 夜雨聆风
夜雨聆风





构建国产GPU软件生态,助力中国AI产业高质量发展
李世保
摘要
面对美对华科技封锁持续升级与英伟达CUDA生态的垄断格局,构建自主可控的国产GPU软件生态已成为国家战略选择的必然要求。本文从产业现状、技术路径、战略价值三个维度,系统论证国产GPU软件栈统一到ROCm开源生态的必要性与可行性。文章指出,当前国产GPU产业面临“各自为战”导致的生态碎片化危机,重复建设与恶性竞争正在消耗宝贵的创新资源。统一采用ROCm开源技术栈,借鉴RISC-V的成功经验,通过组建设立“开放计算基金会”,是实现国产GPU从“可用”走向“好用”的战略突破口。本文引用郑纬民、孙凝晖、李国杰等院士关于统一开源生态建设的重要观点,深入阐述统一软件生态对AI人才培养、科技创新和产业发展的巨大价值,并提出具体的实施路径与政策建议。
关键词:国产GPU;软件生态;ROCm;开源开放;人工智能;人才培养;科技创新;产业发展
一、引言
人工智能正以前所未有的速度重塑全球经济格局与国际竞争格局。作为AI算力的核心载体,GPU(图形处理器)不仅是硬件产品,更是整个智能计算生态的基石。然而,我国GPU产业正面临双重困境:一是外部技术封锁持续升级,英伟达CUDA生态形成事实垄断;二是国内厂商“各自为战”,软件栈互不兼容,生态碎片化问题日益严重。
中国工程院院士郑纬民深刻指出:“在某种程度上,生态自立比算力自主和算法自强更重要。因为生态自立,是让国产平台从‘能跑’到‘好用’‘愿意用’,降低开发者门槛。”这一判断直指问题的核心——没有统一的软件生态,再先进的硬件也只能是“无魂之芯”。
本文旨在回答一个关乎中国AI产业前途的关键问题:如何以最低成本、最高效率构建国产GPU的统一软件生态?答案是——全面拥抱开源,统一到ROCm技术栈,通过组建“开放计算基金会”实现产业合力突围。
二、国家战略与政策背景
随着生成式人工智能的爆发,算力已成为衡量国家综合竞争力的核心指标。《“十四五”数字经济发展规划》与“东数西算”工程明确提出了构建自主可控算力体系的要求。然而,2022年以来,美国通过一系列出口管制法规,严格限制中国获取高端GPU芯片及相关的设计工具与配套软件。
在硬件制造工艺受限的背景下,软件生态成为决定算力自主化的“胜负手”。国务院及工信部多次发文强调,信创工程要从“可用”迈向“好用”,关键在于生态建设。当前,国家明确要求新质生产力的发展必须建立在自主可靠的算力底座之上。这种政策导向意味着,GPU软件栈的统一不仅仅是企业间的商业协作,而是关系到国家数据主权与产业安全的国家战略任务。
三、国产GPU生态困局:碎片化与内卷
3.1 “万卡林立”的碎片化危机
