夜雨聆风
夜雨聆风





AI 网络互连硬件第四篇:AI Ethernet 的工程门槛,RoCE、拥塞控制、交换 ASIC 与系统全解

目 录
-
1、先把问题说准:AI Ethernet 不是便宜版 InfiniBand -
2、为什么工程化门槛会成为第四层利润池 -
3、连接白皮书补上的,是 AI Ethernet 的物理工程边界 -
4、RoCEv2 是门票,但不是护城河 -
5、PFC、ECN、DCQCN:无损以太网不是口号 -
6、Packet spraying 与 adaptive routing:开放网络要处理“乱”和“堵” -
7、交换 ASIC:Tomahawk、Jericho、Spectrum、Silicon One、Teralynx 分工不同 -
8、系统软件:AI Ethernet 的护城河不在 CLI,而在稳定扩容 -
9、白盒不是低端代工:Celestica 与 Accton 证明交付层也有门槛 -
10、客户路线:不是所有云厂都会用同一张网络图 -
11、财务验证:这篇是工程分析,但不能脱离订单和利润表 -
12、公司排序:先按控制层级,不按热度排序 -
13、证伪清单:什么时候说明 AI Ethernet 工程化逻辑不成立 -
14、季度跟踪表:只看订单不够,要看工程指标和财务指标一起改善 -
15、最终判断:开放网络的赢家,是能把复杂度做成平台的人
AI 网络互连硬件第四篇:AI Ethernet 的工程门槛,RoCE、拥塞控制、交换 ASIC 与系统软件全解
AI 网络互连硬件第一篇:1.6T/3.2T 背后的价值迁移,交换、铜互连、光互连和物理层谁最受益
英伟达、博通与 Marvell 的 AI 网络控制权:2026 英伟达闭环与博通开放网络之战
铜互连没有结束:Astera Labs、Credo 与 Marvell 高速连接芯片,2026 AI 机柜短距连接控制权全解
全文内容概括:本文的核心判断是,AI Ethernet 不是低配 InfiniBand,而是一套必须用 RoCEv2、PFC、ECN、DCQCN、VOQ、deep buffer、packet spraying、adaptive routing、NIC/DPU 卸载和系统软件共同补齐的工程化网络。InfiniBand 的优势在于成熟闭环、低延迟和训练稳定性;AI Ethernet 的优势在于开放生态、单位带宽成本、多供应商选择和云厂自研 ASIC 的架构自由。真正的分歧不是二选一,而是开放以太网能不能在万卡、十万卡乃至跨园区集群里稳定处理拥塞、乱序、长尾延迟和故障定位。
