当前时间: 2026-05-11 22:24:34
更新时间: 2026-05-11
分类:软件教程
评论(0)
openclaw技能分享—网站爬取
装上 Web Scraper 技能后,OpenClaw,就可以变成一个“AI爬虫助手”。
不需要自己从零写代码,只要说明想抓取的网站、内容字段和保存格式,AI 就能根据网页情况生成爬虫脚本,帮助整理公开网页数据。
一、适合哪些场景?
二、环境准备
第一步:打开 OpenClaw / QClaw / AutoClaw
先进入你安装好的工具,例如 OpenClaw、腾讯 QClaw 或智谱 AutoClaw。
如没有openclaw 推荐浏览器搜索并下载Qclaw
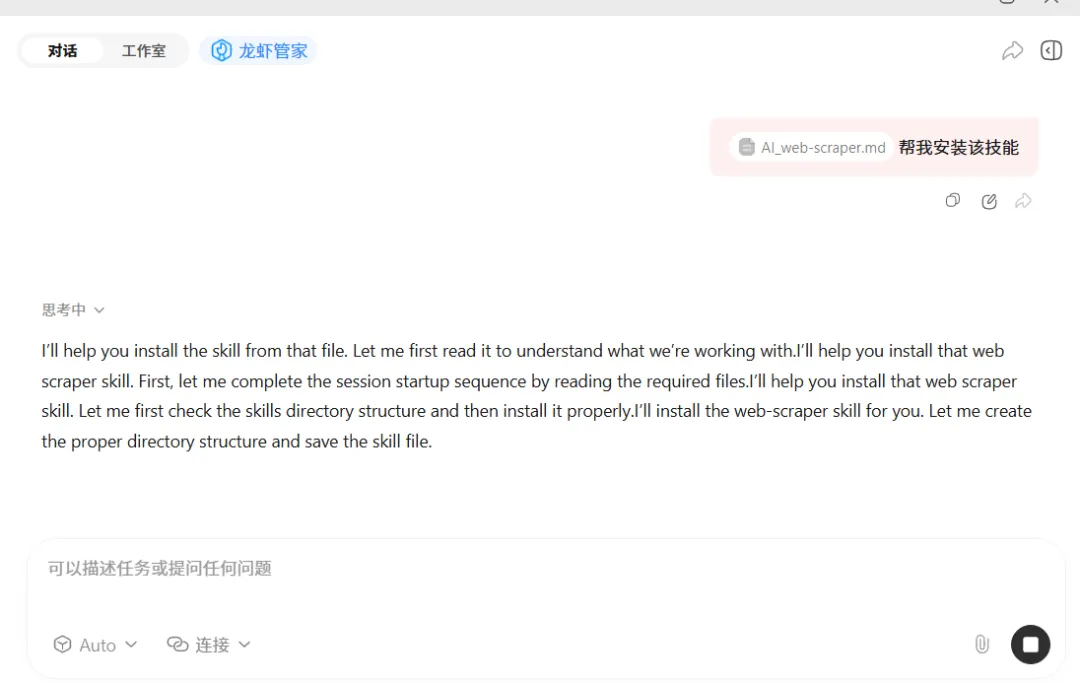
或将skill.md文件发送给你的claw助手,输入:
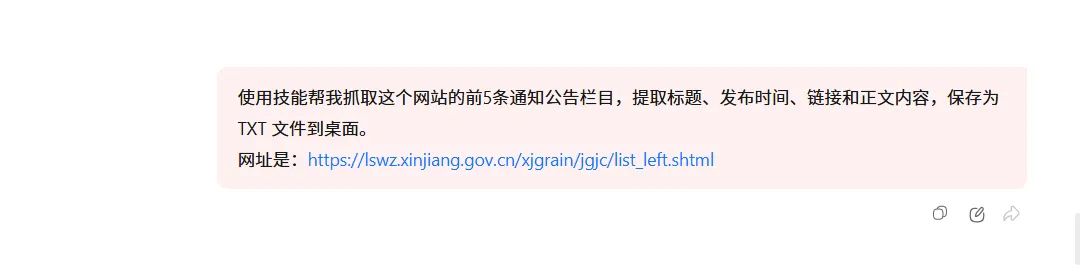
使用相关技能帮我抓取这个网站的通知公告栏目,提取标题、发布时间、链接和正文内容,保存为 CSV 和 TXT 文件到桌面。
请抓取该网站前 5 页文章列表,每篇文章需要提取标题、发布日期、来源、正文和原文链接,最后保存为 data.csv 和.txt。
其中:data.csv 可以用 Excel 打开;
三、推荐提示词
你现在是一个 AI 爬虫助手。请帮我抓取以下网站的公开网页内容。
-
-
只抓取公开可访问内容,不绕过登录、验证码或权限限制。
四、使用时注意
不要抓取需要登录、验证码、付费权限的数据,也不要采集个人隐私信息。
 夜雨聆风
夜雨聆风