当前英伟达CUDA生态垄断全球80%以上AI算力市场,导致国产GPU的生态发展受限,在软件适配,应用迁移方面有众多困难。这就意味着一旦英伟达后续供应出现问题,采用英伟达 GPU的80%以上的AI企业在转向国产GPU时都将面临“适配成本高、迁移风险大”的瓶颈。
同时国内数十家GPU设计都推出了各自不同的编程接口与软件栈:海光的DCU基于ROCm生态,摩尔线程推出MUSA架构,壁仞开发BIRENSUPA,燧原有TopsRider……这种“百花齐放”的表象下,是国产GPU厂家的各自软件栈互相不兼容,不能形成集合算力,导致国产GPU算力碎片化。郑纬民院士直言:“当前产业面临内部竞争和碎片化的问题,不同厂家提供不同接口,软件适配成本极高,产业联盟式的软硬件协同设计非常重要。”
我们亟需打造一套开放的、自主可控的、与各家国产GPU都兼容的底层软件栈生态系统,支撑国产GPU的共同发展,形成集合算力。从零打造一套全新的底层软件生态系统是个巨大的工程,耗时耗力,CUDA的研发用了超过20年的时间,花费数百亿美元,因此利用现有的最强大的开源软件栈是个最合适的选择。
3.2 重复建设与恶性竞争
软件栈碎片化的直接后果是重复建设与恶性竞争。据不完全统计,国内GPU厂商在编译器、数学库、深度学习框架适配等基础软件领域的重复投入累计超过百亿元。每家厂商都在“重新造轮子”,却难以达到国际先进水平。
更严峻的是市场端的内卷。有分析指出:“芯片行业一个细分赛道就有数十家公司,都在做重复的产品。价格杀到血淋淋,几乎没有什么毛利,卷到血流成河。”这种低水平竞争不仅消耗了宝贵的创新资源,更让中国GPU产业难以形成对抗CUDA生态的合力。
3.3 生态孱弱的三重根源
中国工程院院士孙凝晖系统分析了国内智能计算生态孱弱的根源:“一是研发人员不足,英伟达CUDA生态有近2万人开发,是国内所有智能芯片公司人员总和的20倍;二是开发工具不足,CUDA有550个SDK,是国内相关企业的上百倍;三是资金投入不足,英伟达每年投入50亿美元,是国内相关公司的几十倍。”
更为严重的是,“国内企业之间山头林立,无法形成合力,从智能应用、开发框架、系统软件到智能芯片,虽然每层都有相关产品,但各层之间没有深度适配,无法形成一个有竞争力的技术体系”。
四、战略出路:统一开源生态的战略选择
4.1三条道路的抉择
孙凝晖院士指出,中国发展智能计算技术体系存在三条道路:“一是追赶兼容美国主导的A体系(CUDA兼容);二是构建专用封闭的B体系;三是全球共建开源开放的C体系。”
对于国产GPU而言,第一条道路(CUDA兼容)正面临日益严峻的法律风险——英伟达已明确禁止通过翻译层在非授权硬件上运行CUDA,且永远处于追赶落后状态。第二条道路(封闭体系)虽然可控,但难以凝聚产业力量、难以实现全球化。唯有第三条道路——开源开放——才是符合产业规律与国家战略的最优解。