Bernstein 2026 年 5 月 97 页 AI 数据中心连接白皮书进一步补上物理层约束:CPO/NPO/LPO、铜互连、CPC、OCS、PCB/CCL/ABF 与高端材料不是独立主题,而是决定 AI Ethernet 能否从 800G 走向 1.6T、3.2T 的底层边界。投资上应把 AI Ethernet 拆成四层排序:交换 silicon 与架构控制权看 Broadcom、NVIDIA、Marvell;系统软件和客户网络平台看 Arista、Cisco;白盒工程与交付验证看 Celestica、Accton;物理连接和材料瓶颈看光引擎、外部光源、FAU、PCB/CCL、铜缆和接口芯片。
1、先把问题说准:AI Ethernet 不是便宜版 InfiniBand
市场最容易犯的错误,是把 AI Ethernet 理解成“成本更低的 InfiniBand 替代品”。这个说法只看到了采购价格,没有看到工程代价。
InfiniBand 的强项,是把低延迟、拥塞控制、网络适配器、交换机、软件栈和故障定位做成一个相对闭环的系统。对高端训练集群来说,闭环的价值不是好看,而是减少训练中断、长尾延迟和排障时间。GPU 或 XPU 越贵,网络不稳定造成的机会成本越高。
AI Ethernet 的价值也不是“低价”。它的真正价值在开放性:云厂可以混用不同交换 ASIC、不同 NIC/DPU、不同系统厂、不同光电链路和自研 ASIC/XPU。这个开放性给客户带来供应链选择、总拥有成本、软件自主权和架构迭代速度,但代价是工程复杂度显著上升。
所以这一篇要回答的问题不是“Ethernet 会不会替代 InfiniBand”,而是:开放以太网要靠哪些硬件和软件能力,才能跑出接近闭环网络的稳定性。
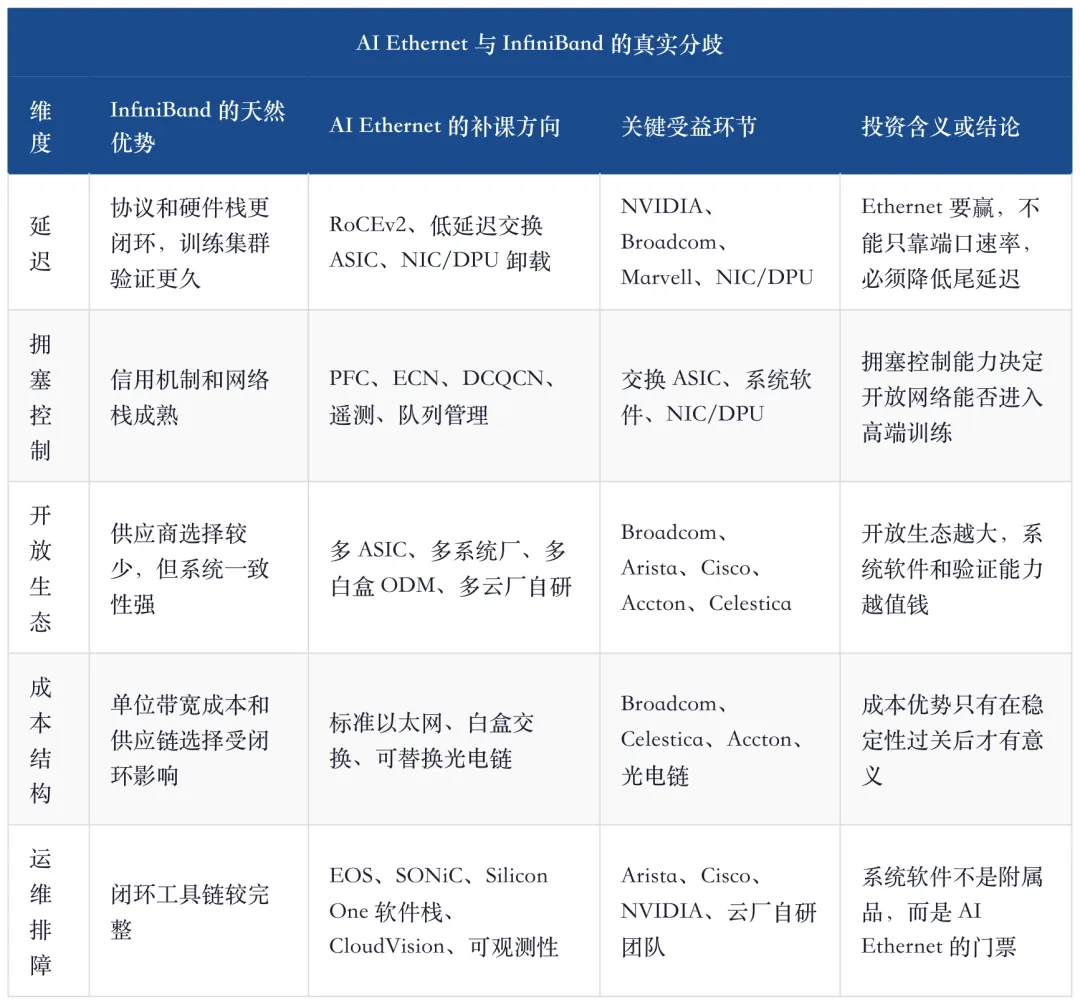
这张表决定本文的写法。前三篇已经分别回答了价值迁移、架构控制权和短距连接芯片;第四篇必须把焦点收回“工程能不能跑起来”。否则 AI Ethernet 只是一个开放网络口号,不能变成投资框架。
2、为什么工程化门槛会成为第四层利润池
AI 集群规模扩大后,网络的成本不是线性增加。Bernstein 把一个关键点讲得很清楚:随着 xPU 数量增加,网络层级、交换机数量、收发器数量和上层 fabric 复杂度都会放大。两层 fat-tree 到三层 fat-tree,不只是多买一点交换机,而是 switch-to-xPU、transceiver-to-xPU 和网络总带宽比例一起提高。
结果很直接:AI 网络越往大规模走,工程化门槛越会变成利润池。
如果只买交换机端口,价值会被白盒和竞价压缩;如果能解决拥塞控制、无损传输、尾延迟、遥测、网络自动化、故障定位和客户认证,价值就会从硬件 BOM 上移到系统级控制权。Arista 的 EOS、Cisco 的 Silicon One 与 Acacia、NVIDIA 的 Spectrum-X 与 BlueField、Broadcom 的 Tomahawk/Jericho 加客户定制网络,都是在争这层价值。
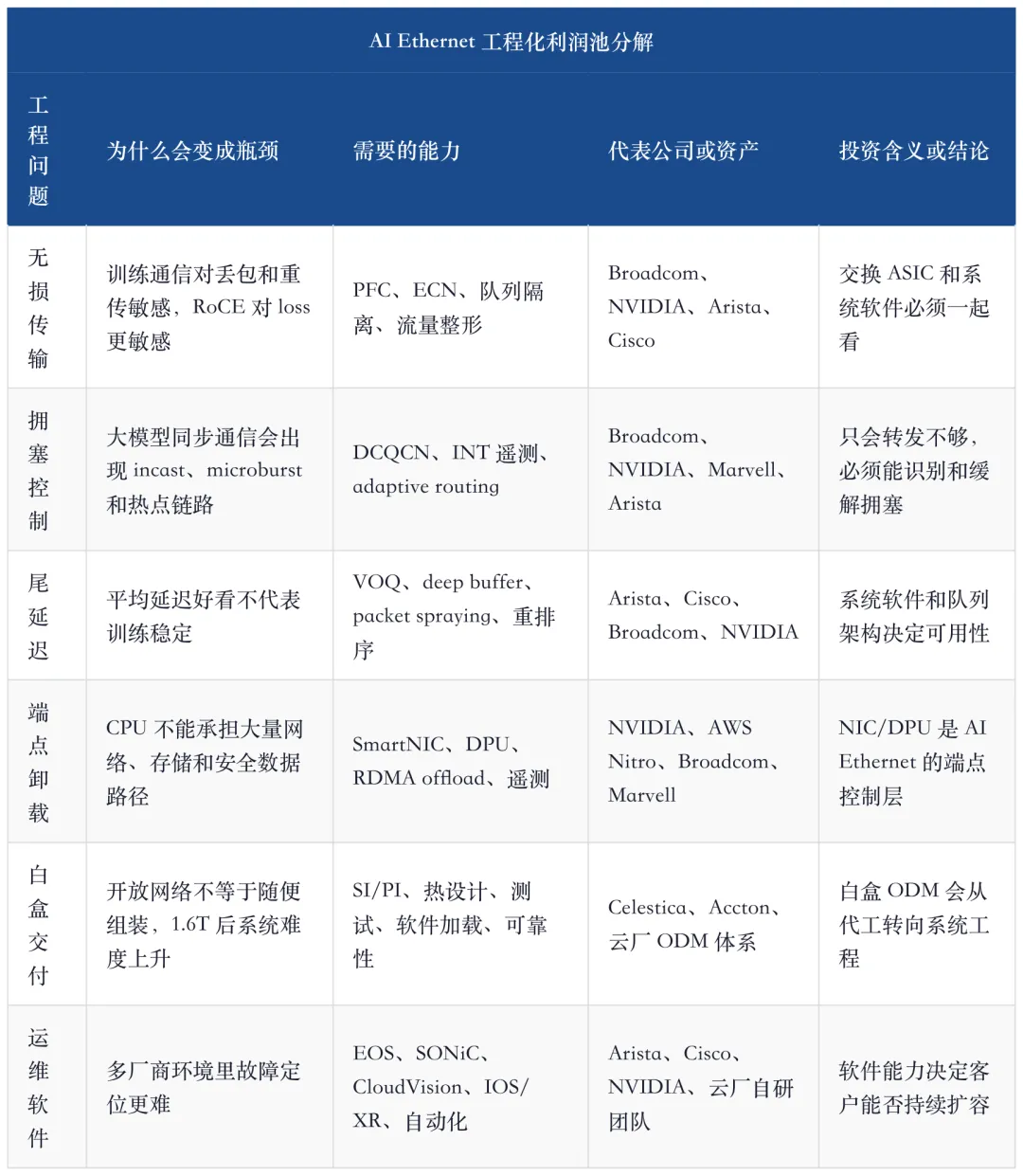
