 夜雨聆风
夜雨聆风





AI 不再只是帮你干活,它开始学着像你一样工作
AI 不再只是帮你干活,它开始学着像你一样工作
如果过去两年的 AI 更像是给白领工作的“加速器”,那么现在出现的长程 Agent,更像是在改写工作的组织方式本身。这篇文章不是关于工程师的故事——它关于你自己的工作会怎么变。
一、你已经感受到的那种变化
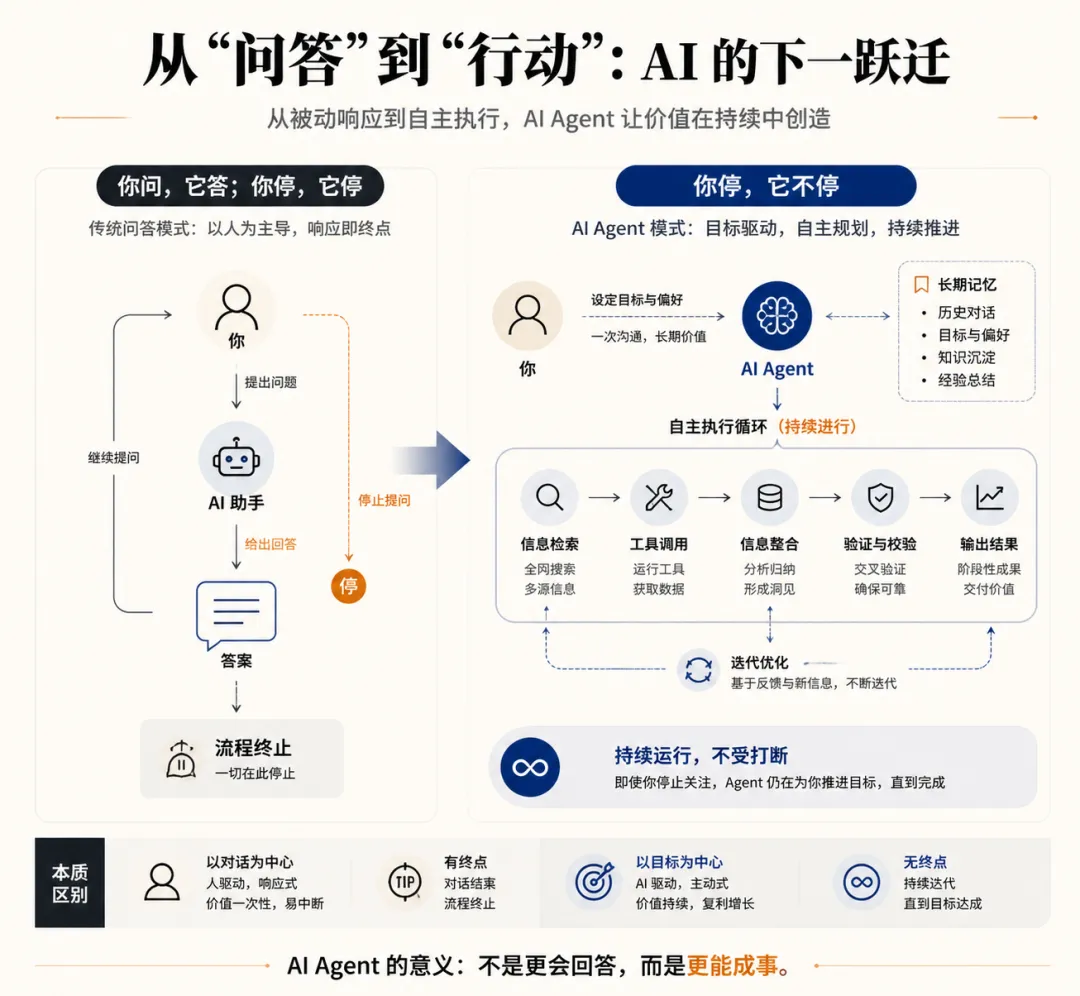
过去两年,你大概已经习惯了这样一种节奏:打开豆包,把一段文字扔进去,几秒钟拿到一个还不错的初稿;或者用 Copilot 补全代码,省掉了查文档的时间。AI 有用,但它的位置很清楚——它是你工作流里的一个加速器,你还是那个做决定、推进任务的人。
你问,它答;你停,它停。它让你快了一些,但没有改变你工作的基本形态。
但最近几个月,有些事情开始不一样了。
不是模型又变聪明了一点,也不是补全速度又快了一些。而是出现了一类新的系统——它不只是回答你的问题,而是在你不盯着它的时候,继续朝着目标工作。它会自己搜索、自己判断、自己调整,直到任务完成或者遇到真正需要你介入的地方。
这类系统有个名字,叫长程 Agent(long-horizon agent)——简单说,就是能在多个步骤、多个工具之间持续工作、自我纠错的 AI 系统,而不是回答一次就停下来的那种。
二、更快的马,还是一辆车?
