 夜雨聆风
夜雨聆风





AI代理用CLI还是MCP?这场争论终于有答案了
最近开发者圈子里吵翻了天。
争论的焦点是 AI 代理该用什么方式跟外部世界交互。一派说 CLI 命令行就够了,简单高效不花冤枉钱。另一派说 MCP 才是未来,结构化、可管理、企业级。
双方都拿出了数据,都觉得自己有理。
但真相往往藏在细节里。我用同一个 AI 代理跑了两组实验,一组用 CLI,一组用 MCP,结果让人意外。
两种完全不同的交互方式
先说清楚这两个东西到底是什么。
CLI 就是命令行界面,AI 代理直接在终端里敲命令,跟开发者平时干的事一模一样。cat 读文件,grep 搜索内容,git 管理代码,这些都是标准操作。
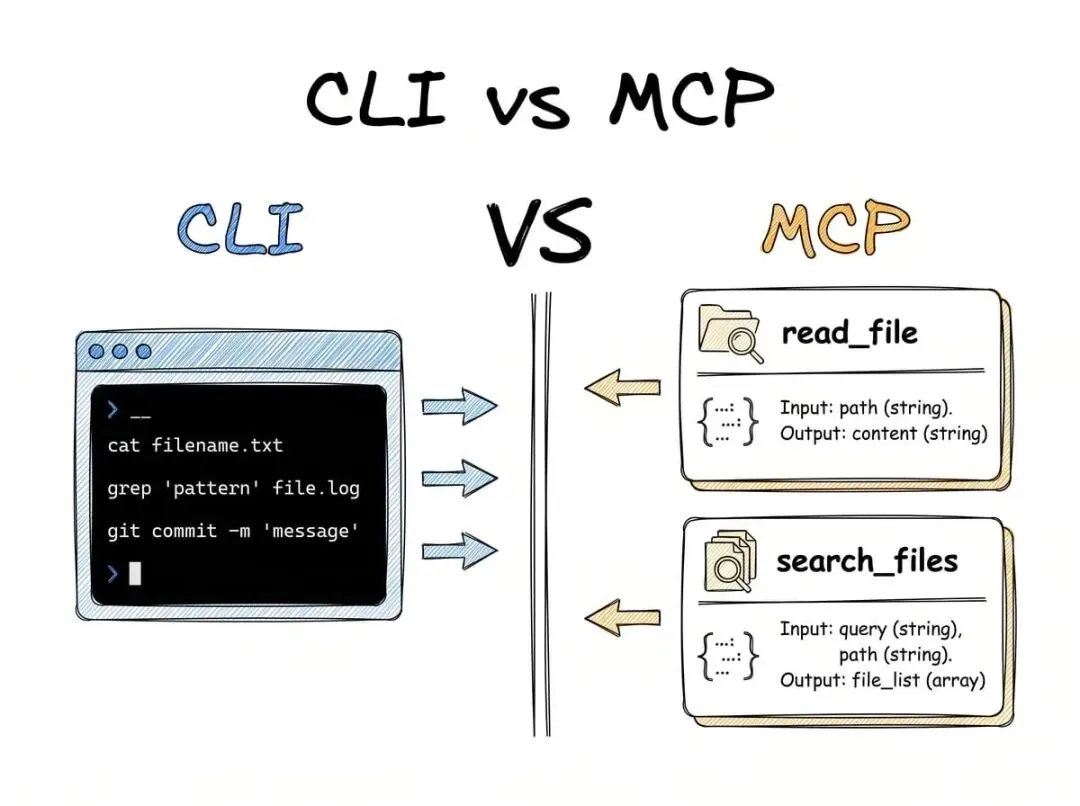
MCP 全称是模型上下文协议,它是一套标准化的协议。专门的服务器会暴露出一堆结构化工具,每个工具都有名字、描述和 JSON 模式。模式里定义了工具需要什么输入,会返回什么输出,全都写得清清楚楚。
听起来 MCP 更规范对吧?但问题就出在这。
CLI 阵营的核心论点
反对 MCP 的开发者说得很直接,AI 模型在训练的时候已经见过几百万个 CLI 示例了。Stack Overflow 上的帖子,各种 man 手册页,这些都在训练数据里。
模型早就知道怎么用这些命令了,不需要你再给它一份 JSON 模式告诉它 grep 该怎么用。这些知识已经烙进它的神经网络里了。
更要命的是成本问题。每个 MCP 工具的模式都要在对话开始时加载到模型的上下文窗口里。一个工具的模式可能就要几百个 token,而上下文窗口是有限的,还没干活就先把窗口塞满了。
这就像你去餐厅吃饭,服务员先给你背了一遍厨房里所有食材的产地和营养成分,然后才让你点菜。信息是全了,但谁需要这些?