这里最重要的投资结论是:AI Ethernet 的价值不会平均分给所有以太网公司。它会向三个位置集中:交换 silicon、系统软件、复杂系统交付。没有 silicon,无法定义低延迟和队列能力;没有软件,客户无法稳定运营;没有交付能力,订单无法变成收入。

3、连接白皮书补上的,是 AI Ethernet 的物理工程边界
只讲 RoCE、交换 ASIC 和系统软件,还不够完整。Bernstein 2026 年 5 月的 AI 数据中心连接白皮书把问题往下压了一层:AI 数据中心正在从 compute-bound 走向 connectivity-bound,连接瓶颈同时发生在 scale-up、scale-out、机柜内短距、机柜间光链路、交换机板级设计和上游材料。
这份白皮书对第四篇最大的补充,不是简单告诉读者 CPO 很重要,而是提醒 AI Ethernet 的工程边界不止在交换芯片。前面板光模块、LPO/NPO 过渡、CPO 可靠性、DAC/AEC 铜缆长度、CPC、224G/448G SerDes、M8/M9 CCL、T-glass、HVLP 铜箔和 ABF substrate,都会影响开放以太网能不能稳定上 1.6T、3.2T。换句话说,AI Ethernet 的上限由协议栈和物理链路一起决定。

这张表把本文和此前 CPO、铜互连、PCB 文章区分开了。CPO 白皮书不是要把第四篇改写成光模块专题,而是告诉我们:AI Ethernet 的工程门槛是跨层问题。RoCE 解决传输语义,交换 ASIC 解决队列和路径,系统软件解决部署和排障,物理连接解决功耗、损耗、距离和可维护性。四层缺一层,开放网络都很难在高端训练里稳定扩容。
4、RoCEv2 是门票,但不是护城河
RoCEv2 的作用,是让以太网承载 RDMA。它把传统以太网从“通用包交换网络”推向“可用于高性能计算和 AI 集群的低开销传输网络”。没有 RoCEv2,AI Ethernet 很难与 InfiniBand 在训练场景里正面竞争。
但 RoCEv2 只是门票,不是护城河。原因很简单:协议本身开源、开放、可实现,真正困难的是怎么在真实大集群里处理 lossless fabric、拥塞、乱序、故障和运维。很多网络都可以说支持 RoCE,真正值钱的是能不能让 RoCE 在高负载、跨 pod、多路径和混合流量下稳定运行。
AI Ethernet 的 RoCEv2 栈可以分成四层。
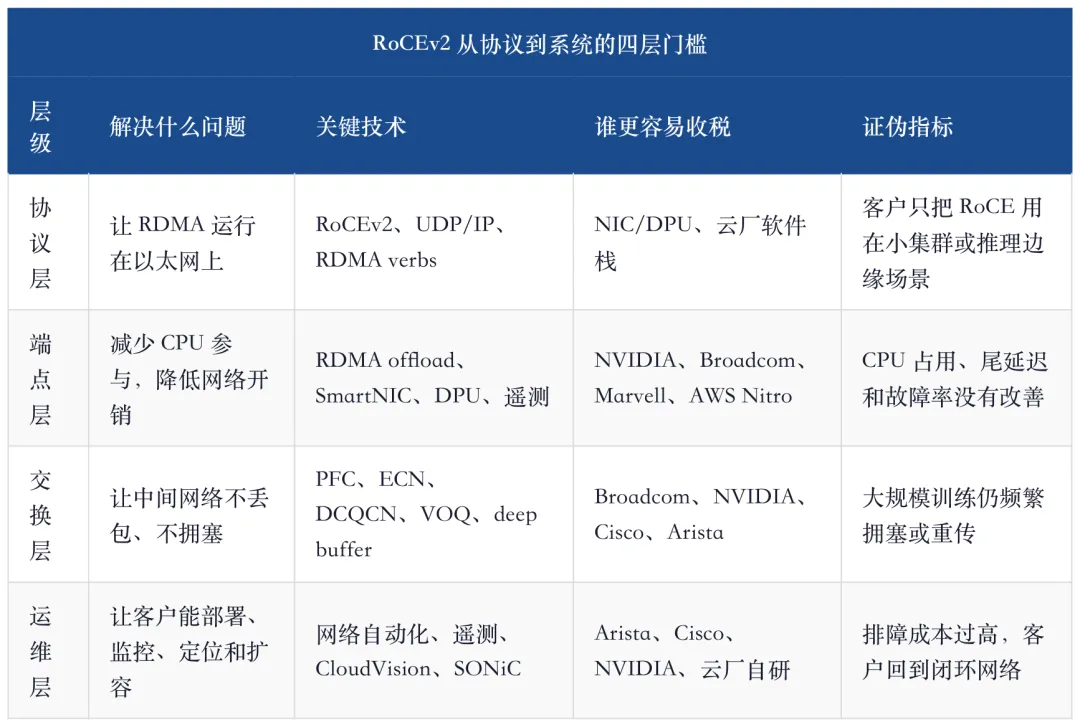
这也是为什么 Arista 的价值不只是交换机端口,Cisco 的价值不只是传统网络订单,Broadcom 的价值不只是 Tomahawk 芯片。RoCEv2 把以太网带进 AI 后端网络,但真正把 RoCEv2 变成可部署网络的是系统工程。
5、PFC、ECN、DCQCN:无损以太网不是口号
