 夜雨聆风
夜雨聆风





AI ASIC:博通剧本,国产演绎
AI 芯片链里仅次于英伟达的第二大芯片赢家,是博通,过去两年市值从4千亿美元涨到1.9万亿美元上下,只是因为他在给Google做了TPU。
ASIC 芯片的剧本虽然是借的,但在国内几条独立变量下,已经开始了国产演绎。
一、什么是ASIC?AI 推理专用芯片
训练和推理是两回事
大模型有两个阶段。训练是把海量数据喂给模型让它学习,像让学生读完整个图书馆。推理是模型学完之后回答你的问题,你在豆包或ChatGPT输入问题后等待回答的那一秒钟发生的事。
训练是阶段性投入。一个大模型训练一次几亿到几十亿,训练完就不用再训练了,下次升级再来一次。推理是天天发生的持续性投入——日活上亿的应用每天的推理次数以万亿计。这部分算力跟业务量线性挂钩,业务越大算力消耗越大。
整体而言推理市场远大于训练。训练天花板很快就到,能用得起几万张训练卡的公司全球就那几家。而推理还在随着 AI 使用量的增长持续爆发。
GPU和ASIC的分工
GPU是通用算力,能做图形渲染、训练、推理、科学计算。通用性的代价是必须保留各种冗余电路、冗余指令集,对一个固定不变的任务来说这些冗余全是死成本。
ASIC全名”专用集成电路”。一种ASIC只为一种任务设计,其他活干不了,但干这一种活效率推到极致。Google的TPU就是为机器学习做的ASIC AI 推理专用芯片。
GPU像瑞士军刀,什么都能做但不极致;ASIC像专业菜刀,只能切菜但切得最好。模型应用一旦稳定下来——比如内容推荐这种用了多年的固定算法——任务固定了ASIC的效率优势就出来了。
ASIC效率优势的来源
为什么一颗”专用”芯片能比通用GPU效率高一个量级?因为ASIC可以同时砍掉七层”通用性税”:把矩阵乘法直接刻进硅片、只支持模型实际用的数值精度、把片上内存做到几百MB甚至几GB让数据不用反复搬运、用数据流架构取代指令调度、把互联拓扑为目标算法定制、让编译器直接控制内存层级、把指令做成超粗粒度。
每一项单独的效率提升是1.5-3倍,七项叠起来在目标场景下可以做到5-10倍的能效比优势。代价是放弃通用性——这就是Google TPU能把推理TCO(总体拥有成本)压到GPU的1/10的硬件来源。
为什么大厂集体自研 ASIC?
因为四个产业账本:
-
推理是天天烧的钱,能效每提升1%一年节省的就是亿级金额。 -
软硬协同的护城河只有大厂走得通——业务稳定下来后从算子库到编译器到芯片可以全栈定制。 -
英伟达毛利率长期75%以上,没有大厂不愿意一直交“英伟达”税。 -
推理市场持续增长,据Marvell和博通在多次季度财报电话会议中给出的指引,2027年全球定制AI芯片市场规模将达到600-900亿美元区间。
因此,大厂自研ASIC从”可选项”变成了”必选项”。
二、博通的万亿剧本
故事的源头是Google。
Google从2006年开始考虑机器学习专用芯片,2016年发布第一代TPU。立项目标很明确:把推理TCO压到GPU的1/10。这不是口号,TPU迭代了将近十年确实做到了数量级的能效优势。
