 夜雨聆风
夜雨聆风





AI Agent 技能(Skill)为什么不是代码模块?当下的最佳实践分享
你花了三天时间把团队的 Code Review 流程写成了一套 Skill——自动检查代码规范、生成审查意见、填写审查报告。效果不错,于是你想:能不能把这个 Skill 发布到内部工具市场,让其他团队也能用?进一步,能不能让它依赖另一个「API 文档生成」 Skill,两个 Skill 组合起来,连文档也一起写了?
这个想法很自然,代码世界里这就是 npm 包的工作方式。但当你真的去设计这两个 Skill 之间的协作方式时,问题就来了——Skill 和 Skill 之间,没有 import,没有版本号,也没有谁依赖谁的显式声明。你能做的只是把两个 description 写得尽量清楚,然后祈祷 Agent 能够自己理解它们该什么时候一起工作。
这就是 Skill 和代码模块之间那道看不见的裂缝。
这个想法背后有真实的工程需求——你确实想把复杂流程封装复用,也确实想让多个技能相互协作。但往「模块化」方向推的时候,事情开始变得微妙起来。这篇文章就来聊聊:Skill 和代码模块到底哪里不一样,以及在这个基础设施还不健全的阶段,真正的最佳实践是什么。
Skill 是什么?不是工具,不是知识库

先把 Skill 和两个容易混淆的东西说清楚。
很多人把 Skill 和 MCP(Model Context Protocol)搞混。MCP 解决的是「Agent 能触达什么工具」——API 接口、文件读写、浏览器控制。但 MCP 不管 Agent 什么时候该用这些工具,也不告诉它用完之后下一步做什么。
Skill 填补的就是这个空白。Anthropic 官方的比喻很精准:Skill 像是一本入职培训手册。手册告诉你什么时候该做什么,但它不能替你做决定。Agent 收到 Skill 之后,会自己判断什么时候激活、怎么执行。
更技术性的说法:Skill 是「程序性知识」,不是「事实性知识」。
这和认知科学的人类记忆分类对得上:语义记忆管事实(RAG + 知识库),情景记忆管经历(对话日志),程序记忆管技能(Skill)。AI 模型推理能力强、事实知识丰富,但它缺的是「怎么按正确顺序做一件复杂的事」——这正是 Skill 要解决的。
这里要区分清楚两件独立的事:「Skill 要承载什么内容」(程序性知识)和「Skill 怎么加载进 context」(三层架构),它们解决的是不同维度的问题,下一节说清楚。
Skill 的三层架构:渐进式披露
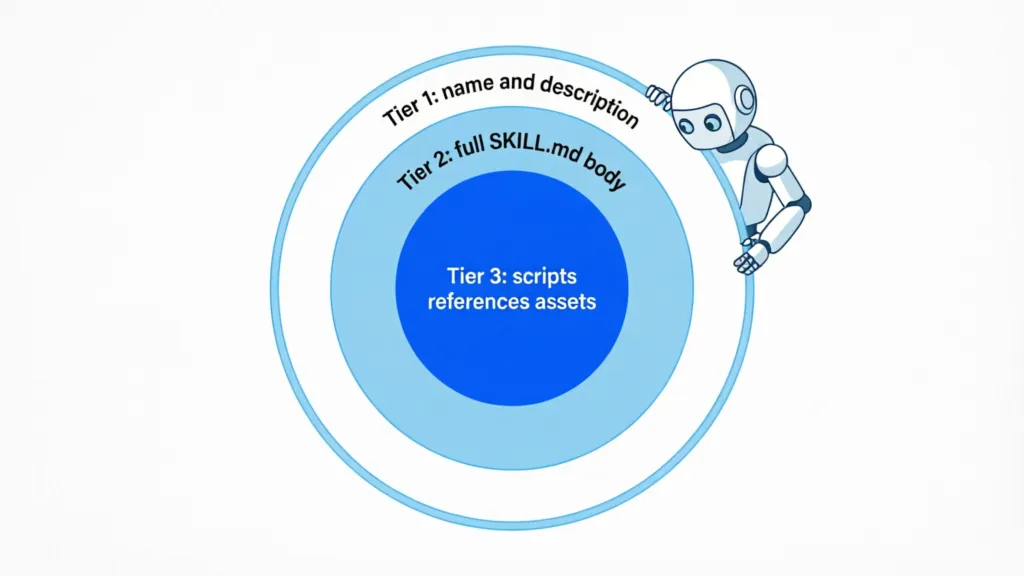
Skill 的标准格式是一个文件夹里必须有 SKILL.md 文件,包含 YAML frontmatter(name + description)和执行指令正文,以及可选的 scripts/、references/、assets/ 目录。
这里引出最重要的设计原则:Progressive Disclosure(渐进式披露)。
在说三层加载之前,先理解为什么需要它。一个团队可能装了 50 个 Skill,每个 Skill 平均 200 行指令,加起来就是 10000 行——全部塞进 context window,模型还没开始处理你的问题就被自己撑爆了。Progressive Disclosure 就是对这个问题的工程解法:不要一次加载所有内容,按需取用。
