 夜雨聆风
夜雨聆风





面试官当场怼我:5000份文档切一切就叫知识库?这6个坑你一个都没躲过
面试官当场怼我:5000份文档切一切就叫知识库?这6个坑你一个都没躲过
❝
别再把5000份文档扔进去就叫知识库了,真正的坑你一个都没踩过
上周一个学员跟我吐槽,说他面阿里大厂大模型算法岗,简历上写着“搭建了基于RAG的企业知识问答系统”。
面试官只问了三个问题:
-
你们PDF多栏排版怎么处理的? -
表格结构有没有丢? -
切分的时候把完整流程切断了怎么办?
学员说:“我用PyPDF提取文本,按512token切分的。”
面试官直接笑了:“你这不叫知识库,叫文档粉碎机。”
场面一度非常尴尬。
一、为什么你的RAG效果上不去?90%的问题出在离线阶段
很多人做RAG,模型选最新的,检索搞混合的,Rerank上了仨版本。但用户一问“这个产品的免赔额是多少”,系统不是答非所问就是直接摆烂。
问题不在模型,在你扔进去的那堆“知识库”——PDF解析成乱码,表格变成流水账,完整的理赔流程被一刀切成两半。
离线解析决定了RAG的上限,在线检索只是在这个上限里挣扎。
下面这张图是我们在一个真实金融项目中跑通的离线解析全流程,每一步都踩过坑,也填过坑。
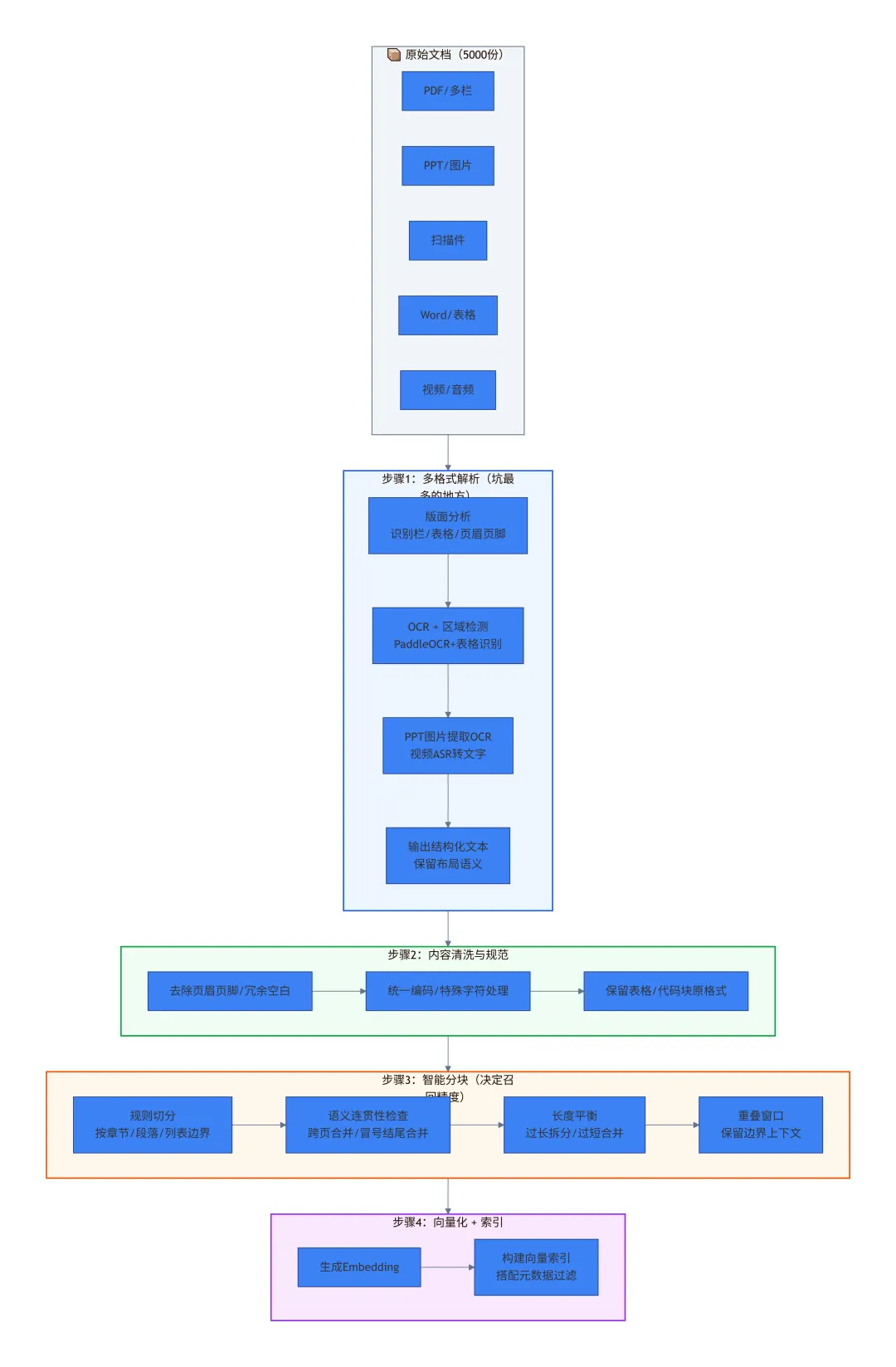