TPU的后端设计交给博通做。博通有三十年定制化芯片设计经验,在芯片间高速互联、信号处理这些底层模块上有绝对领先地位。这个合作的结果:Google省下大量原本要交给英伟达的钱,博通的ASIC业务从几亿美元做到几百亿美元年收入,市值破了万亿。
Google带头之后剧本被复制。亚马逊有Trainium和Inferentia,Meta有MTIA,微软有Maia 100。这些芯片的合作设计方主要是博通和Marvell。
因此作为“专用铲子设计方”ASIC 厂商没有押注任何一家AI公司,但他服务的是整个赛道的”产业基础设施”环节。由于这个产业客户分散、订单可见度高、不依赖单一客户成败、产业格局相对稳定,使得ASIC 厂商的议价权越来越大。
三、ASIC剧本搬到中国,哪些是一样的
四个产业账本映射到中国完全成立。
国内的字节、阿里、腾讯、百度都在做自研ASIC。字节正在推进多款自研AI芯片,预计2026年陆续进入量产阶段。阿里早在2019年发布含光800、2021年发布倚天710。腾讯有沧海视频编解码芯片和紫霄AI推理芯片。百度的昆仑芯已经迭代到第三代。这些项目跟Google做TPU的逻辑是一回事——业务量起来了自研的ASIC 的账就划算。ASIC的经济账在中国其实更夸张。中国互联网应用的用户体量是全球第一,推理算力消耗更大。同样1%的能效提升节省的金额比海外更多。
议价权的算盘也一样。英伟达过去两年在中国市场卖H20、L20、A800这些”特供版”产品,毛利仍然可观。中国大厂同样不愿意让英伟达一直吃这部分利润。
剧本的底层产业逻辑在中国完全成立。
四、国产ASIC三条独立变量
中国市场有三条独立变量,让ASIC剧本在中国有更高的产业确定性,但不同的产业受益方排序。
变量一:能耗硬指标制造的政策护城河
国内相关政策对新建及改扩建数据中心新增算力的能效水平提出了具体要求。其中先进制程AI芯片的能效比要达到一定数值以上才能进入数据中心采购清单。
而英伟达H20这一类海外中端推理产品的能效比并未达到这一标准。这意味着H20及类似产品在国内大型新建数据中心的采购被排除在外。这是政策端制造出来的事实性产业空间,国内特有的变量。政策标准会迫使技术差距会被追赶。
变量二:推理本地化的结构性壁垒
数据合规和低延迟决定了中国市场的推理服务必须本地部署。例如:豆包的推理服务器只能在中国境内运营,哪怕英伟达B100放在新加坡数据中心提供推理服务对豆包来说也用不了——延迟太高、合规过不去。
这个壁垒海外没有。Meta、Google可以全球调度算力,他们的ASIC优势是经济性优势。中国大厂的ASIC既是经济性需求也是结构性需求。这让中国推理ASIC的产业天花板在逻辑上更高。
变量三:大厂资本开支的体量
国内头部互联网公司2026年AI相关投入加总在万亿级别。其中字节单家2026年计划在AI领域投入约1600亿元,其中相当比例用于AI芯片采购和自研投入。
把这个数字放到产业链对照:目前中国ASIC全产业链所有上市公司加起来年营收远低于这个数字。需求端的天花板还没接近被打到。
三条变量叠加的含义:海外的剧本是经济性驱动的(唯一变量),中国的剧本是经济性+政策+结构性壁垒三重驱动(三重变量)。这让中国版剧本的产业确定性更高、产业天花板更高。
