 夜雨聆风
夜雨聆风





AI 的规模之痛:当模型变强时,系统却在偷偷出错
看了 z.ai 团队最近发的那篇技术博客,讲 GLM-5 在大规模 Coding Agent 服务中踩的坑。说实话,看完有点震撼。不是因为 bug 有多难,而是这件事本身:AI 的 Scaling 不只是模型的问题,底层系统工程一旦跟不上,用户那边就开始看到乱码了。
事情是这样的。GLM-5 上线 Coding Agent 服务后,每天处理数亿请求。从三月开始,有用户反馈说模型输出的结果不对劲——有时候乱码,有时候重复,偶尔还冒出些罕见字符。
这种问题你第一反应是什么?模型退化了?长上下文的质量下降了?
他们团队也是这么想的。排查后发现没做任何降低精度的优化。那问题出在哪?
更诡异的是,本地根本复现不了。同一个请求跑几百遍,次次正常。
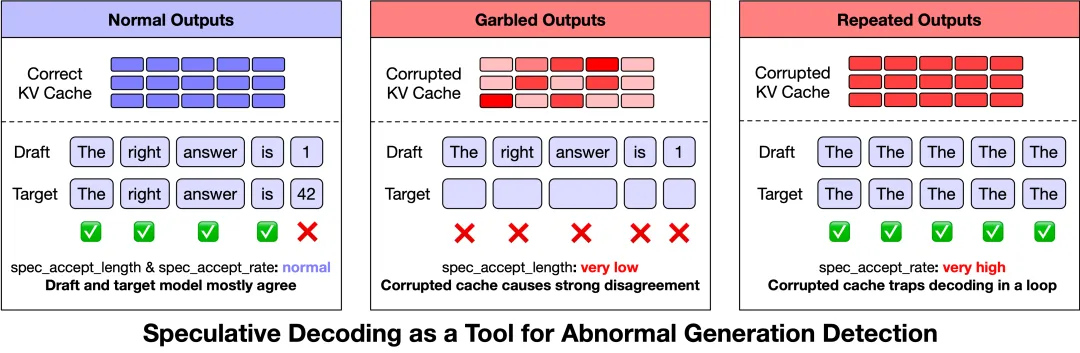
▲ 原文图 1:Speculative Decoding 的指标居然成了异常检测信号
最后他们想了个办法:把生产环境的日志匿名化后完整回放,保持原始的并发分布和请求时序。还是没复现。继续加码,调整 prefill-decode 的分离比,模拟高峰期的压力。这才终于露出了狐狸尾巴——大约每一万次请求里有三到五次异常。
一万分之三。用户已经能感知到了。

▲ 光鲜的表面 vs 暗涌的底层——用户看到的 AI 和系统工程师面对的 AI,从来不是同一个东西
这让我想到一个事。我们平时测模型,跑几个 demo、测几个 benchmark 就以为稳了。但真上了规模,那些你觉得「不可能发生」的边界条件,每天都在发生。
Bug 一:KV Cache 的”幽灵写入”
第一个 bug 特别有操作系统课程的味道。
为了控制尾延迟,推理引擎里有个超时机制:如果 Prefill 阶段超时,Decode 阶段就会终止请求,回收 KV Cache。
问题在于,这个终止信号没有通知到 Prefill 那边。
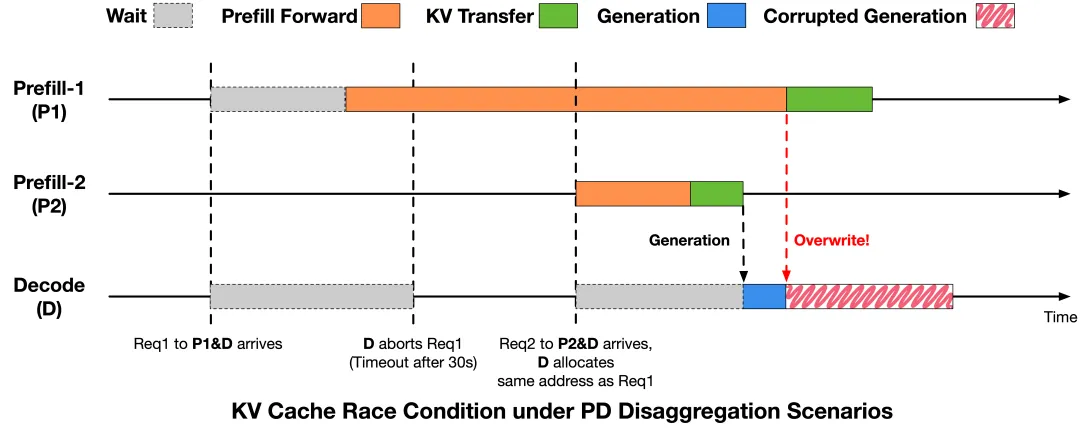
