 夜雨聆风
夜雨聆风





当 AI Agent 成为新的软件范式
软件工程要终结了。这话听着有点刺耳,但一篇论文:The End of Software Engineering: How AI Agents Are Fundamentally Restructuring the Software Paradigm: https://arxiv.org/pdf/2606.05608 ,给了一个很有意思的视角:AI Agent 不是在帮程序员写代码更快,而是在消灭「写代码」这件事本身。
一个被忽视的结构性矛盾
Brooks 在《人月神话》里提过一个观点:软件的复杂度增长方式和其他工程领域完全不同。造桥有制造环节,设计完了就照着造。软件没有,设计就是产品本身。每加一个功能、每处理一个边界情况,可能的交互组合就指数级增长。Brooks 把这种复杂性称为「本质复杂性」,是问题本身固有的,不是实现过程中的偶然产物。
论文给了一个形式化的命题:对于一个有 n 个组件的系统,每个组件可能与其他任何组件交互,可能的交互路径数 P(n) 的上界是 Θ(2^n)。这是因为 n 个组件对中的每一对可能有或没有有意义的交互,产生 2^(n 选 2) 种可能的依赖图。
而人类工程师的认知能力是常数级的。
这个错配是软件项目随着规模扩大,边际生产力持续下降的深层结构原因。传统的应对方式,不管是层次分解、模块接口还是封装,只是降低了常数因子,并没有改变指数增长的本质。数十年的进步——更高级的语言、框架、自动化测试——系统性地降低了偶然复杂性,但本质复杂性仍然无界。
问题不是「工程师不够聪明」,而是「人类认知能力有上限」。
Agent 系统是怎么打破这个天花板的
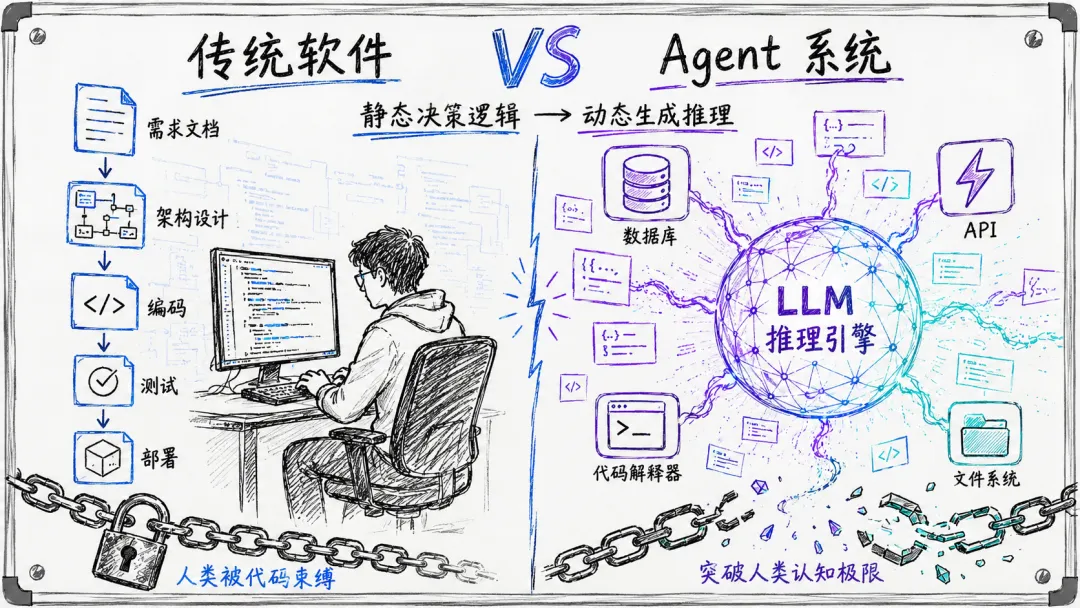
论文提出了两个形式化定义,把传统软件和 Agent 系统的本质区别讲清楚:
传统软件系统 S = (C, D, E)。C 是计算资源,D 是以源代码编码的确定性决策规则集,E 是执行环境。关键属性是 D 相对于执行是静态的:所有决策逻辑必须由人类工程师在系统遇到任何输入之前显式编写。每一个功能添加、每一个 bug 修复、对变化环境的每一次适应,都需要人类理解变更、定位代码、修改逻辑、验证正确性。
Agent 系统则完全不同,A = (M, T, M, Π)。M 是作为推理引擎的大语言模型,T 是可执行工具集(代码解释器、API、数据库、文件系统),M 是记忆子系统(短期上下文、长期向量存储),Π 是将用户意图分解为动作序列的规划机制。
系统通过迭代执行运行:a_t ← M(s_t, M), s_{t+1} ← exec(a_t),其中 s_t 是时刻 t 的系统状态,a_t 是模型选择的动作。