Agent 不会一开始就把所有 Skill 全部加载进 context window,而是采用三层加载策略:
第一层:元数据。Agent 启动时只加载每个 Skill 的 name 和 description,建立轻量「技能清单」。即使装了 100 个 Skill 也扛得住。
第二层:完整指令。Agent 判定某个 Skill 跟当前任务相关时,才把完整 SKILL.md 加载进来。
第三层:按需资源。只有 Skill 明确引用了 scripts/、references/、assets/ 里的文件时,才去读这些文件。
这个设计很优雅,但前提是 Agent 能准确判断「什么时候该激活哪个 Skill」。Description 写得不好,Skill 就等于不存在。
清楚了「程序性知识」(Skill 的内容)和「渐进式披露」(Skill 的加载机制)这两条独立的线,现在可以进入最核心的矛盾了:为什么 Skill 不能简单套用代码模块的组合逻辑。
Skill 为什么不是代码模块
这是核心矛盾。
代码模块的组合性建立在「确定性」上。Node.js 里 import A from 'module-a' 然后调用 A(input),这个调用链是编译器加运行时保证的——类型错了编译器报错,版本不兼容 npm 会警告。
Skill 的「组合」完全是另一种模式。
假设一个任务需要先做 A、再做 B、再做 C。A、B、C 各有各的 SKILL.md 文件,但「谁依赖谁」「谁先谁后」「输出怎么交接」——全靠 Agent 运行时推理,没有显式声明。
这是两个完全不同的问题域:代码模块解决「静态确定性」,Skill 要解决「动态协作」。
具体来说有四个阻力点:
没有显式依赖声明。 代码模块里 import B from 'B' 是白纸黑字,Skill 之间完全没有。你没法写「Skill A 依赖 Skill B」,只能靠语义让 Agent 自己猜。
没有接口契约。 函数签名类型确定,Skill 的 description 是自然语言。两个 Skill 都写着「用于数据处理」,它们是否兼容?谁优先级更高?没有答案。
没有版本约束。 代码模块有 SemVer,升级影响可预测。Skill 升级内容,Agent 行为可能完全不同,甚至难以察觉。
调用没有确定性保证。 代码模块的调用路径编译时就定了,Skill 的触发是运行时推理的,Agent 每次选择可能不一样。
模块化思考不是错的,只是时机还没到
这个类比本身不是坏想法,背后的工程需求是真实的——复杂任务确实需要拆分,某些步骤确实可复用。
问题是:「模块化」带来的全部隐喻——版本契约、依赖解析、命名空间、调用图——是针对「确定性」设计出来的,而 Skill 目前的运作机制还是「语义驱动的动态协作」,确定性基础还没建立。
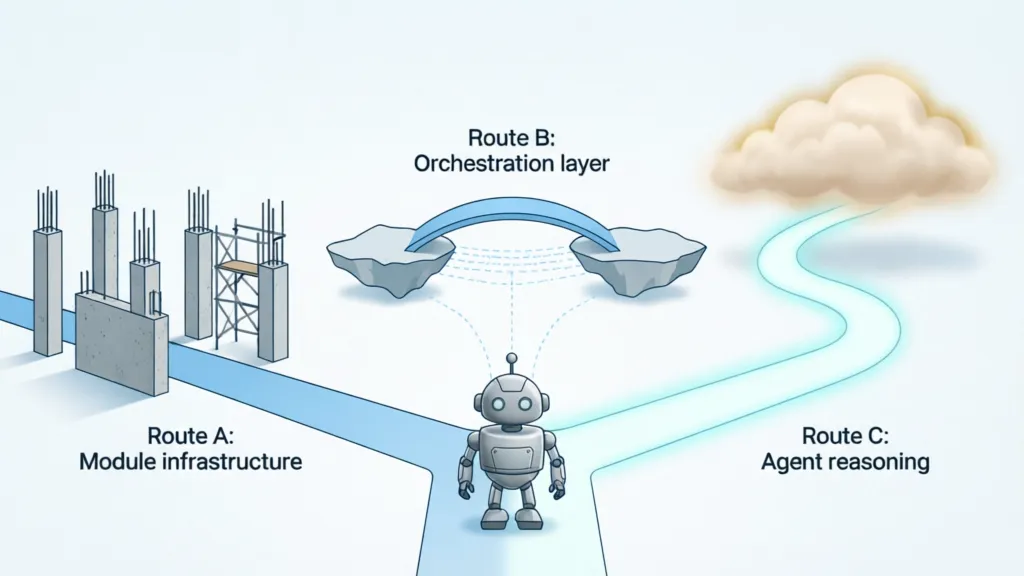
现在行业有三条探索路线:
路线 A 是给 Skill 建立正式的模块系统——像 npm 包那样,声明 skill-a 依赖 skill-b 版本 ^1.2,有版本解析、有依赖图、有发布市场。这需要解决一个根本问题:谁来定义标准?谁来维护注册表?光有技术方案不够,还需要整个生态有共识,然后让 Anthropic、Cursor 这些平台主动去实现。这件事比路线 B 和 C 都慢,现在还没有实质进展。
路线 B 是在 Skill 之上加编排层,用 Orchestrator Skill 定义组件 Skill 之间的协作关系、顺序、数据传递。不需要等平台升级,今天就能用。
路线 C 是让 Agent 自身更擅长理解 Skill 之间的关联,自动判断怎么协作。最根本,但也最难。
这里要特别说清楚 B 和 C 的关系:它们不是并列的,是递进的。路线 C 是终态,路线 B 是通往终态的临时桥。当 Agent 足够聪明能够自动协作时,Orchestrator Skill 这一层就不需要了——但在那之前,路线 B 是唯一可靠的选择。目前路线 B 已有实践,路线 C 还需要模型能力有质的提升。路线 A 则是在另一条轨道上,需要平台层面的标准化支持。
10 个最佳实践
以下综合了 agentskills.io 官方文档、Anthropic 官方团队经验以及社区专家讨论。每项都有完整示例,方便直接参考。
快速导览:
-
Coherent Units — 只做一件事,做完整 -
Orchestrator — 编排层解决多 Skill 协作 -
Gotchas — 最有价值的坑记录 -
Templates — 输出格式标准化 -
Validation Loop — 做→验证→修复→再验证 -
Checklists — 防止跳步 -
Description 优化 — 触发开关怎么写 -
scripts/ 目录 — 复杂命令封装 -
Eval-Driven — 用真实任务测试 Skill
1. Coherent Units:只做一件事,做完整
官方原则:Skill 应该是一个内聚的工作单元,类比函数设计——一个函数只做一件事。
「一件事」的边界判断标准:如果两个步骤需要完全不同的上下文才能执行,就不应该在一个 Skill 里。比如「查询数据库」和「发送邮件」——查询需要知道 schema,发送需要知道模板和收件人。上下文不同,放一起只会让 description 变模糊。
反面有两种:Skill 太大(试图包揽一切,后面会详细说),以及 Skill 太碎(每个小步骤都做成独立 Skill,结果一个任务激活五六个 Skill,开销巨大且可能指令冲突)。
中文示例:
---
name: debugging-and-error-recovery
description: 引导系统性根因调试。当测试失败、构建中断、行为不符合预期时使用。
当你需要系统性方法定位问题而不是靠猜时激活。
---
# 调试与错误恢复
## 停下来原则
遇到意外情况时,不要继续加功能。错误会累积。
1. 停:停止添加新功能
2. 存:保存错误输出、日志、重现步骤
3. 诊:用检查清单逐步排查
4. 修:修复根因
5. 防:写测试防止再次发生
6. 验:验证通过后再继续
## 排查清单
按顺序执行,不要跳过步骤。
### 第一步:复现
让问题可靠地复现。如果无法复现,无法有信心地修复。
- 能复现 → 进入第二步
- 不能 → 收集更多信息,在最小环境里重试
### 第二步:定位
哪个层面出问题?
