 夜雨聆风
夜雨聆风





AI SoC总线互联
AI大算力芯片里的“内部高速路”:NoC片上互联设计,到底在设计什么?
现在做AI大算力芯片、复杂SoC和多裸片芯粒,片上网络NoC已经不是“锦上添花”,而是决定芯片快不快、稳不稳、能不能把算力真正跑出来的核心一环。
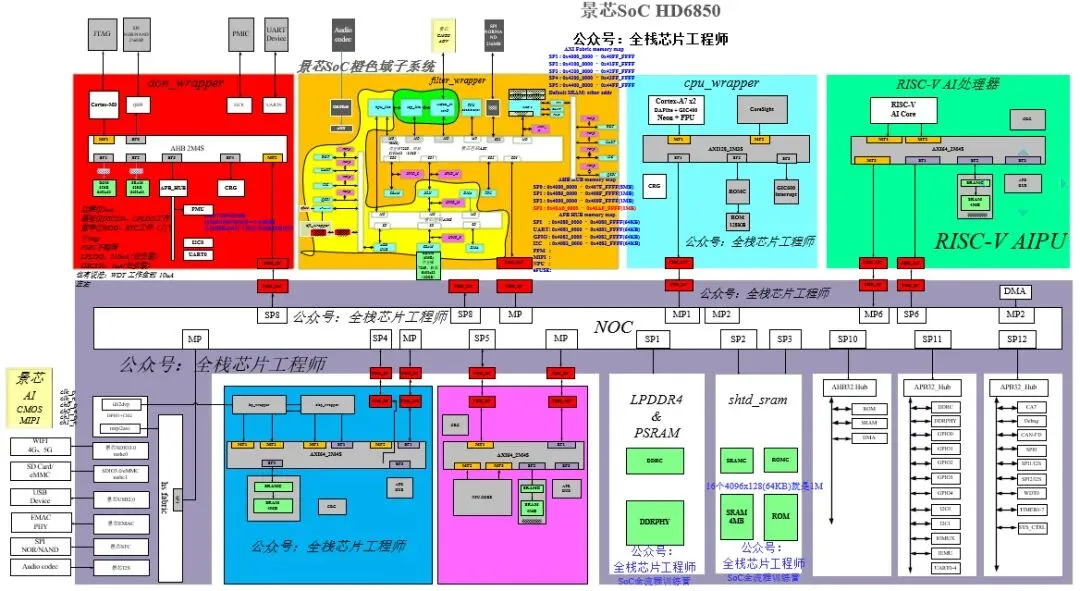
以前大家更关心算力够不够、内存大不大,现在数据量爆炸,数据堵在路上、传得慢、费电,反而成了最大瓶颈。NoC就像芯片内部的交通路网,管着所有计算单元、内存、接口之间的数据怎么跑、走哪条路、不堵车、不冲突。
先简单说下NoC是干嘛的。
芯片里有CPU、NPU、加速器、内存、各种接口,这么多模块要互相传数据,不能像以前一条总线挤着走,必须用一套分布式的“片上网络”,靠路由器、接口、链路把数据打包、转发、送到目的地,这就是NoC。
做NoC最关键的,先看两件事:数据流量是什么样子、要不要缓存一致性。
CPU集群一般必须用一致性NoC,因为要共享内存、数据要实时同步,大家看到的内容得一样;AI加速器、NPU这些大多用非一致性,靠主动搬数据、本地存东西,功耗更低、吞吐更高。
行业里基本形成共识:
• 要共享内存、强同步的CPU场景 → 上一致性NoC
• 重吞吐、可显式搬运数据的AI加速 → 非一致性更划算
一致性NoC听起来高级,但功耗、面积、设计难度都高很多。现在大型芯片普遍做法是:把一致性域和非一致性域分开,CPU、内存等关键部分用一致性,其他外设、低速模块走简单读写,两套网络物理隔开、逻辑独立跑,既够用又省钱省功耗。
早些年大厂很多自己写简单的NoC,够用就行。现在芯片规模几十亿门,AI芯片数据流转又乱又复杂,自研很难搞定布局布线、时序和扩展,行业基本都转向商用NoC IP方案。厂商提供模块化、可配置的工具,按需求选流量类型、要不要一致,自动生成拓扑、例化组件,效率和可靠性都比自研高很多。
这里面难度差别也很大:
• I/O一致性多是外设读CPU缓存,不用反向同步,相对简单
• full缓存一致性要保证一堆CPU核心看到的数据完全一样,状态管理极复杂,出问题就会读错数据
现在芯粒、3D堆叠越来越多,NoC又多了一层“分层设计”的要求。
常见AI芯粒架构大概是三颗:系统芯粒、CPU芯粒、AI加速器芯粒。系统芯粒要同时接两种接口:跟CPU要保持缓存一致,管全局内存;跟加速器只要I/O一致就行,加速器自己有本地内存,不用全局同步。
多裸片里一般会放多套独立NoC,不同子网络之间可以连,但默认用非一致性链路,适配异构芯粒。而且上电之后,NoC还要能自己识别拓扑、认出哪个芯粒在哪、重配网络,自动分配路由,让不同芯粒访问同个地址也能走最优路径,不打架、不绕路。
不管是哪种NoC,做多网络设计都要讲究全局规划、分层优化,也就是常说的PPA——性能、功耗、面积一起平衡。
通常顶层两套主干NoC连所有子系统,下面再按带宽、速度、外设类型拆专用网络,高速AI外设和低速外设各走各的,互不影响。
现在高端芯片还会把控制平面和数据平面分开:管理网络只做配置、监控、上下电,不占业务带宽,保证系统稳定。芯片按物理区域拆分、内存按地址分到不同网络,也能大幅提升并发,减少冲突。
设计思路也在变:以前NoC是最后补上的模块,现在要从一开始就定好,和算力、内存并列当成三大核心。从数据中心、板卡、芯片、芯粒一路往下拆,先定全局架构,再落地子模块,性能从上往下传,实现从下往上做,尽量少走弯路。
总的来看,NoC早就不是芯片里的小配角了。
从单裸片到芯粒、3D堆叠,数据传输的地位越来越高。以后大家会更看重标准化互联、多厂商兼容、动态拓扑自适应,这些东西做好,AI芯片的算力才能真正“释放出来”,而不是卡在数据路上。
