 夜雨聆风
夜雨聆风





OpenClaw多Agent协作实战:从原理到智能客服案例
多Agent协作正在成为AI应用的主流架构。本文以OpenClaw框架为例,深入解析其多Agent协作的核心机制,并通过一个智能客服自动化工件的完整案例,帮助读者掌握这一前沿技术的实战技巧。
一、为什么需要多Agent协作?
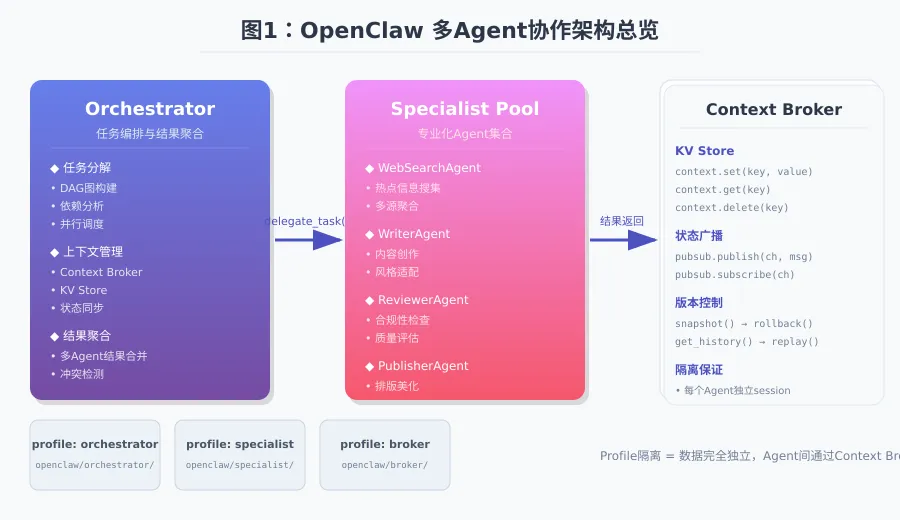
在复杂任务中,单一AI Agent的能力有上限。多Agent协作通过将任务分解给专业化Agent,实现:
-
能力专业化:每个Agent专注单一领域,成为该领域的专家 -
任务并行化:多个独立Agent同时工作,大幅提升吞吐量 -
流程可编排:通过有向无环图(DAG)定义Agent间的依赖关系 -
状态可追溯:每个节点可单独监控、干预和回滚
二、OpenClaw核心架构:一张图读懂协作模型
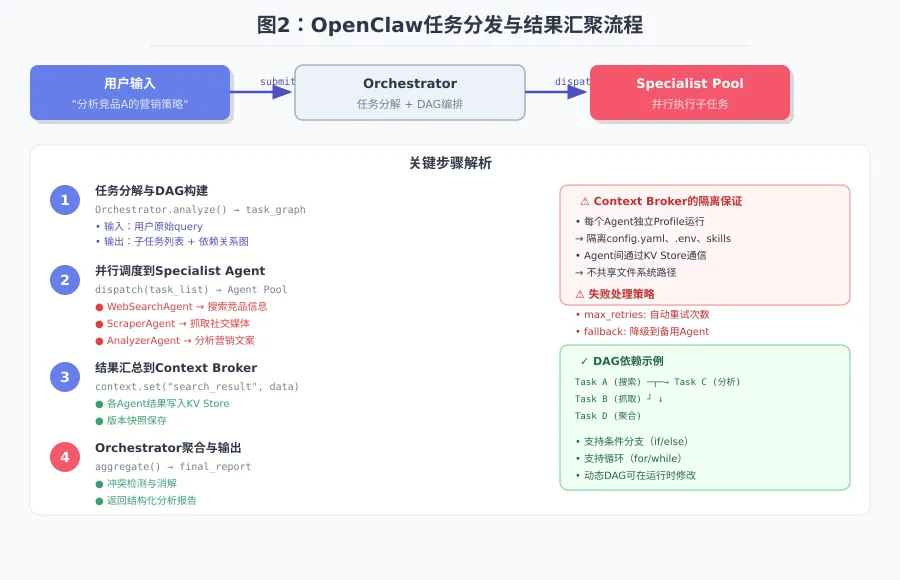
OpenClaw的多Agent协作基于任务分发 + 结果汇总的模型:
-
Orchestrator(编排器):负责任务分解、子Agent调度、结果聚合 -
Specialist(专家Agent):专注执行特定类型任务(搜索/写作/审核等) -
Context Broker(上下文经纪人):管理Agent间的共享上下文,防止信息孤岛
三、OpenClaw的任务分发机制
3.1 任务创建与分发
当用户提交任务时,Orchestrator执行以下步骤:
┌─────────────────────────────────────────────────────────┐│ 用户输入:"帮我分析竞品A的营销策略" │└─────────────────────────┬───────────────────────────────┘ ▼┌─────────────────────────────────────────────────────────┐│ Orchestrator: 任务分解 ││ ├─ 子任务1: 搜索竞品A的基本信息 ││ ├─ 子任务2: 抓取竞品A的社交媒体内容 ││ └─ 子任务3: 分析竞品A的营销文案风格 │└─────────────────────────┬───────────────────────────────┘ ▼┌─────────────────────────────────────────────────────────┐│ Specialist Agent Pool ││ ├─ WebSearchAgent → 子任务1 ││ ├─ ScraperAgent → 子任务2 ││ └─ AnalyzerAgent → 子任务3 │└─────────────────────────┬───────────────────────────────┘ ▼┌─────────────────────────────────────────────────────────┐│ 结果聚合 → 用户可见的完整分析报告 │└─────────────────────────────────────────────────────────┘3.2 结果汇总与上下文传递
