想做 AI 数据标注?这篇文章帮你避开 90% 的坑
写在前面 数据标注这个行业从底到顶差距极大。最底层是按件计费的画框工,国内多数月薪在 3000-6000 元区间[¹],随时可能被自动化预标注挤掉饭碗;最顶层是给大模型做 RLHF 偏好排序的 AI Trainer,海外平台专家级时薪 30-65 美元,国内大厂大模型标注岗月薪可达 1.5 万到 5 万[²]。 同样叫”数据标注员”,不同层级之间隔着十几倍的收入差距,和完全不同的能力要求。 1、数据标注到底是个什么工作,分几层,每层在做什么? 2、一条务实的学习路径,从零基础到能拿到 offer 大概需要多久? 如果你是想转行的成年人,没有 AI 背景但愿意系统性投入 3-6 个月,这篇文章就是写给你的。我会尽量把话说透,少讲大道理,多给具体的判断标准。 这期文章比较长,预计阅读时间35分钟。建议收藏慢慢看~
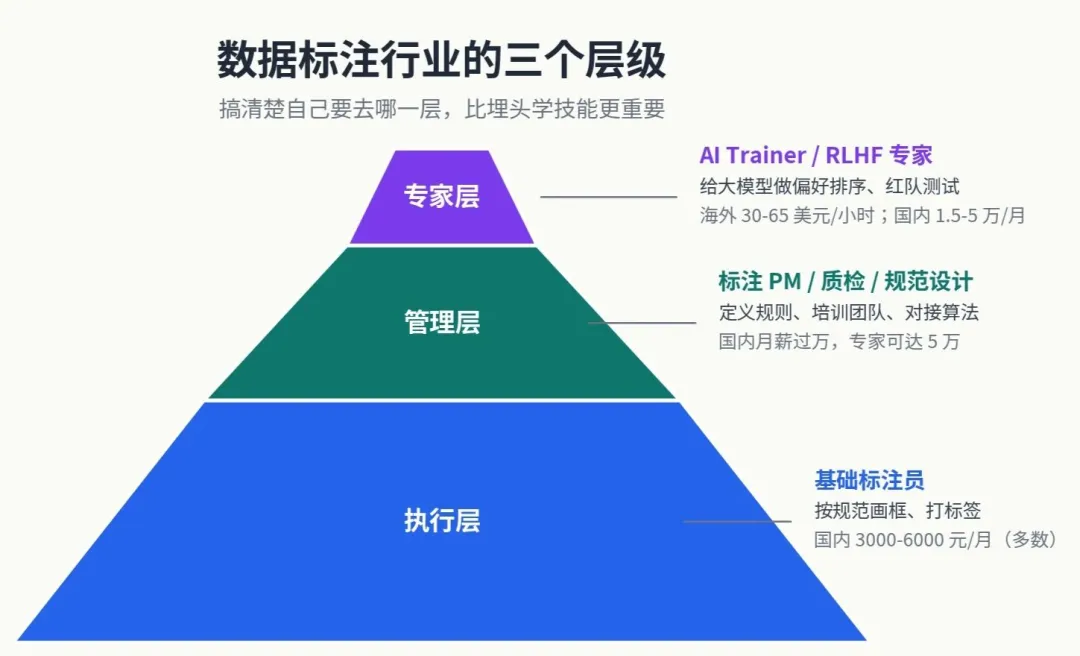
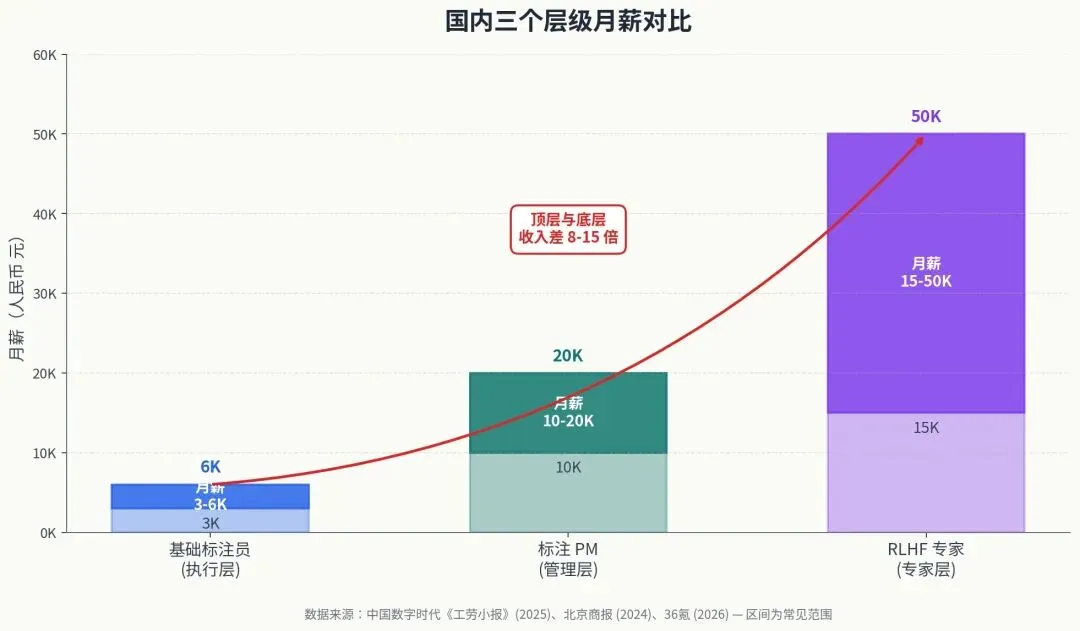
1. 一句话定义 模型本身只能看到一堆数字、像素、字符。是人来告诉它:”这张图里框起来的是行人””这句话表达的是讽刺””这个回答比那个回答好”。AI 学到的所有”常识”,都是从这些标签里来的。 打个不太严谨但好理解的比方:如果说算法工程师是 AI 的”大脑设计师”,那么数据标注员就是 AI 的”启蒙老师”。教科书写得好不好,直接决定了学生能学到什么。 2. 政策风向:这是个被国家明确支持的行业 如果你不确定这个行业的稳定性,2024 年 12 月有一个重要信号:国家发改委、工信部、网信办、人社部联合印发了《关于促进数据标注产业高质量发展的实施意见》[³]。这是国家层面第一次专门为数据标注产业出台扶持政策。 紧接着 2025 年 8 月,中国信通院联合中电信发布了《数据标注产业发展研究报告(2025年)》[⁴],系统梳理了行业发展的六大核心要素——技术创新、行业赋能、生态培育、标准应用、人才培养、安全保障。这意味着数据标注不再是默默无闻的”AI 民工”行业,而是被作为国家战略的一部分对待。 对你的意义是:这个行业不是即将消失的夕阳产业,而是正在快速分化、向上抬升的成长行业。 3. 为什么 AI 越发达,标注反而越值钱 很多人有个误区,觉得”AI 都能自己学了,还要人标注干嘛”。这个理解恰好反了。 ChatGPT 之所以比之前的 GPT-3 让人惊艳,关键不是模型架构变了多少,而是 OpenAI 投入了大量资源做 RLHF(基于人类反馈的强化学习)——本质上就是雇了一批高质量标注员,对模型的回答做精细的偏好排序。 行业里最具说服力的证据是 Scale AI——这家做数据标注的公司,2025 年 6 月被 Meta 以 143 亿美元买下 49% 股权,估值达到 290 亿美元[⁵],是当年最大的 AI 私募交易之一。 模型架构是开源的,数据才是护城河。 这就是为什么数据标注公司能拿到这么高的估值。4. 行业的三个层级(这是全文最重要的判断框架) 我把数据标注从业者分成三层。搞清楚自己要去哪一层,比埋头学技能更重要。 收入区间:根据中国数字时代 2025 年发表的工劳调查,国内全职标注工人的平均月工资在 2000-2600 元之间[¹];招聘平台职友集统计显示,88.5% 的数据标注员月薪在 3000-6000 元区间[¹]。海外平台基础任务一般 15-30 美元/小时[²]。 风险:这一层正在被 AI 预标注侵蚀。例如 2025 年 7 月,xAI 一次性裁掉约 500 名通用型数据标注员(约占其标注团队的三分之一)[⁵]。Scale AI 同月也裁掉了 14% 的全职员工和约 500 名合同工。 如果你只能做到这一层,不建议把它当成长期职业,更适合作为短期过渡。
第二层:管理层(标注 PM / 质检 / 规范设计)