有一个比喻,在讨论 AI 的时候被反复引用:如果你去问马车时代的人“你想要什么”,他们会说“一匹更快的马”。没有人会说“我要一辆汽车”——因为汽车这个概念还不存在。
这个比喻的意思不是说人们愚蠢,而是说:当一种根本性的新事物出现时,我们最自然的反应是把它理解成“原来那个东西的升级版”。
过去两年的 AI 工具,大多数确实是“更快的马”。它们让你写邮件更快、查资料更快、做初稿更快。有用,但没有改变工作的基本结构——你还是那个坐在流程中间、推动每一步的人。
“车”是什么样的?是一个系统,它不只是帮你做某一步,而是能接管一段完整的工作流程,自己推进,自己处理中间遇到的问题,在需要你判断的地方才停下来。
但这里有一个重要的警告。
“车”不是自动驾驶。至少现在还不是。
一个长程 Agent 可以独立完成很多步骤,但它也会犯错——而且犯的错有时候很难发现。
想象这样一个场景:你让一个 Agent 帮你整理一份竞争对手分析报告。它搜索了十几个来源,提取了关键数据,写出了一份格式整洁、逻辑清晰的文档。看起来很专业。但其中有一个关键数字,它从一篇过时的新闻里引用了,没有核实。这个数字影响了整份报告的结论。
如果你没有仔细读,这个错误就直接进了你的决策。
这不是说 Agent 没用。
而是说:它改变的是你需要把注意力放在哪里。以前你要做每一步,现在你要做的是:设定目标、提供上下文、在关键节点审查输出。人的判断没有消失,它只是移动到了不同的位置。

三、为什么编程最先被改变
如果你最近关注 AI 新闻,会发现一个反复出现的词:编程 Agent。GitHub Copilot、Claude Code、各种“自动写代码”的工具——为什么 AI 在编程这件事上跑得最快?
这不是因为编程特别神奇,而是因为编程有一个其他很多工作没有的特质:你可以立刻知道结果对不对。