孙凝晖院士明确主张:“用开源打破生态垄断,降低企业拥有核心技术的门槛,让每个企业都能低成本地做自己的芯片,形成智能芯片的汪洋大海。用开放形成统一的技术体系,我国企业与全球化力量联合起来共建基于国际标准的统一智能计算软件栈。”
4.2 ROCm:构建统一生态的“技术基座”与“通行证”
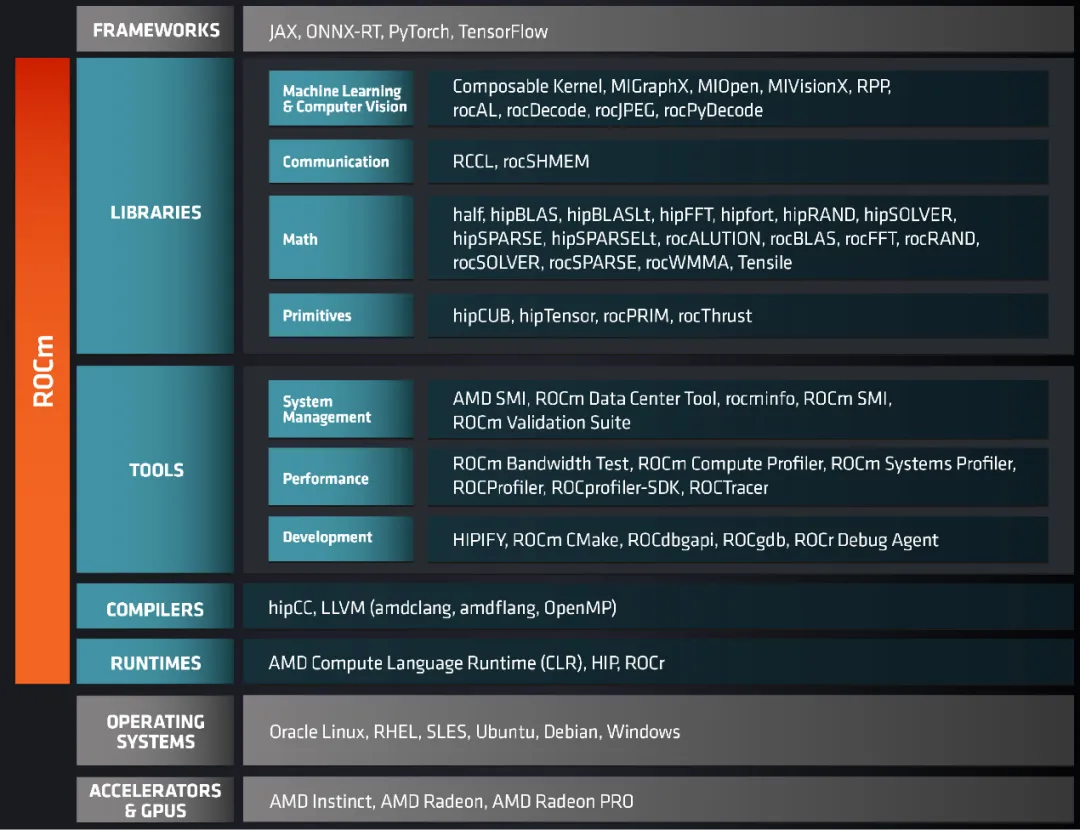
ROCm(Radeon Open Compute platform)是AMD推出的开源GPU计算平台,包含基于LLVM的HIP编译器、高性能数学库(rocBLAS、rocSOLVER、rocFFT)、深度学习库(MIOpen)、通信库(RCCL)以及丰富的开发工具集。
选择ROCm作为统一基座,基于以下战略考量:
第一,技术成熟且持续演进。 ROCm经过近十年发展,已在全球超算领域得到验证。美国橡树岭国家实验室的Frontier系统(全球首个百亿亿级超算)即基于ROCm构建。ROCm 7.2已全面支持大语言模型训练与推理,与PyTorch、TensorFlow等主流框架实现深度集成。
第二,开源许可友好。 ROCm主体代码采用MIT等宽松许可证,允许自由使用、修改和分发。这意味着中国产业完全可以创建自主维护的分支,不受外部断供风险影响,自主性与基于Linux发展国产操作系统完全一致。
第三,迁移成本可控。 ROCm提供HIPIFY工具,可将CUDA代码自动转换为HIP代码,转换率通常超过90%。这为应用从CUDA生态迁移到国产平台提供了可行的技术路径。
第四,海光DCU已验证可行性。 海光DCU基于ROCm生态实现规模部署,在金融、电信等领域成功替代英伟达 GPU,证明非AMD原生硬件完整运行ROCm的技术路径已打通。
4.3 统一不等于同质化
需要强调的是,统一软件栈不等于扼杀差异化竞争。郑纬民院士指出:“全功能GPU需同时满足AI计算、3D图形、HPC高精度计算三大能力,适配多元化场景。”统一的软件接口之下,各厂商仍可在硬件架构、性能优化、成本控制等方面展开差异化竞争。正如Linux统一了操作系统内核接口,但并未阻止Red Hat、Ubuntu、Android等发行版在应用层面的百花齐放。
五、统一软件生态对AI产业的战略价值
5.1 对AI人才培养的价值
李国杰院士强调,实现AI自立自强首先要“创新人才的使用和培养模式”。统一的软件生态对人才培养具有基础性意义。
降低学习门槛,扩大人才基数。 当前高校学生在校学习的GPU编程主要是CUDA,毕业后自然倾向于使用CUDA平台。如果国产GPU各自为政,学生不可能学习十几种互不兼容的编程接口。统一到ROCm/HIP后,学生只需学习一套编程模型,就能在各类国产GPU上开发应用。这为国产平台进入高校教育体系创造了条件。