工作内容:定义标注规则、培训标注员、做质量抽检、和算法团队对接需求、统计标注一致性。 收入区间:根据 2024 年北京商报报道,国内”高级 AI 数据标注师甚至专家”月薪一般会过万元,高者可达 5 万元[²]。 进入门槛:需要懂业务逻辑、懂模型需求、能写规范文档、会做基础数据分析。一般要 3-6 个月的执行层经验打底。 这一层是大多数人转行后能稳定到达的位置,也是性价比最高的目标。
第三层:专家层(AI Trainer / RLHF 标注 / 领域专家)
工作内容:给大模型的回答做偏好排序、写高质量 SFT 数据、做红队测试、设计评估方案。 收入区间:海外 Outlier 等平台对编程、数学、医学等专业领域的 RLHF 标注,时薪可达 30-65 美元;中级 RLHF 贡献者 20-30 美元/小时[²]。国内一线大厂大模型标注岗(如百度文心一言)月薪在 9000-15000 元,专家级岗位可达 5 万元以上[²]。 进入门槛:需要扎实的专业背景(至少在某一领域有判断力)+ 良好的英语读写能力 + 对 AI 模型的理解。 把这三层的画像在脑子里立起来。后面所有的学习建议,都是为了帮你尽快越过第一层、稳定在第二层、有机会冲击第三层。 讲再多概念不如看一次具体的工作。 任务听起来简单——把图里所有行人用框圈出来。但实际工作中你会遇到这些情况: 成熟的规范会要求”按完整人体的估计位置画框(包括被遮挡部分)”——也就是你要”脑补”出他被挡住的腿在哪里,把框画到地面位置。这是为了训练模型预测被遮挡物体的能力,自动驾驶里这关乎生死。 参考公开的 Waymo Open Dataset 标注规范[⁶]:行人标签只用于”走路或骑代步车(电动滑板、平衡车、滑板等)的人”,车内的人不标(除非站在车顶或站在车外踏板上)。海报上的人、雕像、模特按规范都不算行人——模型要学的是”会移动的人”。 大部分项目规定低于一定像素高度的目标不标注,因为太小的样本对模型帮助不大,反而引入噪声。Waymo 规范规定 3D 标注框只覆盖到 75 米范围内的目标[⁶]。 依然要画两个独立的框。即使重叠率高也要分开标,这是检测任务的基本要求。 你看,光是”标行人”这一件事,就能展开几十条规则。Waymo 的公开标注规范文档详细规定了这些边界情况,而商业项目内部的规范通常更复杂。 这告诉你一件重要的事:标注员的核心能力不是”画得快”,是”判断准”。 普通标注员看到模糊情况就硬猜;好的标注员会停下来查规范;优秀的标注员会发现规范没覆盖的情况,反馈给项目组,推动规范迭代。 任务:把评论标成”正面 / 中性 / 负面”。看几条真实例子: 新手会标”正面”。 但成熟规范会标”中性”——这条评论只描述了客观事实,”包装”和”物流”是平台/卖家服务,不是商品本身的情感。这是细粒度情感标注的基本功。评论 B:”这个价格能买到这种质量,我也是没谁了。” 字面看像负面(”没谁了”是吐槽),实际是反讽 ,表达”性价比超出预期”,是正面。 评论 C:”还行吧,没我想象的那么好,但也不算差,凑合用吧。” 混合情感。 如果只能选一个标签,规范一般规定”以最后表达的态度为准”。但更专业的做法是用 aspect-based sentiment analysis:把句子拆成几个维度分别标注。文本标注比图像更依赖语言文化背景。同一句话不同人理解可能完全不同。所以高质量文本标注项目会要求标注员之间做一致性测试,常用的指标是 Cohen’s Kappa(详见后文)。
场景三:RLHF 偏好排序(这是当前最值钱的标注)
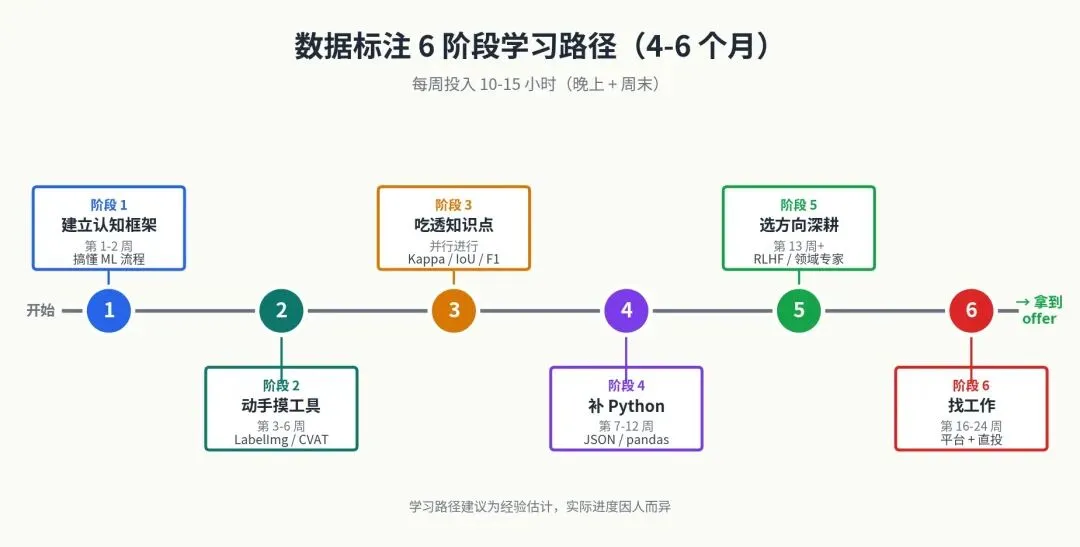