❝
视觉提示:浅色背景,不同阶段用不同色块区分,方便面试时手绘给面试官看
二、PDF多栏排版:PyPDF2根本不懂什么叫“栏”
实战中最常见的翻车现场。
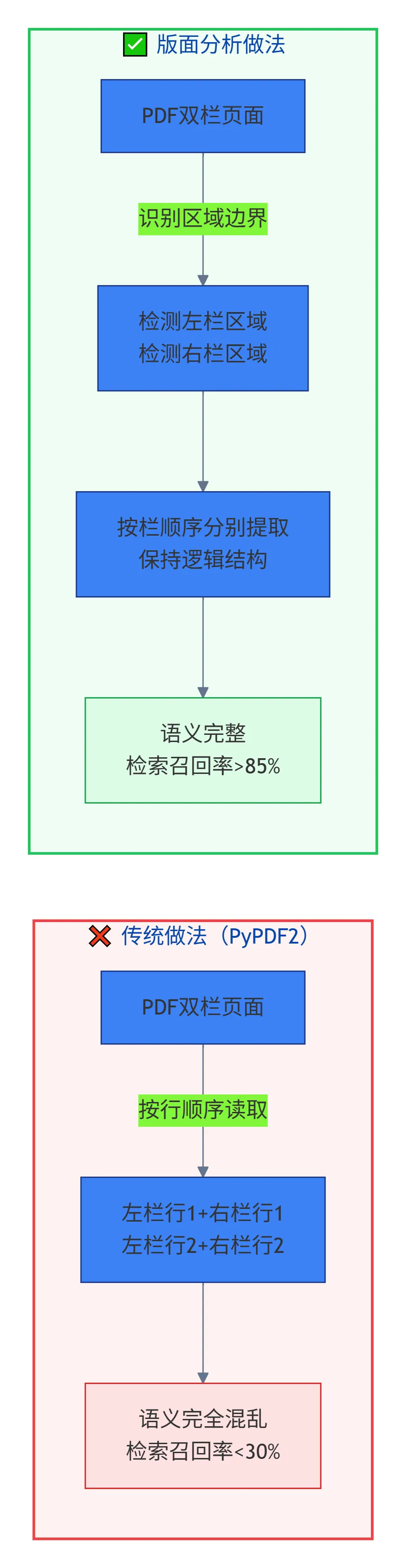
保险公司的理赔指南,很多是双栏排版——左边写步骤,右边写具体要求。PyPDF2按行从上往下读,结果左栏第一行和右栏第一行拼到一起:
❝
“理赔流程申请人需提交以下材料:事故发生后,尽快联系保险公司-身份证复印件”
用户问“理赔需要什么材料”,检索系统根本找不到“材料”这个词,因为它在乱码里。
面试官想听的解决方案:
用版面分析技术,先识别文档的物理布局——哪些区域是左栏、哪些是右栏、哪些是表格。推荐 MinerU 或 Marker,它们内置了Layout Analysis,能按逻辑结构提取内容。
下面这张图展示了版面分析前后的差别:
三、表格和代码块:OCR的“粉碎机”模式
扫描版PDF必须走OCR,但普通OCR对结构化内容的还原能力约等于零。
一份产品对比表,原始是三列:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
OCR处理后变成一行:险种 最高赔付 免赔额 A款 500000 5000 B款 300000 3000