关键区别在于,在智能体系统中,决策逻辑是在运行时生成的。LLM 可以动态生成代码、调用工具、根据中间结果调整行为——这些都不是预先编程的。它生成的代码不是系统本身,而是按需产生和丢弃的临时制品。
论文说这和 Karpathy 提的「Software 2.0」一脉相承,但更进一步。Karpathy 说的是神经网络用学习到的权重替代手工程序逻辑。Agent 系统更激进,神经网络不仅替代程序,它还按需编写程序,把代码当工具用。这一模式与 ReAct 框架一致,该框架证明推理轨迹与工具使用动作的交错可以显著提高任务性能;也与 Chain-of-Thought 提示一致,后者表明显式的中间推理步骤可以解锁 LLM 的潜在能力。
这就是为什么 Agent 能突破人类认知天花板。传统范式下,人类工程师必须先理解整个问题空间,然后编码成静态程序。Agent 范式下,LLM 直接遍历问题空间,有效能力随模型规模和训练算力增长。当任务复杂度 N 超过人类认知能力 C_H 时,传统方法在任何现实成本下都不可行。但 Agent 的有效能力 C_M 随着 LLM 能力的指数增长而相应增长。
不是 10% 的改进,是质变。
第三次范式转移
论文梳理了软件交付模式的演变,把它理解为复杂性从终端用户逐步转移的过程。
第一阶段是授权软件,微软 Oracle 那个年代。用户买了软件,自己装、自己维护,复杂性全在用户这边。收入模式是授权销售。
第二阶段是 SaaS,Salesforce、AWS 这些公司把基础设施接管了。用户不用管服务器了,供应商负责运维和更新。收入模式从授权销售变成了订阅制。
现在是第三阶段,论文叫 Agent-as-a-Service,简称 AaaS。用户只需要说清楚「要什么结果」,Agent 自己去理解、去构建、去运行。收入模式转向基于结果定价。
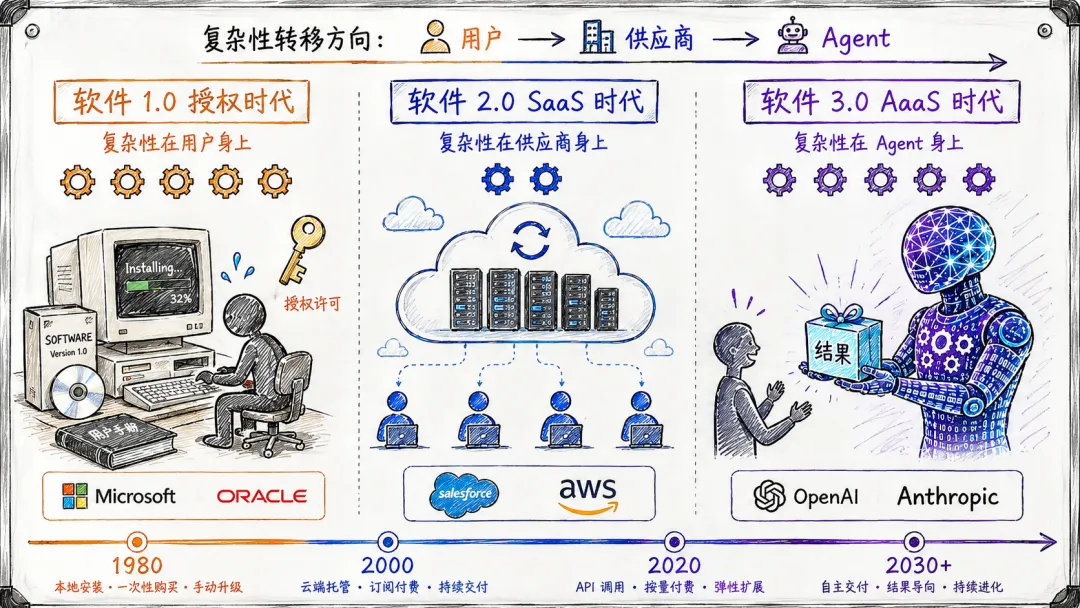
每次转变的模式都一样:最有能力吸收复杂性的一方吸收它,最无能力管理它的一方被解放。SaaS 让企业不用管服务器了,AaaS 要让企业连「怎么实现」都不用管。
但当前主流的企业 AI 用法,是「AI 帮你写代码」。论文把这种模式表示为「AI → 软件 → 结果」管道,指出它有三个结构性缺陷。
人类工程师仍然是瓶颈。AI 只加速了代码生成这个子步骤,没有把人从任何阶段移除。设计决策、架构、集成测试、部署,这些关键路径仍然卡在人类沟通和协调的速度上。最终交付物还是传统软件系统 S = (C, D, E),复杂性天花板完好无损。AI 只是让 D 的构建稍微快了一些,但 D 的规模扩展仍然需要人类理解才能修改。
真正的范式转变是「Agent → 结果」,消除了软件制品作为必要中间层。人类向 Agent 表达意图和约束,Agent 自主规划、执行(按需生成代码)、验证、交付结果,人类审计结果并提供反馈。Agent 可能生成数千行代码、执行数据库查询、调用外部 API、生成可视化,全都是临时的。持续存在的是 Agent 的能力,而不是其中间制品。
