 夜雨聆风
夜雨聆风





AI 写代码总是跑偏?这个工具帮你想清楚自己要写什么……

在AI编程中最让人抓狂的是你跟它来回拉扯五六轮之后,原始需求早就不知道飘到哪里去了。换一个新会话,它对你的项目一无所知,一切从零开始,仿佛在跟一个失忆的天才反复对话。其实我觉得这不是 AI 太蠢,是我们少了一样东西。
传统开发里,我们用需求文档、PRD、设计稿来”钉住”需求。到了 AI 编程时代呢?大部分人直接对着对话框就开始敲了,结果往往偏离预期,这就好比你跟装修师傅说”随便搞搞好看就行”,然后验收时嫌弃风格不对。师傅冤不冤?所以核心问题从来不是AI 能不能写代码,而是”AI 有没有理解你要什么”。
目前市面上用 AI 写代码的人,大致分成了三派。
第一派:Vibe Coding(氛围编程)。翻译成人话就是主打一个随性。
想怎么写就怎么写,AI 你看着办吧。速度确实快,适合出原型、做 demo、验证想法。但一旦上了正式项目,这种方式就像闭着眼睛开高速,偶尔运气好没事,翻车是迟早的。古人说”谋定而后动”,Vibe Coding 派的反义词大概就是”先动再说”。
第二派:工程纪律派。以 SuperPowers 等框架为代表,给 AI 配备完整的工程流程:brainstorming、规格定义、计划拆分、TDD、代码审查……全流程 7 个阶段,23 个角色分工,纪律拉满。这就像给那个实习生配了一个完整的项目管理体系:需求评审、技术方案、单元测试、代码审查,一样不少。听上去很完美对吧?但源码翻开来一看,所有这些”铁律”——都是用自然语言写在 prompt 里的。用大白话说就是:规则全靠自觉遵守。SuperPowers 的技能注入文件里有这么一段话:
IF A SKILL APPLIES TO YOUR TASK, YOU DO NOT HAVE A CHOICE.YOU MUST USE IT. This is not negotiable. This is not optional.
语气够狠了吧?问题是——这段话本身就是 prompt,不是程序逻辑。它没有一行可执行代码来强制执行这些规则。就像你在公司墙上贴了禁止迟到,但门口没有打卡机。更离谱的是,SuperPowers 的审查循环没有最大迭代次数限制。如果 AI 写的代码一直审不过,它会无限循环下去。每次审查都要调 LLM,5 个任务最少 16 次子代理调用,审不过的话数字还能膨胀到 26 次。没有超时、没有成本上限,这比我的加班还狠。还有一个隐蔽的坑就是每个任务创建独立的子代理,子代理不继承完整上下文。这就意味着 Task 7 的实现者完全不知道 Task 3 改了什么接口。每个子代理都像是第一天上班的新人,只拿到了主管(也是 LLM)认为它需要知道的信息。
所以 SuperPowers 解决了很多问题,但也留下了一个根本矛盾,当所有的规则都依赖被约束者的自觉,可靠性上限就取决于 LLM 本身的可靠度。
这让我想起一句话:你可以给猴子一套西装,但它依然是一只猴子。
第三派:规范驱动(Spec-Driven)。这就是今天的主角——OpenSpec 的思路。核心逻辑非常朴素,在 AI 写代码之前,先用结构化的”规范文件”把需求定义清楚。不是口头约定,不是聊天记录,是白纸黑字写下来的契约。听起来是不是很耳熟?没错,这就是软件工程里需求先行的老传统。只不过 OpenSpec 把这个老传统用一种特别轻量的方式搬到了 AI 编程场景里。
别被OpenSpec的名字吓到
OpenSpec 不是又一个让 AI 写代码更快的工具,而是让 AI 写代码写得更准确的框架。我认为它解决的不是速度问题,而是方向问题。打个比方,SuperPowers 像是给车装了更好的刹车系统确保你能停下来。OpenSpec 像是给你一张导航地图确保你开的方向是对的。刹车再好,方向不对也没用。
OpenSpec 的 GitHub 仓库来自 Fission-AI 团队,目前支持了很多AI 编程工具,像我们常用的Claude Code和Cursor都能接上。