训练集群最怕的不是平均速度慢一点,而是尾部节点拖慢所有同步。All-reduce、parameter synchronization、MoE routing、推理 KV cache 调度都会让网络出现突发流量。以太网如果用传统丢包重传逻辑处理这些流量,会把延迟尾部放大。
所以 AI Ethernet 必须先做“近似无损”。PFC 用来在局部链路上暂停优先级流量,ECN 用来给拥塞做标记,DCQCN 用来让端点根据拥塞信号调整发送速率。三者都不是新名词,但在 AI 集群里,它们从“网络功能”变成“训练稳定性保险”。
问题也在这里。PFC 如果配置不好,会引入 head-of-line blocking,甚至出现 PFC storm;ECN 和 DCQCN 如果调参不好,会导致过度降速或拥塞缓解不及时。AI Ethernet 的难点不是把功能写进产品页,而是在不同客户拓扑、不同流量模型、不同 NIC/DPU 和不同交换 ASIC 之间调成稳定系统。
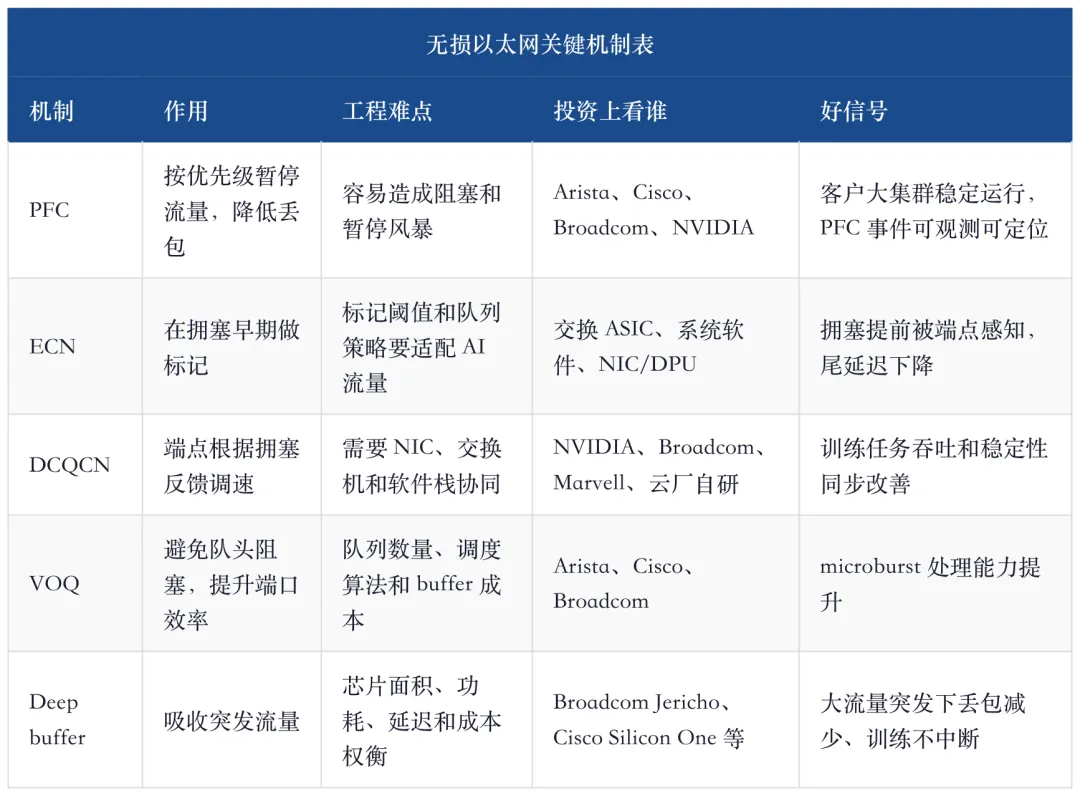
这张表也解释了为什么 AI Ethernet 的竞争不是普通企业交换机竞争。普通网络更看端口、管理和安全;AI 后端网络更看 lossless fabric、尾延迟和端点协同。对投资来说,能把这些能力做成客户可复制部署的公司,才有资格享受 AI 网络估值。
6、Packet spraying 与 adaptive routing:开放网络要处理“乱”和“堵”
AI 训练和推理的网络流量不是均匀的。大量小流、少数 elephant flow、同步通信和突发写入会造成链路热点。传统 ECMP 只按 hash 把流量分到路径,遇到 elephant flow 时容易出现某些路径拥塞、某些路径空闲。AI Ethernet 要提高可用带宽,就必须更积极地使用 packet spraying、adaptive routing 和端点重排序。
packet spraying 的好处,是把流量拆散到多条路径,提升链路利用率;问题是可能带来乱序。乱序会让端点重组、缓存、排序和拥塞控制更复杂。adaptive routing 的好处,是根据实时拥塞选择更优路径;问题是需要交换 ASIC、遥测和系统软件能更快感知网络状态。
这就是 NIC/DPU 的价值。端点如果不能处理乱序、重排、RDMA 语义和遥测反馈,交换网络再聪明也难以稳定。AI Ethernet 的真正系统边界,不在交换机端口,而在交换机、NIC/DPU、软件栈和客户调度系统之间。
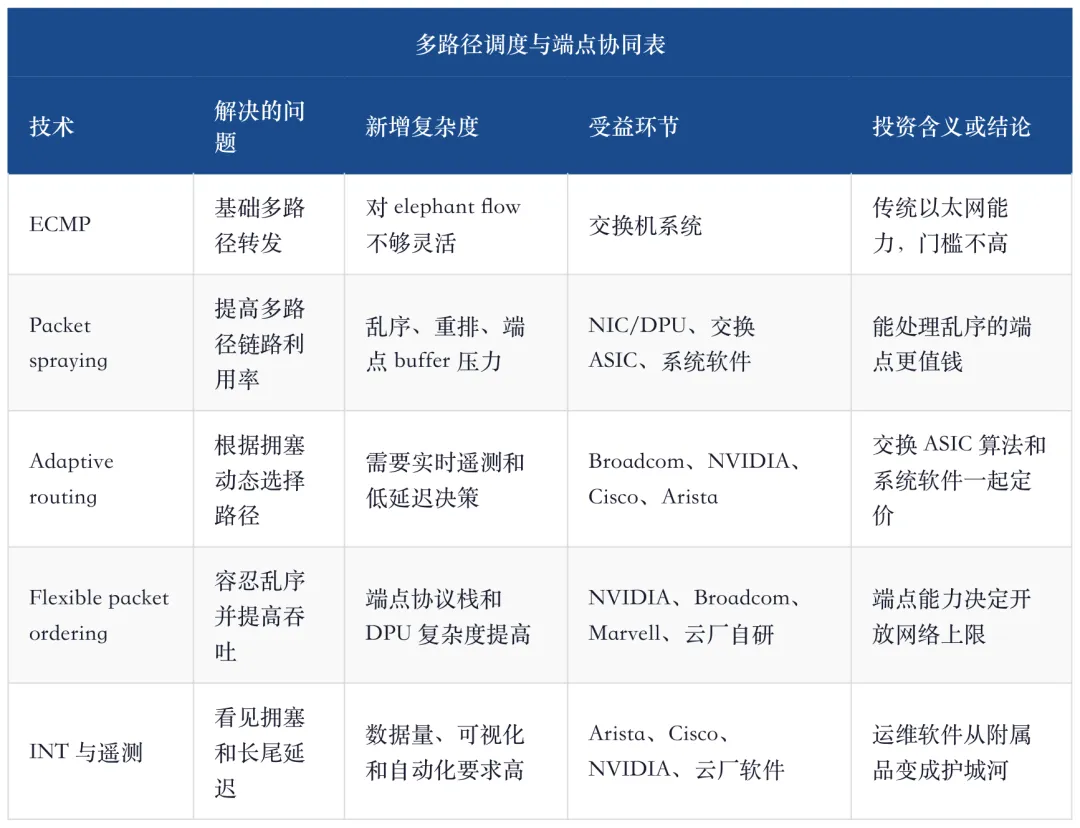
这也是为什么 AI Ethernet 的受益者不能只写 Arista 或 Cisco。系统厂验证的是客户部署,Broadcom/NVIDIA/Marvell 验证的是 silicon 和端点,Celestica/Accton 验证的是高端白盒交付。工程化网络是一组能力,不是一台盒子。
7、交换 ASIC:Tomahawk、Jericho、Spectrum、Silicon One、Teralynx 分工不同
