 夜雨聆风
夜雨聆风





AI 重塑 FPGA:当协作颗粒度从"周"降到"分钟",一个人能做什么

三个月,两个人 + AI,把 128K-point FP32 FFT 从 0 推到 FPGA PASS
★
AI介入FPGA研发后,一个人可以同时推进多个项目,并且你可以在半夜睡醒、食堂排队打饭、高铁上、参加会议的间隙等任何时候查看并推进你的项目,这种可以利用碎片化时间推进项目的模式可能会给FPGA开发带来深刻的变革。
AI不能替你做决策,但它能把”做对一次”的经验,以可复用的形态沉淀下来,让你在第二次、第三次踩同样坑时,先停一秒。
楔子
2026 年 2 月,我接到一个任务:
在 Xilinx VU13P(UltraScale+ 4-SLR SSI 大芯片)上实现 128K-point(N=131072)的 FP32 单精度浮点 FFT,单帧时延要小于 3.2 μs。
这个数字不是拍脑袋来的 —— 是 NVIDIA A100 GPU 跑 cuFFT 在 batch-1 模式下的实测时延。
FPGA 要在数据吞吐上对标 A100 的最差工况。
到 5 月初,这件事的状态是这样的:
-
Phase 3.2 BFP 版本 上 VU13P 完成 silicon BIST PASS(R7 / R8 / R9.0 三代 bit 上板,vector_pass=16’hFFFF,err_cnt=0,5/5 复位一致),freeze 为产品基线 v9.0-bfp-product。 -
Phase 4.0 FP32 ASIC 预研版本 xsim bit-exact PASS(N=131072 / P=128,5 vector × max_rel=0)+ 27 页 ASIC 资源外推白皮书完成,12nm/16nm 双轨流片 conditional GO 决策。 -
项目跨 4 代仓库,28 份会话记录、~3500 行 dev log、11 篇 wiki concept 文章、4 张 Obsidian Canvas 拓扑图全部归档。
全程两个人 + Claude(Cursor IDE 集成)。
按业内常规估算,这种规模的工作(FPGA 全流水线 + 多次 silicon 上板 + ASIC 资源外推白皮书)通常需要 3-5 人团队、6-12 个月。
我不是想说”AI 多牛”。
我想认真总结的是:AI 在 FPGA 这种”工具链异常脆弱、调试反馈周期极长、错一步可能损失数小时综合时间”的场景里,到底能干什么、不能干什么、要怎么用才有效。
这篇文章把三个月的真实路径摊开,给后面想用 AI 做硬件设计的人留一些可参考的坑位。
一、项目背景:为什么是 128K FP32 FFT?
1.1 数字目标
|
|
|
|---|---|
|
|
|
|
|
|
|
|
≤ 3.2 μs
|
|
|
xcvu13p-fhgb2104-2-i) |
|
|
|
|
|
|
3.2 μs 是个极其苛刻的数字。
要达到它,必须每个 clock cycle 同时处理 P 个并行复数样本,且 P 大约要在 64 以上。
这意味着要让 ~10K DSP + ~1M LUT 在大芯片上同时跑 400 MHz 时钟,且时序闭合。
1.2 我的工作模式
-
两个人 —— 还有一个HLS方式实现的协作工程师,所有决策、调试、综合都是我 -
AI —— Cursor IDE + Claude(过程中模型升级了几次) -
工具链 —— Vivado 2022.1(Windows + WSL 双环境,后期收敛到 Windows + PowerShell) -
沟通方式 —— 中文(我描述目标和约束)→ AI 输出 plan / RTL / Python 金模 / 综合脚本 / 文档 → 我审 → AI 执行 → 我验证 → 把经验沉淀回 wiki
二、三个月的开发时间线
★
建议横屏阅读 / 也可以跳过本章直接看下一节。这里把 4 大 Phase 一次性铺开,后面会逐个挑关键转折讲。
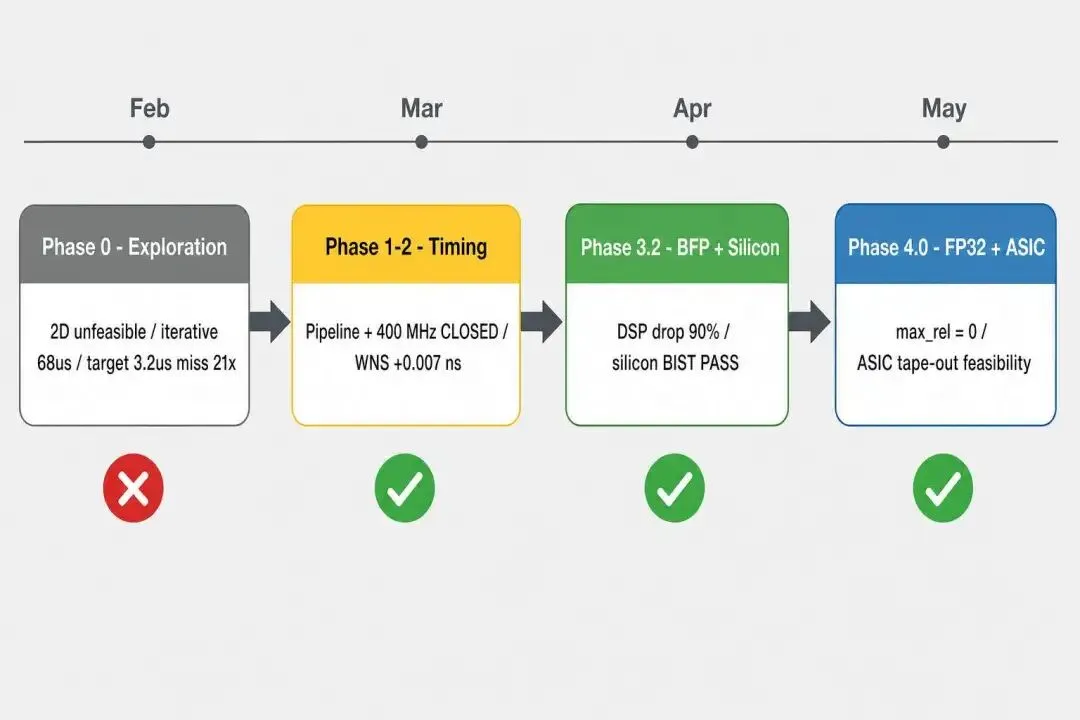
Phase 0 (cursor_fft 仓库, 2026-02 ~ 03-01) — 早期探索 2D Cooley-Tukey 512×256 → 单片 FP32 128 路 DSP ~86K, 不可行 4×VU13P 集群方案 → 片间通信瓶颈, PCB 复杂度高, 否 INT16 路线 → 时序未闭合 最终采纳: PAR_BF=32 迭代式 → 时延 ~126 μs @ 400 MHz, 距 3.2 μs 差 40×Phase 1-2 (slr_local_pack → slr_local_p19, 2026-03-13 ~ 03-27) — 时序攻坚 Phase 1.6 SLR Pipeline 插入 WNS: -6.222 → -1.636 ns Phase 1.7 shuffle 末端寄存器 无效, 路径在源头不在末端 Phase 1.8 Shuffle 静态化 WNS: -1.401 → -0.288 ns Phase 1.9 Per-cluster bcast WNS: -0.288 → +0.010 ns ✅ 200 MHz CLOSED Phase 2.0 FP IP 流水线化 攻坚 400 MHz Phase 2.1b 多策略 phys_opt 轮换 WNS: +0.007 ns ✅ 400 MHz CLOSED 迭代式 BF 利用率 11%, 时延 68 μs, 距 3.2 μs 差 21×Phase 3.0-3.2 (slr_local_p19, 2026-03-29 ~ 04-26) — 全流水线 + BFP 革命 Phase 3.0 R4MDC FP32 9-stage 时延 5.97 μs, DSP 81% Phase 3.1 三层 RAM 映射 URAM/BRAM/distributed 自动选取 Phase 3.2 BFP + R²² 17-stage DSP ↓90% (9984 → 960) Phase 3.2d 方案 B' + C 组合 WNS = +0.003 ns ✅ 400 MHz CLOSED 时延 10.95 μs (P=32, 工程退让 vs P=64) R7/R8/R9.0 上板 BIST PASS freeze v9.0-bfp-productPhase 4.0 (slr_local_p19_fp32 worktree, 2026-04-26 ~ 05-01) — FP32 + ASIC 预研 MS-1B xsim bit-exact max_rel = 0, 100/100 + 10/10 PASS MS-1C OOC 综合 P=32 WNS=+0.363 ns, LUT 49% / DSP 76% P=64 hard FAIL (DSP 152% 超容量) MS-2 P=32 全 board build ❌ FAIL: 1.44M fanout 跨 SLR3↔SLR1 MS-2b cmul-only 上板 ✅ PERFECT PASS: 16 × 32 × 5 reset MS-4 ASIC 资源外推白皮书 v1.0 27 页, 12nm/16nm dual-target, conditional GO Scope A ASIC RTL skeleton (N, P) 参数化, P=128/256 xsim bit-exact PASS Scope B ASIC RTL N=131072/P=128 production target xsim PASS, max_rel=0简而言之:3 个月,4 代仓库,从”2D 不可行”走到”silicon BIST PASS + ASIC 流片预研白皮书”。
