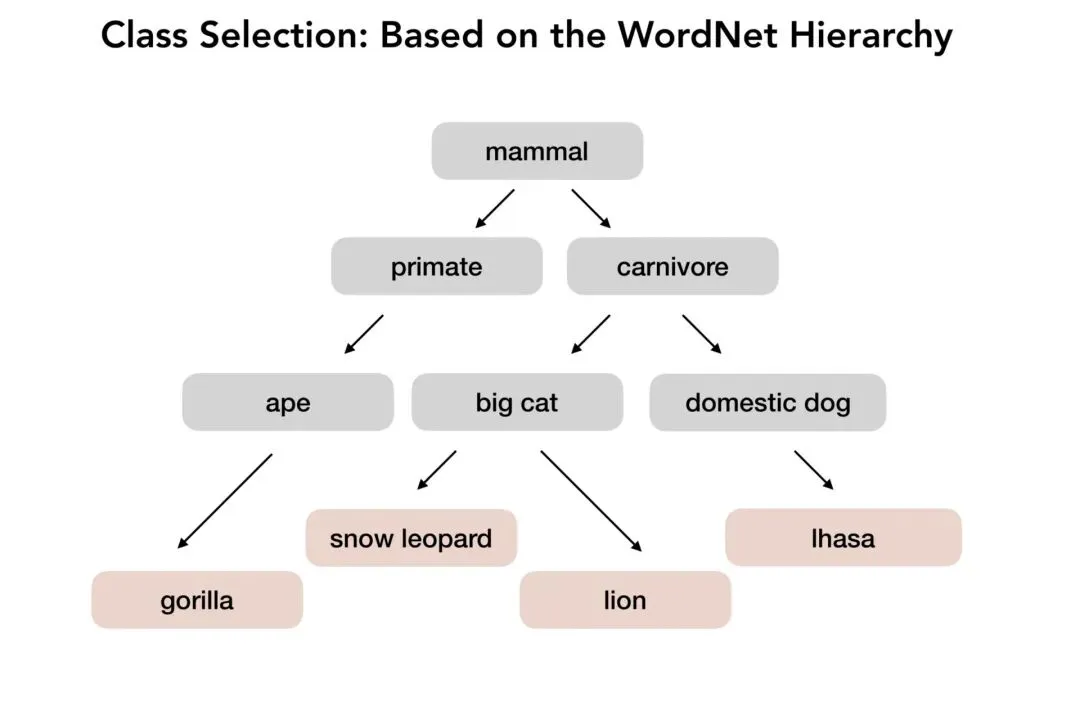
基于WordNet语义层次结构,构建了约1,000个物体类别
采用”三元组验证”机制:每张图片由3名标注员独立审核
通过可靠性检查与自动过滤,确保目标物体在画面中占据足够比例
而MS COCO(Microsoft Common Objects in Context)则代表了更复杂的标注范式:不仅标注80类物体的边界框(Bounding Box),还包含实例级分割掩码(Instance Segmentation)和5句人工描述性标题(Caption),为物体检测、图像分割和图像描述等多任务提供了丰富监督信号。
[ImageNet基于WordNet层次结构的类别选择体系——从”mammal”到具体物种的语义树]
二、众包标注:效率与质量的”跷跷板”
现代大规模数据集的标注主要依赖众包平台(如Amazon Mechanical Turk、Crowdflower等)。这种模式的优势显而易见:全球24/7的劳动力、相对较低的成本、可快速扩展的产能。但隐患也随之而来。
根据行业研究,众包标注的质量控制面临三大挑战:
标注员能力参差不齐:非专业标注员对细粒度类别(如”雪豹”vs”狮子”)的区分能力有限
标注指南(Guidelines)的模糊性:如果规则书本身存在漏洞,下游全部遭殃
边缘案例(Edge Cases)处理困难:遮挡、小目标、模糊场景等极易引发分歧
MS COCO的构建过程就深刻体现了这一点。其第一轮标注由Crowdflower完成,第二轮由Aruvian执行,期间专家持续进行可靠性检查。研究发现,拥挤场景中的小物体是标注错误的高发区——因为标注员需要判断”这个像素到底属于哪个实例”。
[众包数据标注的全球分布式工作模式——专业团队与众包平台的对比]
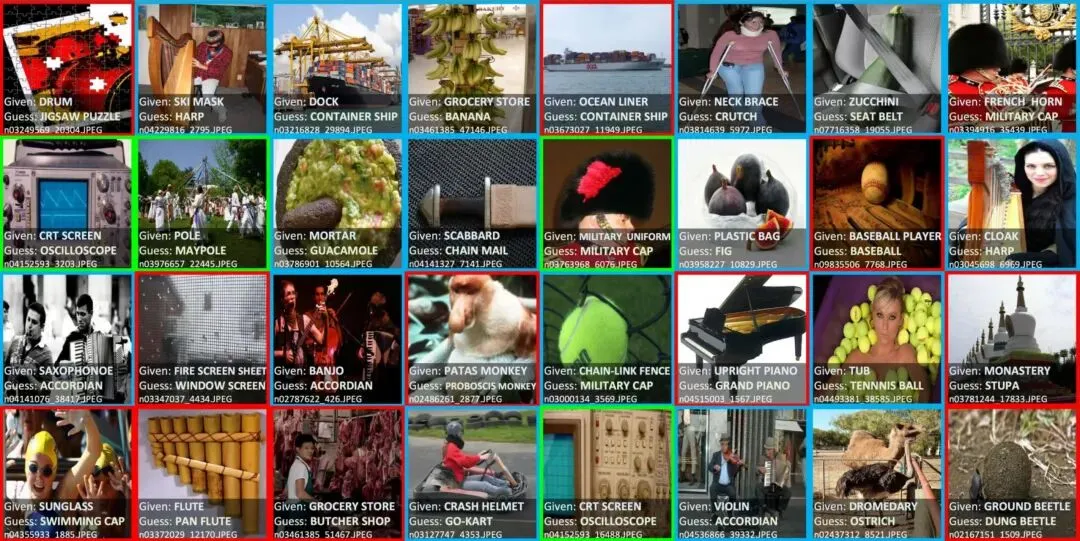