写完代码,运行一下,测试通过了就是通过了,报错了就是报错了。这个反馈是即时的、明确的、可重复的。这种环境,在技术上叫验证环境(verification environment)——一个能让 Agent 的输出被快速测试和纠正的系统。你可以把它理解成一个会立刻告诉你“这里错了,而且错在哪里”的工作场。
有了这个环境,Agent 就可以做一件非常有价值的事:自己循环。
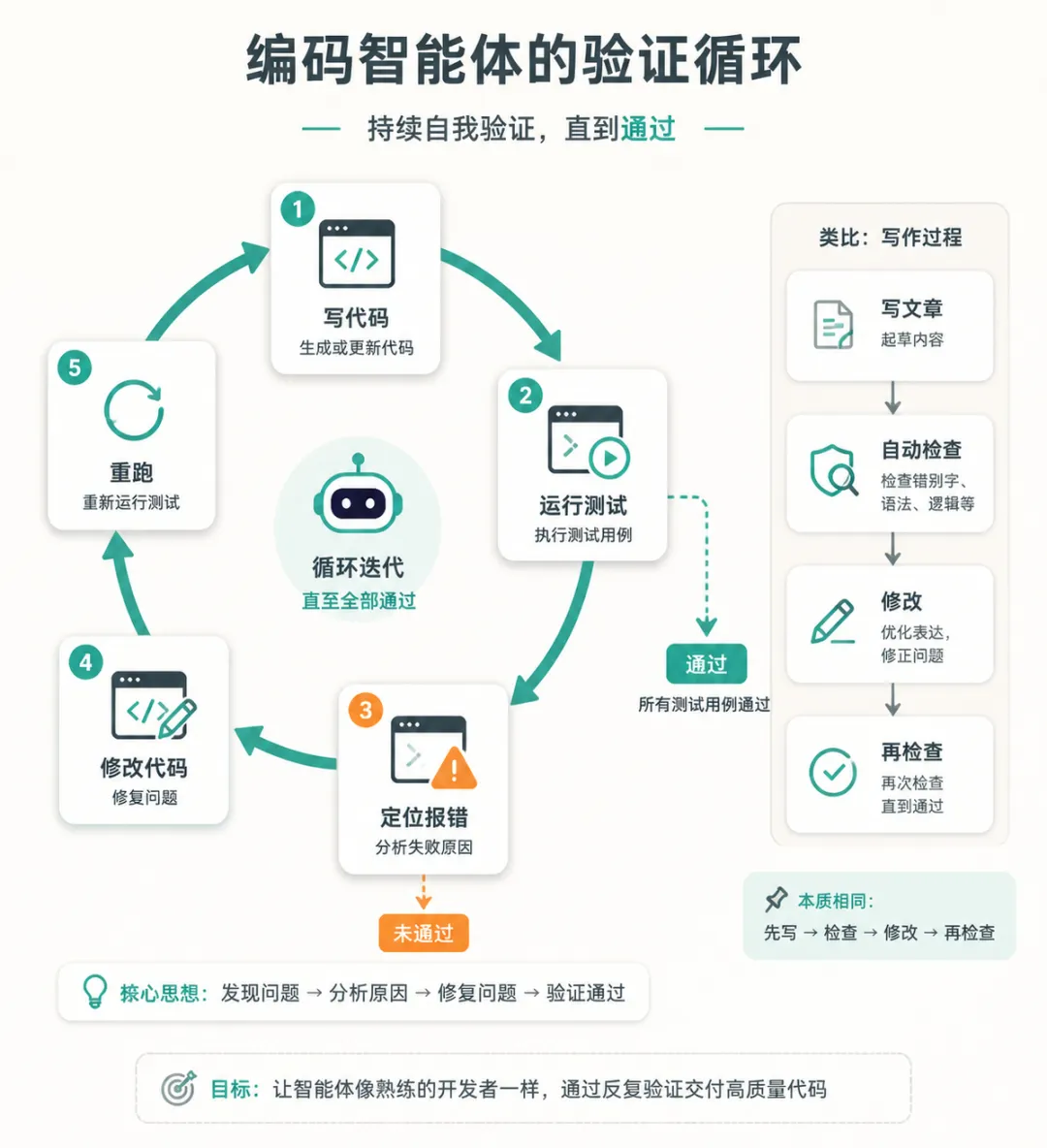
具体是什么样的?想象一个不懂编程的人也能理解的版本:
你在写一篇文章,写完之后有一个工具可以自动检查——哪些句子太长、哪些词用错了、哪些段落逻辑不通。工具给出反馈,你修改,再检查,再修改,直到所有问题都解决。
编程 Agent 做的事情和这个几乎一样:写代码 → 运行测试 → 看哪里报错 → 修改代码 → 再运行 → 直到测试通过。这个循环,Agent 可以自己跑几十次,不需要人在旁边盯着每一步。
这就是为什么编程是第一个被 Agent 大规模改变的领域——不是因为代码比其他工作更重要,而是因为代码有一个天然的验证机制,让 Agent 的自我纠错成为可能。
但这里有一个值得注意的地方:即使是编程 Agent,它也不是在所有任务上都表现一致。同一个 Agent,可以流畅地重构十万行代码,但在某些看起来更简单的问题上却会犯低级错误。原因之一,就是反馈循环的松紧程度:在有明确测试的地方,Agent 能快速纠错;在没有明确标准的地方,它就容易跑偏。
所以,编程是第一个证明点,不是终点。它真正说明的是:只要一个工作领域有足够清晰的验证机制,Agent 就有机会在那里建立起有效的工作循环。
四、这其实是关于大多数白领工作的故事
如果验证机制是关键变量,那接下来更值得问的问题其实是:你自己的工作里,有没有类似的结构?