openspec initnpm install -g @fission-ai/openspec@latest
下面就是选择你使用的AI工具类型
然后就会多出这些文件,在根目录下生成一个openspec目录、在.claude目录中生成commands和skills目录。
OpenSpec 三条命令走天下
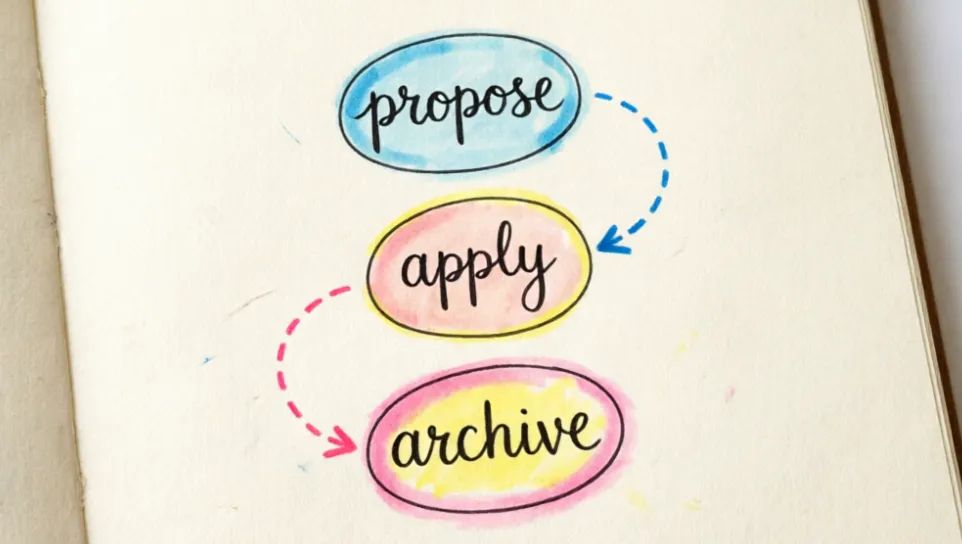
我对于OpenSpec 的实际使用体验是就是这三条命令,
第一步Propose提出变更,它会自动创建变更目录,这一步的核心价值是:让 AI 在写代码之前先对齐”要做什么”。不是直接跳到实现,而是先想清楚。
第二步Apply执行实现,确认方案没问题后,输入 /opsx:apply。AI 按 tasks.md 逐项实现。实现过程中发现方案不对直接改 design.md,然后继续 apply,不需要从头来过。
第三步Archive归档收敛,实现完成后,输入 /opsx:archive。归档做三件事:把增量规范合并到主规范、把变更目录移到归档区、保留完整的决策记录。下次打开项目,specs/ 里已经包含了上一次变更的行为描述。新的变更会基于这份更新后的主规范来写。
这就是一个良性循环:Specs 描述当前行为 → Changes 提出修改 → 实现让修改落地 → Archive 合并到 Specs → Specs 变成新的真相 → 下一个 Change 继续基于更新后的 Specs。
Spec 不是又一层容易过期的文档
很多人会觉得这就是多了一层文档要维护,但是你要知道代码擅长表达局部逻辑,不擅长表达系统级的业务语义边界。
比如用户登录失败 5 次后锁定账户这条规则可以用代码实现,但代码不会主动告诉后来者这是一个必须长期坚持的安全策略。如果下一个人来做需求优化时顺手把锁定逻辑改了,代码编译照样通过,测试照样绿灯,但安全策略已经被悄悄瓦解了。
卢曼卡片工作法里有一个精妙的分类:永久卡片和过程卡片。OpenSpec 的主规范就像永久卡片长期有效、反复引用;归档记录就像过程卡片记录当时的决策上下文。用一句话判断是否需要写 Spec,这条规则如果不写下来,未来是否很容易被无意中破坏,如果是,就值得写。
OpenSpec 别啥项目都往上套
如果你是生产级项目,需要长期维护;多人协作,业务规则复杂;AI 长期参与开发,需要持续对齐理解;需求变更频繁,需要追溯历史。不要犹豫直接上OpenSpec。
对于特别轻量的项目,Claude Code 的 Plan Mode 加上 CLAUDE.md 里写点项目规则,可能就足够了。等项目出现多人协作、规则越来越多、历史变更难追踪时,再升级到 OpenSpec 也不迟。这就像健身一样,你不需要第一天就去报私教课。先跑跑步,觉得有瓶颈了再加专业训练也不迟。
写在最后
OpenSpec 做的事情很朴素,在 AI 写代码之前,帮你和 AI 对齐一次”要做什么”。在写完代码之后,帮你把稳定下来的认知沉淀下来。我们在日常开发中浪费最多时间的不是写代码本身,而是在需求理解偏差上反复拉扯。AI 改了你不想要的,你让它改回来,它又改过头了。来回三轮,时间就没了,心情也废了。OpenSpec 要解决的就是这种无声的时间黑洞。
快速开发和高质量代码之间,差距不在工具本身,而在于你有没有在 AI 开始写代码之前,把要写什么这件事定义清楚。这个道理其实不新。几千年前的《孙子兵法》就说”胜兵先胜而后求战,败兵先战而后求胜“。翻译成程序员的话就是:想清楚再动手,永远比动手再想清楚更高效。AI 编程时代,这个道理不但没有过时,反而更重要了。因为 AI 的执行速度太快了方向一旦偏了,跑偏的效率也是指数级的。
所以,与其追求让 AI 写代码更快,不如先追求让 AI 写代码更准。OpenSpec 不是万能药,但它至少给了我们一个方向,先对齐,再动手;先定义,再执行。
现在看来,规范才是核心资产,代码只是规范的衍生物。在这个模式下,程序员的个人能力不再体现为我能默写出复杂的算法,而是体现为我拥有极强的系统抽象能力,能写出完美的契约,然后指挥 AI 帮我搬砖。