 夜雨聆风
夜雨聆风





AI 编码术语到底在说什么?这份词典 57 个词条把黑话翻成了人话
项目卡片
项目:dictionary-of-ai-coding[1] 状态:57 词条 / 1k+ Stars / 5 天内从零增长 一句话判断:AI 编码领域的”术语黑话翻译器”,信息密度远超同类文档,适合所有正在用 AI 写代码的人读一遍。
用 AI 写代码这件事,有一个隐性门槛:你得先听懂行话。
context、context window、session、contextual knowledge——四个词都带 context,到底在说什么?hallucination 说”模型编了东西”,但到底是记错了还是读漏了,处理方式完全不同。
Matt Pocock 的 dictionary-of-ai-coding[2] 做了一件事:57 个术语,逐个拆开,用开发者对话演示用法,再标出哪些说法该避免。 项目本身就是一个 GitHub 仓库,纯 Markdown,不需要安装任何东西。
Matt Pocock 是谁?TypeScript 社区知名教育者,Total TypeScript 创始人,newsletter 订阅者 62k+。他做这件事的动机写得很直白:“AI 编码的困惑有很大一部分是被制造出来的——一整条 VC 资助的经济链条受益于让它保持难懂。” 项目 5 月 1 日创建,5 天 38 个 commit,目前 57 个词条。
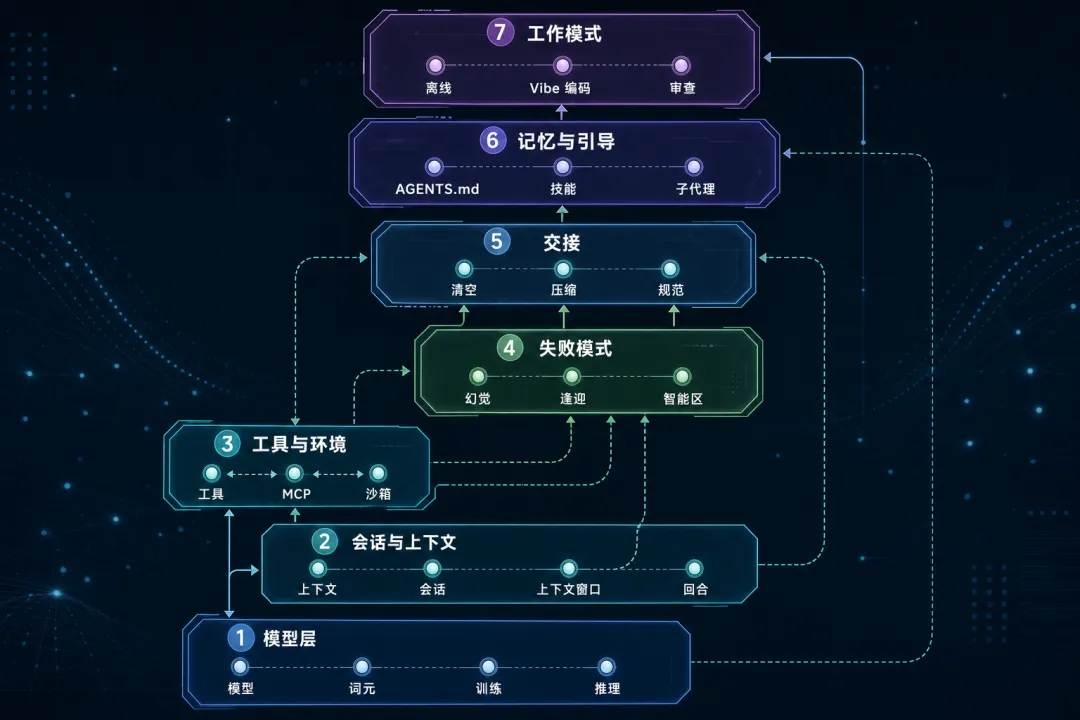
这 57 个词条不是随意罗列,而是按 7 个章节组织,从底层模型一路讲到工作模式:
-
The Model — Model、Token、Training、Inference……模型本身是什么 -
Sessions, Context Windows & Turns — Context、Session、Context window、Stateless/Stateful -
Tools & Environment — Tool、Tool call、MCP、Sandbox、Permission mode -
Failure Modes — Hallucination、Sycophancy、Attention degradation、Smart zone -
Handoffs — Clearing、Compaction、Handoff artifact、Spec、Ticket -
Memory and Steering — AGENTS.md、Progressive disclosure、Skill、Subagent -
Patterns of Work — AFK、Human-in-the-loop、Vibe coding、Grilling