三、七个真正的转折点
下面挑 7 个最具转折意义的节点讲。
每个节点都包含:发生了什么、AI 怎么参与、我自己做了什么、给后续工作留下了什么。
转折 1:架构判死(2026-03-01,Phase 0)
[DSP 用量演变 — 86K (不可行) → 960 (BFP 革命) → 9.3K (FP32 P=32 OOC) → 18.7K (P=64 hard FAIL)]
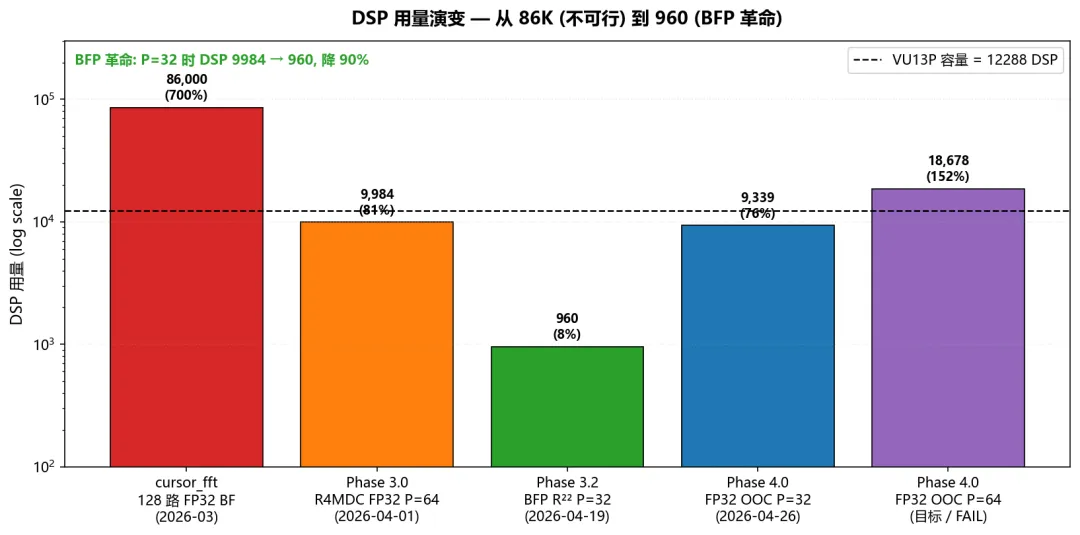
起点:第一次 RTL 综合,128 路 FP32 BF 直接报 DSP 86K(VU13P 总共才 12K),完全不可行。
怎么处理:让 AI 把”为什么不可行”的所有原因列出来 —— 不是让它给方案,是让它穷举失败模式。
最后我们把不可行的根因清单贴进 result_20260301.md,作为后续所有决策的 baseline。
学到的事:
★
架构判死要快、要狠、要文档化。
AI 在这一步最有用的不是”提建议”,而是”把你已经知道但没说清楚的东西,逐条列清楚”,防止你在某个分支上耗到第三周才发现死路。
转折 2:迭代式 → 全流水线(2026-03-29,Phase 3.0)
起点:Phase 1-2 时序闭合到 400 MHz 后,时延 68 μs,距 3.2 μs 差 21×。
仅靠提频已经救不了。
怎么处理:跟 AI 一起把 R4MDC 流水线的全部 9 个 stage 拆开,每个 stage 写独立的 RTL —— 包括延迟交换器(commutator)、BF 阵列、级间置换、post-buffer。
AI 负责生成大量重复模板代码 + 把不同 stage 的 stride / D 参数算清楚。
我负责定接口、定 latency 口径(MUL_LAT=8、ADD_LAT=11)、做最终的算法 review。
学到的事:
★
架构改动是 AI 最大的省时点。 这种”9 个 stage 每个 200 行 RTL”的模板化工作,人写一周,AI 写一天。
但接口和 latency 必须人工定 —— 这是后续所有 stage 对齐的 ground truth,AI 自己拍的口径会前后矛盾。
转折 3:BFP 革命 —— DSP 一夜降 90%(2026-04-19,Phase 3.2)
起点:Phase 3.0 R4MDC 跑通了,DSP 用到 81%,时序还差 -1.4 ns。继续优化的边际收益越来越小。
怎么处理:跟 AI 复盘了一周,意识到 FP32 在 FFT 这种”全程同尺度”的算法里浪费太严重 —— 大量精度被用在表示量级差异不大的中间结果上。
决定切到 BFP(Block Floating Point):MANT=24 / EXP=8 共享,每级 renorm。
算法重写成 R²²(BF2-I + BF2-II 交替)17 stage。
结果:
-
DSP 9984 → 960,降 90% -
LUT 从 1275K 降到 808K,降 37% -
WNS 经过 Phase 3.2a/b/c/d 四轮迭代,最终 +0.003 ns @ 400 MHz -
R7 / R8 / R9.0 三代 bit 上板,全部 BIST PASS
学到的事:
★
数据格式是架构决策的一部分,不是事后调优。
这个决策比任何微优化都重要 —— 10× DSP 节省直接把项目从”算力不够”推到”算力富余”。
AI 在这一步的价值是:在我描述完物理直觉(BFP 应该省很多)之后,它能把这个直觉量化成 normalize barrel shifter 的 LUT 估算 + 各 stage 共享指数树的位宽 / 时序代价 / 误差模型,让我在动手前就知道大概能省多少、风险在哪。
转折 4:bit-exact 金模 vs 1e-5 容差(2026-04-26,MS-1B)
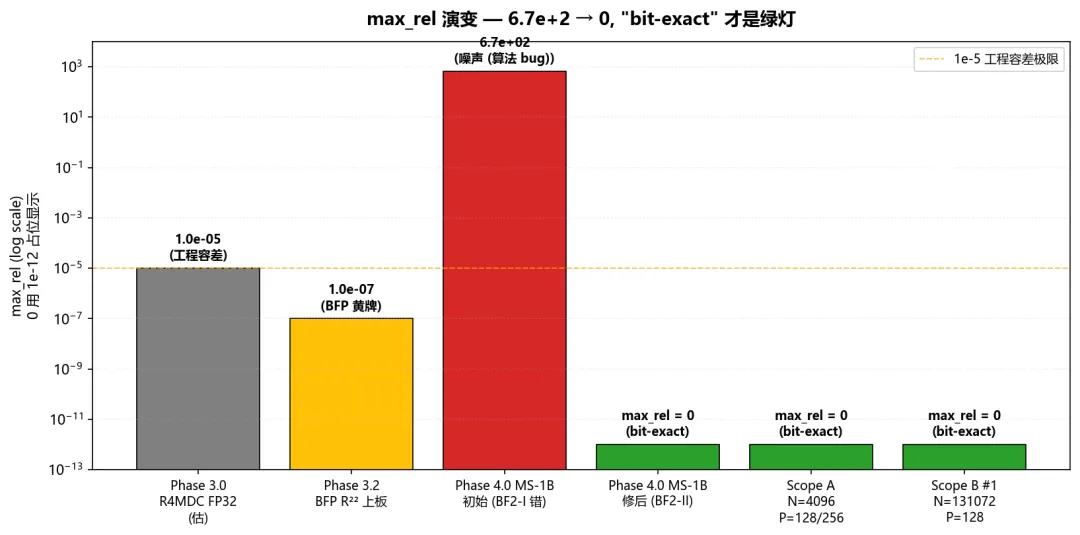
起点:Phase 3.2 BFP 上板后,公司决定再做一版 FP32 流片预研版本。
RTL 从 streaming_bfp/ fork 到 streaming_fp32_r22/,跑顶层 xsim,第一发就 max_rel ~ 6.7e+2。
这是个吓人的数字。
max_rel 表示”输出 vs 金模的最大相对误差”,1e-5 已经是工程容差极限,6.7e+2 意味着计算出来的根本不是 FFT,是噪声。
怎么处理:我让 AI 帮我从 17 个 stage 里逐 stage 隔离测试。每个 stage 单独喂金模生成的输入,看输出是否 bit-equal。
结果:17 个 stage 全部独立 PASS,但合起来跑就是 6.7e+2。
这意味着不是某个 stage 的 RTL bug,是算法层面的问题。
AI 帮我把 R²² 的论文(He-Torkelson 1996/1998)重新捋了一遍,发现:
★
BF2-I 的”统一 -j rotation 不放 twiddle”这个捷径,只在 BF2-I 与紧邻 BF2-II 一起 fold 成一个 R⁴ 行为时合法。
BFP 因为 normalize 阶段会把 phase-factor 误差吃掉,看起来”OK”;FP32 严格 IEEE-754 round 不会吃任何东西,所以一拆即错。
修方案:全部改成 BF2-II,canonical W_N^k twiddle,丢掉 fold-back 优化。
代价:多 8 个 twiddle ROM bank(BRAM +5%)。
收益:max_rel = 0,bit-for-bit 等价。
学到的事:
★
这是这三个月最深刻的教训。
max_rel容差(1e-5)是工程妥协,bit-exact(max_rel = 0)才是算法等价的硬证据。
原因:FP32 没有”约等于”这回事,任何浮点运算顺序变化都会产生确定性差异。
如果你的 RTL 跟金模 max_rel = 1e-7,那不是 OK,那是你金模写错了或 RTL 里某个加法器 latency 错了。
转折 5:silicon 比 Vivado 报告宽容 0.4 ns(2026-04-30,MS-2b)

起点:MS-2 全 FFT FP32 build post-route WNS = -3.438 ns,远低于 -2 ns 的 silicon 余量阈值。