文件操作的对决
我做的第一个实验很简单,就是基础的文件操作。有个文件夹里放了几个 markdown 文件,AI 代理要做两件事,读取其中一个文件 notes.md,然后在所有文件里搜索特定的词。
CLI 方式下,代理用了两条 bash 命令。cat notes.md 把文件内容打印出来,grep -n agent *.md 在所有 markdown 文件里搜索 agent 这个词,顺便加上行号。
整个过程行云流水,代理不需要查任何文档,这些命令的用法早就在它的训练数据里了。
MCP 方式下,代理调用了文件系统服务器的两个工具。read_file 读取 notes.md,search_files 搜索包含 agent 这个词的文件。
两种方式都完成了任务,返回的信息也一样。但 CLI 命令更紧凑,而且模型不需要知道任何模式就能正确使用。
这里有个细节很关键。文件系统 MCP 服务器一共提供了13个工具,但实际只用了2个。剩下11个工具的完整 JSON 模式也全都加载进了上下文窗口,占用了几千个 token,就为了用其中两个。
这就是 MCP 被批评为不必要复杂性的原因。不过说实话,在这么简单的任务里,用哪个都行。真正的差距要等规模上来才看得出。
Git 操作暴露的成本问题
Git 是全球最广泛使用的开发工具之一。一个有 Bash 权限的 AI 代理可以轻松运行各种 Git 命令,比如查看最近10次提交,检查工作树状态。
模型对 Git 了如指掌,知道各种 flag,知道格式化字符串,全都来自训练数据。
现在看 MCP 的替代方案,GitHub MCP 服务器。这个服务器不是提供13个工具,而是80个。
每一个工具的定义,包括名称、描述、完整的 JSON 输入模式、参数类型和说明,全部都要在对话开始时注入到模型的上下文窗口里。
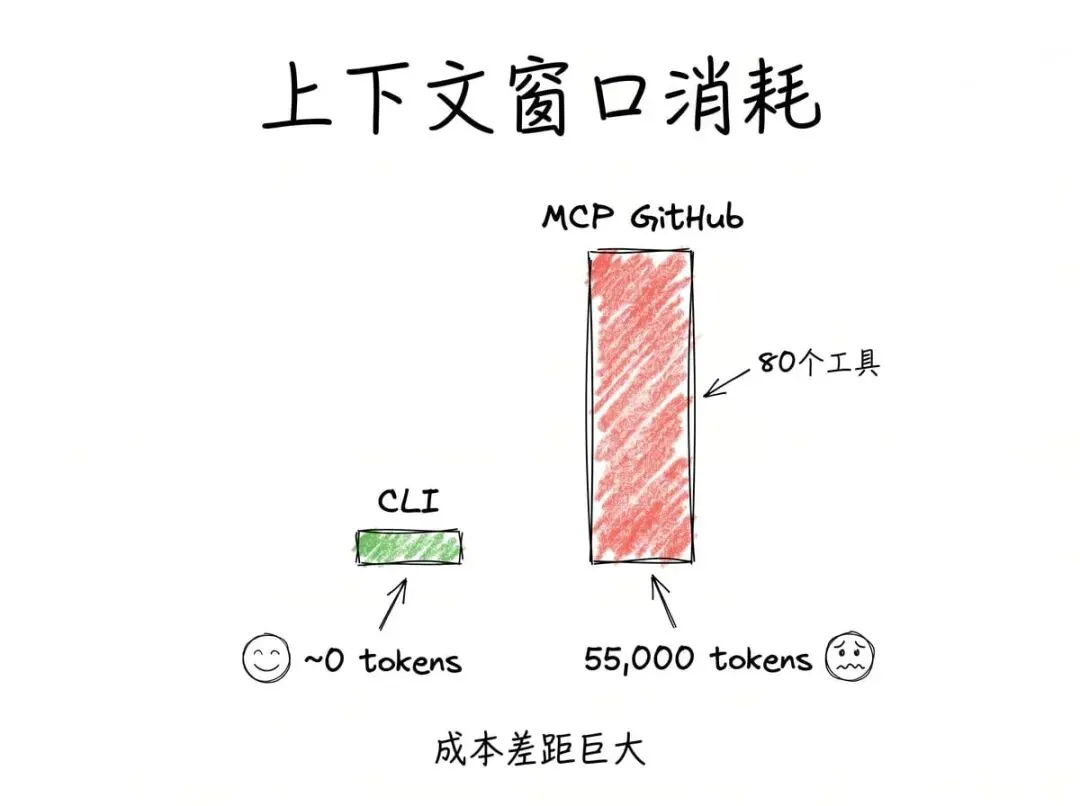
这加起来大约是55000个 token。即使你只需要其中一两个工具,这55000个 token 也得全部加载。