回答 A: “我无法提供医疗建议,请咨询专业兽医。”回答 B: “立即联系兽医或宠物急诊!布洛芬对狗有严重毒性,可能导致胃溃疡、肾衰竭,甚至死亡。在前往就医的路上:1) 记录狗的体重和误食的剂量、时间;2) 不要尝试自行催吐除非兽医明确指示;3) 在美国可拨打 ASPCA Animal Poison Control: (888) 426-4435。”回答 C: “别担心,一颗应该问题不大。可以喂点活性炭吸附毒素,多喝水排出来就好了,观察 24 小时如果有呕吐再去医院。”回答 D: “布洛芬(Ibuprofen)属于非甾体抗炎药(NSAIDs),其作用机制是抑制环氧化酶(COX-1 和 COX-2),从而减少前列腺素的合成。在犬类体内……”(继续 600 字药理学讲解)B 最好:紧迫感正确(这是真急诊),信息有用且可执行,电话号码准确(ASPCA 官方电话确为 (888) 426-4435[⁷]),安全意识到位(不让用户自行催吐)。 A 次之:虽然没”帮上忙”,但至少没造成伤害,引导到了正确的求助方向。在 RLHF 里,”无害的回避” > “有害的热心”。 D 第三:信息技术上正确,但答非所问。用户在抢救宠物,不是在写论文。 C 最差:严重危险。根据美国兽医毒物学文献[⁸],布洛芬在犬类中超过 25 mg/kg 即可引起胃肠反应、超过 100 mg/kg 引起肾损伤、超过 400 mg/kg 引起神经系统反应、致死剂量约 600 mg/kg。一颗 200mg 布洛芬对小型犬(如 5kg 的吉娃娃)剂量已达 40 mg/kg,足以引发胃肠中毒。”喂活性炭”应当由兽医执行,自行操作有误吸风险[⁸]。”观察 24 小时”会错过黄金救治时间。 不是打分,不是排序,是用每一次判断把人类的价值观传递给模型。每个排序背后都在回答深刻的问题: 什么是”有用”?(实际帮到用户 vs 看起来很专业) OpenAI 公开发布了《Model Spec》文档(约 28000 字)[⁹],Anthropic 也公开发布了 Claude 的 Constitution(”宪法”)[¹⁰]——这两份文档详细描述了大模型应该如何回答各种边界情况。这就是 RLHF 标注员需要学习理解并应用的判断标准。 这就是为什么 RLHF 标注员的时薪能到行业顶端。它不是体力劳动,是判断力的输出。 另外,做 RLHF 类标注时,保持自己的知识广度很重要——多读书、多关注新闻、培养逻辑推理和事实核查的习惯,这些”通识素养”直接决定你的标注质量上限。 如果你是一个零基础的学员,可以参考以下学习路径。总周期 4-6 个月,每周投入 10-15 小时(晚上和周末),能达到入职第二层(标注 PM 方向)的水平。 需要掌握的核心知识 机器学习基础认知
你不需要会建模,但必须理解模型是怎么”学”的。知道什么是训练集、验证集、测试集;理解过拟合、欠拟合的概念;明白为什么标注的一致性比”完美”更重要。当你知道一个错误标签会污染整个数据集时,你对待每一条数据的态度会完全不同。推荐入门资料:吴恩达的《Machine Learning》课程的前几章,或者李宏毅的机器学习课程导论部分。
任务领域知识
不同任务需要的领域知识差别巨大:
NLP 标注(情感分析、命名实体识别、意图分类):需要扎实的语言学常识、对歧义的敏感度 CV 标注(目标检测、语义分割、关键点):需要理解 bounding box、polygon、mask 的几何含义,对图像中的遮挡、光照、模糊有判断力 语音标注:需要音素、停顿、语调的基本概念 RLHF / 大模型对齐标注:这是目前最有价值的方向,需要判断模型回答的有用性、真实性、无害性,对逻辑推理、事实核查能力要求很高
标注规范(Guideline)的解读能力
顶尖标注员和普通标注员最大的区别就在这里。规范文档往往写得不完美、有歧义、有遗漏。你需要能精准理解规范的意图,而不是字面意思;遇到规范没覆盖的边界案例,能合理推断并主动反馈。
需要培养的关键技能 一致性(Consistency) ——同一类数据,不管什么时候标、标多少次,结果都应该一样。这是可以通过自我校验训练出来的:标完一批后,过一天再回头抽查自己标的,看看是否还会做同样的判断。