理论上这个 bit 不应该上板能用。
怎么处理:做对照实验 —— MS-2b cmul-only build,只把 32 个 fp32_cmul_array 实例放到单 SLR,不带 controller 跨 SLR。
post-route WNS = -0.297 ns。
烧上板:LED4 ON + LED5 OFF + LED3 ON + LED6/7 全 OFF,联立解出 vector_pass=16'hFFFF && err_cnt=0,且 5/5 复位一致。
这意味着:silicon 实际比 Vivado 报告快 ≥ 0.4 ns。
来源:
-
(a) silicon 平均比 -2 worst case spec 快 5-10% -
(b) 室温(25°C)vs 工业级 worst(100°C+)再快 2-5% -
(c) Vivado WNS 用 SS corner 加 derate,silicon TT 实际更快
学到的事:
★
Vivado WNS 是带 corner derate 的工程余量,不是物理事实。
但前提是设计不能跨 SLR 大 fanout,否则 silicon 余量也吃不下。
转折 6:fanout-cost 是真正的主导成本(2026-04-30)
起点:MS-2 失败 + MS-2b 成功,silicon 不变、IP 不变、时钟不变、worst case spec 不变,唯一变量是 controller 的跨 SLR fanout。
★
建议横屏阅读以下对照表。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
1.44M | 32 | 45,000× |
|
|
|
|
|
|
|
|
|
|
学到的事:
★
FPGA 上板 PASS / FAIL 的真正主导成本不是 FP 算术,不是 DSP 占用,而是 control fanout / clock distribution。
这条经验直接成为 ASIC 流片白皮书的核心论据之一 ——
ASIC 工艺的 clock tree balanced + on-chip wire delay 比 FPGA Laguna SLR crossing 低 1-2 个数量级,同等 RTL 的 controller 在 ASIC 上跨 die 等价距离的 timing budget 大 10-100×。
换句话说:FPGA 装不下 P=128 不仅是因为 DSP/LUT 不够,更是因为跨 SLR fanout 在 P=128 规模下不可能 close。
转折 7:ASIC RTL 平行树 + 算法等价单独坐实(2026-05-01)

起点:白皮书已经写完,论据齐了,但有个”软肋”:
P=128 / P=256 的 ASIC RTL 在 FPGA 上放不下(资源外推显示 LUT 196% / DSP 301%),所以”算法等价”只能靠 P=32 间接推。
怎么处理:跟 AI 一起把 silicon-validated 的 rtl/streaming_fp32_r22/ 树 fork 出一棵 rtl/streaming_fp32_r22_asic/,做三件事:
-
(N, P) 全参数化 —— pkg 里所有硬编码的 N_FFT=131072 / P=32 都拿掉,helper 函数加 (stage_idx, N, P)显式签名 -
17 个 stage 展开 → generate for—— 单 reset、无 SLR pipe、无 4-SLR pblock -
删除全部 Vivado 属性 —— (* MAX_FANOUT *)/(* KEEP *)/(* DONT_TOUCH *)/(* ram_style *)/(* rom_style *),因为 ASIC EDA tool(DC / Genus)看不懂
结果:
-
Scope A:N=4096 / P=128 / P=256,xsim 5 vector × 2 配置全 PASS,max_rel = 0 -
Scope B #1:N=131072 / P=128(production target),xsim 5 vector × max_rel = 0,wall ~15 min
ASIC RTL 树跟 silicon-validated FPGA 树 byte-for-byte 不动,两边各打 git tag。
学到的事:
★
ASIC RTL 平行树是项目复用的最佳实践。
silicon-validated 树承载历史和复现性,不能动;ASIC 树承载未来,自由演进。
三·补 三块磨人的硬骨头
★
上面是项目里做对的事 —— 每个里程碑都带来一次明确的状态推进。
但实际开发时间里,真正消耗心力的不只是这些”高光时刻”,还有三块持续性磨人、反复犯、每次犯都要烧好几天的硬骨头。
这三件事单独拎出来讲,因为它们对应的不是某个 milestone,而是贯穿整个项目的痛苦底色。
硬骨头 1:128G 内存反复崩溃
128G 物理内存的 Windows 工作站,听起来已经”奢华”了。
但跑大设计综合时,Vivado peak memory 突破 128G 是常态,不是偶发。
具体场景:
-
Phase 3.0 R4MDC 9-stage 全流水 FP32 全 P=64 设计:综合 peak 一度逼近 100G,实现阶段触顶 OOM,Vivado 直接 SIGTERM 退出,没有任何报错信息(WSL 模式下被 Hyper-V 也直接 kill,日志只剩半截)。 -
MS-1C 整体综合 P=32 OOC:peak 大约 60-70G,可控,但加上后台 Chrome / Edge 浏览器就会失败。 -
早期 cursor_fft 时代的 128 路 FP32 直综:peak 估算超 128G,根本起不来,从 OOC 报告看 DSP ~86K,物理上就不可能成立。
每一次 OOM 崩溃都意味着:
-
(a) 几个小时综合时间白费 -
(b) 要拆分黑盒 / 加 keep_hierarchy / 改 OOC 模式 重新组织 build 流 -
(c) 关闭所有后台进程,重启 Vivado,空守一台机器跑综合
根因:
-
Vivado UltraScale+ 大芯片综合的内存模型不友好 —— 工具内部一些数据结构是 O(net_count × hierarchy_depth) 的,大设计 + 深层次结构 + LUTRAM 优化打开时,内存爆炸式增长 -
-mode batch -no_log不能省内存,只能省日志 —— 这是个新手陷阱,以为关 GUI 就能省内存 -
Windows 系统缓存 + 64-bit Vivado 内存索引开销 实际可用容量 < 物理 128G
踩坑教训(三道防线):
-
第一道防线:用 OOC 拆顶层 + 黑盒 + keep_hierarchy="yes",把综合分成多个独立 OOC pass,每 pass 内存 peak < 60G -