如果你不写代码,你可能会觉得上面这些故事和你的工作关系不大。但在继续往下读之前,先停一秒,想想你上周做过的某一件具体的工作——不管是写一份分析报告、筛选一批候选人、还是跟进一个跨部门的项目。
你做了什么?
大概率是这样的:你先收集了一堆散乱的信息——邮件、文档、数据、别人的反馈。然后你在脑子里形成了一个初步判断。接着你用了一些工具——搜索、表格、沟通软件——把这个判断变成了一个具体的东西:一份文档、一封邮件、一个决策建议。然后你检查了一遍,发现有些地方不对,改了改,再发出去。
这个过程,和编程 Agent 做的事情,在结构上几乎是一样的:收集上下文 → 形成假设 → 使用工具 → 产出成果 → 检验结果 → 迭代。
场景一:分析师写备忘录
一个投资分析师需要在周五下午之前交一份行业研究备忘录。她的原材料是:三份散乱的行业报告、两家竞争对手的财报、一个同事发来的数据表格,还有她自己上周参加行业会议时记的笔记。
她要做的事情是:把这些东西整合成一个有观点的文档,说清楚这个行业现在的格局、关键变量是什么、值得关注的风险在哪里。
这个任务的结构是:收集分散的输入 → 提炼出核心论点 → 用工具(搜索、表格、写作)把论点变成文档 → 检查逻辑是否自洽 → 修改 → 交付。
一个 Agent 可以做这件事的大部分:搜索相关资料、提取关键数据、起草初稿、检查数字是否一致。它能在几十分钟内给出一个结构完整、引用清晰的版本。分析师的工作,从“做每一步”变成了“设定方向、提供判断框架、审查输出是否真的有洞察”。
场景二:招聘负责人筛选候选人
一家初创公司的创始人需要找一个开发者关系负责人。他给 Agent 发了一条消息,大意是:要技术背景够硬、能在工程师圈子里建立信任,但同时真的喜欢在社交媒体上活跃。我们卖给平台团队。去找。
Agent 开始工作。它先搜索了竞争对手公司的 DevRel 职位,找到了几百个候选人。但职位名称说明不了谁真的擅长这件事,于是它转向信号:搜索技术会议的演讲视频,找到了五十多个演讲者,再筛选出互动数据好的。然后它交叉比对这些人的社交媒体账号,过滤掉那些只转发公司博客的——留下了十几个有真实观点、能和工程师产生互动的人。
它继续缩小范围:检查谁最近三个月发帖频率下降了——这有时意味着对当前工作的倦怠。三个名字浮出来。它逐一调查:一个刚宣布了新职位,太晚了;一个是刚融资的公司创始人,不会离开;第三个在一家刚裁员的公司做高级 DevRel,她最近的演讲主题正好是这家初创公司的目标客户群,社交媒体上有一万四千个关注者,发的内容工程师真的会点赞。她的 LinkedIn 两个月没更新。
