 夜雨聆风
夜雨聆风





从源码读懂nanobot的运行原理
nanobot是香港大学数据科学实验室(HKUDS)开源的超轻量级个人AI助手框架,可以看作是openclaw的极简实现版。openclaw的源代码超过40万行,而 nanobot 仅 2 万余行,其中核心代码约 4000 行。我们可以通过nanobot来理解openclaw的设计思想与实现机制,它是学习研究openclaw的一条快速通道。
nanobot在设计和实现上有很多的关键特性,在一篇文章里难以面面俱到。本文从nanobot最核心的Agent Loop入手(其核心功能是根据用户输入的消息,调用大模型进行推理,执行工具以完成任务,并最终向用户返回结果),通过对源代码的分析来理解其实现机制。
“思考-行动-观察”的循环处理框架
nanobot 采用ReAct 智能体构建模式,其本质是一个“思考(Think)—行动(Act)—观察(Observe)” 的循环过程,如下图所示。
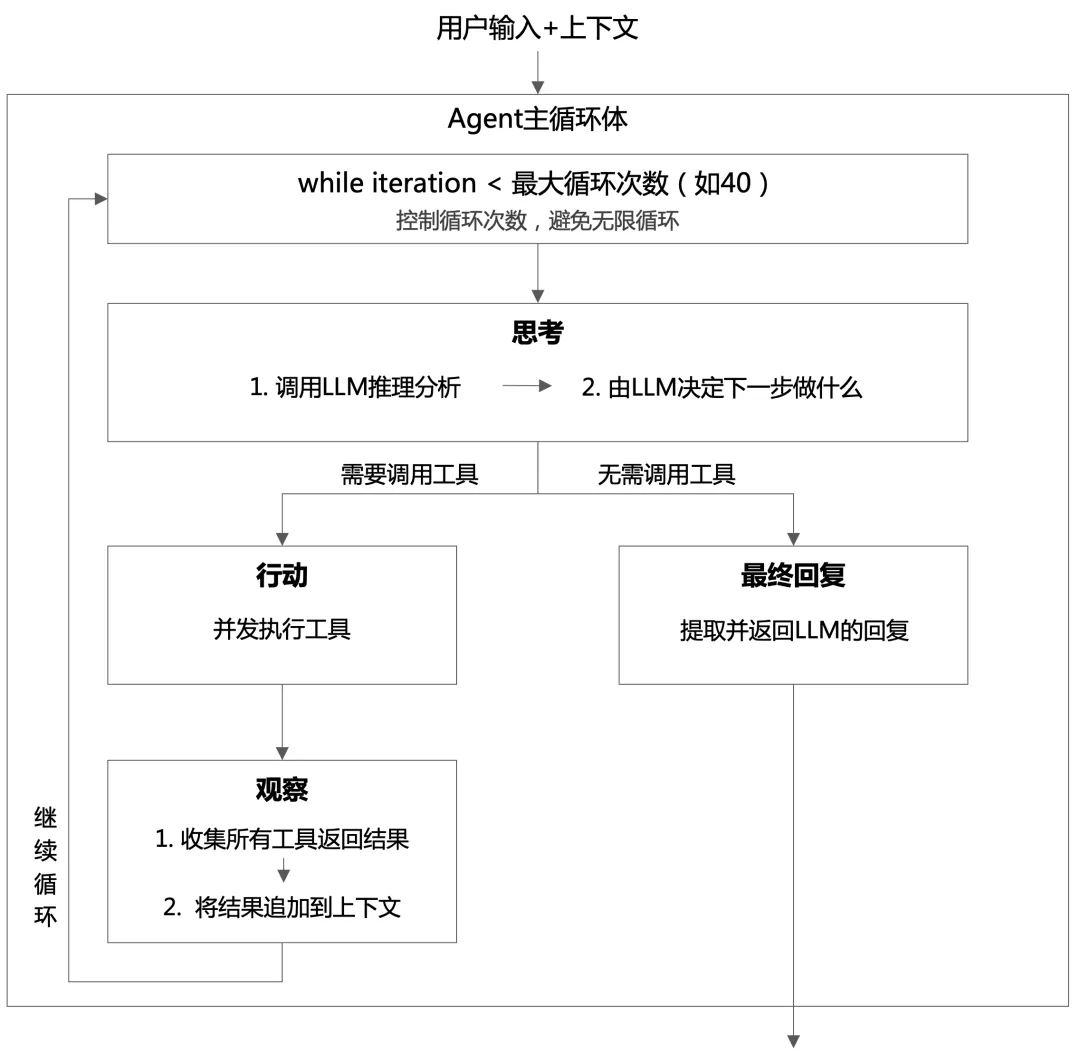
当用户输入消息之后,智能体整合上下文信息之后进行ReAct主循环。首先是思考环节,智能体调用大模型进行推理分析,由大模型来决定下一步要做什么。如果大模型判断需要调用工具,那么进入行动环节。
在行动环节,智能体调用工具执行相应的任务,并返回工具执行结果。然后进入观察环节,在这个环节,智能体收集工具返回的结果,将结果整合到上下文信息之中,然后进行下一轮循环,重复上述过程。
当某一轮循环中,大模型明确表示“不需要再调用工具”时,意味着它已经掌握了足够的信息来回复用户。此时,智能体将大模型的回复作为最终结果,退出循环,本轮对话与推理任务结束。
一个实际例子来看ReAct循环处理过程
通过飞书中向nanobot提出一个问题:今天杭州的天气怎么样?