五、产业链拆开看——产业卡位在哪
按产业链层级从顶到底看,ASIC能不能真正大规模落地,是被后端卡住的,产业弹性也在后端。
设计端(顶层):包括AI加速芯片、CPU+加速卡、芯片IP和设计服务等公司。这一层是市场关注度最高的环节,因为lead time(从下单到出货的时间)最短、订单可见度最高。
设计能力本身在国内不算稀缺资源——能做ASIC前后端设计的公司不止三五家(摩尔、燧原、沐曦、寒武纪、芯原),真正的产业瓶颈不在设计能力而在订单端:哪些大客户愿意把项目给你做。这是设计端的核心产业特征。”博通模式的成功在于通过自有IP库+多客户全栈设计服务+不押注单一客户。而自有IP库+多客户全栈设计服务+不押注单一客户的 ASIC 设计厂商只有芯原一家。
制造端:晶圆代工是产能就是天花板的典型。这一层的产业逻辑相对稳定,业绩弹性比设计端小但确定性比设计端高。国产先进制程ASIC的代工产能高度集中在中芯,华虹承接成熟制程节点。这是产能就是天花板的典型环节——设计端订单再爆,造不出来都是空话。
后端封装(被低估的真正瓶颈):ASIC的高算力密度依赖2.5D/3D异构集成,把多颗芯片像盖楼一样堆在一起通过中介层连接。
华为CloudMatrix 384集群在公开技术发布中展示了对标英伟达GB200 NVL72的部分指标,路径是封装换制程、规模换性能——把多颗成熟制程的芯片通过先进互联堆出集群级算力。这是中国市场环境下走出的一条独特产业路径。
国内能做先进2.5D/3D封装的OSAT(外包封测厂)数量有限,主要集中在头部几家厂商。长电的XDFOI扇出型封装已经量产,能做HBM中介层封装;通富是AMD MI系列加速卡的核心封装供应商;甬矽在FCBGA和SiP方向有差异化布局。这个细分行业的产业特征是客户不会自建产线、CapEx壁垒高、产业格局相对稳定——是典型的”位置型”产业环节。
HBM存储:ASIC性能上限被HBM(高带宽存储)卡死。可以这样理解:ASIC是大力士,HBM是它的水管,大力士再壮水管细一切都白搭。所有顶级AI芯片都用HBM。
HBM国产化目前还在追赶。三星和海力士对中国先进HBM的供应受到一定限制,国内长鑫HBM产能爬坡的时间表决定了国产ASIC什么时候真正能大规模可用。配套环节上,太极实业通过与海力士的合资公司江苏海太半导体参与HBM封测,是国内少有的能直接吃海外HBM产能爬坡红利的标的;雅克科技为三星和海力士提供HBM前驱体材料(TMA、TMG等关键化学品);这是相对独立的产业线,不依赖任何一家ASIC设计公司的成败。海外没这个变量——海力士和三星给Google、Meta供HBM不受限。
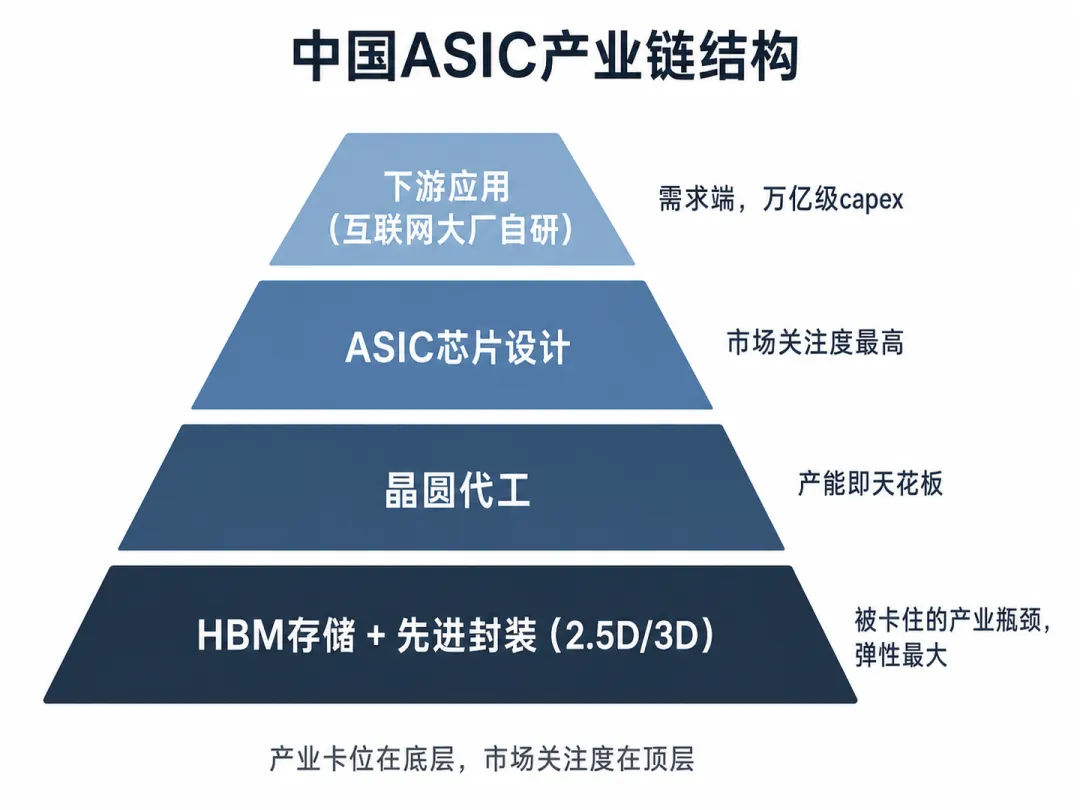
中国市场对应的产业卡位是分散的——封装、HBM、互联、PCB各自构成独立的产业环节,每一环都有不依赖单一客户成败的产业逻辑。这是中国ASIC产业链相比美股最重要的结构差异。
ASIC在海外,是由经济性单一驱动的产业必然,在国内经济性、政策、推理本地化三重驱动——这让产业确定性更高、天花板更高。但还有真正的产业瓶颈有待解决:封装、HBM、互联。