第二道防线:大设计 build 期间关掉浏览器、其他 EDA 工具,留 100G 净空间给 Vivado -
第三道防线:所有 build 脚本加 report_memory实时监控,把内存曲线画出来 -
最后底牌:WSL2 + 256G 服务器(后期没用上,但留了应急方案)
硬骨头 2:单次综合 / 实现 30+ 小时
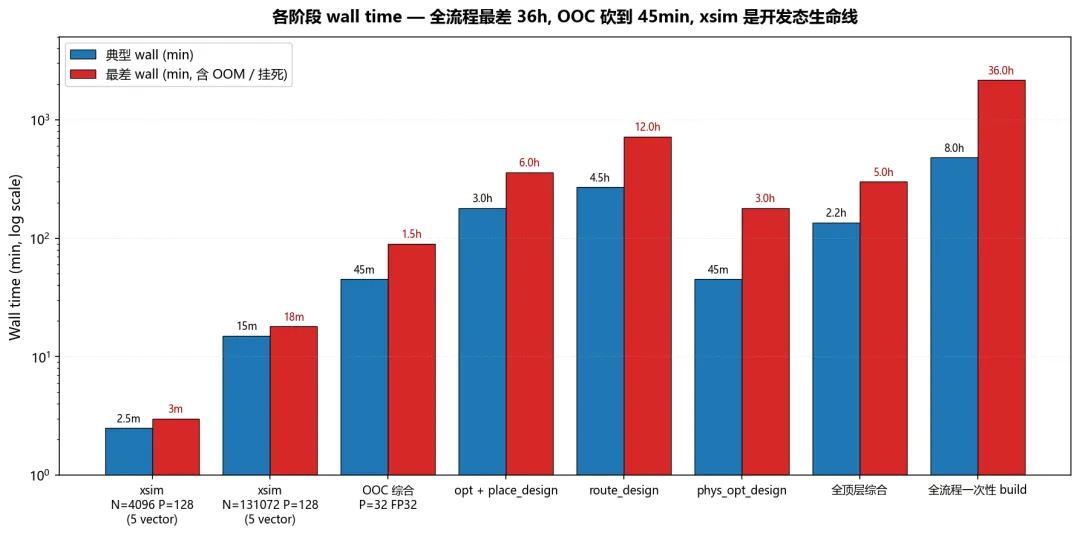
★
Wall time 才是 FPGA 开发真正的”开发速率”约束。
★
建议横屏阅读以下表格。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
opt_design + place_design) |
|
|
route_design) |
|
挂死 / 12+ hr |
phys_opt_design |
|
|
| 全流程一次性 build | ~6-10 hr | ~24-36 hr |
最痛的几次:
-
Phase 3.2c 阶段: route_design在 ExploreSequentialArea 策略下单跑挂死 12+ 小时没收敛,半夜醒来发现 100% CPU 但 routing iteration 不动,只能 kill 重来,改用 Default 策略 -
早期 cursor_fft 时代某次 128 路设计:从下班启动 build,第二天晚上还没跑完(估算 30+ hr),回来一看是 OOM 后某个子进程没退干净僵在那 -
MS-2 全 board build:综合 + 实现 + bit gen 全流程花了将近 5 小时,跑完 post-route WNS = -3.4 ns,结果是预期失败,但只能跑完才能上板验证 fanout 假说 —— 这种”明知会失败但必须跑完”的成本极其反人性
根因:
-
FPGA 综合是 NP-hard 问题的工程近似,设计规模越大,wall 越非线性增长 -
Vivado 没有 incremental synthesis 一类的廉价 rerun(2022.1 时代) -
WNS < 0 时,phys_opt 会反复 retry,wall 暴增 -
OOM 失败 → 重新组织 build → 又跑几小时 —— 这是 wall 的隐形大头
踩坑教训:
-
OOC 综合是开发态的救命稻草 —— 顶层不动,只综合改过的子模块,wall 从 5 hr 砍到 45 min -
能不跑全流程就不跑 —— Phase 4.0 MS-1C 阶段大量用 OOC 综合做资源 + 时序摸底 -
后台跑 build,前台用 AI 写文档 / 下一阶段 plan —— 不要傻等,把 wall 隐藏到并行任务里 -
失败 build 也要写 dev log —— 5 小时跑完发现 FAIL,要立刻把 critical path / 失败模式 / 资源占用 / WNS 数据沉淀到 wiki,不能让 5 小时白费
MS-2 失败后我立刻写了详细的 FAIL 分析 dev log,直接成为 ASIC 白皮书”fanout-cost 是主导成本”的硬数据。
硬骨头 3:跨 SLR 布局 + SSI 延时反复迭代

VU13P 是 4-SLR 的 SSI(Stacked Silicon Interconnect)封装大芯片。
单 SLR 之间通过 Laguna 寄存器 + SLL(Super-Long Line) 互联,跨 SLR 的布线延迟约 2-3 ns / SLR 跳数。
这是 FPGA 工艺最深的”原罪”之一。
Phase 1.6 启点:WNS = -6.222 ns,所有违例路径都是 SLR 跨片组合路径。Controller 在 SLR1,Cluster 3 在 SLR3,中间隔 2 个 SLR,跨片延迟直接叠加在数据路径上。
修方案的演进(每一步都是一次几小时甚至几天的实验):
★
建议横屏阅读以下表格 —— 三个月血泪攻坚一次看完。
|
|
|
|
|
|---|---|---|---|
|
|
SLR_PIPE_LAT=2 级 Laguna pipeline 寄存器 |
|
|
|
|
|
|
无效 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-3.438 ns ❌ | 跨 SLR fanout 1.44M,Pblock 救不了 |
|
|
|
|
避免跨 SLR 才是真解 |
核心教训(三个月血泪沉淀):
-
跨 SLR 不是”加 pipeline 就能解”的问题 —— Phase 1.6 加 SLR_PIPE_LAT修了一部分,但 controller 的 FSM state register 跨 SLR 大 fanout 是 pipeline 救不了的(因为 pipeline 救的是 datapath,不是控制集) -
Pblock 是双刃剑 —— 加得太严会让 placer 没空间塞,加得太松不起作用 -
跨 SLR fanout 的 critical path 不是 timing 问题,是拓扑问题 —— MS-2 的 1.44M fanout 跨 SLR3↔SLR1,没有任何 pipeline / pblock / phys_opt 能救,只能改 RTL 拓扑 -
VU13P 的 4-SLR 拓扑不是优势,是约束 —— 如果你的设计能装下单 SLR(LUT < 25%、DSP < 25%),就尽量装单 SLR;一旦被迫跨 SLR,timing 复杂度立刻 10× 上去
★
这一条教训直接成为 ASIC 白皮书的核心论据之一 ——
ASIC 单 die 没有 SLR 概念,clock tree balanced,同等 RTL 在 ASIC 上 timing budget 大 10-100×。
跨 SLR 是 FPGA 工艺的”税”,ASIC 不交这个税。
四、AI 辅助 FPGA 开发的 7 条核心经验
★
上面是项目本身的转折点,下面是把它抽象成”下次怎么用 AI”的可复用经验。
经验 1:AI 不能替你做架构决策,但能极大加速架构验证
反例:让 AI 直接出”做 128K FFT 的最优架构方案”—— 大概率给你的是教科书 R4MDC,不会知道你的 SLR 拓扑、不会知道 BFP 的 normalize 代价、不会知道 silicon 余量。
正例:你描述约束(VU13P 4-SLR、3.2 μs 时延、FP32 数据格式),让 AI 穷举每条候选路径的资源 / 时延 / 风险量化估算,然后你自己拍板。
★
这三个月里,所有架构决策都是我做的,AI 做的是把每个决策的代价算清楚。
经验 2:bit-exact 金模是 ASIC 流片的必要前提,1e-5 容差会咬人
任何浮点运算的顺序变化都会产生确定性差异。
如果你的 RTL 跟金模 max_rel = 1e-7,那不是 OK,那是金模或 RTL 哪里少算了一拍 / 多算了一次 FMA。
具体做法:
-
Python 金模显式 np.float32()cast 每个子运算,避免 NumPy / CPython 内部 FMA 融合 -