构建人才供给的正向循环。 郑纬民院士指出:“开发者才是生态的核心资源,平台的成败由开发者决定。”统一生态能够形成“学ROCm→用国产卡→贡献开源→反馈产业”的良性循环。建议将HIP/ROCm编程纳入计算机等级考试和高校课程体系,设立“异构计算工程师”认证,快速扩大开发者群体。
对标国际培养竞争力。 ROCm是国际主流开源技术,学习ROCm不仅不与国际脱轨,反而能让学生掌握与国际接轨的技术能力。这与学习Linux而非某个国产操作系统分支的逻辑一致——既服务国产化需求,又保持国际竞争力。
5.2 对AI科技创新的价值
避免低水平重复,聚焦核心创新。 李国杰院士提出:“相关部门应下决心组织全国开发力量,开发一套比CUDA更优秀、自主可控的AI软件工具系统。”统一软件生态使产业力量从“重复造轮子”中解放出来,集中突破高性能计算库、大规模分布式训练框架、模型编译优化等核心技术。
形成“一次优化,全行业受益”的协作效应。 在统一技术栈下,任何厂商或科研机构对编译器、数学库、通信库的优化改进,所有参与者都能共享。这种“开源协同”模式已被Linux、LLVM、PyTorch等成功项目反复验证。
构建自主演进的创新能力。 郑纬民院士提出“主权AI”概念,强调“算力自主、算法自强、生态自立”三位一体。统一开源生态使中国产业从国际开源社区的“使用者”转变为“贡献者”乃至“主导者”,逐步形成自主演进的技术能力,而非永远跟随。
5.3 对AI产业发展的价值
降低ISV适配成本,加速应用落地。 当前独立软件开发商(ISV)面对十几家国产GPU厂商,需要为每家单独适配,成本呈指数级上升。软件生态统一后,ISV只需一次适配即可覆盖所有国产硬件,极大降低迁移成本和市场风险。
形成市场合力,突破生态壁垒。 碎片化的“小生态”永远无法达到商业闭环所需的临界规模。只有统一,才能形成“开发者愿学、ISV愿配、用户敢买”的正向循环,真正打破CUDA的“生态围墙”。
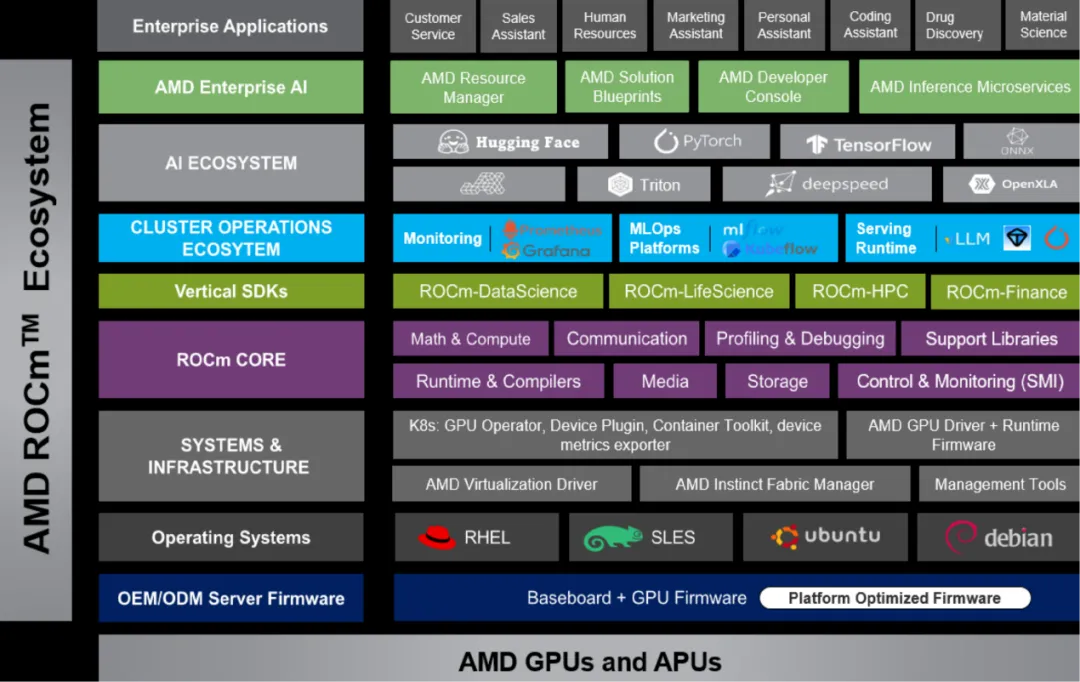
培育中国自主的开源生态体系。 通过组建设立《开放计算基金会》发布新一代开放计算平台和人工智能开源社区,“围绕模型开源、算力协同、数据开放、社区运营与人才培养等方向展开深度合作”。依托这一基础设施,可以构建中国主导的GPU开源生态。
六、战略验证:多维度的可行性分析
6.1 信创可行性:完全自主的“开源分叉”
针对“ROCm源自美国是否有断供风险”的质疑,需明确指出,基于MIT许可证的代码具有永久自主权。《开放计算基金会》可立即启动“异构计算通用软件栈”项目,Fork当前ROCm稳定版本作为自主维护主干。这与基于Linux Kernel发展出麒麟软件、统信UOS、欧拉操作系统的逻辑完全一致,完全符合国家安全审查的信创核心要求。