正如 Kumar 和 Ramagopal 所总结的:「AI 编码 Agent 擅长在单次用户驱动的会话中将意图转化为代码。智能体工程在更高的抽象层次上运作,它是一个控制平面,编排跨团队工作流,维护跨 Agent 的长期记忆,并在整个软件交付生命周期中管理状态和可追溯性。」
新职业:意图架构师
论文提了一个概念,Agentic Engineering,智能体工程。
LangChain 在 2026 年 4 月正式引入这个定义:一种多 Agent 协调模型,其中 AI Agent 作为数字团队成员运作,每个都有明确的角色、共享记忆和统一可观测层,驱动软件通过整个交付管道,而不仅仅是更快地生成代码。
有意思的是人类角色的变化。论文用一张表对比了传统软件工程和智能体工程的差异。
传统软件工程的核心制品是源代码,是静态的;智能体工程的核心制品是 Agent 系统,是动态的。传统软件工程的控制中心是人类工程师;智能体工程的控制中心是 LLM 推理引擎。传统软件工程的决策机制是预设计逻辑;智能体工程的决策机制是运行时生成推理。传统软件工程的开发周期是线性的,从设计到编码到测试;智能体工程的开发周期是自主迭代循环。
最根本的变化是人类角色。传统范式下,人的价值是写代码的能力,代码生成技能是核心竞争力。Agent 范式下,代码生成技能被商品化了。新的人类差异化能力是什么?
-
意图表达。以足够的清晰度和约束指定目标,使 Agent 能自主运作而不产生非预期结果的能力。这不是简单地写个需求文档,而是要理解 Agent 的能力边界,知道什么任务适合交给 Agent,什么任务需要人类干预。
-
架构监督。在系统层面理解多个 Agent 应如何协调、什么记忆应被共享、何处人类判断必须介入。当多个 Agent 组成团队工作时,就像管理一个分布式系统,需要设计通信协议、共享状态、容错机制。
-
质量校准。定义「好」的标准并构建 Agent 可用于自我修正的评估框架。Agent 需要明确的反馈信号才能改进,这个信号的质量直接决定了 Agent 输出的质量。
-
伦理治理。确保 Agent 行为符合组织价值观、法律要求和社会期望。随着 Agent 越来越自主,这个问题会越来越重要。
论文说,掌握 Agent 编排能力的人,生产力倍增会远超传统的「10x 工程师」。不是打字更快,而是能指挥一群 Agent 完成复杂任务。上限不是固定的,它随着模型能力和编排基础设施的每次进步而上升。
现实很骨感
理论很美好,但 EvoClaw 基准测试把人拉回现实。
这个基准要求 Agent 执行持续软件演进,不是修一个 bug 就完了,而是跨提交历史的持续开发,每次变更都要保持系统完整性,错误还会累积。论文构建这个基准的原因是,现有的基准测试都是孤立任务,不能反映真实世界的软件开发场景。
结果呢?