这个结构本身就是教学设计。读一遍下来,你脑子里的概念会从散装变成有层级的。词条之间有大量交叉引用——第一个出现的术语会链接到它自己的定义,形成一个可以自由跳转的网。比如你从 Hallucination 跳到 Attention degradation,再跳到 Smart zone,几条读完,context 退化这件事的前因后果就串起来了。

词典类项目的通病是:每条都写,但每条都浅。这个项目反着来——每条很短(平均 65 词),但几乎每条都在做区分。
比如 Hallucination 这条,直接拆成两种:
-
Factuality hallucination——模型凭空编造。原因是 parametric knowledge 有缺口,修复方式是加载正确的 contextual knowledge -
Faithfulness hallucination——模型没读进去已经给它的东西。原因是 attention degradation,修复方式是 clear 或 compact
同一个词,两种原因,两种修法。这个区分直接决定了你下一步该做什么。
再比如 Smart zone / Dumb zone:session 开始时 agent 处于”聪明区”,越往后越进入”愚蠢区”——同一个模型,同一个 harness,只是 context 变多了。”大约在 100,000 tokens 左右开始变蠢,但这个数字有争议。”这条没有学术论文背书,但它精准描述了大量 AI 编码用户的体感。
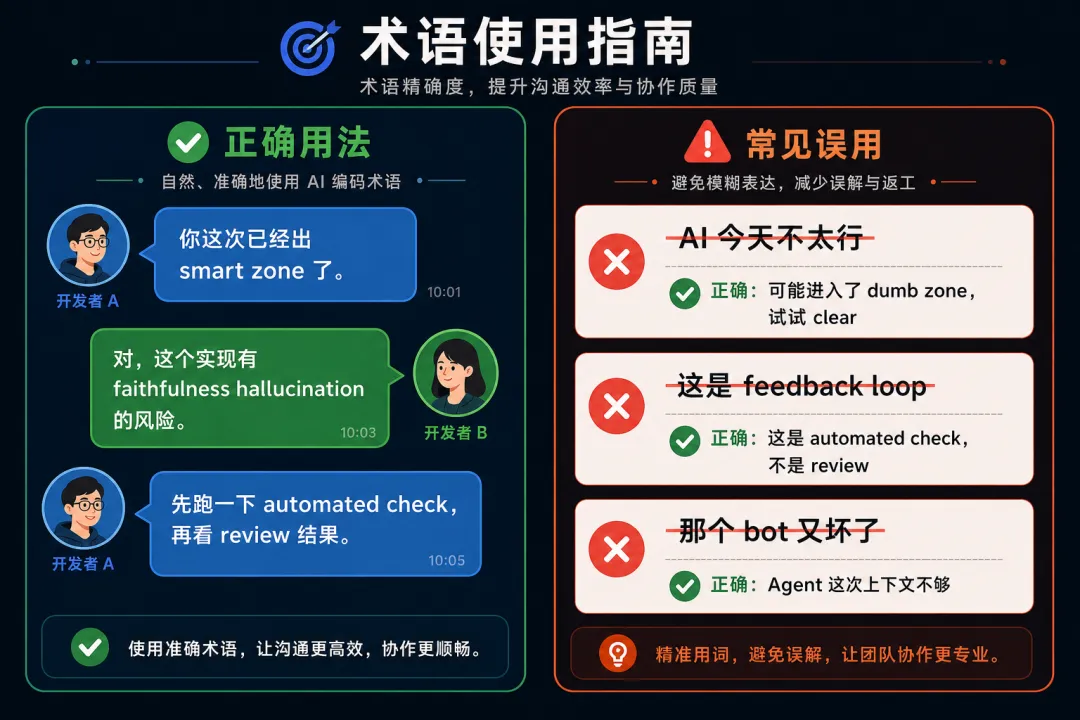
大约四分之一的词条带有一个 Avoid 部分,明确标注哪些说法容易误导。这个设计不常见,但非常有用:
-
Agent 条:避免说 “the AI”、”the bot”——太模糊,掩盖了你说的是参数本身还是被 harness 化了的东西 -
Vibe coding 条:避免用来指”低质量 AI 编码”——它命名的是审查立场,不是代码质量 -
Automated check 条:避免说 “feedback loop”——那把 check 和 review 混在一起了
这些标注暴露了一个事实:很多关于 AI 编码的讨论之所以混乱,不是因为技术难,而是因为术语没有被精确定义。 你以为在和同事说同一件事,其实脑子里指的是不同的东西。
每个词条都以一段对话结尾,不是教科书式的造句,而是开发者之间真实的交流场景:
“它一直捏造类型里没有的字段。”
“类型文件不在 context 里——它在读调用处然后猜。把定义读进去。”
“Claude 今天太烂了。他们是不是推了个更差的版本?”
“多半不是——模型输出是非确定性的。同一个任务你会有好日子和坏日子。明天再试一次,先别急着找原因。”