- 前端 → 检查控制台、网络请求
- 后端 API → 检查服务器日志
- 数据库 → 检查查询和 schema
- 构建工具 → 检查配置和依赖
### 第三步:简化
构造最小化复现场景——去掉无关代码/配置,直到只剩 bug 本身。
### 第四步:修复根因
不断问「为什么」,直到找到真正原因,而不是症状。
- 症状:用户列表显示重复
- 修症状(不好):在前端用 [...new Set(users)] 去重
- 修根因(好):API 的 JOIN 查询产生了重复 → 修查询
## 常见坑
- 本地测试通过但 CI 失败 → 通常是环境差异(Node 版本、数据库状态、环境变量)
- 本地构建成功但 CI 失败 → 通常是缓存问题 → 在 CI 里做 clean install
- 「之前还好好的」加上「最近没改动」 → 通常是时序或状态污染问题
这个 Skill 只做一件事(调试),每个步骤都有具体判断标准。Gotchas section(常见坑)是官方认为投资回报率最高的部分——写那些 Agent 一定会踩的、违反直觉的、团队特有的事实。
2. Orchestrator:编排层解决多 Skill 协作
不改 Skill 本身,在 Skill 之上加 Orchestrator Skill,专门定义顺序、依赖、数据传递和检查点。
中文示例——把 YouTube 长视频自动转换成 5 个短内容的工作流:
---
name: shortform-video-system
description: 端到端短视频制作编排。从 YouTube URL 提取内容并发布到多平台。
当用户要求基于视频创建短视频内容时激活。
---
# 短视频制作系统
## 概述
这是编排层 Skill,协调多个专业组件 Skill 完成短视频制作。
**输入:** YouTube 视频 URL
**输出:** 5 个带字幕、可直接发布的短视频
## 执行流程
按顺序执行,每个 Skill 的输出是下一个的输入。
### 阶段一:提取字幕
激活技能:视频字幕提取
输入:{视频 URL}
输出:词级时间戳字幕(JSON)
**验证:** 字幕时长少于 30 秒 → 终止。
### 阶段二:剪辑重制
激活技能:片段选择 + 视频裁剪
输入:阶段一字幕 + 视频 URL
输出:5 个竖屏(9:16)成品片段
**验证:** 每个片段评分 >= 7,且检测到人脸。
### 阶段三:字幕 + 发布
激活技能:字幕生成 + 内容发布
输入:5 个成品片段 + 原始字幕
输出:添加了字幕动画的成品,并排期发布
**验证:** 字幕与语音偏差不超过 200ms。
## 人工确认点
阶段一完成后:确认视频内容值得制作。
阶段二完成后:展示 5 个片段,请用户确认后进入阶段三。
这个 Orchestrator Skill 本身没有操作指令,职责是定义顺序、传递输入输出、在每阶段之间验证、在关键节点请人介入。两个关键设计原则:一是每个阶段末尾必须验证,前一步的输出不合格就不继续,防止错误累积;二是人工确认点放在不可逆步骤之前,发布是不可逆的,所以在发布前让人介入。
Anthropic 官方团队做广告文案自动化时,也是这样拆的——一个 sub-agent 负责标题,一个负责描述撰写,一个负责 QA 审核。理由是:「debugging easier and improves output quality when dealing with complex requirements」——拆开之后更容易调试,输出质量也更高。
3. Gotchas Section:最有价值的内容
官方把 Gotchas section 列为 Skill 里投资回报率最高的段落。
原因是:Agent 从训练数据里已经学到了大量「正确做法」,但不知道你们团队特有的「反常识事实」。
## 常见坑
- `users` 表使用软删除。查询必须包含 `WHERE deleted_at IS NULL`,
否则结果会包含已停用的账户。
- 用户 ID 在数据库叫 `user_id`,在认证服务叫 `uid`,
在账单 API 叫 `accountId`。三者指向同一个值,
混用会导致静默数据错乱。
- `/health` 端点在 Web 服务器运行时返回 200,
即使数据库连接已经断开。检查完整服务健康用 `/ready`。
- 我们的 API 限流是按用户计,不是按 IP 计。
遇到 429 查看 `X-RateLimit-Remaining` 头,不是看 IP。
判断标准:非显而易见的、Agent 一定会踩的坑,放在主文件 SKILL.md——Agent 读取 Skill 时立刻看到。需要特定条件才触发的(如「当 API 返回 500 时」),放到 references/ 并在主文件说明「在这种情况下读取」。
4. Templates:输出格式标准化
用模板而不是描述,因为 Agent 对具体结构的 pattern match 能力强,对自然语言描述的理解可能有偏差。
## 报告结构模板
生成分析报告时,严格使用以下格式:
# [分析标题]
## 执行摘要
[关键发现的单段概述]
## 关键发现
- 发现 1:具体说明及数据支撑
- 发现 2:具体说明及数据支撑
## 建议
1. 具体可执行的建议
2. 具体可执行的建议
## 方法论
[分析所使用方法的简要说明]
## 局限性
[任何已知的方法论局限或数据缺口]
除非用户明确要求不同格式,否则不要偏离此模板。
模板特别适合:代码审查报告、数据分析报告、会议纪要、API 文档。任何需要固定结构的输出,模板比描述更可靠。
5. Validation Loop:自我纠错的执行模式
防止「错误累积」的关键机制。Agent 执行长流程时经常在某个步骤做了错误判断,但继续往下走——后面的步骤基于错误结果执行,最后出来的内容格式完整但全错。
## 数据库迁移流程
### 第一步:创建迁移计划
运行:`python scripts/analyze_schema.py --diff old.sql new.sql`
输出:`migration_plan.json`,列出每个表/列的变更
### 第二步:验证计划
运行:`python scripts/validate_plan.py migration_plan.json`
如果验证失败:
- 读取 `references/validation-errors.md` 了解错误含义
- 修订 `migration_plan.json`
- 重新运行验证脚本
- 重复直到验证通过
### 第三步:备份
应用前备份:`python scripts/backup.py --env {环境}`
### 第四步:执行迁移
运行:`python scripts/apply_migration.py migration_plan.json`
### 第五步:验证
运行:`python scripts/verify_migration.py migration_plan.json`
如果验证失败,运行回滚:`python scripts/rollback.py migration_plan.json`
核心逻辑:做 → 验证 → 失败就修复 → 再验证 → 通过才继续。适用于任何「计划 → 执行 → 验证」的工作流。
6. Checklists:防止跳步
Agent 执行长流程时经常跳过某些步骤觉得差不多就往下走了。Checklist 把隐式步骤变成显式检查点:
## Pull Request 审查清单
进度:
- [ ] 阅读 PR 描述和动机
- [ ] 本地运行代码:`git checkout {分支} && npm install && npm test`
- [ ] 确认所有 CI 检查都通过
- [ ] 从安全性、性能、清晰度、测试覆盖率角度审查代码
- [ ] 检查新代码是否有对应的测试
- [ ] 确认没有调试代码或 console.log
- [ ] 如果有 UI/行为变更,手动测试
- [ ] 批准或提出具体修改意见
每完成一步打个勾,没完成的步骤一目了然。特别适合 Code Review、调试流程、发布检查等场景。
Checklists 和 Validation Loop 的区别: Validation Loop 是「防止错误累积」,每个阶段做完要验证输出质量,不合格就打回重做;Checklists 是「防止跳步」,确保该做的步骤没有遗漏,即使最后输出质量有问题也能追溯到哪一步没做好。两者配合使用:Checklists 保证不跳步,Validation Loop 保证每步输出合格。
7. Description 优化:触发开关
官方单独出了一篇指南,因为 description 是 Skill 被激活的唯一入口,写得不好 Skill 就等于不存在。
三个核心原则:
用祈使句。「Use this skill when…」比「This skill is for…」更有效。
描述用户意图,不是 Skill 内部实现。「when user wants to analyze data」比「uses pandas for processing」更有效。
主动声明不触发的情况。 避免 Skill 在不该激活的时候被激活。
description: >
当用户要求分析或处理 CSV 数据时激活,即使用户没有明确说「CSV」。
「电子表格」「导出数据」「行列数据」等表述均表明此技能适用。
也包括:图表制作、数据聚合、筛选或透视表。
不适用于:JSON、XML、数据库查询或自由文本处理。
8. scripts/ 目录:把复杂逻辑封装成可测试的脚本
这条原则背后有一个朴素的工程道理:一个命令,如果你在终端里都不能一次写对,放进 SKILL.md 里 Agent 也不可能一次执行对。
把复杂逻辑封装成 scripts/ 目录里的脚本,不只是让 Skill 更整洁,更重要的是让你可以在放进 Skill 之前先在本地把脚本跑通、测好。脚本是可以独立测试的,SKILL.md 里的指令不行。
简单命令直接写,几个 flag 能解决的不需要额外逻辑:
# uvx — Python 包(推荐首选,快速,有缓存)
uvx ruff@0.8.0 check .