12 个前沿模型在 4 个 Agent 框架上的评估显示,孤立任务成功率超过 80%,持续演进场景直接跌到 38%。54 个百分点的落差,暴露了 Agent 在长期维护和错误传播方面的深刻困境。
论文分析了四个核心挑战:
-
上下文漂移。当代码库超出有效上下文窗口时,Agent 失去对系统级不变量和依赖关系的连贯理解。这就像一个工程师只看到局部代码,看不到全局架构。
-
错误传播。早期提交中的小错误在后续工作中级联为复合故障,Agent 缺乏检测和从这些链中恢复的鲁棒机制。人类工程师有经验可以凭直觉发现问题,Agent 没有。
-
技术债务感知。Agent 当前不为设计决策的长期成本建模,它们优化即时任务完成而不考虑可维护性。人类工程师会考虑「这个设计以后改起来方便吗」,Agent 只关心「当前任务能不能过」。
-
验证保真度。自动化测试仍然不完整,Agent 可以通过测试但引入细微的语义错误,这些错误只在新的输入下才显现。测试能过,不代表代码是对的。
这四个问题加在一起,就是为什么持续演进场景成功率暴跌。
四阶段路线图
论文基于当前能力和轨迹,提出了智能体工程演进的四阶段路线图。
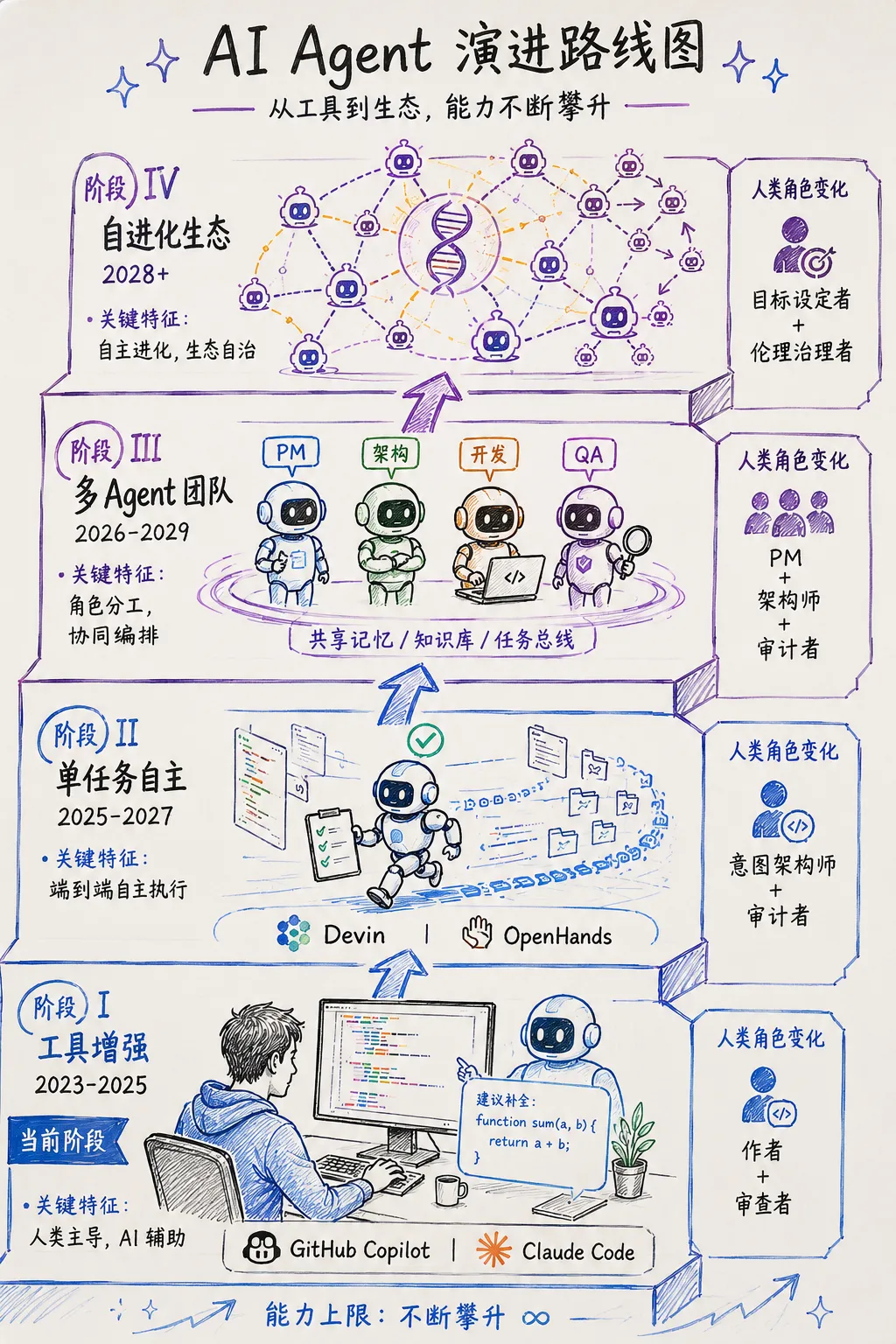
现在是第一阶段,工具增强(2023-2025)。Agent 作为人类主导工作流中的助手,帮你写代码、补全、解释。突破在于编码:模型可以在范围明确的任务上以接近专家的水平生成、解释和调试代码。局限是人类仍需分解问题、设计架构、验证正确性。代表系统是 GitHub Copilot、Claude Code。
接下来是第二阶段,单任务自主(2025-2027)。Agent 开始拥有从规格到部署的完整任务。Devin 和 OpenHands 等系统展示了 Agent 可以自主导航代码库、实现功能、提交 PR。人类从「做」转向「指定做什么并验证做了什么」。