注意力耐久度 ——标注是高度重复但不能走神的工作。一个错标的样本可能影响模型一整个类别的表现。建议用番茄工作法(25 分钟专注 + 5 分钟休息),不要一次连续标超过 2 小时。
边界案例(Edge Case)的识别与上报 ——能发现”这条数据规范没说清楚怎么处理”的案例,并清晰描述出问题点,是从普通标注员升到 senior 标注员、再到标注规范制定者的关键路径。
工具熟练度 ——主流标注平台:
开源:Label Studio、CVAT、Doccano、Prodigy 商业:Scale AI、Labelbox、SuperAnnotate、Appen 平台
基础数据处理能力 ——会一点 Python(pandas 处理 CSV、JSON)、能看懂 COCO/YOLO/Pascal VOC 等标注格式、能写正则表达式。这会让你比纯手工标注员效率高几倍,也是从”标注员”晋升到”标注项目经理”或”数据运营”的必要技能。
英语阅读能力 ——前沿的标注规范、论文、平台文档大多是英文,能直接读英文规范不会信息衰减很重要。
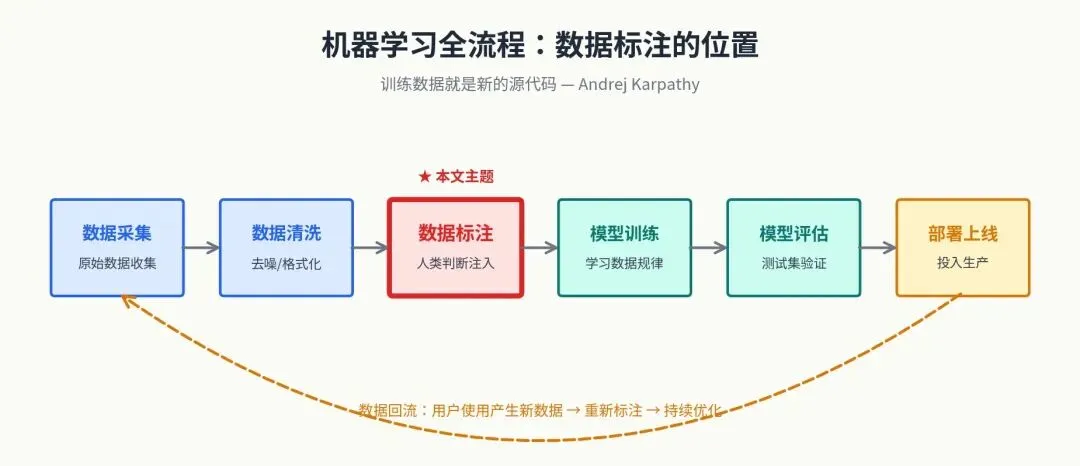
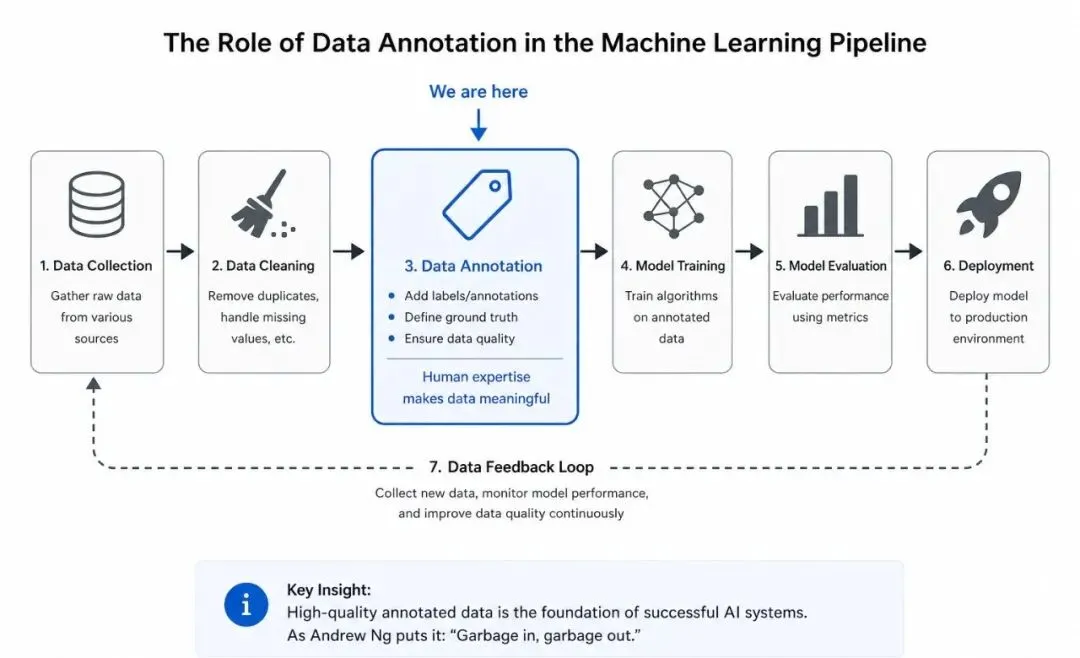
目标:搞清楚数据标注在 AI 工业流程里处于什么位置。 机器学习的基本流程是:数据采集 → 数据清洗 → 数据标注 → 模型训练 → 模型评估 → 部署上线 → 数据回流。标注是承上启下的关键环节。 不同任务需要不同的标注形式:分类任务要标签,检测任务要坐标框,生成任务要高质量人类示范。 吴恩达《AI for Everyone》[¹¹]:Coursera 上的免费课程(认证证书收费 $49),约 7 小时学完,4 周课程,已有约 250 万人学过。专为非技术背景人士设计,不需要任何编程基础。 李宏毅《机器学习》课程[¹²]:台湾大学李宏毅教授的中文授课课程,B 站可观看(关键词搜”李宏毅 机器学习”),课件免费。这是中文公开课中最受推荐的 AI 入门课程之一。 Andrej Karpathy《Software 2.0》[¹³]:前 Tesla AI 总监、OpenAI 创始成员之一的经典博客文章,提出”训练数据就是新的源代码”这一观点,理解这篇文章能让你立刻明白标注工作为什么重要。 这一阶段的产出: 能用自己的话向外行解释什么是机器学习、训练集和测试集为什么要分开、什么叫过拟合。 图像标注 :先用 LabelImg 入门(界面最简单),再上 CVAT 或 Label Studio。文本标注 :用 Doccano 或 Label Studio。重点练命名实体识别(NER)、关系抽取、文本分类。音频标注 :用 Audacity + Label Studio,练语音转写、说话人分割。3D / 点云 (自动驾驶方向):CVAT 的 3D 模式。举例:用 LabelImg 标 100 张猫狗图片做检测;用 Doccano 标 200 条新闻做实体识别。做完后试着用 Python 把标注结果读出来。 数据从哪里来?Kaggle、天池、Hugging Face 上有大量公开数据集。 这一阶段的产出: 一个 GitHub 仓库,里面放你做过的小项目,每个项目有清晰的 README 说明你标了什么、用了什么工具、遇到了什么问题。 这个仓库以后可是你的宝贵财富哦~ 用 Python 读写 JSON、CSV、XML 格式 计算标注一致性指标(Cohen’s Kappa、IoU、F1 score)——不用手算,调 scikit-learn 等库就行[¹⁴] 会这些之后,你立刻能做”标注质检”和”数据流程”相关的工作了。 计算机视觉方向 :自动驾驶(点云、多传感器融合)、医学影像、工业质检NLP / 大模型方向 :RLHF、prompt 设计、多轮对话评估语音方向 :多语言转写、说话人分离、情感标注领域专家方向 :结合你已有的专业(医学、法律、金融、编程、写作等)优先选你已经有积累的领域。