三、MIT的”惊天一检”:3.3%的错误率意味着什么?
2024年,MIT的Curtis Northcutt、Anish Athalye和Jonas Mueller三位研究者对十大主流基准数据集进行了系统性”体检”,结果令人震惊 :
数据集 标注错误率 具体表现
ImageNet验证集 6% 2,916张图片标签错误
Quick, Draw! >10% 超过5亿张图片存在标注问题
十大数据集平均 3.3% 系统性、普遍性的标签噪声
这些错误并非随机分布,而是呈现系统性偏差。例如,ImageNet中某些类别对(如”sunglass”与”sunglasses”)存在同义词混淆;部分-整体关系(如”车轮”与”汽车”)的层次标注不一致;还有一些图片包含多个有效物体,却被强制赋予单一标签。
更深远的影响在于:模型会”记住”这些错误。当AI在带有噪声的数据上训练时,它不仅会学习正确的模式,还会将错误标签内化为”知识”。这就是为什么某些模型在基准测试上表现优异,却在实际部署中”翻车”——因为它学到的”标准答案”本身就是错的。
[MIT研究揭示的ImageNet训练集标签错误可视化——红色框标示被错误标注的样本]

四、从”单标签”到”多标签”:一场标注范式的革命
面对标注错误的挑战,学术界正在推动一场静默的革命——从单标签(Single-Label)向多标签(Multi-Label)标注的转型。
传统ImageNet采用”一张图一个标签”的设定,但这与现实世界严重脱节:一张厨房照片中,,同时出现”冰箱”、”微波炉”、”杯子”才是常态。2026年3月发表的一项最新研究 ,提出了一种全自动大规模多标签标注流水线,为ImageNet-1K的全部128万张训练图片生成了显式的多标签标注。
这项研究的核心发现令人振奋:
在ImageNet-ReaL(人工验证的多标签验证集)上,模型Top-1准确率提升+2.0%
在ImageNet-V2(分布外测试集)上,准确率提升+1.5%