用户问“A款的免赔额”,检索系统要从这行流水账里找答案,基本靠玄学。
面试官想听的解决方案:
对表格区域做专门的表格识别,按单元格顺序输出并保留结构化格式。整体用 PaddleOCR 配合版面分析,先检测区域类型(文字/表格/代码/图片),再分别用针对性策略处理。
代码块也是同理——保留缩进、括号、关键字。
四、分块策略:为什么512token固定切分是“文档粉碎机”
很多人直接 split_text(text, chunk_size=512),这是最偷懒的做法。问题在于它完全不管语义边界。
一段完整的理赔流程可能1000字,刚好在“交通事故需提供交警事故”这里被切成两块。用户问“重大疾病理赔需要什么材料”,这个chunk里根本没有完整信息。
面试官想听的解决方案:三层切分 + 重叠窗口
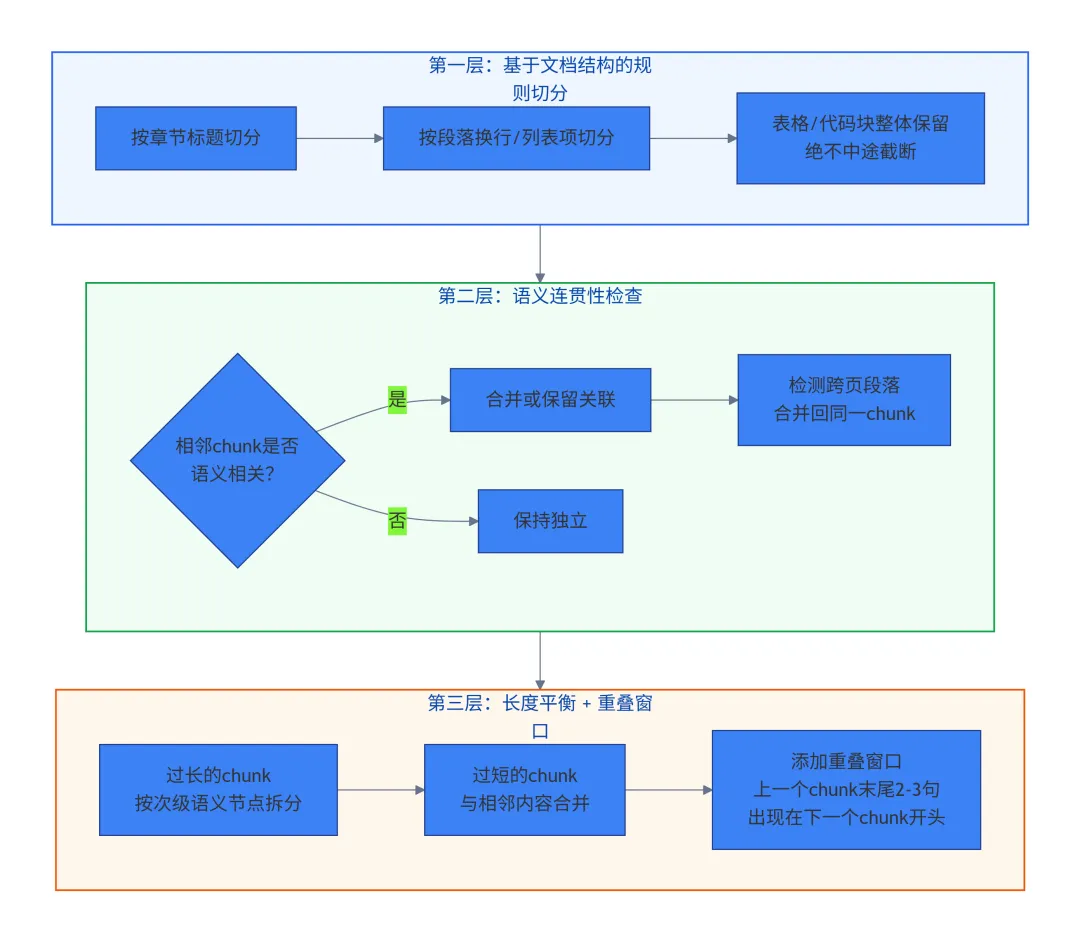
重叠窗口的示意图:
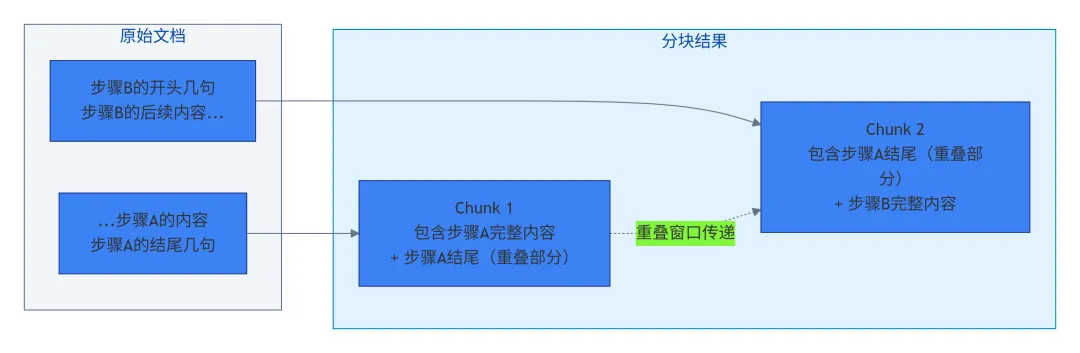
五、隐藏大招:层级标签和元数据
分块做完很多人就直接入库了,漏掉了一个极其重要的信息——文档的层级结构。
比如“差旅报销上限5000元”这段内容,如果不记录它属于“报销政策 > 差旅报销”,那用户搜“差旅报销”的时候,纯靠向量匹配可能找不到这段。
面试官想听的方案:
在解析阶段维护一个层级栈,检测到“1 总则”是一级标题,“1.1 范围”是二级标题,就把当前chunk标记为 总则 > 范围。检索时,这些标题词也会参与索引匹配。
同时打上三类元数据:
|
|
|
|
|---|---|---|
|
|
报销政策 > 差旅报销 |
|
|
|
表格
代码块 / 政策条例 |
|
|
|
文档名
页码 / 幻灯片编号 |
|
有了这些元数据,在线检索就可以做精准过滤。比如用户问“昨天发布的报销制度有什么变化”,系统可以先用发布时间过滤,大幅缩小候选范围。
六、模块联动:离线质量如何影响全链路
很多人把离线解析和在线检索当成两件事,实际上它们是强耦合的。
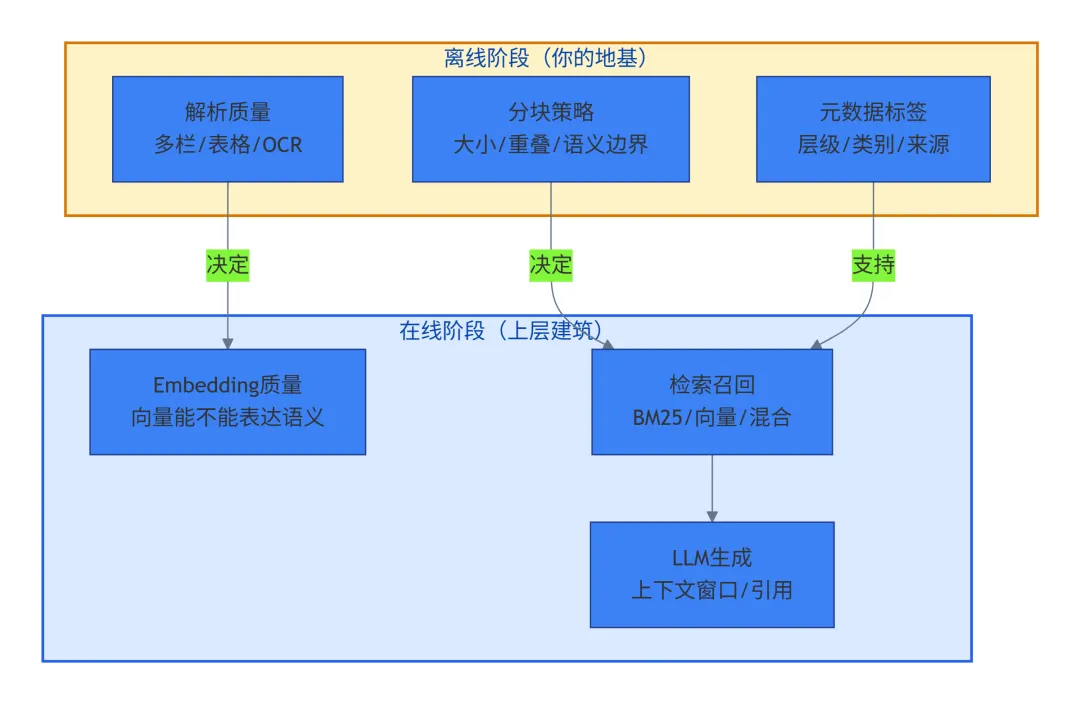
三个关键联动关系:
-
chunk大小要配合LLM上下文窗口:块太大,一个chunk占几千token,LLM一次只能放两三个,覆盖面窄。块太小,语义残缺,需要拼凑更多片段。需要通过实验找到平衡点。
-
元数据质量决定检索过滤能力:离线偷懒没打标签,在线想过滤都没法过滤。
-
解析质量直接影响Embedding质量:OCR把表格解析成乱码,再好的Embedding模型也救不回来。
七、面试官问“离线解析怎么做的”,你就按这个框架讲
第一步:先讲挑战(体现难度)