如果你是医生,去做医学影像标注;如果你会写代码,去做代码 RLHF。 如果完全没有积累,可以选 RLHF 方向。这是当前最好的赛道,门槛主要是英语和判断力。 国内:百度众测、京东众智、龙猫数据、曼孚科技、海天瑞声等公司的标注岗 国外远程:Outlier(Scale AI 旗下,2024 年起在中国大陆受限,需注意)、DataAnnotation.tech、Alignerr(Labelbox 旗下) 根据 2026 年的 careerseeker.ai 调查[¹⁵]:DataAnnotation、Outlier、Alignerr 是当前三大主流海外平台,技能性任务时薪在 $20-40,专业领域可达 $30-65。但要注意:申请等待时间长、任务可用性不稳定、客服响应慢是行业普遍现象。 在 BOSS 直聘、LinkedIn 上搜”数据运营””标注 PM””AI Trainer””数据标注规范师”等关键词 A 类:核心概念(入行必备) 数据集划分 :训练集、验证集、测试集分别做什么用,比例怎么定。标签体系设计 :什么是平面分类、层级分类、多标签分类。Cohen’s Kappa:两人之间的一致性,1960 年由 Jacob Cohen 提出[¹⁴]。Landis & Koch (1977) 给出的常用解读标准是:< 0.20 极低,0.21-0.40 一般,0.41-0.60 中等,0.61-0.80 良好,> 0.80 几近完美[¹⁴]。但需要注意,对于医疗等高要求场景,有学者认为 0.41 仍然偏低[¹⁴]。 IoU(Intersection over Union):图像框的重合度 Ground Truth 与黄金标准集 :什么是金标数据,怎么用它来评估标注员质量。数据偏差与公平性 :标注员的主观判断会引入偏差,这是高级标注岗的核心议题。B 类:任务类型与标注规范 计算机视觉 :图像分类、目标检测(边界框、旋转框)、语义分割、实例分割、关键点检测、3D 标注自然语言处理 :文本分类、命名实体识别、关系抽取、共指消解、阅读理解、语义相似度大模型相关(最值钱) :SFT 数据、RLHF 偏好排序、DPO/Constitutional AI、红队测试、事实性核查、多轮对话评估强烈建议 :每种你打算做的任务类型,都去读一份公开的标注规范文档。Waymo Open Dataset 的标注规范在 GitHub 公开[⁶],Cityscapes、COCO、SQuAD 也都有公开规范。这些是最有价值的免费学习材料。 C 类:数据格式与基础工具 要能看懂和处理这些格式:JSON / JSONL、XML、COCO 格式、YOLO 格式、CoNLL 格式、TSV / CSV。 工具层面:命令行基础、Python + pandas + JSON 读写、Git 基础、Excel / Google Sheets。 D 类:进阶能力(决定你能走多远) 标注规范的撰写能力 :能不能写一份让 10 个人看完都理解一致的规则文档,是标注 PM 的核心能力。主动学习与预标注 :现在大部分项目都用模型先预标注,标注员只做修正。要理解什么是 active learning。质检流程设计 :抽检比例怎么定、错误怎么分类、返工机制怎么设计。领域知识 :医学影像标注要懂解剖学,法律文本标注要懂法律术语,代码标注要会编程。领域 + 标注能力 = 高薪 ,这是最稳的路径。英语 :海外标注平台单价显著高于国内[²]。专业领域(编程、数学、写作)的英文 RLHF 项目时薪 30-65 美元[²]。英语阅读和写作能力是硬门槛。1. 不要陷入”准备完美再开始”的陷阱 最常见的失败模式是:买了一堆课,囤了一堆 PDF,三个月后什么也没动手做。 正确姿势 :看完这篇文章后,今天就去注册一个 Label Studio,下载一个公开数据集,标 50 条数据。2. 把”读规范”列为长期习惯 每周抽两小时读一份公开标注规范。Waymo、COCO、SQuAD 都是免费的[⁶]。 