6.2 技术可行性:模块化架构的平滑接入
ROCm天然具备“驱动层-运行时-应用库”的分层解耦设计。对于算力各异的国产GPU,只需要实现底层的ROCk内核驱动与LLVM编译器后端,即可向上无缝对接ROCm的庞大应用生态。对于暂不具备独立驱动的轻量级GPU,还可通过“HIP-CPU”模式或兼容层技术实现快速接入。
6.3 商业可行性:求同存异,分层竞争
厂商担心统一会磨平产品差异。真正的落地策略应当是“统一语言,不统一硬件”。即强制统一上层API和编程模型,释放硬件底层的自由竞争。正如安卓统一了应用生态,但并不妨碍各家手机厂比拼芯片、影像和屏幕素质。中国工程院院士高文曾指出,开源社区的协调机制能很好地解决“公共利益”与“私有利益”的矛盾,国家应主导生态共性技术,而企业聚焦硬件差异性。
七、收益性评估:从“输血”到“造血”
全面统一ROCm软件栈将在3-5年内为中国AI产业带来显著的直接与间接收益。
研发降本: 消除ISV的N次重复适配,预计每年可为产业节省数百亿元的生态适配浪费,使资金流向更核心的模型算法创新。
效能提升: 通过集中的底层库优化,国产GPU在大模型训练推理中的综合利用率将从当前的普遍低于40%向英伟达 90%以上的效率看齐。
全球话语权: 中国庞大的开发者群体集体贡献ROCm社区,将使中国需求反向重塑国际开源异构计算的演进标准,从跟随者变为引领者。
八、实施路径:组建“开放计算基金会”
8.1 组织架构设计
建议在组建设立《开放计算基金会》框架下,联合GPU企业、整机厂商、操作系统厂商、算法模型厂商、云计算厂商、AI框架团队、科研院所,共同组建“开放计算基金会”(Open Computing Foundation,暂名)。该基金会参照RISC-V国际基金会的治理模式,下设:
技术委员会:负责ROCm中国分支的技术路线规划、版本管理与兼容性认证。
标准委员会:制定《GPU异构计算软件栈统一接口规范》,明确以HIP及ROCm库为唯一标准编程接口。
合规与安全委员会:负责代码审查、后门排查、出口管制合规等。
人才与生态委员会:负责高校合作、开发者社区运营、认证体系建设。
8.2 技术架构
采用“统一接口、分层实现”的开放技术架构:
应用层:AI框架(PyTorch、PaddlePaddle、TensorFlow等)通过ROCm后端调用。
统一接口层:HIP C++ API + ROCm核心库(rocBLAS、MIOpen、RCCL等),全行业共享。
硬件适配层(HAL):各厂商实现ROCk内核驱动与LLVM后端,差异化竞争硬件性能。
工具链层:ROCgdb调试器、ROCProfiler性能工具、HIPIFY迁移工具,由联盟统一维护。