complex_mul 用 4 mul + 1 sub + 1 add 的离散结构,不用 a*b - c*d这种语法糖(编译器可能 fuse 成 FMA) -
max_rel = 0才是绿灯,max_rel = 1e-7是黄灯,要查到底为什么不是 0
def_fp32_chain_explicit(a_re, a_im, b_re, b_im): ac = _f32(a_re * b_re) bd = _f32(a_im * b_im) ad = _f32(a_re * b_im) bc = _f32(a_im * b_re) p_re = _f32(ac - bd) p_im = _f32(ad + bc)return p_re, p_im这套金模 silicon 实证后,ASIC RTL 验证直接复用,3 个 (N, P) 配置 × 5 vector × max_rel = 0。
经验 3:silicon 比 Vivado 报告宽容 ~0.4 ns,但前提是不能大 fanout 跨 SLR
silicon 余量是真实存在的工程边界,但不是免费午餐。
MS-2 的 -3.4 ns WNS 上板就是 stuck —— 1.44M fanout 跨 SLR 已经把这层余量吃光。
判定方法:看 critical path 在哪。
-
单 SLR 内部、低 fanout、纯 datapath,WNS = -0.3 ns 大概率上板能 PASS -
跨 SLR、高 fanout(>10K)、过 controller FSM,WNS 哪怕 +0.1 ns 也要小心
经验 4:fanout-cost 是 FPGA 上板 PASS/FAIL 的真正主导成本
FPGA 上板成功不是看 timing 余量,是看 fanout 拓扑。
MS-2 vs MS-2b 的对照(1.44M vs 32 fanout,完美分隔 FAIL/PASS)是这条规律的硬证据。
实操建议:
-
Controller 的 FSM state register 不要让 fanout 跨 SLR -
大 fanout 的全局 valid 信号要做 SLR-local replica -
用 (* MAX_FANOUT *)在 RTL 里强制约束(但 ASIC 不要) -
post-route 跑 report_high_fanout_nets看哪些信号的 fanout 是危险量级
经验 5:FPGA 装不下不是终点,是 ASIC 流片预研的起点
我们的项目最后停在 P=32 上板 PASS、P=128/256 装不下。
这不是失败,是信号 —— FPGA 已经触顶,要继续提升必须换工艺。
把”FPGA 装不下”做成 ASIC 流片的论据,需要做几件事:
-
silicon-validated 数据:有 MS-2b 这样的 silicon PASS 实证 + 5 条核心结论(FP IP 工作 / 金模 silicon-truth / 实例一致性 / silicon 余量 / fanout-cost) -
MS-2 vs MS-2b 对照:把”fanout-cost 是主导成本”用同一颗 silicon 实证出来 -
ASIC 缩比公式:基于公开工艺数据(cell area / clock tree / wire delay),把 silicon 数据外推到 12nm/16nm -
dual-target 推荐配置:不只给”理想”目标,给”成本敏感”备选
★
ASIC 流片决策不是拍脑袋,是把 FPGA 路上学到的所有东西打包成可量化的证据链。
经验 6:给 AI 建一个 wiki 知识库,让它跨 session 接力
这是这三个月最反直觉但最重要的经验之一。
LLM 的上下文窗口再大,也不可能记住一个三个月项目的所有细节。
但是 —— 只要你把关键决策、关键数据、关键踩坑用结构化方式写到 wiki,新 session 启动时让 AI 读一遍 INDEX + 相关 concept,它能在 5 分钟内 “load” 完整个项目状态,接着继续干。
我的 wiki 结构(简化版):
wiki/├── INDEX.md ← 项目首页 + 速查卡 + 时间线├── concepts/ ← 11 篇核心概念文章│ ├── architecture-evolution.md│ ├── timing-closure.md│ ├── routing-congestion.md│ ├── resource-estimation.md│ ├── ram-mapping-tradeoff.md│ ├── slr-layout.md│ ├── simulation.md│ ├── rtl-coding-rules.md│ ├── vivado-tooling.md│ ├── asic-extrapolation.md│ └── rtl-asic-port.md├── devlog/ ← 按月份的开发日志, 倒序追加, append-only└── *.canvas ← Obsidian Canvas 拓扑图并且我在 AGENTS.md 里写死了 R1 规则(强制 wiki 同步触发条件 + 反模式清单),让每次代码改动都必须连带 wiki 同步,不留”下次再 sync”。
★
wiki 的及时性是项目能跨 session、跨周、跨月持续推进的基础。
经验 7:把工具链踩坑沉淀到规则文件,别让下一代踩第二次
这三个月最让我血压上升的不是 RTL bug,是工具链坑:
-
xsim的 plusargs(+name=value)在 PowerShell 下=被吃掉 -
xelab --generic_top X=Y同坑 -
WSL + Vivado 大设计内存上限 + Hyper-V SIGTERM -
hw_server实例冲突 -
Vivado 综合在 OOM 时直接 SIGTERM 不报错
我把这些坑都写进 AGENTS.md 的 R3 规则:
★
R3. xsim / PowerShell 踩坑提醒
xsim plusargs ( name=value) 在 PowerShell 下被吃=→ 一律走--file xsim_args.f间接传tb_*_top.sv默认dump_flag = 0,sweep 时不要倒灌 GB 级 hex 文件
效果:新 session 启动时 AI 读完 AGENTS.md,踩同一个坑的概率降到接近 0。
★
规则文件的本质是:”让 AI 把别人的经验当自己的经验用。”
这是 AI 辅助开发的复利效应来源。
五、AI 辅助 FPGA 开发的方法论
★
上面是经验,下面是方法论 —— 给想用 AI 做 FPGA 项目的人一个可操作的起点。
5.1 AI 适合做什么
★
建议横屏阅读。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.2 AI 不适合做什么(必须人工把关)
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.3 项目结构怎么建