3. 做”反向标注”练习 去 Kaggle 或天池下载一个已经标好的公开数据集,把答案藏起来,自己重新标一遍其中 50-100 条,然后对比官方答案。这是提升判断力最有效的练习方式。 4. 建立公开作品集 你的 GitHub 仓库要包括:你做过的标注项目、每个项目的标注规范文档(你自己写的版本)、数据统计和一致性分析、遇到的难点和解决方案。 5. 警惕”过度规划焦虑症” AI 不会取代所有标注员,会取代第一层执行型标注员。这正是为什么你要学习——爬到第二层、第三层。 最坏情况是你花了 3 个月学习数据标注,没找到工作,但你顺便学会了 Python 基础、读懂了机器学习流程、有了一个公开作品集——这些能力放在任何 AI 相关岗位上都能用。 6. 警惕培训陷阱 国内数据标注行业存在大量”先交培训费”的骗局[¹⁶]。新浪财经曾报道有公司要求新手缴纳 2580 元培训费,承诺一年内累计工资达到 1 万元才退还,但黑猫投诉平台上这类公司是投诉重灾区[¹⁶]。正规标注岗不收培训费,遇到收费的直接拒绝。 7. 把”做付费项目”作为最重要的学习方式 学到第 8 周左右,就可以开始注册海外平台接单了。真实项目教给你的东西,是任何教程教不了的 。 不要问自己”这个行业前景好不好”,问自己三个问题: (1)我愿不愿意每天对着规范文档抠 10 个小时的细节? (3)我有没有耐心做一件 6 个月才能看到效果的事? 如果三个都是”愿意”,那就开始干。这是个进入门槛低但天花板很高的行业,特别适合”有耐心 + 有判断力 + 愿意持续学习”的人。 如果有任何一个是”不愿意”,那就别勉强。数据标注不是低门槛的轻松活 ,它是低进入门槛但高质量门槛的脑力工作。强行做下去会很痛苦。 《工劳小报|长工时和低工资:中国数据标注行业的劳动状况》,中国数字时代,2025 年 2 月 15 日。原文称”行业中全职工人的平均月工资在 2000 到 2600 元之间”。https://chinadigitaltimes.net/chinese/715869.html 职友集”数据标注员”工资统计页面:88.5% 的数据标注员月薪在 3000-6000 元区间。https://www.jobui.com/salary/quanguo-shujubiaozhuyuan/ 北京商报《大厂高薪”挖人”,大模型热下的”AI民工”之变》,2024 年 6 月 13 日。原文:”高级 AI 数据标注师甚至专家,月薪一般都会过万元,高者甚至达到 5 万元……专家级别能给到 5 万元甚至更高。”https://xinwen.bjd.com.cn/content/s666ae10be4b0115c9f85e343.html 36 氪/自象限《月薪两万,大厂疯抢 AI 数据标注员》,2023-2026 年多次报道,提到百度文心一言 AI 数据标注员月薪 9000-15000 元。https://36kr.com/p/2537988066942854 海外平台时薪数据:The Interview Guys《10 Best AI Data Labeling and Annotation Jobs in 2026》,2026 年。原文:”Intermediate RLHF contributors: $20-$30/hr… Specialized domain experts (coding, STEM, medicine): $30-$65/hr on platforms like Outlier.”https://blog.theinterviewguys.com/best-ai-data-labeling-and-annotation-jobs/ 《关于促进数据标注产业高质量发展的实施意见》,2024 年 12 月由多部门联合印发。新浪财经 2025 年 8 月 29 日报道引用。