# OpenClaw 伪代码示例result = await orchestrator.run( task="分析竞品A的营销策略", agents=[ web_search_agent, scraper_agent, analyzer_agent ], context={"competitor_name": "竞品A","analysis_depth": "comprehensive" })四、案例:智能客服多Agent流水线
场景描述
我们构建一个智能客服助手,包含以下专业Agent:
|
|
|
|
|
|---|---|---|---|
NLUAgent |
|
|
|
KBRetrievalAgent |
|
|
|
ResponseAgent |
|
|
|
SentimentAgent |
|
|
|
流水线架构图
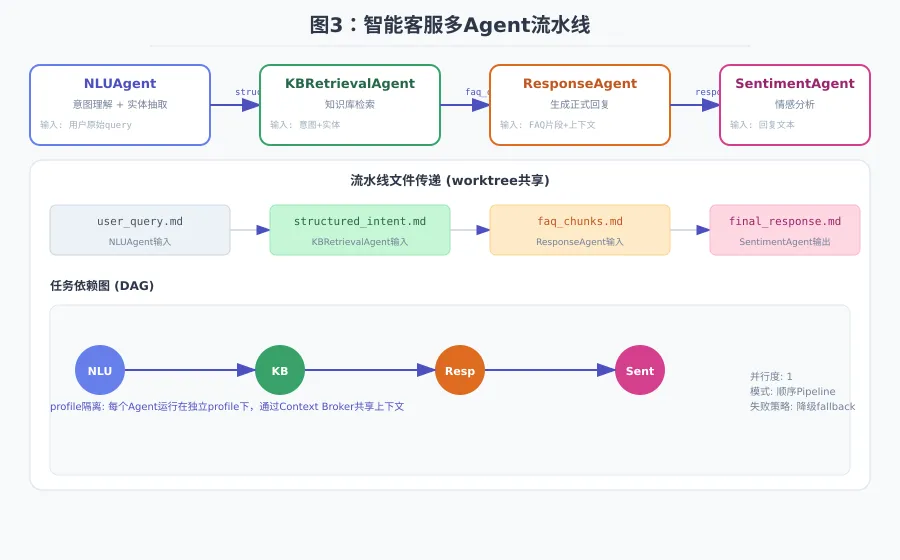
每个Agent接收上一节点的输出,经过自己的专业处理后传递给下一节点。
工作流文件传递(worktree共享)
worktree/├── user_query.md ← NLUAgent 输入├── structured_intent.md ← NLUAgent 输出,KBRetrievalAgent 输入├── faq_chunks.md ← KBRetrievalAgent 输出,ResponseAgent 输入├── response_draft.md ← ResponseAgent 输出,SentimentAgent 输入└── final_response.md ← SentimentAgent 输出,最终回复五、四种隔离方案详解
方案1:Profile隔离(推荐)
原理:每个Agent运行在独立Profile下,数据完全隔离。
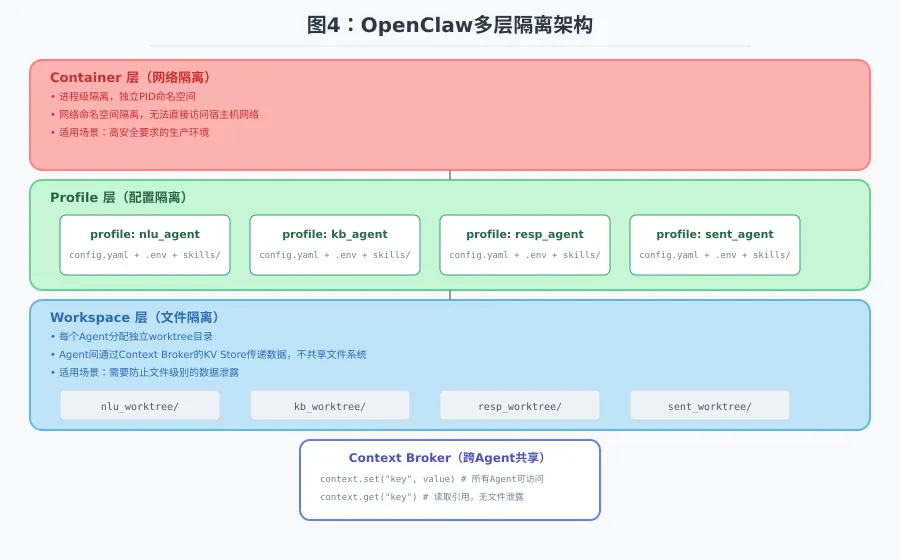
~/.hermes/├── config.yaml # 默认profile(Orchestrator)└── profiles/ ├── nlu_agent/ │ ├── config.yaml # 独立NLU配置 │ ├── .env # 独立API Keys │ └── skills/ # 独立技能 ├── kb_agent/ │ ├── config.yaml │ ├── .env │ └── skills/ ├── response_agent/ │ ├── config.yaml │ ├── .env │ └── skills/ └── sentiment_agent/ ├── config.yaml ├── .env └── skills/适用场景:不同Agent需要完全独立的配置、工具集和会话历史。