▲ 原文图 2:PD 分离架构下的 KV Cache 竞态条件
Decode 以为请求死了,回收了内存,分配给了新请求。但 Prefill 那边不知道,还在吭哧吭哧地往这块内存里写数据。结果就是新请求的 KV Cache 被老请求的残留写入覆盖了,输出就乱了。
学过操作系统的人看到这儿应该会心一笑。经典的 use-after-free,只不过场景从进程内存变成了跨节点的 GPU 显存,从指针变成了 RDMA 写入。
修的方法也经典:加同步。Decode 终止请求后通知 Prefill,Prefill 确认所有写入都完成了(或者压根没开始),Decode 才回收内存。
就这一个改动,异常率从 0.1% 降到了 0.03%。
Bug 二:数据还没到,计算已经开始了
第二个 bug 更像是流水线同步的问题。
Coding Agent 的输入平均超过 7 万 token,所以 HiCache(分层 KV 缓存)成了关键优化。原理是从 CPU 内存里异步加载历史前缀缓存,和计算并行执行,提升性能。
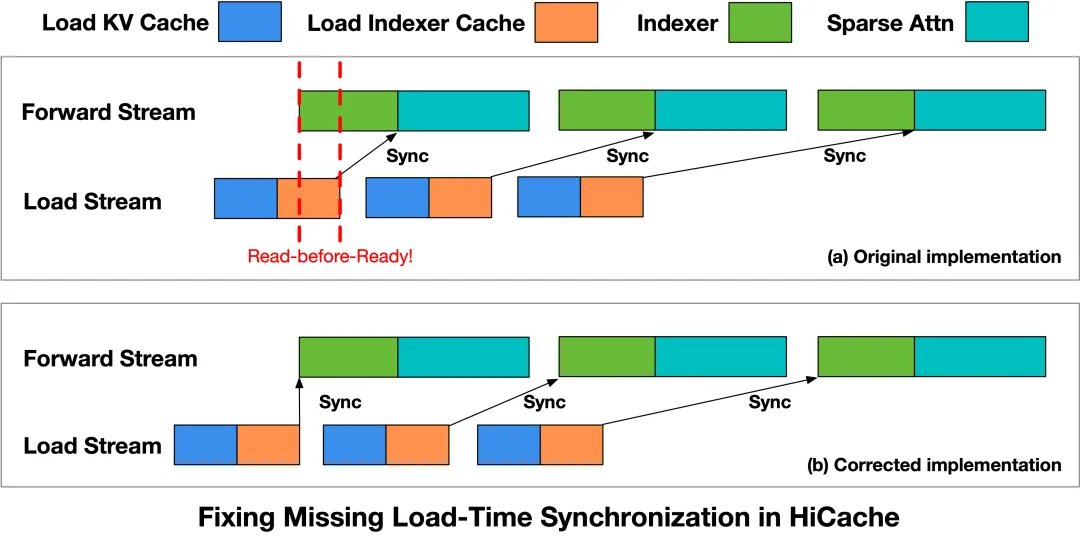
▲ 原文图 3:HiCache 中缺失的加载 – 使用同步
但实现的时候漏掉了一个同步点:Indexer 的计算没等 Indexer cache 加载完就开始跑了。拿着不完整的数据做索引,后续的 sparse attention 全歪了。
这个 bug 让我想起小时候看的流水线工厂纪录片——传送带还没把零件送到,装配线已经开始拧螺丝了。
修复很直接:在 Indexer kernel 启动前加一个同步点,确保数据到位再计算。这个 fix 已经提交给了 SGLang 社区。
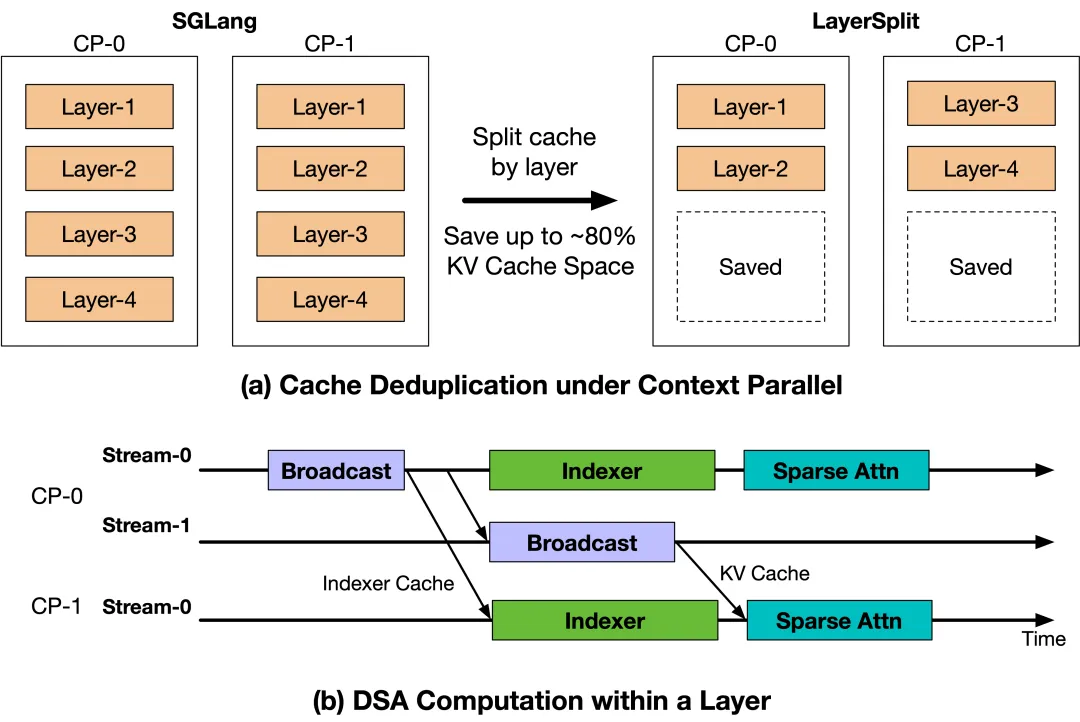
▲ 原文图 4:LayerSplit——按层拆分 KV Cache 存储
最有意思的发现:性能优化变成了质量检测
整篇文章我最喜欢的是这个点。
Speculative Decoding(推测解码)原本是个性能优化技术:用小模型先猜几个 token,大模型验证,猜对了就加速。