Agent 起草了一封邮件,提到了她最近的演讲,点出了业务方向的重叠,以及小团队能给的创作自由。建议约一次轻松的对话,不是正式面试。
整个过程:31 分钟。创始人拿到的不是一份职位描述,而是一个有名字、有背景、有接触理由的候选人。
这个例子来自 Sequoia 2025 年的文章《2026: This is AGI》,它描述的不是未来想象,而是已经在发生的工作方式。
场景三:跨部门项目跟进
一个项目经理负责协调五个部门之间的一个产品上线。每周她要做的事情是:整理各方的进展更新、识别哪些地方卡住了、起草一封给所有人的同步邮件、跟进上周的待办事项是否完成。
这件事的结构是:收集分散的状态信息 → 识别阻塞点 → 产出沟通文档 → 跟进行动项 → 下一轮循环。
一个 Agent 可以接管这个循环的大部分机械性工作:读取各方的更新、生成状态摘要、起草跟进邮件、标记逾期的行动项。项目经理的注意力,可以从“整理信息”转移到“判断哪些阻塞点真正需要她介入、哪些可以让系统自动推进”。
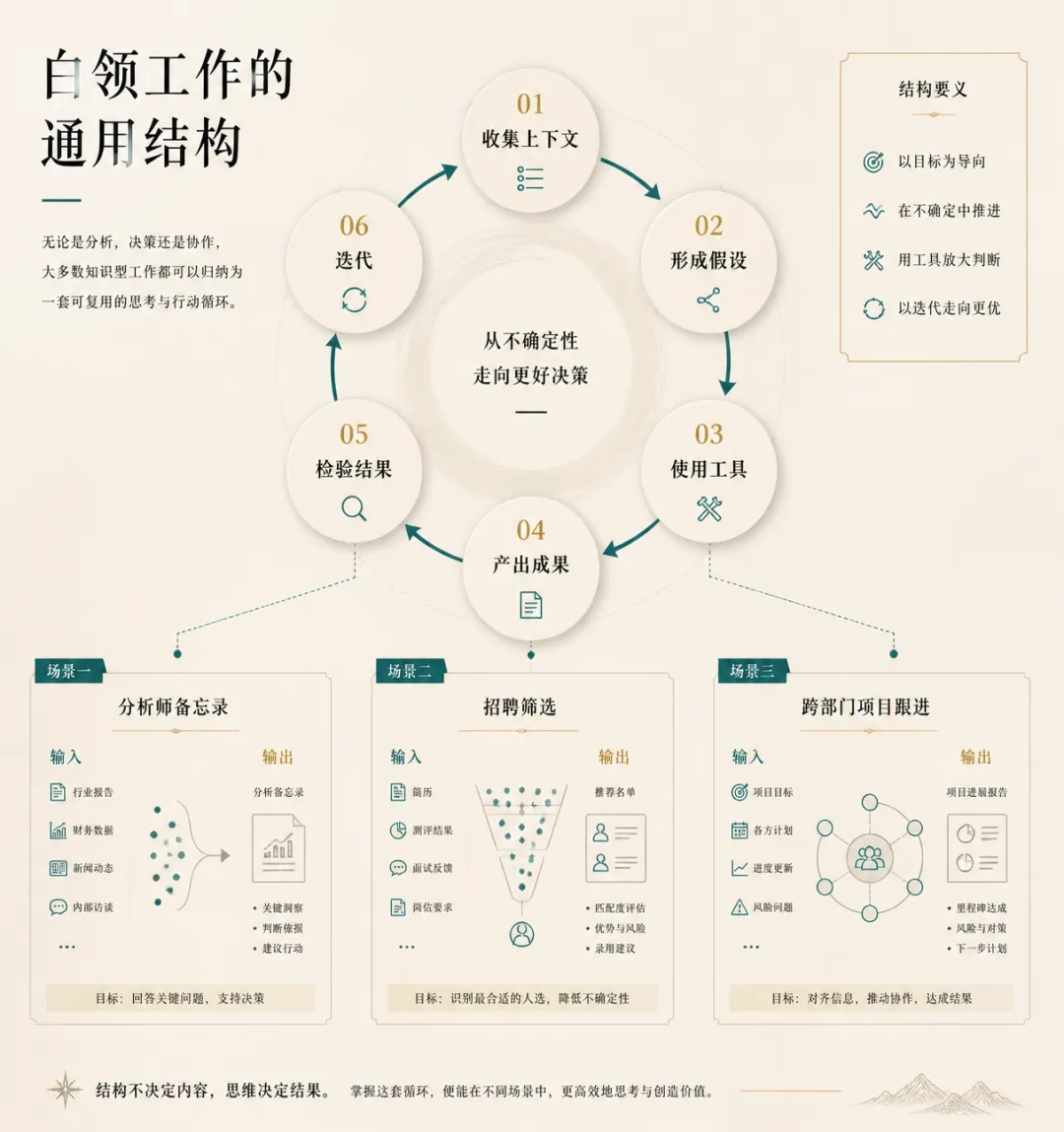
这三个例子有一个共同的结构,也有一个共同的前提:任务的结果是可以被检验的。备忘录的逻辑是否自洽,可以读出来;候选人是否匹配,可以对照标准;项目是否推进,可以看行动项是否完成。
但不是所有工作都有这个前提。
有一类工作,验证本身就是模糊的。比如:一个品牌的视觉风格是否“对”?一次艰难的绩效谈话是否处理得当?一个产品方向是否值得押注?这些判断没有测试可以跑,没有标准答案可以对照。它们依赖的是经验、直觉、对人的理解,以及对“什么是真正有价值的”的品味。
在这些地方,Agent 目前能做的,主要是提供信息和起草初稿——但最终的判断,还是需要人来做。而且这个判断的质量,很大程度上取决于那个人对问题的理解有多深。
所以,这不是一个“AI 会替代所有白领工作”的故事。而是一个更具体的故事:在那些有清晰验证机制的工作环节,Agent 正在接管越来越多的执行循环;而在那些验证本身就是模糊的地方,人的判断依然是不可替代的——而且可能变得更加稀缺和重要。
五、为什么能力曲线可能加速