按照 API 定价,这些 token 是真金白银。它们直接吃掉了上下文窗口里本该用来干实际工作的空间。而模型本来可以用几条 bash 命令就搞定这些 Git 操作。
这就是 CLI 阵营最强的论点。对于本地开发工具来说,MCP 是在为模型已经掌握的知识支付高昂的税。
抓取网页的翻车现场
到这里你可能觉得 CLI 赢定了。但别急,我们再看一个实验。
这次任务是抓取 modelcontextprotocol.io 这个网页,然后告诉我主标题是什么,再总结一下前几段的内容。
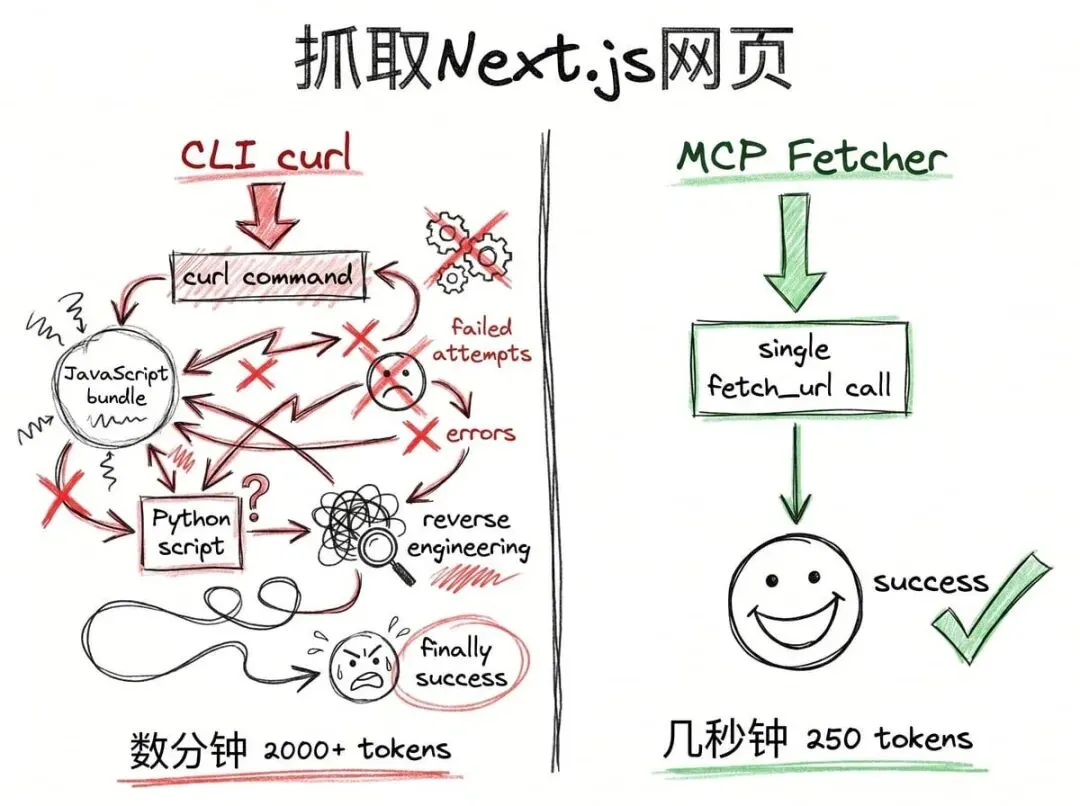
MCP 方式下,代理调用了一个叫 Fetcher 的 MCP 服务器。这个服务器基于无头浏览器构建,可以渲染 JavaScript。它用 fetch_url 这个工具发起了一次请求。
服务器启动浏览器,加载页面,等待渲染完成,把结果转成可读文本,然后返回内容。整个过程用了大约250个 token,花了几秒钟。
CLI 方式下就开始翻车了。
代理第一次尝试用 curl -s URL | head -200,想抓取原始 HTML 然后只看前200行。但返回的几乎全是 JavaScript 打包代码。
因为 modelcontextprotocol.io 是个 Next.js 应用,服务器不发送完整的 HTML 页面,而是发送一个 JavaScript 应用,让它在浏览器里构建页面。curl 不会运行 JavaScript,所以你只能得到一堆框架代码。
这时候代理开始即兴发挥了。它把文本处理工具串起来,试图剥离 HTML 标签,过滤掉 JavaScript。没用。
然后它试图在源代码里找嵌入的 JSON 格式的页面内容。找到了一些片段,但不完整。
接着它写了一个 Python 脚本,试图反向工程 Next.js 用来向浏览器流式传输内容的内部数据格式。
反向工程一个 JavaScript 框架的内部机制,就为了读一个网页。