交换 ASIC 是 AI Ethernet 的第一硬件入口。没有高容量、低延迟、高 radix 和成熟队列管理的交换芯片,系统厂很难把开放网络做成训练集群。J.P. Morgan 对数据中心以太网交换和 AI 数据中心交换的模型给出了需求斜率,Bernstein 则把 switch 和 connectivity/optics 都列为 AI 网络最大价值池之一。
但交换 ASIC 不能只按“谁的带宽最大”排序。Tomahawk 更偏高容量数据中心以太网,Jericho 更强调大规模 fabric 和深 buffer,NVIDIA Spectrum-X 结合自家 NIC/DPU 和软件栈,Cisco Silicon One 强在路由交换统一架构和系统自给,Marvell Teralynx/Prestera 更偏云厂白盒和特定平台机会。
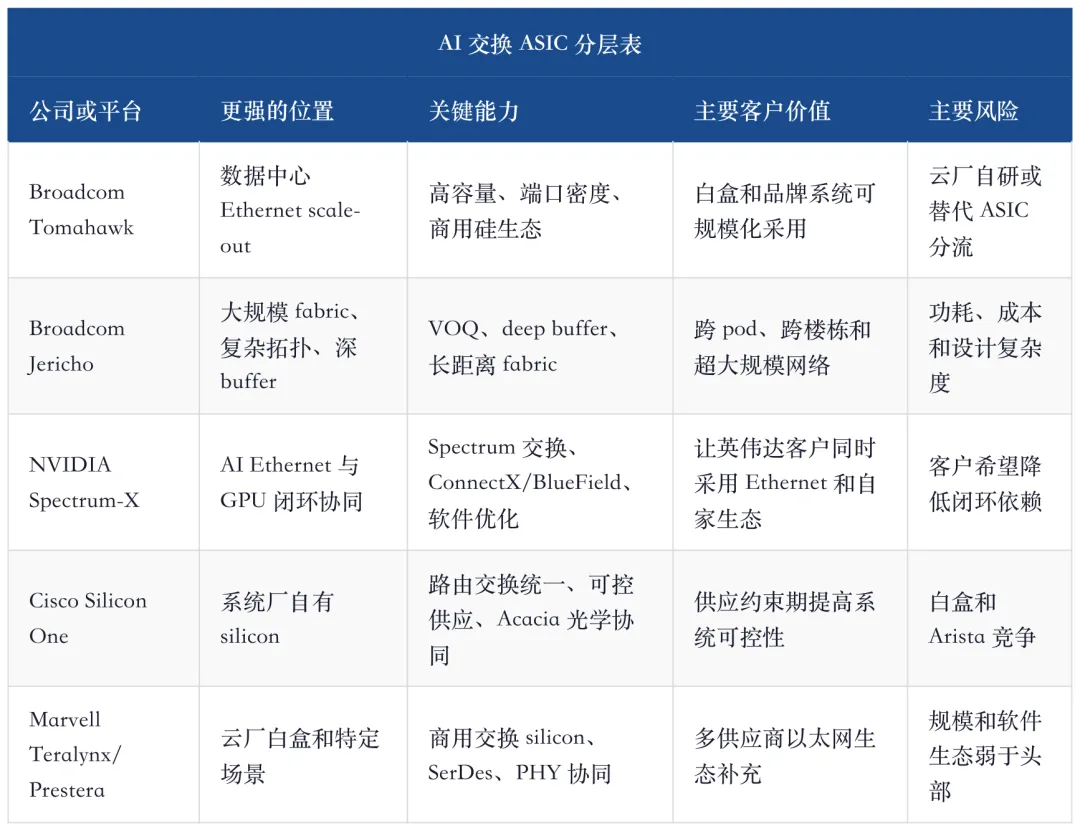
交换 ASIC 的投资结论是:Broadcom 是开放以太网最核心的商用 silicon 税收层,NVIDIA 是闭环延伸到 Ethernet 的系统税收层,Cisco 是品牌系统和自有 silicon 结合的再验证,Marvell 是弹性补充。Arista 不做交换 ASIC,但它把商用 silicon 和 EOS 结合成客户可运行系统,这是另一种控制权。
8、系统软件:AI Ethernet 的护城河不在 CLI,而在稳定扩容
AI Ethernet 要做到大规模部署,不能靠硬件堆料。客户需要的是网络从几千卡扩到几万卡时,配置、遥测、变更、故障定位、性能回归和容量规划都能被系统化管理。这里正是 Arista、Cisco、NVIDIA 和云厂自研网络团队的价值。
Arista 的 EOS 和 CloudVision 价值,在于把商用 silicon 变成可复制的云厂网络平台。高盛报告里,Arista 1Q26 收入 27.09 亿美元,产品收入同比增长 37%,AI Center 2026 年收入指引上调到 35 亿美元,采购承诺升至 89 亿美元。这些数字说明,客户不是只买便宜交换机,而是在买一套可持续扩容的网络平台。
Cisco 的价值则在另一个方向:传统网络客户基础、Silicon One、Acacia 光学和完整系统能力。高盛报告显示,Cisco F3Q26 网络收入 88 亿美元,同比增长 25%,产品订单同比增长 35%,FY2026 AI 超大规模客户订单展望上调至 90 亿美元。Cisco 的 AI 纯度不如 Arista,但订单体量说明传统系统厂仍然能拿到超大规模 AI 网络预算。
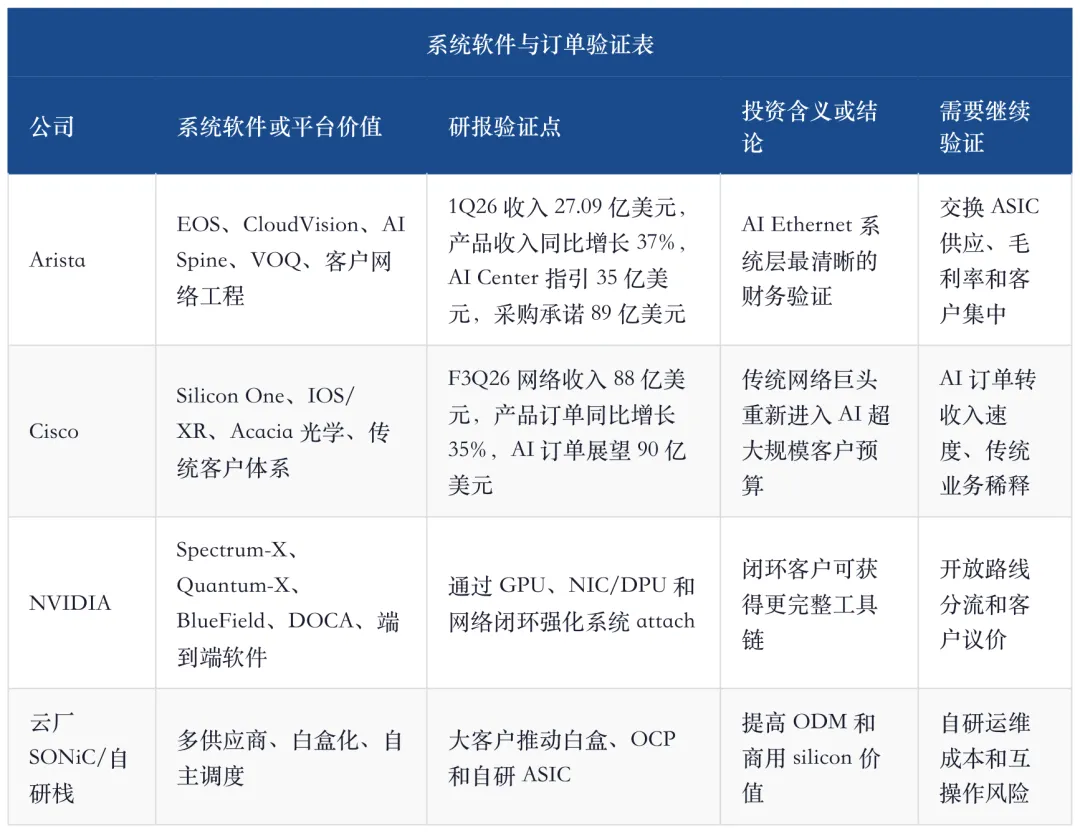
系统软件的本质是降低客户扩容成本。AI Ethernet 的开放性越强,组件越分散,软件和运维越值钱。开放网络不是不要平台,而是平台从硬件闭环变成系统软件和客户网络工程。