读到这里,你可能会想:好,Agent 现在能做这些,但它也会犯错、会跑偏、会在没有明确反馈的地方失去方向。这些限制是真实的。那么,为什么不能把它们理解成一个稳定的天花板,然后继续按原来的方式工作,只是偶尔用 AI 加速一下?
这个问题值得认真回答,而不是用“AI 发展很快”这种话糊弄过去。
有一个来自港口历史的故事,可能比任何技术预测都更能说明问题。
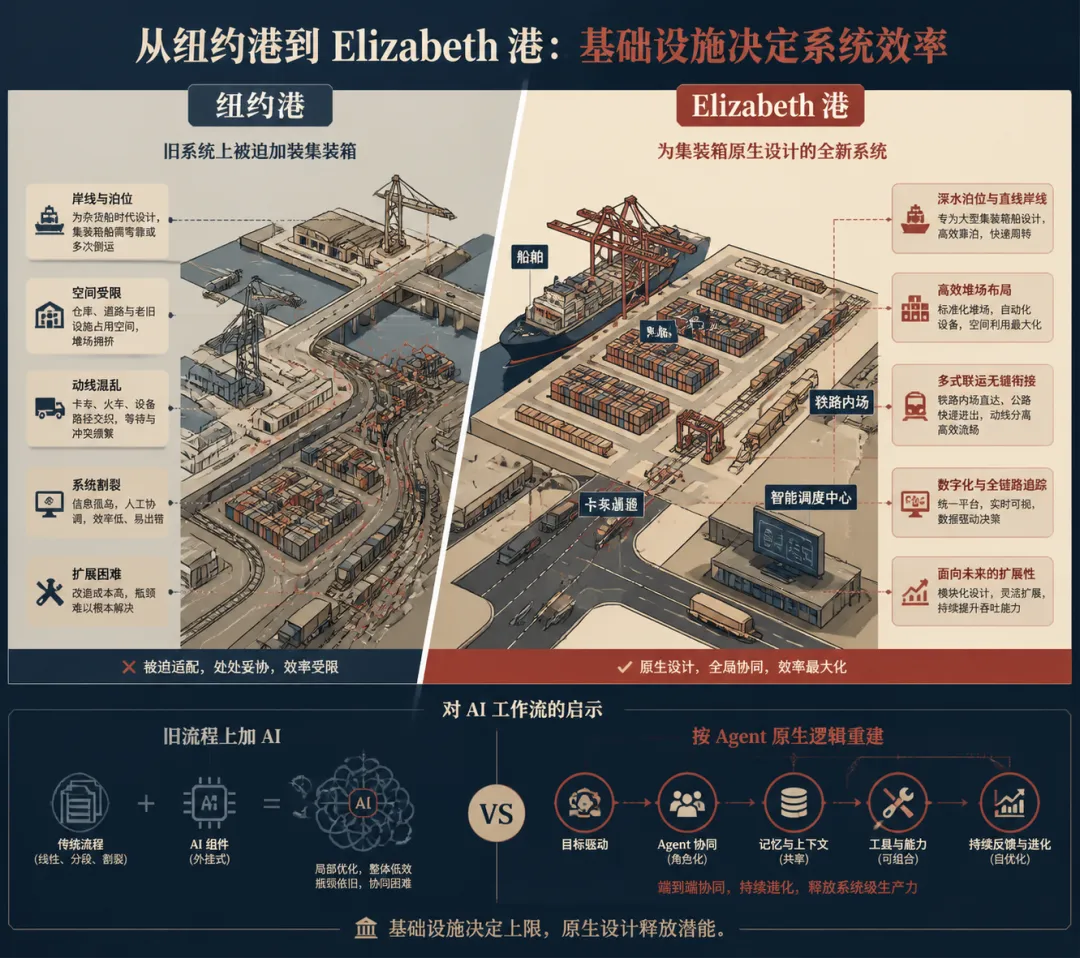
1956 年,集装箱刚出现的时候,纽约港是北美最大的港口。它当然看到了集装箱的效率优势——装卸成本从每吨 5.83 美元降到了 0.16 美元,降了三十多倍(这个经典对比出自 Marc Levinson 的《The Box》)。纽约港的反应很合理:在原有的散货码头旁边加装集装箱泊位。装卸效率提高了,但整体结构没变。
问题在于,集装箱不只是“一个更快的盒子”。它要求整套组织形态跟着变:大型堆场、铁路直接接入码头、高速公路直接接入、完全不同的工会合同、全新的电子追踪系统。这些改变组合在一起,要求的是一次整体重建,不是在旧框架上打补丁。
纽约港做不到。不是不想,是每一条都被既有资产挡住了:曼哈顿地价太高没法建堆场,铁路接入改造会拆掉半个城市,工会合同动不了。
哈德逊河对岸的新泽西 Elizabeth 港,1950 年代还是一片沼泽地。没有港口历史,没有既有资产,没有需要保护的利益结构。1958 年,新泽西港务局决定把 Elizabeth 港完全为集装箱从零设计——堆场、铁路、公路、工会合同、追踪系统,全是新的。1962 年开港,1970 年代超过纽约,1980 年代成为北美最大集装箱港之一。几公里外的纽约港在同一时期基本停摆。今天曼哈顿下城的老码头区,变成了博物馆和奢侈公寓。
这个故事的要点不是“新的总是赢”,而是更具体的一件事:在旧框架上把新工具用得最好的港口,输给了从零按新逻辑建起来的港口。
这个规律,在 AI 时代可能正在重演。
今天大多数公司使用 AI 的方式,是在原有工作流程上加工具:邮件写得快了,报告起草得快了,会议纪要自动生成了。这是真实的效率提升,值得做。但它的问题和纽约港一样:你能用,竞争对手也能用。效率红利很快被拉平,没有人真正拉开距离。
而另一种可能性是:有些团队正在做的事情,不是“在旧流程里把 AI 用得更好”,而是从零开始,按照 Agent 能做什么、不能做什么,重新设计工作流程本身——哪些环节交给 Agent 自动循环,哪些节点需要人介入,验证机制怎么建,上下文怎么传递。