起步阶段必须立即做的:
-
AGENTS.md(或CONVENTIONS.md):写死项目级规则 -
R1:wiki 同步触发条件 + 反模式 -
R2:沟通语言 / 命名规则 -
R3:工具链踩坑红线 -
wiki/INDEX.md:项目速查卡 + 时间线 + 最新 milestone -
wiki/concepts/<topic>.md:每个主题一篇,append-only -
wiki/devlog/<YYYY-MM>.md:开发日志倒序,append-only,永不修改历史条目 -
tb/python/<scenario>_golden.py:bit-exact 金模 + 物理意义校验 -
build_<scenario>/run_*.ps1:标准化 build/sim 脚本
进阶:
-
Obsidian Canvas:架构拓扑图 + 知识图谱可视化 -
双 git tag 策略:silicon-validated 树 + ASIC RTL 树各打 tag -
白皮书写作模板:章节 outline + 论据一览 + handoff context
5.4 工作流的”五步循环”
下面这张 Mermaid 流程图是这个工作循环的标准形态:
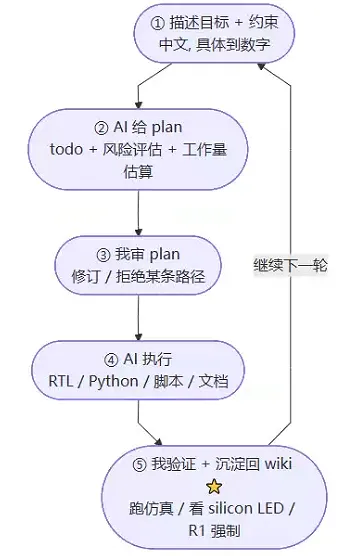
这个循环的关键:
-
第 ② 步的 plan 必须包含数字 —— “估算 LUT 30%、DSP 80%、wall 45 min” 这种 quantified plan,不要”应该可以、大概可行”这种空话 -
第 ③ 步的审是必经环节,不能跳。AI 自己跑一遍后我再 review,反而比一次性审 plan 慢 -
第 ⑤ 步的沉淀是复利来源 —— 验证 + 沉淀必须连成一个动作。验证完不沉淀就等于 reset,下次同样的坑还要踩
六、压轴反思:最大的教训

★
如果让我把这三个月所有的反思只挑一条,就是这条:
★
我从一开始没有把”最终目标是 ASIC 流片,FPGA 只是验证平台”这件事跟 AI 讲清楚。
结果是:AI 按”在 FPGA 上做出最强的 128K FP32 FFT”这个表面目标,陪我把项目最大化地往 FPGA 终端产品方向推。
而这个方向,有相当一部分工作量,对 ASIC 流片是无效的。
这条教训不是技术层面的,是沟通层面和目标设定层面的。
但它的代价比所有技术坑加起来都贵。
6.1 这个误解到底浪费了多少时间
我事后复盘,以下几条工作量,如果 day 1 就明确”目标是 ASIC,FPGA 是验证平台”,可以完全不做或大幅简化。
(a) BFP 路线整体投入(~3 周,Phase 3.2)
BFP(Block Floating Point,MANT=24/EXP=8)的全部价值,仅在于把 FPGA DSP 用量从 9984 降到 960(降 90%),让 P=32 能在 VU13P 上时序闭合 + 上板。
但是:
-
ASIC 工艺下 DSP / multiplier 不是约束(ASIC 有的是 mul cell,12nm 上一个 FP32 mul 大约 0.005 mm²,1000 个也就 5 mm²) -
ASIC 上根本不需要”用 BFP 省 multiplier”这件事 -
真要做 ASIC,直接用 FP32 全流水就好
如果 day 1 就明确目标,Phase 3.2 完全可以不做 BFP 上板,而是:
-
直接做小规模 FP32 子集(比如 P=8 或 P=16)上板,做算法 silicon 验证 -
把 BFP 留作”FPGA 商用化时再做”的可选副线
实际损失:Phase 3.2 整个 BFP 路线大约 2-3 周纯开发时间。
其中”DSP 降 90%”这个亮眼数字,对 ASIC 流片预研的实际贡献接近零。
(b) Pblock / SLR pipeline / Vivado 属性堆砌(贯穿 Phase 1-3)
整个项目里大量 RTL / XDC 代码是 FPGA 工艺特定的产物:
-
4 个 SLR pblock + per-SLR 复位 replica + 3 个 SLR 边界 pipeline -
(* MAX_FANOUT *)/(* DONT_TOUCH *)/(* KEEP *)/(* ram_style *)/(* rom_style *)遍布 stage / commutator / top -
URAM_DEPTH_TH=513/BRAM_DEPTH_TH=64这种 FPGA RAM 阈值参数
ASIC EDA tool(Synopsys DC / Cadence Genus)完全看不懂这些属性,流片时要全部删掉。
事实上 Phase 4.0 Scope A 阶段做 ASIC RTL 平行树时,我们干的最大一件事就是把这些 FPGA-specific 的代码全删了:
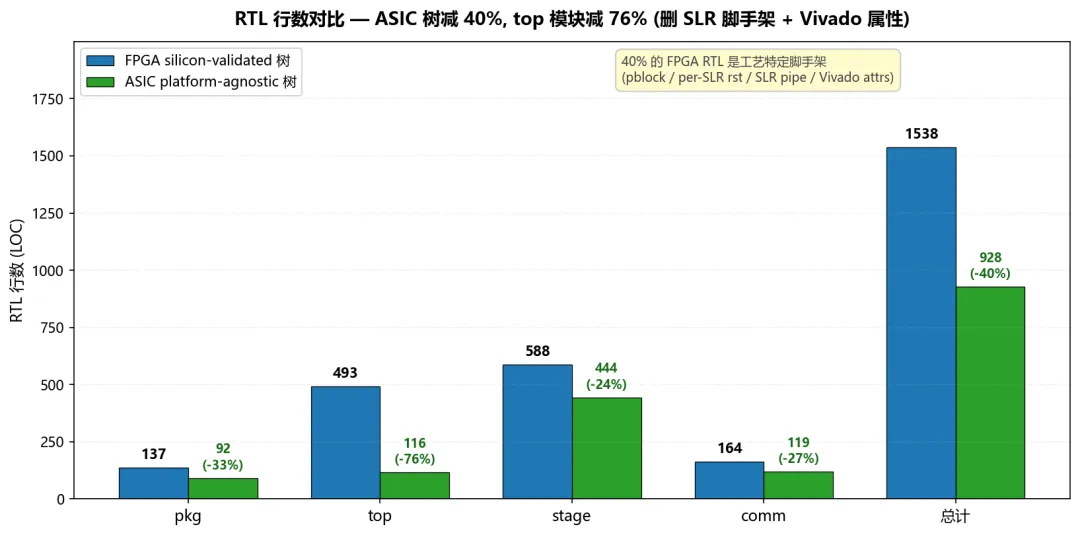
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
-76% |
|
|
|
|
|
|
|
|
|
|
| 总计 | ~1538 | ~928 | -40% |
40% 的 RTL 是 FPGA-specific 的脚手架,ASIC 不需要。
如果 day 1 就明确目标,这部分代码本可以从一开始就走双轨:silicon-validated 树带 SLR 脚手架(用于 FPGA 验证),ASIC 树不带(用于流片预研),并行推进 —— 而不是 FPGA 先跑通了再回头”翻译”到 ASIC。
(c) MS-2 跨 SLR fanout 攻坚(几天 + 一次失败的 5 hr 全流程 build)
MS-2 阶段为了让 P=32 FP32 全 board build 在 VU13P 上时序闭合,反复尝试 controller 跨 SLR fanout 的修复 —— 最终失败,post-route WNS = -3.438 ns,1.44M fanout 跨 SLR3↔SLR1。
这个问题在 ASIC 上根本不存在 —— ASIC 单 die 没有 SLR 概念,clock tree balanced,fanout 1.44M 在 ASIC 上完全可以靠 buffer tree 解决。
如果 day 1 就明确目标,MS-2 阶段完全可以:
-
直接放弃”P=32 全 board 上板”这个 FPGA-specific 目标 -
直接走 MS-2b 的 cmul-only 路径,做 silicon 实证 FP32 算术正确性 -
把跨 SLR fanout 的”失败”作为 ASIC 流片的论据(而不是作为”需要修复的 bug”)提前归档
实际损失:MS-2 攻坚 + 失败 build + 失败诊断,大约 3-5 天纯开发时间。
(d) 其他隐性损失
-
大量 dev log / 综合报告 / 时序分析围绕 FPGA-specific 指标(SLR 平衡、Pblock 命中、Laguna 利用率)展开,这些数据对 ASIC 流片决策几乎没有参考价值 -