方案2:Workspace隔离
通过 --workspace 参数为每个Agent分配独立工作目录。
hermes kanban create "NLU处理" \ --assignee nlu_agent \ --workspace nlu_worktree适用场景:需要隔离文件系统访问权限。
方案3:Container隔离
通过Docker容器运行Agent,实现进程级隔离。
# docker-compose.ymlservices:nlu_agent:image:openclaw-nlu:latestcontainer_name:nlu_agentkb_agent:image:openclaw-kb:latestcontainer_name:kb_agent适用场景:对安全性要求极高,需要网络和进程完全隔离。
方案4:混合隔离策略
生产环境推荐方案:Profile + Workspace + Container 三层隔离。
Container层(网络隔离) └─ Profile层(配置隔离) └─ Workspace层(文件隔离)六、OpenClaw与CrewAI/MCP的对比
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
七、常见问题与解决方案
Q1:Agent间如何保证上下文一致性?
A:使用Context Broker统一管理。它维护一个共享的KV Store,所有Agent通过它传递信息,避免直接点对点通信导致的耦合。
context_broker.set("current_intent", intent_data)# 任何Agent可通过以下方式读取intent_data = context_broker.get("current_intent")Q2:某个Agent失败怎么办?
A:OpenClaw支持两种策略:
-
自动重试:配置 max_retries和retry_delay -
降级fallback:指定备用Agent处理失败任务
agents=[ WebSearchAgent(max_retries=3, fallback=BackupSearchAgent), ScraperAgent(max_retries=2),]Q3:如何监控整个流水线的状态?
A:使用OpenClaw的Dashboard:
openclaw dashboard --port 8080实时查看每个Agent的:
-
输入/输出数据 -
执行时间 -
错误日志 -
资源消耗
八、总结
OpenClaw的多Agent协作通过专业分工 + 灵活编排 + 多层隔离,为复杂AI应用的工程化落地提供了可靠方案。结合Profile隔离机制,可以实现:
-
开发态:快速迭代,单Agent独立调试 -
生产态:安全隔离,多Agent协同作业
推荐实践:
-
先用Profile隔离快速验证单Agent能力 -
再用Workspace隔离测试多Agent协作 -
最终用Container隔离保障生产安全