这两种方式的差距,现在可能还不明显。但如果 Agent 的能力继续沿着当前的轨迹提升——比如有研究机构 METR 正在追踪这条曲线——那么围绕 Agent 原生假设设计的工作流,可能会比在旧结构上打补丁的工作流,积累出越来越大的优势。到那时,二者之间的差距就不再只是效率高一点、低一点,而会更像 Elizabeth 港和纽约港之间的差距:不是线性拉开,而是按新框架重组之后迅速拉开。
这未必会在所有行业、所有任务里同时发生。但它已经足够值得认真对待。纽约港的问题不是它不够努力,而是它在用旧框架理解一个需要新框架的变化。
六、Software 3.0:AI 成为数字工作的新操作层
有一个框架,可以帮助理解这一切变化的底层逻辑。
在 Sequoia Ascent 2026 的一次演讲里,有人提出了一个划分:Software 1.0 是人写明确的代码,告诉计算机每一步怎么做;Software 2.0 是人设计目标和数据,让神经网络把程序“学”进权重里;Software 3.0 是人通过上下文、工具、示例、记忆和指令来“编程”大语言模型——模型成为一个能理解意图、调用工具、持续工作的解释器。
这个框架的意义不在于给技术分代,而在于它说明了一件事:AI 正在成为数字工作的一个新操作层,就像操作系统是软件的基础层一样。
在这个新层上,有些东西变便宜了。
写样板代码、生成初稿、重复性的格式整理、标准化的信息提取——这些任务的边际成本正在趋近于零。以前需要一个人花半天做的事,现在可能几分钟就有一个可用的版本。
但有些东西,反而变得更稀缺、更有价值。
评估设计:你怎么知道 Agent 的输出是对的?谁来定义“对”的标准?这个判断框架本身,需要人来建。
边界和安全:Agent 能做什么、不能做什么,在哪里必须停下来等待人的确认——这些边界不会自动出现,需要人来设计和维护。
系统编排:当多个 Agent 协作完成一个复杂任务时,谁来决定任务怎么拆分、上下文怎么传递、失败了怎么恢复?这个编排层,是新的核心工程工作。
可复用的上下文:一个团队积累的判断标准、工作规范、领域知识——如果能被结构化地传递给 Agent,就变成了一种可以持续复利的资产。
换句话说:执行变便宜了,但定义执行框架的能力变贵了。

七、注意力、理解力,和品味
这里有一个容易被忽视的问题:如果 Agent 能做越来越多的执行工作,人的价值在哪里?