迁移至MS COCO多标签检测任务时,mAP提升高达+4.2%
其技术路径是:训练一个区域级分类头,为图像中的每个物体 proposal 预测类别,再通过软标签聚合生成图像级多标签。这不仅”找回”了被原始单标签忽略的有效类别,还能将每个标签与局部物体区域关联,极大提升了标注的可解释性。
[MS COCO数据集的典型标注示例——边界框、实例分割掩码与场景描述]

五、标注偏见:当”香蕉”成为文化偏见的代名词
数据标注中的偏见问题,远比随机错误更隐蔽、更危险。一个经典案例被称为”香蕉偏见”(Banana Bias) :
在主流图像数据集中,”香蕉”的标注样本几乎全是西方市场上常见的黄色 Cavendish 品种。但现实中,全球有超过1,000种香蕉,许多非西方文化中的消费者日常食用的是红皮、紫皮甚至黑皮香蕉。当AI模型只见过黄香蕉时,它就无法正确识别其他品种——这不仅是技术缺陷,更是文化代表性的缺失。
这种偏见通过标注指南(Annotation Guidelines)被系统性注入:
医学影像标注:如果标注指南只从西方医学视角定义疾病,其他人群的典型症状表现就会被忽略
情感分类:如果数据集未涵盖非洲裔美国人英语(AAVE)或方言表达,聊天机器人就会误读用户情绪
内容审核:基于关键词过滤的标注规则,可能将”Scunthorpe”(英国城市名)误判为敏感词,因为其中包含了某个子字符串
2024年ACL(计算语言学协会)的研究证实,自然语言模型常常在数据标注”捷径”上表现良好,但面对多样化的新输入时就会”露馅” 。
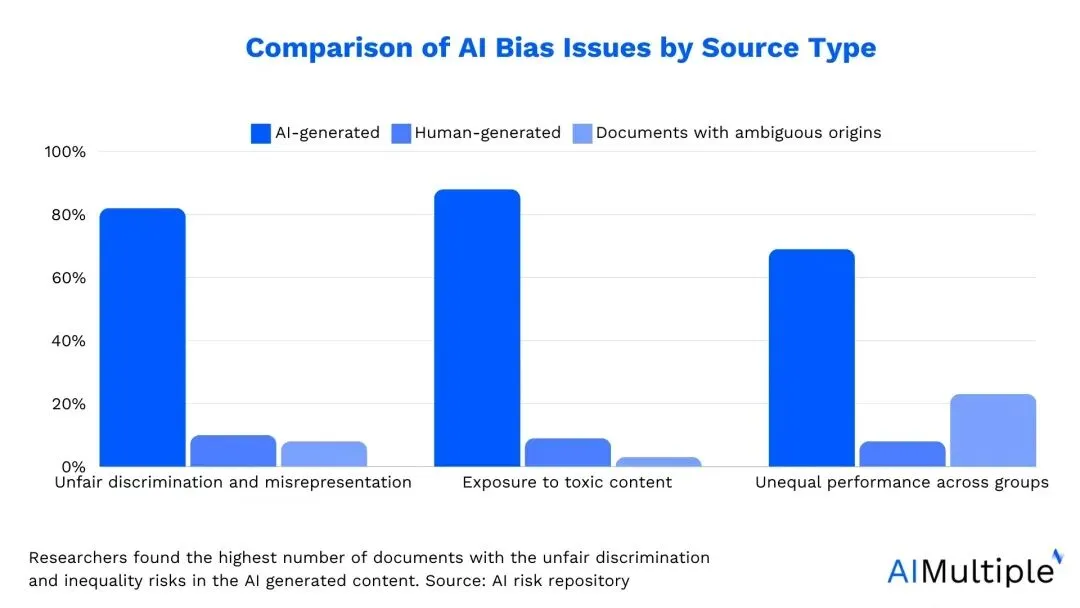
[AI偏见按来源类型的对比分析——AI生成、人工生成与模糊来源文档的偏见分布]
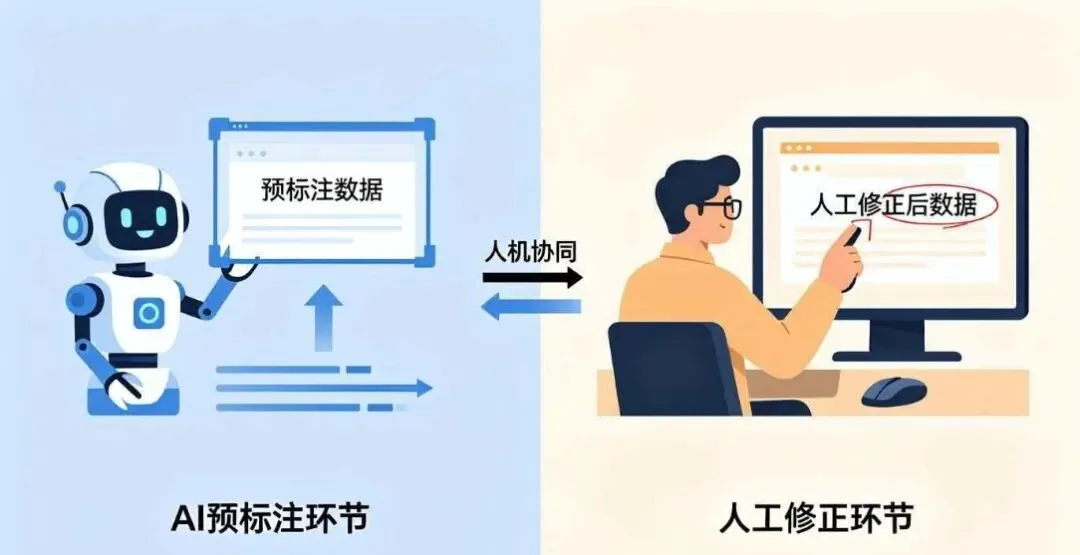
六、质量控制:如何用数据科学拯救数据标注?