然后是第三阶段,多 Agent 团队(2026-2029)。专业化 Agent 像人类工程团队一样协调运作。「产品经理 Agent」将业务需求翻译为技术规格,「架构师 Agent」设计系统结构,「开发 Agent」实现组件,「QA Agent」测试验证。共享记忆和可观测性成为关键基础设施。LangChain 的试点研究代表了这一模式的早期验证。
最后是第四阶段,自进化生态(2028+)。Agent 获得改进自身架构、为新的问题领域生成专用子 Agent、以及在不需人类干预下适应环境变化的能力。此时「软件」与「Agent」的界限完全消融,Agent 就是系统,且持续进化。人类参与转向元级治理:设定伦理边界、定义价值函数、确保对齐。
这对我们意味着什么
论文最后给了三类人的建议。
-
对从业者:从代码生产转向意图工程。最有价值的技能不再是高效编写代码,而是以足够的清晰度、上下文和约束来表达任务,使 Agent 能正确执行。理解如何在 Agent 间分解工作、管理共享记忆、设计评估标准,将区分有效的从业者。Agent 系统需要与传统软件根本不同的监控方式,追踪 Agent 的推理链、检测幻觉、衡量结果质量需要新工具。
-
对研究者:长上下文状态管理、开放环境下的验证、大规模 Agent 对齐、经济模型,这些是开放问题。当前基准测试孤立正确性,现实系统需要随时间推移的安全性、可靠性和可维护性保证。随着 Agent 更加自主并组合成团队,确保其集体行为与人类价值观一致变得既更重要又更困难。
-
对组织:识别 Agent 就绪的工作流,投资评估框架,重新设计团队结构。并非所有软件工作都同等适合 Agent 自动化,具有明确成功标准、定义良好的范围和现有测试基础设施的任务是理想的起点。随着个体生产力通过 Agent 杠杆倍增,团队拓扑必须演进,更小的「Agent 编排者」团队可能取代更大的开发者团队。
论文坦承,完全自主的软件开发还需要数年研究。但 Agent 作为增强范式,今天就已经是真实且变革性的。孤立任务性能(>80%)与持续演进性能(<38%)之间的差距,量化了当前 Agent 能力与完全自主软件工程阈值之间的距离。
旧的软件工程正在终结,新的已经开始。