v9.0-bfp-product这个 freeze tag 虽然好看,但它是 FPGA 商用化的产物,对 ASIC 流片预研而言只是个副产品 -
早期会跟 AI 反复讨论”P=64 是否能在 VU13P 上装下” —— 答案是不能,但这个问题本身只在 FPGA 是终端目标时才有意义
★
综合估算:如果 day 1 就把目标讲清楚,这个项目至少节省 4-6 周(占总时长的 30-50%)。
6.2 为什么会犯这个错
复盘起来,有三层原因:
原因 1:我自己也是边做边想清楚的
项目启动时我并没有”必然要走 ASIC 流片”的明确决策,这个决策是 Phase 3.2 上板 PASS 之后才浮现的”后续可能性”。
也就是说,目标不是被我隐瞒,而是它本身就是模糊的。
原因 2:AI 默认按”表面目标”最大化
我说”做 128K FP32 FFT 在 VU13P 上跑通”,AI 就理解成”在 VU13P 上做出最强的实现”,而不是”在 VU13P 上做出最能为 ASIC 流片提供论据的实现”。
这两个目标有交集但不重合,差异巨大。
原因 3:没有”目标元层级”的对话机制
我跟 AI 的所有讨论都集中在”具体技术问题怎么解”层面,**从未在某次会话里专门花时间讨论”我到底为什么做这个项目”**。
这种”目标元层级”的对话,在传统团队里是 PM / 架构师做的事 —— 但 AI 辅助开发时没有人替你做,必须你自己主动做。
6.3 如果重来,Day 1 我会怎么开局
1. 写一份 PROJECT_VISION.md 放在 worktree 根目录,而不只是 AGENTS.md
AGENTS.md 是”怎么干”(规则),PROJECT_VISION.md 是”为什么干”(目标)。
明确写:
-
真实终极目标:ASIC 流片量产 -
FPGA 在路径上的角色:silicon-validated 算法验证平台 + ASIC 资源外推数据来源 -
不是目标的事:FPGA 商用化 / FPGA 极致性能 / 跨 SLR 完美布局 -
可接受的妥协:FPGA 上跑不动 P=64 / P=128 是预期内,不需要修 -
核心可交付物:ASIC 流片白皮书 + ASIC RTL skeleton + silicon 实证数据
2. 每次新 session 启动,AI 必读的第一份文档是 PROJECT_VISION.md,在 AGENTS.md 之前
3. 架构决策时,AI 必须显式陈述”这个决策对 ASIC 流片的影响”
比如 —— “BFP 数据格式对 FPGA DSP 用量降 90%,但对 ASIC 流片无收益(ASIC mul 不是约束),建议优先级降为 P3″。
这是目标导向的决策口径,跟”这个决策让 FPGA 跑得更快”完全不同。
4. Phase 划分按”对 ASIC 流片的论据贡献”来安排,而不是按”FPGA 性能里程碑”
比如 Phase 3.2 BFP 上板 PASS 应该被定义为”可选商用化里程碑”,而不是”主线 milestone”。
6.4 给所有用 AI 做硬件设计的人的核心警示
★
当你不告诉 AI 真实终极目标时,AI 会按你描述的表面目标(通常是”在当前平台跑通”)给你最大努力。
这种”最大努力”对真实目标的有效性,可能只有 50% 甚至更低。
这不是 AI 的问题,是你给 AI 的 framing 的问题。
AI 是非常优秀的执行者和优化器,但它不会主动追问”你为什么要做这个” —— 这个问题只有你自己能回答。
而回答的清晰度,直接决定了项目所有后续工作的效率。
我这个项目大概有 30-50% 的工作量,如果回到三个月前重做,完全可以不做或大幅简化。
这个数字对我自己是震撼的 —— 它意味着同样三个月时间,本可以多做 3 个 ASIC silicon 实证 build,或者把 Scope B 的 4 项后续工作(FP IP 替换 / DFT / DC 综合 / STA)都干掉。
★
不是没努力,是努力错方向。
六·补 比项目本身更深的冲击 —— AI 在重塑科研协作的颗粒度
★
前面六章讲的是”AI 怎么帮我做完了这个项目”。
这一章想讲的是 —— 这种工作模式,正在从根本上改变高校研究生培养、科研院所做项目的运行方式。
6.5 时空颗粒度的崩塌
传统科研协作的颗粒度是周或天:
-
导师周一布置课题 → 学生周二到周五跑实验 → 下周一汇报 → 讨论改进 → 再过一周 -
课题组长发任务 → 工程师写代码 → 一周后 demo → review → 下一轮迭代
AI 辅助的协作颗粒度直接降到分钟甚至秒:
-
正在开会的间隙,我打开 Cursor,一句话让 AI 把上次会议提到的 corner case 加进 testbench -
跑了 6 小时综合在等结果,中间几分钟我让 AI 先草拟下一阶段的资源外推 plan -
食堂排队时手机连 SSH,让 AI 把昨天的失败 log 总结成一条 dev log 条目 -
晚上睡前让 AI 跑一组隔夜 sweep,第二天早晨起来看汇总报告 -
学术报告路上的高铁车厢里,跟 AI 讨论一个还没想清楚的架构问题,下高铁时已经有了带数字的 plan
物理时空里的”碎片时间”过去是浪费的(刷短视频),现在变成项目推进的实质时间。
★
AI 把”碎片时间”重新激活成了主战场,这对中年学者尤其友好 —— 他们最稀缺的恰恰是”连续 4 小时不被打扰的工作块”。
6.6 高校研究生培养:从”教做”到”教问”
我自己读研时的工作模式很典型 —— 导师布置题目,我去查论文 / 写 RTL / 跑仿真,卡住了再去问,每周组会汇报一次,以”周”为单位推进。
AI 辅助下,研究生工作模式开始出现这些变化:
-
导师布置课题颗粒度可以更粗,但要求目标定义更精确(否则 AI 会按表面目标最大化,参考第六章压轴反思) -
学生核心能力从”会写代码、会跑实验”转向 “会问问题、会判断 AI 输出对错、会沉淀知识” -
导师 / 学生交流颗粒度从”周组会”变成 “知识库实时可查” -
论文写作 / 文献综述 / 可视化全程 AI 加速,但数学推导正确性、工程直觉、物理意义校验仍要人工把关
更深的变化是,研究生的”训练目标”本身可能要重新定义。
过去研究生培养的核心是”学会独立完成科研全流程”。但当 AI 能接管 60-80% 的执行环节时,真正稀缺的能力变成:
-
判断”什么问题值得做”(目标定义) —— AI 不会主动追问”你为什么做这个” -
判断”AI 给的答案对不对”(质量把关) —— 算法正确性、物理意义、工程直觉 -
把项目知识沉淀成可传承的形态(知识工程)
★
这三件事都不在传统研究生课程里。
未来可能要专门加一门”AI 辅助科研方法学”。
6.7 科研院所做项目:交付物从”代码 + 文档”升级到”项目本身”
这是我自己最直接体会到的变化。
传统模式:
-
3-5 人 × 6-12 个月 -
交付物 = 源代码 + 几十页设计文档 + demo 视频 -