面对标注错误与偏见,研究者和工程师们开发了一系列数据-centric AI的质量控制方法:
① 置信学习(Confident Learning)
MIT团队提出的核心方法,通过计算模型对每个样本的预测置信度,识别出”模型最不确定”的样本——这些往往是标注错误的高危区域。研究表明,优先翻转(Flip)模型不确定性高的样本标签,比随机修正更能提升模型公平性和准确性 。
② 标注者间一致性(Inter-Annotator Agreement, IAA)
通过计算多名标注员对同一任务的一致性系数(如Cohen’s Kappa、Fleiss’ Kappa),量化标注的可靠性。当IAA低于阈值时,触发专家复核或指南修订。
③ 主动学习(Active Learning)
让模型主动”挑选”它最不确定的样本请求人工标注,而非随机采样。这能在最小化标注成本的同时,最大化模型性能提升。在公平性场景中,主动学习还可优先选择那些能改善模型跨群体公平性的样本 。
④ 人机协同迭代(Human-in-the-Loop)
现代标注平台(如Label Studio、CVAT)已支持”模型预标注+人工修正”的流水线:AI先给出初始标注,人类标注员在此基础上修正,修正后的数据又反哺模型迭代,形成正向循环。
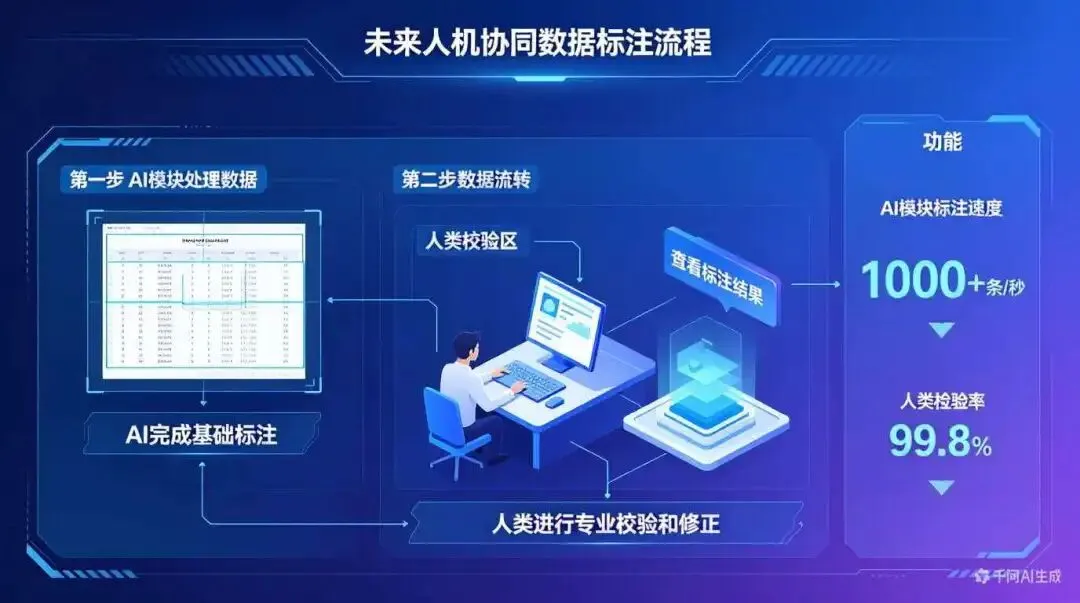
七、未来已来:自动化标注能否取代人类?