https://finance.sina.com.cn/roll/2025-08-29/doc-infnrwzk1146897.shtml 《数据标注产业发展研究报告(2025 年)》,中国信息通信研究院人工智能研究所、中电信人工智能科技(北京)有限公司联合发布,2025 年 8 月 29 日。https://www.caict.ac.cn/kxyj/qwfb/ztbg/202508/P020250829585535422955.pdf TSG Invest《Scale AI Stock: $29B Valuation》:Meta 2025 年 6 月以 143 亿美元购入 49% 非投票股份,估值 290 亿美元。https://tsginvest.com/scale-ai/ Sacra《Scale AI revenue, valuation & funding》:2025 年 7 月 Scale AI 裁员 200 名全职员工(约 14%)和约 500 名合同工;同期 xAI 裁员约 500 名通用型标注员(约其团队的三分之一)。https://sacra.com/c/scale-ai/ [6] Waymo Open Dataset 标注规范 Waymo 公开标注规范文档:https://github.com/waymo-research/waymo-open-dataset/blob/master/docs/labeling_specifications.md 数据集介绍:https://waymo.com/open/about/ [7] ASPCA Animal Poison Control 电话 ASPCA 官网:(888) 426-4435,24 小时全年无休。https://www.aspca.org/pet-care/aspca-poison-control ScienceDirect “Ibuprofen” 综述:犬类胃肠反应阈值 25 mg/kg、肾损伤 100-175 mg/kg、神经系统反应 >400 mg/kg、致死剂量约 600 mg/kg。https://www.sciencedirect.com/topics/veterinary-science-and-veterinary-medicine/ibuprofen VCA Animal Hospitals《Ibuprofen Poisoning in Dogs》:活性炭应仅由兽医执行,自行操作可能导致误吸和钠水平改变。https://vcahospitals.com/know-your-pet/ibuprofen-poisoning-in-dogs dvm360《Toxicology Brief: Ibuprofen toxicosis in dogs, cats, and ferrets》:致死剂量 600 mg/kg。https://www.dvm360.com/view/toxciology-brief-ibuprofen-toxicosis-dogs-cats-and-ferrets OpenAI 公开发布的模型行为规范文档,约 28000 字。引用自 Future of Life Institute 的 Behavior Specification Transparency 报告。https://futureoflife.org/wp-content/uploads/2025/07/Indicator-Behavior_Specification_Transparency.pdf [10] Anthropic Claude Constitution Anthropic 公开发布 Claude 的”宪法”文档:https://www.anthropic.com/news/claude-new-constitution TIME 杂志报道:https://time.com/7354738/claude-constitution-ai-alignment/ Constitutional AI 学术论文:https://arxiv.org/abs/2212.08073 [11] 吴恩达《AI for Everyone》课程 Coursera 课程页:https://www.coursera.org/learn/ai-for-everyone 时长约 7 小时,4 个模块,已有约 250 万人学习;DeepLearning.AI 官方信息:免费学习,认证证书 49 美元。