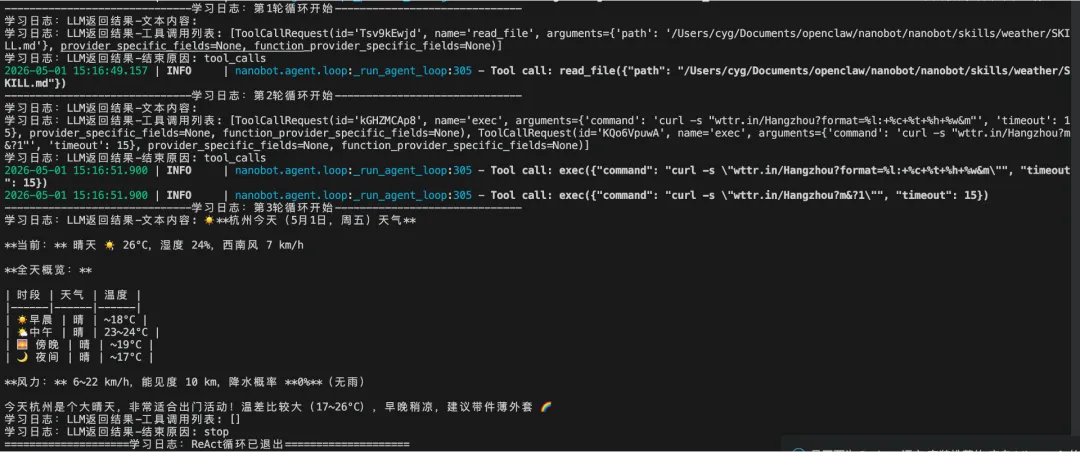
nanobot的ReAct循环处理时序过程如下图所示。本次任务经过了3轮循环处理:
第1轮:LLM思考发现,要读取查询天气的SKILL文档;智能体调用读取文件的工具,获得了天气SKILL文档中的内容,并追加到上下文中。
第2轮:LLM在读取了SKILL文档之后,经过思考发现要调用能够执行shell命令的工具;智能体调用工具来执行shell命令(查询天气),命令执行之后获得了杭州的天气信息,并追加到上下文中。
第3轮:LLM在上下文中读到了杭州的天气信息之后,发现已经可以回答用户的问题了,就生成并返回结果信息。智能体退出ReAct循环。

通过在nanobot源代码中增加打印日志的代码之后,输出的日志信息如下图所示,可以发现与上面的时序图完全一致。
核心机制:大模型主导任务规划,打破固定工作流限制
与以往面向特定应用场景的智能体不同,nanobot 的核心特点在于:其任务规划与调度由大模型动态控制,而非依赖固定工作流。这使得 nanobot 成为一个通用型智能体,能够灵活处理多种类型的任务。
相比之下,基于固定工作流的传统智能体往往只能应对单一或有限的场景。以常见的 ChatBI 智能体为例,其处理流程是硬编码的:第一步,根据用户意图召回数据表和字段;第二步,由大模型基于输入上下文生成 SQL 查询语句;第三步,执行 SQL 并从数据库中获取结果数据;第四步,在前端展示结果。这种固定流程极大地限制了任务类型的泛化能力。
通过以上对 nanobot 的 ReAct循环运行原理的分析,并结合实际案例,我们清晰地看到了从“思考—行动—观察”每一步的详细处理过程。nanobot呈现了现代 AI Agent 的核心设计思想:让大模型主导任务规划,让框架保持极简与灵活。对于希望深入理解 openclaw 乃至通用智能体实现原理的同学而言,nanobot 是一个很好的学习对象,希望本文对你有所帮助。