9、白盒不是低端代工:Celestica 与 Accton 证明交付层也有门槛
如果只看品牌系统,容易低估白盒交换机和 ODM 的变化。1.6T、CPO、OCS、液冷、高速 PCB、光模块兼容、固件验证、软件加载和多 ASIC 支持,都让白盒交换机从“按图制造”升级为“系统工程交付”。
Celestica 的 1Q26 报告验证了这个方向。它的重点不是单季收入好看,而是 CCS 业务、全年指引和 1.6T CPO 交换项目同时指向高端网络交付能力。这说明 AI 网络交付不是低价值尾部环节,而是高端项目能否量产的闸门。
Accton 的 UBS 覆盖报告进一步把白盒价值说清楚。它不是普通装配公司,而是美国头部云厂数据中心交换机、AI 加速卡、switch tray 和未来 L11 rack 的系统工程伙伴。更关键的是,白盒交换市场份额高度集中,能够跨多 ASIC 平台做高速设计、热管理、测试和软件加载的 ODM 并不多。
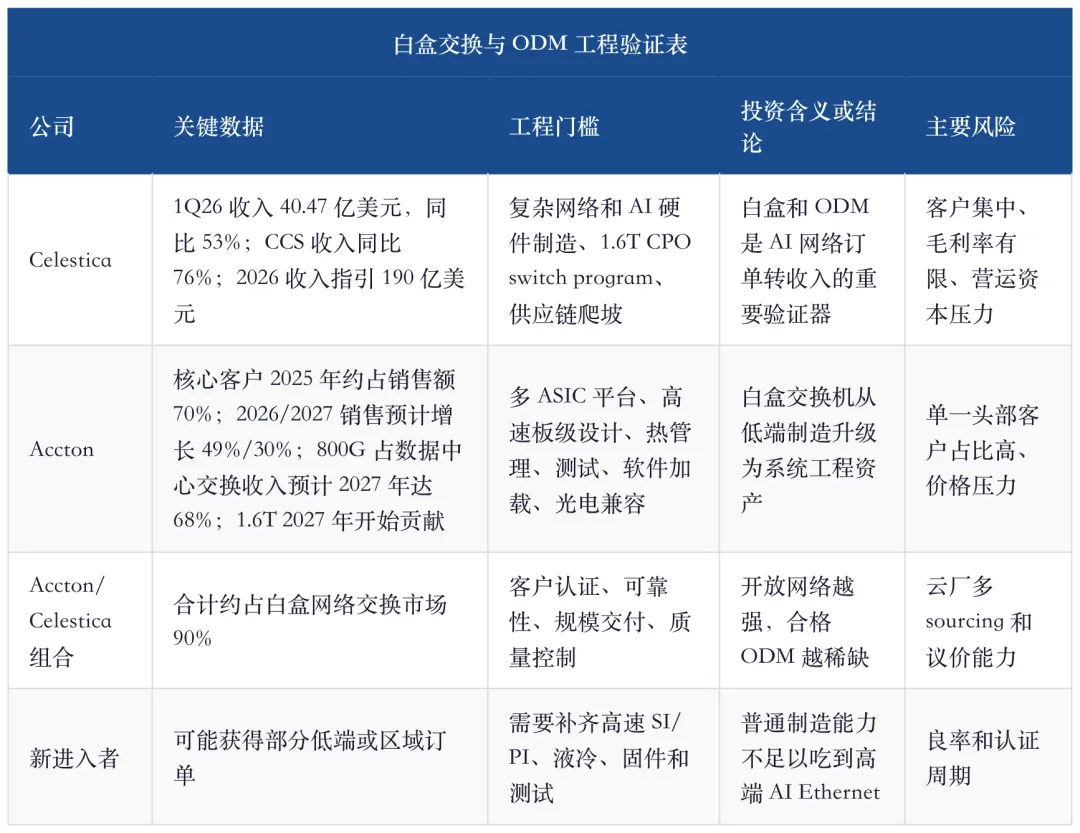
这里的结论很直接:白盒不是 AI Ethernet 的低端替代,而是开放网络的一部分。云厂要降低闭环依赖,就必须有能承接商用 ASIC、光电链路和自研软件栈的系统交付伙伴。Celestica 和 Accton 的价值就在这里。
10、客户路线:不是所有云厂都会用同一张网络图
AI Ethernet 的推进速度,最终由客户路线决定。Microsoft/OpenAI、Meta、Google、AWS、Oracle、xAI、Anthropic、中国主要云厂的网络选择不会完全一样。训练、推理、自研 ASIC、供应链策略、电力约束、软件团队能力都会影响路线。
Meta 是开放网络和 custom silicon 最强的代表之一。高盛对 Broadcom 与 Meta 合作的报告显示,双方是多年多代战略合作,支持 MTIA custom compute chips,供应链计划延伸到 2029 年,首阶段承诺超过 1GW,并覆盖 scale-up、scale-out、scale-across 网络需求。这类客户会同时拉动 custom ASIC、Ethernet fabric、系统软件和白盒交付。
AWS 更像自研系统工程公司。Trainium、Nitro/NIC、以太网交换、白盒 ODM、系统软件和大规模云服务合在一套系统里。Accton 的报告把 Trainium 2/3、AI accelerator cards、switch tray 和 L11 rack integration 放在同一条价值链里,这说明自研 ASIC 客户会把网络、加速卡和系统集成一起外溢给合格供应链。
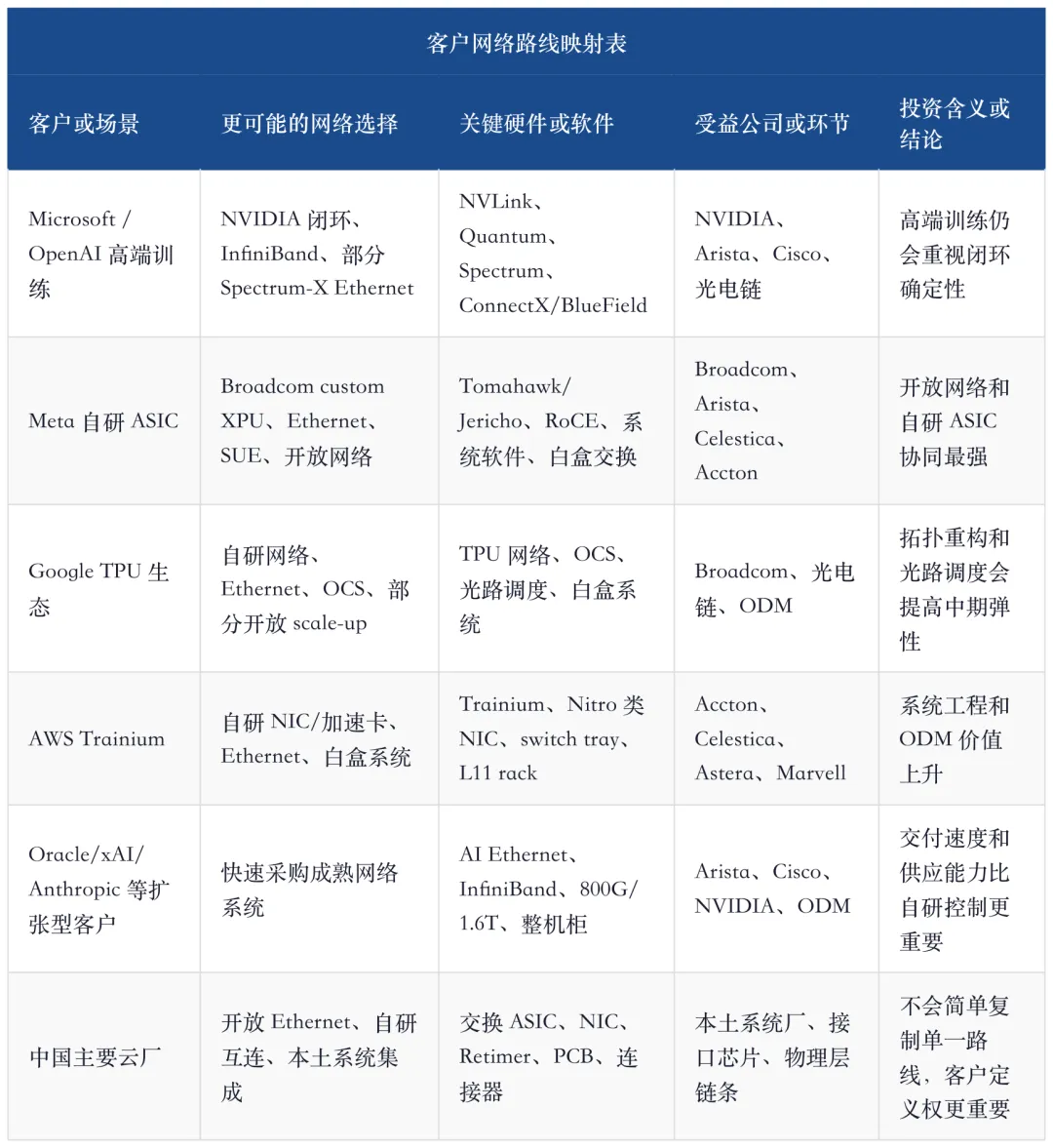