一个直觉上的答案是“人负责创意,AI 负责执行”。但这个答案太模糊,也不够准确。
更精确的说法是:人的注意力是稀缺的,而且是不可替代的。
Agent 可以在你不盯着它的时候持续工作,但它不能替你决定什么值得做、什么结果是真正有用的、什么方向是对的。这些判断需要你真正理解正在发生的事情——不只是看到输出,而是能判断输出是否符合真实需要。
这就是为什么“保持理解”变得如此重要。
当 Agent 帮你完成了一份分析报告,你不能只是接受它。你需要能判断:这个结论是否真的成立?这个数据来源是否可靠?这个建议是否适合你的具体情况?如果你对这个领域的理解在退化——因为你把越来越多的思考外包给了 Agent——你就失去了做这个判断的能力。
但在所有这些能力里,有一种可能是最难被复制的,也是最值得培养的:品味。
品味不是审美偏好,不是“我觉得这个好看”。品味是一种判断力:能注意到什么真正重要、能选择什么值得去做、能判断一个输出是否真的对真实的人有用。
当执行成本趋近于零,“做出来”不再是稀缺的。稀缺的是“做对的事”和“做出真正有用的东西”。这两件事,都需要品味。
一个有品味的人,在 AI 工具面前,能更快地识别哪些输出是真正有价值的,哪些只是看起来不错;能更准确地定义什么样的结果才算成功;能在 Agent 跑偏的时候更早发现问题。
品味可能正在成为 AI 原生世界里最持久的人类优势之一。这不是一个已经被证明的结论,而是一个值得认真对待的方向。

八、你的工作,正在变成什么?
读到这里,你可能已经在想自己的工作了。
这篇文章不是要告诉你 AI 会不会替代你。那个问题太笼统,也不是最重要的问题。
更值得问的问题是:你的工作,正在变得对 Agent 更友好吗?
具体来说:你的工作里,有没有可以被清晰定义的目标?有没有可以被检验的输出?有没有可以被结构化传递的上下文?如果有,那么 Agent 正在、或者很快会进入这些环节。
而你的角色,可能正在从“做每一步”,转向“定义目标、提供上下文、设计验证标准、在关键节点做判断”。
这个转变不是一夜之间发生的,也不是对所有人同时发生的。但它的方向是清晰的。
那么,你现在花最多时间做的那件事——它是执行,还是判断?如果明天有一个 Agent 能做其中的大部分执行工作,你的注意力会去哪里?你的理解力和品味,是在增长,还是在萎缩?
这些问题没有标准答案。但它们是值得认真想的问题。