这种写法的好处是:你不仅学到了术语的定义,还学到了什么时候该用这个术语来诊断问题。对话里的角色会引用其他术语,形成一种自然的概念串联——读到 Non-determinism 条的时候会提到 smart zone,读到 Sycophancy 条的时候会提到 clear,读多了自然建立起术语之间的联系。
项目的工程层面也值得一看。README.md 不是手写的——它由一个 TypeScript 脚本(internal/generate-readme.ts)从三个源自动组装,运行 npm run generate 即可重新生成:
-
dictionary/*.md— 全部 57 个词条的正文 -
internal/Curriculum.md— 词条的章节排列顺序 -
internal/README.template.md— 头尾模板
运行 npm run generate 就会重新生成 README。CI(GitHub Actions)在每次 push 和 PR 时都会检查 README 是否与源文件同步,不同步就报错。
这意味着词条的维护者只需修改 dictionary/ 下的对应文件,再更新 Curriculum.md 的顺序,README 会自动保持一致。交叉引用的链接也会在生成阶段自动从相对路径转为锚点链接。
几个典型场景:
-
用 Claude Code 写了半天代码,session 越来越长,模型开始”变笨”——翻 Smart zone 和 Attention degradation,搞清楚发生了什么 -
同事说”模型又幻觉了”,你想知道是 factuality 还是 faithfulness——翻 Hallucination -
团队要引入 AI 编码流程,需要统一语言——把词典里的定义直接拿来当团队术语规范 -
刚接触 AI 编码工具,被 context、session、tool call 这些词绕晕——从头到尾读一遍
不太需要的:已经对 LLM 架构和 agent 模式有系统了解,这些术语对你来说没有新信息。
一天能读完,但它解决的问题会一直伴随你的 AI 编码实践:当你遇到 context 退化、模型”变蠢”、同样的 prompt 不同表现这些问题时,你能准确描述发生了什么,而不是含糊地说”AI 今天不太行”。
Matt Pocock 项目的 README 开头有一句话:“基本规则一个下午就能学会。一旦你有了这些词,整件事就不再像在猜了。”
这个词典就是帮你拿到这些词的。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
引用链接
[1]dictionary-of-ai-coding: https://github.com/mattpocock/dictionary-of-ai-coding
[2]dictionary-of-ai-coding: https://github.com/mattpocock/dictionary-of-ai-coding