但他们发现,当模型输出异常时,speculative decoding 的指标会出现非常稳定的异常模式:
-
• 乱码和罕见字符 → spec_accept_length极低(小模型猜的几乎全被拒绝,说明 KV Cache 状态不一致) -
• 重复输出 → spec_accept_rate极高(损坏的缓存让注意力模式退化,陷入了高置信度的循环)
于是他们把一个性能优化工具变成了实时的质量监控信号。超过 128 token 后如果 spec_accept_length 持续低于 1.4,或者 spec_accept_rate 超过 0.96,就主动终止生成,交给负载均衡器重试。
一个用来加速的东西,意外成了检测 bug 的探针。这种副产品往往比原始目的更有价值。
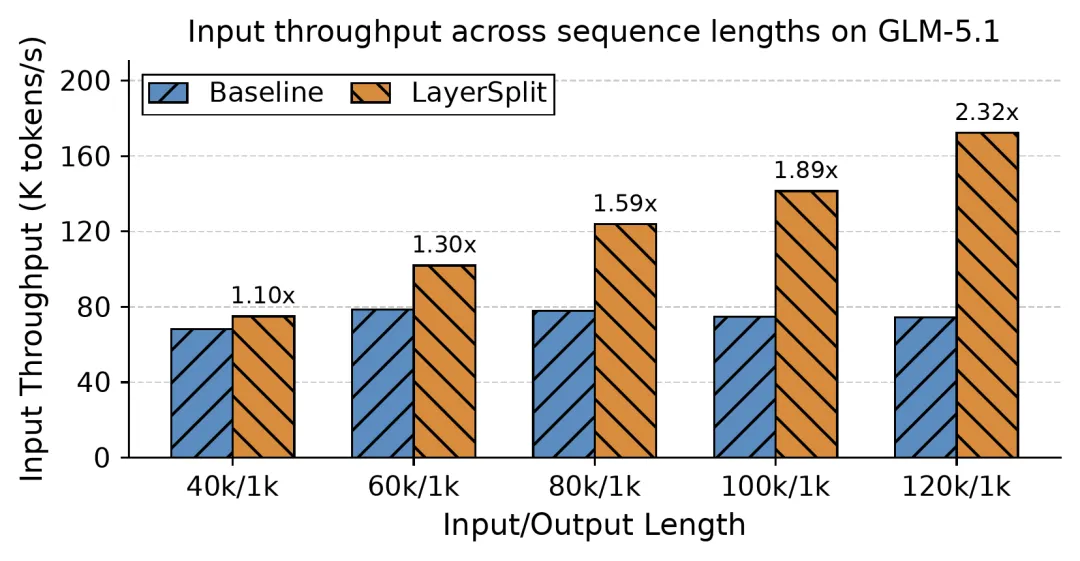
▲ 原文图 5:GLM-5.1 + LayerSplit 的吞吐量提升,长上下文场景提升最高达 132%
感想
看完这篇文章,最大的感受是:AI 行业的 Scaling Law 叙事太聚焦于模型了。
我们每天聊参数量、训练数据、benchmark 分数。但真正让几亿人用起来的时候,决定体验的不是模型能不能答对,而是推理系统会不会在百万并发中偷偷搞混某个请求的状态。
z.ai 这篇博客真正有价值的地方,不是他们修了哪几个 bug,而是他们坦诚地展示了一个事实:规模本身就是一种测试。万分之一概率才会触发的 race condition,在每天数亿请求面前,不再是「可以忽略的边界情况」,而是用户实实在在看到的乱码。
模型强不强看论文,系统稳不稳看工程。
你遇到过那种「本地跑得好好的,一上线就出问题」的 bug 吗?当时花了多久才找到根因?
原文参考
z.ai Team. Scaling Pain of Coding Agent Serving: Lessons from Debugging GLM-5 at Scale. z.ai Blog.https://z.ai/blog/scaling-pain