这张表解释了为什么不能用一个答案概括 AI Ethernet。高端训练闭环仍然有强确定性,自研 ASIC 客户会推动开放网络,快速扩容客户会先买成熟系统,中国市场则更强调开放和可控供应。公司排序必须放在客户路线里看。
11、财务验证:这篇是工程分析,但不能脱离订单和利润表
工程化文章如果没有财务验证,容易变成技术百科。把这组研报放在一起看,AI Ethernet 工程化已经有足够的订单和收入信号。
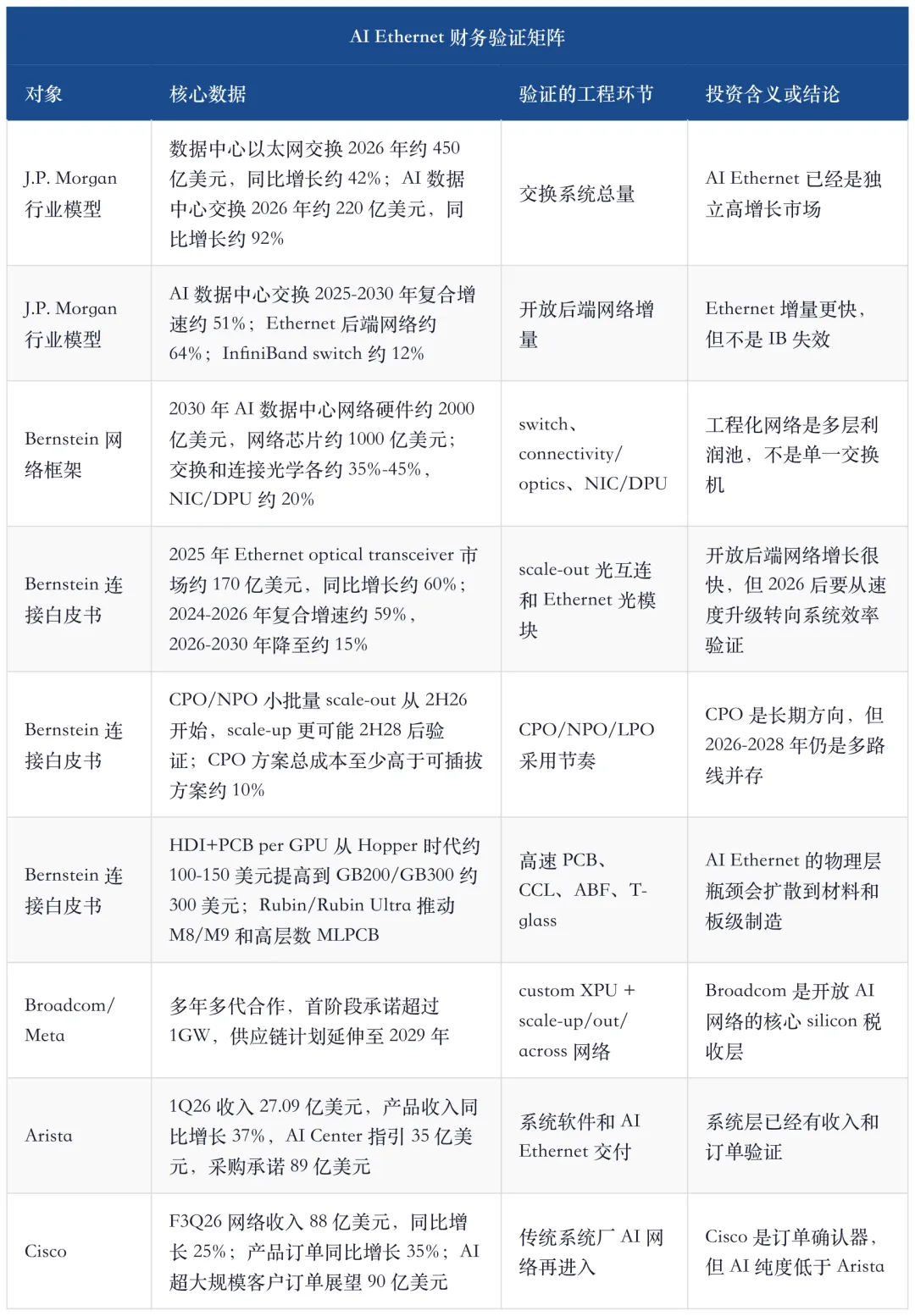
这张表把文章的投资方向压得更清楚:工程能力已经开始被财务验证。不是所有网络设备都能重估,但具备交换 silicon、系统软件、白盒工程、光电兼容和客户认证的环节,会获得更高质量的收入。
12、公司排序:先按控制层级,不按热度排序
AI Ethernet 工程化的公司排序,不能只按短期涨幅或订单标题。更合理的排序方法是三层:架构和 silicon 控制权、系统软件和客户平台、系统交付和白盒工程。
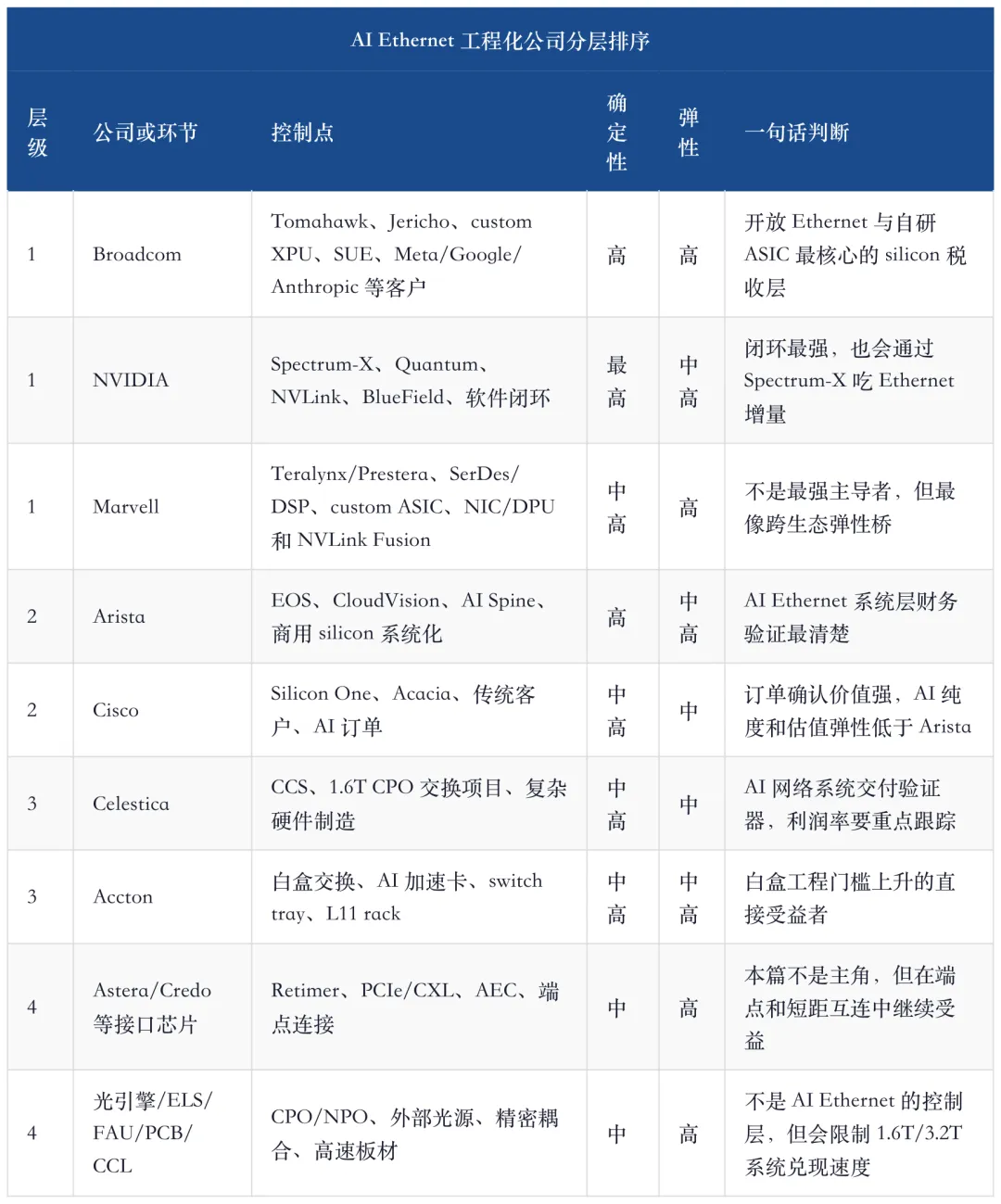
如果只买确定性,NVIDIA、Broadcom、Arista 是主线;如果买开放网络弹性,Broadcom、Marvell、Accton 更值得跟踪;如果买订单兑现,Arista、Cisco、Celestica 是更直接的财务验证;如果买工程瓶颈扩散,Astera、Credo、PCB/CCL、连接器和光电链要放在相关分支里看。
13、证伪清单:什么时候说明 AI Ethernet 工程化逻辑不成立
AI Ethernet 的方向很强,但最怕把开放生态写成自动胜利。开放网络要过四道证伪门:性能、运维、供应链和利润率。
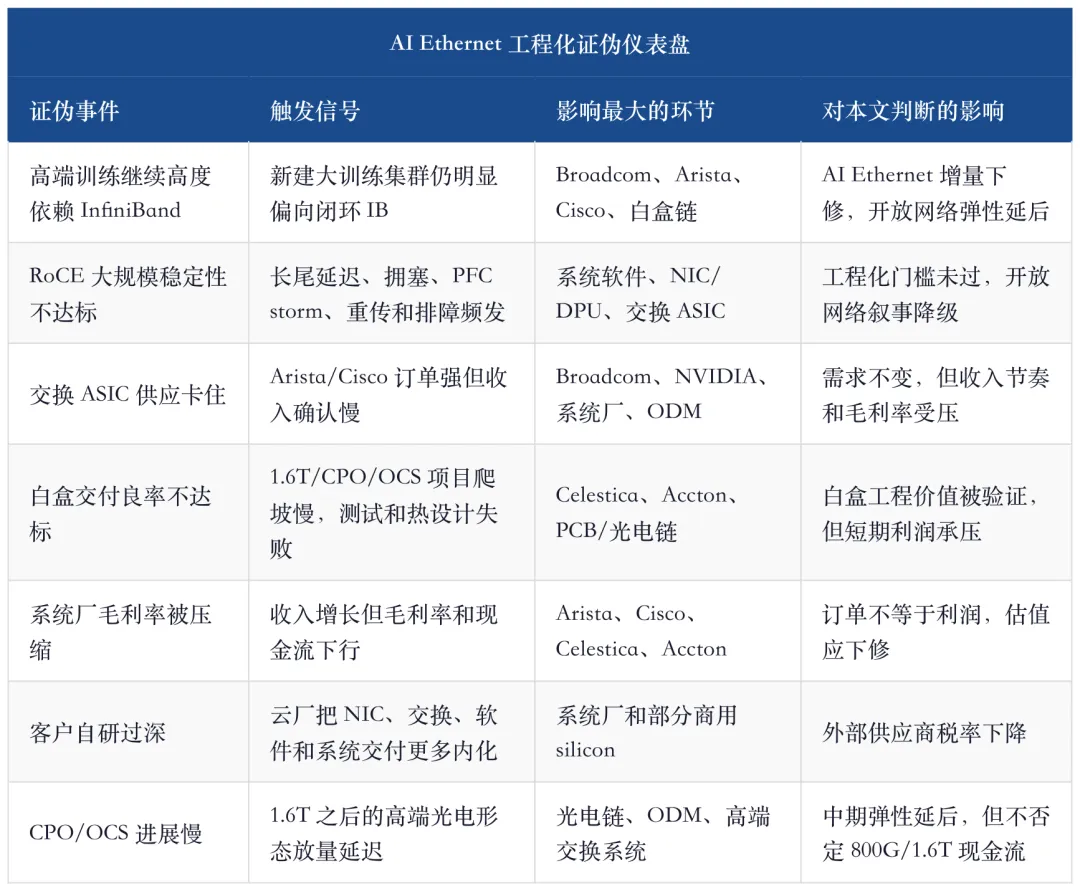
这张表也给出跟踪方法。后续不能只看“AI 订单上修”,更要看订单是否转收入、收入是否守住毛利率、网络是否稳定运行、客户是否继续扩大开放以太网部署。
14、季度跟踪表:只看订单不够,要看工程指标和财务指标一起改善
AI Ethernet 的季度跟踪,要把工程指标和财务指标放在同一张表里。只有两者同时改善,才能证明开放网络不是主题行情,而是结构性利润池。
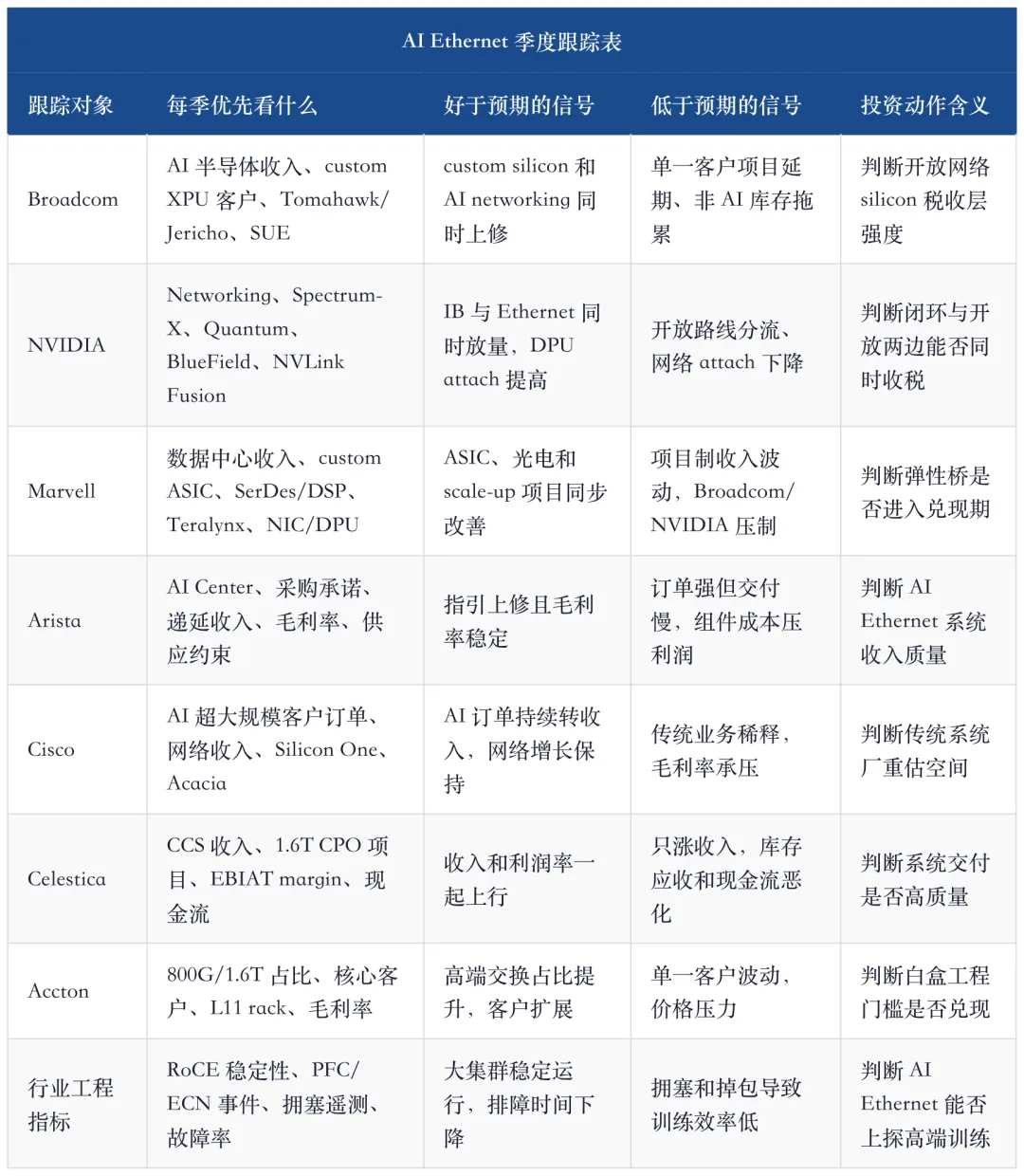
这个跟踪表的核心,是把“技术能不能跑”和“财务能不能兑现”绑在一起。只讲工程,不看收入,是技术爱好;只看订单,不看稳定性,是财务误读。AI Ethernet 的投资价值恰好在两者交叉处。
15、最终判断:开放网络的赢家,是能把复杂度做成平台的人
AI Ethernet 不是低配 InfiniBand,也不是所有以太网交换机公司的共同红利。它是一条更开放、更复杂、更考验系统工程的 AI 网络路线。
短期看,InfiniBand 和 NVIDIA 闭环仍然会在高端训练里保持强确定性。客户愿意为成熟闭环付溢价,因为训练稳定性和排障成本比单个端口价格更重要。这个判断不能因为 AI Ethernet 增长快就被推翻。