客户接手后,绝大多数细节”刻在原作者脑子里”,已经丢失 -
想做二次开发,必须把原作者请回来
AI 辅助模式:
-
1 人 × 数天到数周(复杂项目小团队 2-3 人 × 1-2 月) -
交付物 = 源代码 + 完整 wiki 知识库 + AGENTS.md规则文件 + Canvas 拓扑图 + dev log 全历史 + chat 索引 -
客户接手后: -
直接打开 Cursor,加载 wiki,自然语言提问:”MS-2 为什么 FAIL?”、”BFP 的 normalize barrel shifter 怎么设计?”、”P 从 128 升到 256 影响哪些模块?” -
AI 基于知识库给结构化、有引用、有 cross-link 的答案 -
想做二次开发,直接让 AI 基于现有 wiki + 代码接力推进
★
这是交付物的”价值密度”质变 —— 同样一份代码,带完整 wiki 的版本对客户的价值是不带的 5-10 倍。
更深的影响:
-
小团队 / 个体工程师可以承接以前只有大团队能接的项目 —— AI 把”知识传承 / 接手成本”这条传统大团队的护城河抹平了 -
科研院所的人员结构开始失衡 —— 过去 10 人组现在 2-3 人就能跑,剩下的人要么转向更高维度(指标定义、跨项目协调、对外议价),要么被边缘化 -
横向项目的定价模型开始变化 —— “带 wiki 知识库的 AI 友好交付”应当比”源代码 + PDF”贵 2-3 倍,因为客户后续二次开发省的钱多得多
6.8 给个人 + 机构的几条具体建议
如果你是研究生 / 一线工程师:
-
优先沉淀,而不是优先输出 —— 多花 20% 时间写 wiki,后续节省别人接手的 80% 成本 -
把”会问问题”练到比”会写代码”更熟 —— 工具会变,问题不会 -
接受”工作时空被打散” —— 不要再追求”完整 4 小时不被打扰” —— 现在的工作模式是”碎片时间 × N 个并行任务”,这是优势不是劣势 -
把”目标定义”当作核心技能 —— AI 可以帮你做 100 种”怎么做”,但只有你能选”做什么”
如果你是机构 / 团队管理者:
-
重新定义交付物标准 —— 代码不带 wiki = 没交付完整,写进合同 / 立项书 -
重新评估外包预算 —— “AI-ready 知识库版本”定价应是传统版本的 2-3 倍 -
重新设计团队结构 —— 不是裁员,是把”中游执行层”的工作重心调到”知识工程 + 质量把关 + 目标定义” -
建立”项目知识库审计”机制 —— 结题验收除了代码和论文,还要看 wiki 完整度 / cross-link 健康度
6.9 一个不完全的预言
★
未来 3-5 年,”带 wiki 知识库的 AI 友好交付”会从今天的”锦上添花”,变成”项目验收的硬性标准”。
这个变化对小团队是机会,对大机构是冲击。
这三个月的项目,本质上是用一个 FPGA 项目把这套交付模式跑通了一遍。
128K FFT 这件事的技术意义是”silicon BIST PASS + ASIC 流片预研 conditional GO”;
但更深的意义,可能是它验证了”一个人 + AI + 严格的知识工程纪律”这个工作模式的可行性 —— 在硬件设计这种过去被认为”必须大团队 + 长周期”的领域里,这个模式同样能跑出来。
而硬件设计如果都能这么跑,几乎所有别的工程领域都能跑得更顺。
七、给后来人的建议
把这条最大的教训放在第 0 条,后面 4 条是技术层面的:
0. 先把”真实终极目标”跟 AI 讲清楚,再讲”当前要做什么”
这是元层级的事,所有技术决策的前提。
如果你的真实目标是 ASIC 流片 / IP 授权 / 学术验证 / 商用产品,这四种目标会导出完全不同的工作量分配。
★
模糊的目标 + 优秀的 AI = 高效率地做错事。
1. 先写规则文件,再写代码
AGENTS.md 之于 AI 项目,等价于 Makefile 之于传统软件 —— 它定义了”怎么干”的边界。
规则越清晰,AI 输出越收敛。
同时配套写 PROJECT_VISION.md,定义”为什么干”。
2. 把 wiki 当 first-class deliverable
代码改动如果不连带 wiki 同步,等于没做。
下个月、下个季度、下个工程师接手时,wiki 是唯一的 ground truth。
3. bit-exact 不是过度追求,是工程边界
max_rel = 1e-7 不是合格,是黄牌。
要么金模有 FMA,要么 RTL latency 错了,要么数据格式不一致。
追到 0,别凑合。
4. silicon 才是真理,Vivado 是参考
Vivado WNS / 资源报告是工程余量,不是物理事实。
有条件就上板,没条件至少做小规模 silicon 实证(像我们 MS-2b 的 cmul-only build),把”silicon 实际行为 vs Vivado 报告”的 gap 量化下来 —— 这是后续所有架构 / 流片决策的硬数据基础。
八、最后
回到开篇那句话:
★
AI 不能替你做架构决策,但能把”做对一次”的经验,以可复用的形态沉淀下来,让你在第二次、第三次踩同样坑时,先停一秒。
这三个月,我做对的事大概就两件,做错的事一件:
做对 1:从第一天起就把 wiki / golden / 规则文件当作 first-class 交付物,让 AI 跨 session 能续上。
做对 2:架构决策、算法正确性、silicon 实证这三件事自己扛,其他一切交给 AI 做模板化生成 + 复利沉淀。
做错 1:没在 day 1 跟 AI 讲清楚”FPGA 是 ASIC 流片的验证平台,不是产品终点” —— 导致 30-50% 的工作量花在了对真实目标无效的方向上。
如果让我在这两条”做对”和这一条”做错”之间排序 —— 那条做错的事的代价,比两条做对的事的收益加起来还大。
128K FP32 FFT 这件事,从 2D 不可行,到 silicon BIST PASS,到 ASIC 流片预研 conditional GO,全程没有奇迹,只有一步一步把决策数字化、把经验文档化、把工具链规范化。
但回头看 —— 如果三个月前我就把”真实目标”和”工作流程”同时讲清楚,这些里程碑可能在两个月就能到达。
如果你也在做 FPGA / ASIC,且也在尝试用 AI 加速,希望这篇文章里的某条经验能让你少踩一个坑。
尤其是那条最大的、最贵的、最容易被忽略的元层级的坑:
★
先把”为什么做”讲清楚,再讲”怎么做”。
互动 / 引用
如果这篇文章对你有帮助,欢迎在评论区留下你的想法:
-
你在用 AI 做硬件 / FPGA 开发吗?踩过哪些坑? -
文章里哪条经验你觉得最有共鸣 / 最有争议? -
你有自己的”最大教训”想分享吗?
转载请注明:出处 + 作者 + 原文链接(公众号原文链接)。
未经授权的商业转载,请联系作者。
本文写于 2026-05-02。原始项目仓库 git 历史 + wiki 知识库 + 27 页 ASIC 白皮书可作为本文所有数据的 ground truth 来源。