❝
我们项目有5000份多格式文档,包含PDF(多栏排版、扫描版)、PPT、纯文本甚至视频。主要挑战是多格式统一解析、OCR对表格和代码的还原、以及分块时保持语义完整性。
第二步:讲方案(体现技术深度)
❝
解析层面:PDF用版面分析处理多栏和表格;扫描件用PaddleOCR配合区域检测;PPT对图片元素做OCR补充提取;视频走ASR转字幕。
分块层面:采用规则+语义融合的三层切分策略,配合chunk overlap保持连续性。
元数据层面:给每个chunk打上层级标签、内容类型和来源元数据,支持在线阶段的精准过滤。
第三步:讲效果和联动(体现系统思维)
❝
chunk大小通过实验配合LLM上下文窗口调优,元数据标签在检索阶段支持按时间、来源、类型等维度过滤,整体提升了召回的准确率。我们用解析失败率、平均chunk长度等指标监控离线流程质量,持续迭代优化。
写在最后
RAG系统效果不好,别急着换模型、调参数。
先回去看看你的知识库:PDF是不是解析成了乱码?表格是不是变成了一行流水账?完整的流程是不是被一刀切断了?
离线解析是RAG的地基,地基打不好,上面花再多钱也是白搭。
面试的时候,能把这些坑和解决方案讲清楚的,才是真正做过项目的人。
如果觉得这篇文章对你有帮助,欢迎转发给你的朋友。面经这种东西,一个人看不如一群人看。