中期看,AI Ethernet 的增量斜率更高。原因不是它天然性能更强,而是云厂需要开放生态、多供应商选择、自研 ASIC 适配、白盒交付和总拥有成本优化。这个趋势会继续抬高 Broadcom、Arista、Cisco、Celestica、Accton、Marvell 以及 NIC/DPU、光电和接口芯片的价值。
长期看,真正穿越周期的公司不是“支持 Ethernet”的公司,而是能把开放网络复杂度做成平台的人。Broadcom 用 custom XPU、Tomahawk/Jericho 和客户网络协同收 silicon 税;NVIDIA 用 GPU、NIC/DPU、Spectrum-X、InfiniBand 和软件闭环收系统税;Arista 用 EOS 和客户网络工程收运维税;Cisco 用 Silicon One、Acacia 和传统客户体系收订单确认税;Celestica 和 Accton 用高端白盒工程收交付税。
连接白皮书补上的关键点,是这套平台利润最终还要落到物理链路。CPO/NPO/LPO、铜互连、CPC、OCS、PCB/CCL/ABF 和高端材料不是旁支,而是决定开放网络能不能从 800G、1.6T 继续走向 3.2T 的硬约束。也正因为如此,AI Ethernet 的赢家不只要会转包,还要会管理光电、板级、热、测试和运维的跨层复杂度。
所以,第四篇的结论可以压成一句话:AI Ethernet 的投资主线不是“以太网替代 InfiniBand”,而是开放网络从协议、芯片、系统软件、白盒工程到客户认证的工程化升级。谁能让万卡集群在开放网络里少拥塞、少重传、少排障、少空转,谁就能把端口价格变成平台利润。
数据口径与来源
本文主体判断来自多篇 2026 年 AI 数据中心网络、硬件与网络设备、半导体和系统制造研报的交叉验证,主要包括 Bernstein 关于 AI 数据中心网络分层与网络硬件价值池的研究,Bernstein 2026 年 5 月《Artificial Intelligence: Inside the War for AI Data Center Connectivity》连接白皮书,J.P. Morgan 关于硬件与网络市场模型、AI 数据中心交换、以太网后端网络和端口升级的模型,Goldman Sachs 关于 Broadcom/Meta、Arista、Cisco、Celestica 的公司研究,Citi 关于 Broadcom AI 半导体与网络平台的研究,以及 UBS 关于 Accton 白盒交换机、800G/1.6T 和系统工程的覆盖研究。
文中财务数据、市场规模、增长率、客户合作和目标价等均按对应研报或公司披露口径整理;目标价和评级仅作为机构观点背景,不构成当前估值结论。本文不进行实时股价判断,不构成任何证券买卖建议。后续判断可能随客户资本开支、技术路线、供应链、毛利率、订单确认和宏观环境变化而调整。