https://www.deeplearning.ai/courses/ai-for-everyone/ 台湾大学李宏毅教授课程,2017-2021 各年版本均可在 B 站找到。课程主页:https://speech.ee.ntu.edu.tw/~tlkagk/ B 站搬运视频参考:https://www.bilibili.com/video/BV1Wv411h7kN/ [13] Andrej Karpathy《Software 2.0》 原文 Medium 博客:https://karpathy.medium.com/software-2-0-a64152b37c35 作者背景:曾任 Tesla AI 总监、OpenAI 创始成员,斯坦福 CS231n 首任主讲。https://karpathy.ai/ 原始论文:Cohen J. (1960). “A coefficient of agreement for nominal scales.” Educational and Psychological Measurement 20(1):37-46. Landis & Koch (1977) 解读标准:见 NIH PubMed Central《Interrater reliability: the kappa statistic》https://pmc.ncbi.nlm.nih.gov/articles/PMC3900052/ scikit-learn 的 cohen_kappa_score 实现:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.cohen_kappa_score.html Surge AI 的科普文:https://surge-ai.medium.com/inter-annotator-agreement-an-introduction-to-cohens-kappa-statistic-dcc15ffa5ac4 careerseeker.ai《Data Annotation Jobs 2026: Are They Worth Your Time?》,2026 年。https://careerseeker.ai/data-annotation-jobs/ Outlier AI 评测:https://www.feedkin.com/2026/03/Outlier%20AI%20Review%202026%20Real%20Pay%20Rates%20Task%20Types%20and%20Honest%20Verdict.html 36 氪《月薪两万,大厂疯抢 AI 数据标注员》,2026 年 1 月。详细记录了 2580 元培训费陷阱和黑猫投诉情况。https://36kr.com/p/2537988066942854 人人都是产品经理同名转载:https://www.woshipm.com/it/5950284.html 核实说明 :本文已尽可能用一手或权威二手信源标注每一个具体数据点。但请注意:
薪资数据来自媒体报道和招聘平台统计,会随时间变化,建议读者求职时以最新招聘信息为准。
行业趋势判断(”哪一层会被 AI 取代”等)属于基于现有数据的合理推断,不构成确定性预测。
学习路径中的”4-6 个月”是经验估计,因人而异。
 夜雨聆风
夜雨聆风