8.3 推进步骤
第一阶段(奠基期,第1-2年): 组建设立《开放计算基金会》,冻结HIP/ROCm基线版本,发布兼容性测试套件。各厂商发布基于HIP-over-OpenCL的运行时预览版,实现“能跑”。
第二阶段(移植期,第3-4年): 各厂商完成原生ROCk驱动与LLVM后端适配,实现关键数学库和深度学习库原生运行。PyTorch官方分支支持“中国ROCm”后端,实现“好用”。
第三阶段(成熟期,第5年): 所有信创整机预装统一ROCm软件栈,头部ISV完成核心应用移植。至少3家厂商通过完整性能认证,达到数据中心部署要求。
第四阶段(演进期,第6年起): 淘汰私有API,新产品仅支持统一软件栈。中国ROCm社区开始主导新特性开发并回馈国际ROCm社区,构建中文生态应用市场。
九、政策建议
第一,将“统一软件生态”纳入信创强制标准。 出台《GPU异构计算软件栈统一接口规范》,将“通过统一生态兼容性认证”作为信创采购的入场条件。这并非人为设置壁垒,而是避免产业陷入“碎片化夭折”的必要保障。
第二,设立专项工程与资金支持。 启动“统一GPU软件栈”国家科技重大专项,对厂商内核移植、编译器开发、库优化等给予研发补贴,推行首版次保险补偿,降低企业投入风险。
第三,构建高校人才培养体系。 将HIP/ROCm编程纳入示范性人工智能学院、软件学院和集成电路学院课程,支持编写中文教材和在线课程。设立“异构计算工程师”认证,建立人才供给通道。
第四,建设开源基础设施。 依托《开放计算基金会》平台,建立“中国ROCm”主干仓库。借鉴“开源鸿蒙”的治理经验,形成基金会主导、厂商共建、社区共治的可持续治理结构。
第五,深化国际合作。 在坚持自主可控的前提下,积极与ROCm国际社区保持技术交流和代码合并,避免“闭门造车”。中国产业应争取成为国际开源社区的主力贡献者,而非被动跟随者。
十、结语综述
中国AI产业的高质量发展,不能建在别人提供的“沙滩”上。将全部国产GPU软件栈统一于ROCm开源生态,是面对技术封锁时的“强渡大渡河”。它具备无与伦比的战略必要性——打破碎片化必走之路;具备完全现实的操作可行性——基于开源架构的自主重构。
郑纬民院士强调:“我们要团结一心,解决应用不足与生态薄弱的问题。产业界要团结起来,应用也要团结起来。”李国杰院士呼吁:“在信息领域,单个企业的闭门造车永远无法对抗国际巨头的生态垄断。国家力量的介入,通过开源模式组织大兵团作战,是建立中国自主软件生态的唯一历史经验。”
以国家力量引导、开源机制运行、全行业合力推进,我们完全有可能用3-5年时间,打造出一个能与CUDA良性竞争、繁荣的国产通用异构计算软件生态,为中国人工智能产业高质量发展筑牢坚实的算力基石。