# npx — Node.js 包(内置,无需额外安装)
npx eslint@9.0.0 --fix .
命令变复杂时移到 scripts/ 目录——需要错误处理、需要测试:
skill-name/
├── SKILL.md
└── scripts/
├── analyze_form.py # 分析 PDF 表单
├── validate_fields.py # 验证字段映射
└── fill_form.py # 填充表单
判断标准: 几个 flag 能解决 → 直接写;很难一次写对 → 移到 scripts/;需要测试和错误处理 → 必须用 scripts/。
9. Eval-Driven:用真实任务测试 Skill
官方认为最重要的原则:Skill 必须用真实任务测试,不能只靠「看起来合理」判断。
这可能听起来理所当然,但实际做的人很少。大家写完一个 Skill 之后通常是「嗯,看起来没问题」,然后就直接用了。但 Skill 的质量不是靠读出来的,是靠跑出来的——而且要跑在真实任务上,不是跑你自己设计的「理想输入」。
为什么不能只靠读 Skill 判断质量? 因为 SKILL.md 里的描述和指令,在 Agent 推理过程中可能被理解成完全不同的意思。你觉得「当用户要求分析 CSV 时激活」写得够清楚了,但 Agent 可能在一个用户说「帮我看看这个表格」的时候激活了这个 Skill,也可能没有。这种偏差只有在真实任务里才能发现。
Eval 的正确姿势:不是验证「Agent 做了什么」,而是验证「输出质量是否达到了预期」。一个 Skill 执行完,你关心的是:生成的分析报告格式对不对?图表有没有标题和标签?字段名有没有拼错?这些是可以在没有 ground truth 的情况下判断的。
官方推荐的 Eval 工作流:
csv-analyzer/
├── SKILL.md
└── evals/
└── evals.json # 测试用例定义
csv-analyzer-workspace/ # 执行结果目录
└── iteration-1/
├── eval-top-months-chart/
│ ├── with_skill/ # 带 skill 执行
│ ├── without_skill/ # 不带 skill baseline
│ ├── grading.json # 断言结果
│ └── timing.json # token 消耗 + 耗时
└── benchmark.json # 汇总统计
{
"skill_name": "csv-analyzer",
"evals": [
{
"id": 1,
"prompt": "在 data/sales_2025.csv 中找出收入前 3 个月,并制作柱状图",
"expected_output": "一张带坐标轴标签和数值标签的柱状图",
"files": ["evals/files/sales_2025.csv"]
},
{
"id": 2,
"prompt": "这个 customers.csv 有些行邮箱是空的,帮我清理一下并告诉我有多少条是空的",
"expected_output": "清洗后的 CSV 文件 + 缺失邮箱的计数",
"files": ["evals/files/customers.csv"]
}
]
}
最关键的原则:每个测试用例跑两遍——带 Skill 和不带 Skill,对比 baseline。 如果带 Skill 的输出明显比不带 Skill 好,这个 Skill 才是真有价值的。如果两者差不多甚至 Skill 版更差,那要么是这个 Skill 设计得不好,要么是这个任务本来就不需要它。测试用例要覆盖各种表述:正式的、非正式的、有错别字的、带缩写的。如果有条件,还要覆盖边界情况:空文件、超大文件、格式不规范的输入。
总结

Skill 不是代码模块,因为两者的前提完全不同——代码模块建立在确定性之上,Skill 是语义驱动的动态协作。
但模块化的工程需求是真实的。行业正在探索三条路:路线 A(模块化基础设施)需要平台支持;路线 B(编排层)今天就能用,是通往路线 C 的桥;路线 C(Agent 推理增强)是终态,Agent 能自动理解 Skill 之间的协作关系。路线 C 成熟后,路线 B 就不再需要了——但在那之前,路线 B 是唯一可靠的选择。
如果今天就想用 Skill 构建可靠的工作流,把 Skill 设计成小而专注的组件,用 Orchestrator Skill 定义协作关系,同时用 Gotchas、Validation Loop 和 Eval-Driven 保证每个组件的质量。这些今天就能做到,不需要等基础设施成熟。
今天就能做的最小一件事:找一个你团队里重复做过两次以上的流程,写下第一步要做什么——这就有了你的第一个 Skill 的起点。
模块化是一个方向,不是现在就能兑现的承诺。