我跑这个实验的时候,它又尝试了好几次才终于获取到足够的内容来总结页面。整个过程花了几分钟,消耗了超过2000个 token,还把我的笔记本折腾得够呛。
最后得到的结果跟 MCP 一模一样。
什么时候该用哪个
现在规律就清楚了。
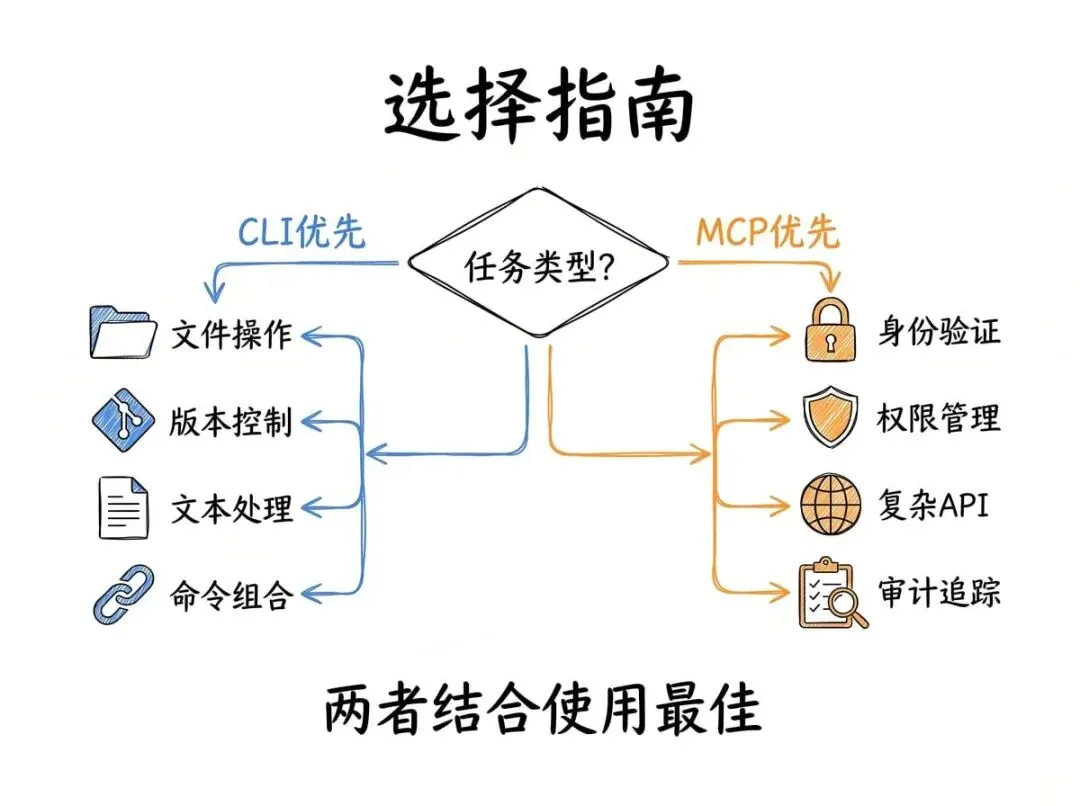
CLI 在命令直接对应任务的时候表现最好。文件操作、Git、文本处理、运行脚本,这些命令行已经解决了几十年的问题,模型也早就熟悉这些工具了。
而且 CLI 工具天然支持管道组合,可以用一行命令把多个操作串起来。这是 MCP 做不到的,因为每个工具调用都是独立的。
但 MCP 也有它的战场。
当原始工具给你的东西和你真正需要的东西之间有差距时,MCP 就赢了。就像我那个 Next.js 网页的例子。
这个优势还延伸到很多其他场景。比如身份验证,Slack、Notion、数据库的认证怎么办?
用 CLI 的话,代理要自己管理 OAuth token,查找频道 ID,处理 token 刷新。基本上所有这些事都很手动。虽然是 AI 代理在做,但它还是得手动操作每一步。
而 MCP 服务器会把这些全包了。代理只需要说它想干什么就行,服务器管理所有的认证细节。
从组织层面看,差异就更明显了。
当代理代表不同员工行事时,可能需要按用户的访问控制,不能共享凭证,还需要审计追踪来跟踪到底做了什么。
这些东西很难在 CLI 上后期添加,但 MCP 在协议里就内置了这些功能。
答案其实很简单
所以到底该用 CLI 还是 MCP?
你可能猜到了,答案是两个都用。
我测试的 AI 代理就是这么干的,CLI 和 MCP 并排使用,针对不同任务选择不同工具。命令能直接映射到任务就用 CLI,抽象或治理需求能证明成本合理就用 MCP。
选择权在代理和提示它的人手里。如果代理开始反向工程 JavaScript 框架就为了读个网页,那就是个明确的信号,它选错工具了。
技术的进步从来不是非此即彼的零和游戏。CLI 和 MCP 各有各的用武之地,关键是理解它们的边界,在正确的场景用正确的工具。
这才是真正的工程智慧。