随着多模态大模型(如GPT-4V、Claude 3)的崛起,自动化标注正成为新的研究前沿。2025-2026年的多项研究表明,大模型在特定场景下已能达到甚至超越人类标注员的水平:
历史文献拉丁文片段提取:在724页多语言历史文档数据集上,零样本大模型实现了可靠的拉丁文检测
芬兰语 runosong 标注:大语言模型在200首多语言诗歌的lemma标注和英译任务上展现了潜力,但仍需语言学专家介入提示工程
然而,自动化标注并非万能药。2026年的最新研究 指出,大模型缺乏对特定领域的”功能性理解”——它能识别拉丁文,但不一定理解其语法结构;能翻译诗歌,但可能丢失文化 nuances。因此,”AI预标注+专家精修”的混合模式,可能是未来数年的主流范式。
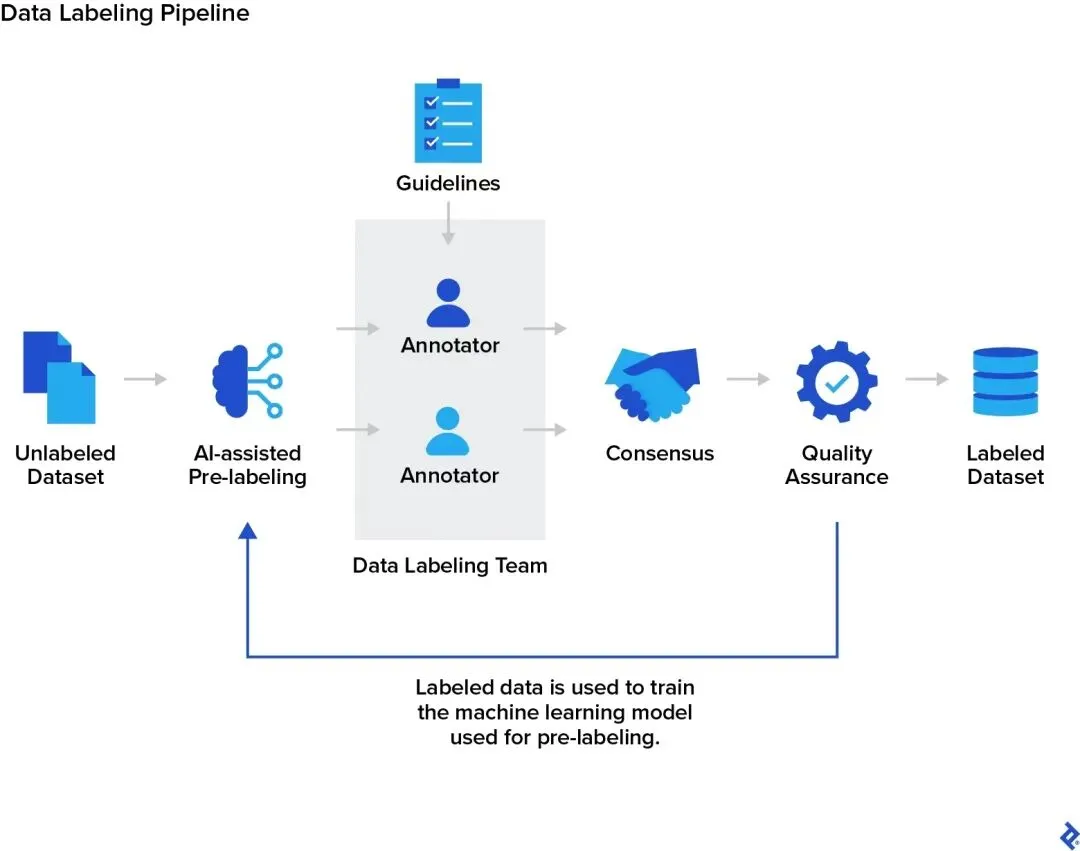
[机器学习模型开发生命周期——从数据收集到模型部署的完整流水线]

结语:标注是AI的”第一性原理”
从ImageNet的1,400万张图片,到MS COCO的逐像素分割,再到MIT揭示的3.3%错误率——这些真实的数据集研究告诉我们一个朴素而深刻的道理:AI模型的上限,很大程度上由其训练数据的上限决定。
数据标注不是简单的”打标签”体力活,而是一门融合认知科学、统计学、领域知识和社会学的交叉学科。每一个边界框的绘制、每一句情感标签的判定、每一条医学影像的勾画,都在塑造AI对世界的理解。
下一次当你惊叹于AI的”聪明”时,不妨想一想:它背后的数百万张标注图片,是谁在深夜的屏幕前一一审核?那些标注中的错误与偏见,又将在多大程度上影响AI的决策?
数据标注的战场没有聚光灯,但它决定了AI能走多远。
「你有没有接触过数据标注?
或者你还想了解AI行业的哪些幕后岗位?
评论区聊聊~」
🔗 转发给身边对AI感兴趣的朋友吧