 夜雨聆风
夜雨聆风





OpenSpec火了:月下载8个月涨450倍
最近有个开源项目,在 AI 编程圈悄悄爬上了 GitHub 56k Star,npm 月下载量从一千冲到了五十多万,只用了 8 个月。
它叫 OpenSpec。
如果你也被 AI 写出的代码反复折腾过——三轮对话下来它兴致勃勃写了 400 行,结果不是你要的——这个项目值得花十分钟了解一下。
一、它解决了一个所有 AI Coding 用户都遇到过的问题

场景大概是这样:
你跟 Cursor、Claude Code 或者 Codex 聊了几句需求,AI 噼里啪啦把代码写出来了。看上去能跑,仔细一看不对——你当时那句模糊的「加个深色模式」,被 AI 按概率最大的一条路硬接了下去,做出来的东西和你脑子里想的完全是两回事。
回头改,比从头讲清楚再写要贵得多。
问题的根在哪?需求住在 chat 历史里。Chat 是个一次性的、随手扔的东西,AI 读不到全貌,你三天后也想不起来当时说了啥。
OpenSpec 给的答案很简单:在你和 AI 之间,加一层很轻的「规约」。先把「要做什么」写下来,两边看着同一张图达成一致,然后再让 AI 动手。
官方定位是 Spec-driven development(规约驱动开发,简称 SDD)。听起来挺重,实际用起来比写一段 prompt 多不了多少步。
二、用数据说话:它到底有多火
光看 Star 数容易被刷出来,下载量是更难造假的指标。下面几组数据都来自 GitHub 仓库和 npm registry,截至 2026 年 6 月 25 日。
仓库侧:
- GitHub Stars:56.6k
- Fork:3.9k
- Commits:608
- 已合并 PR + Open PR:合计上千
npm 侧:
- 包名:@fission-ai/openspec
- 首次发布:2025-09-06(v0.1.0)
- 当前版本:v1.4.1,累计 38 个版本
- 累计下载:约 187 万次
- 最近 30 天:64.7 万次
- 最近 24 小时:3.9 万次
最直观的还是月度下载曲线:
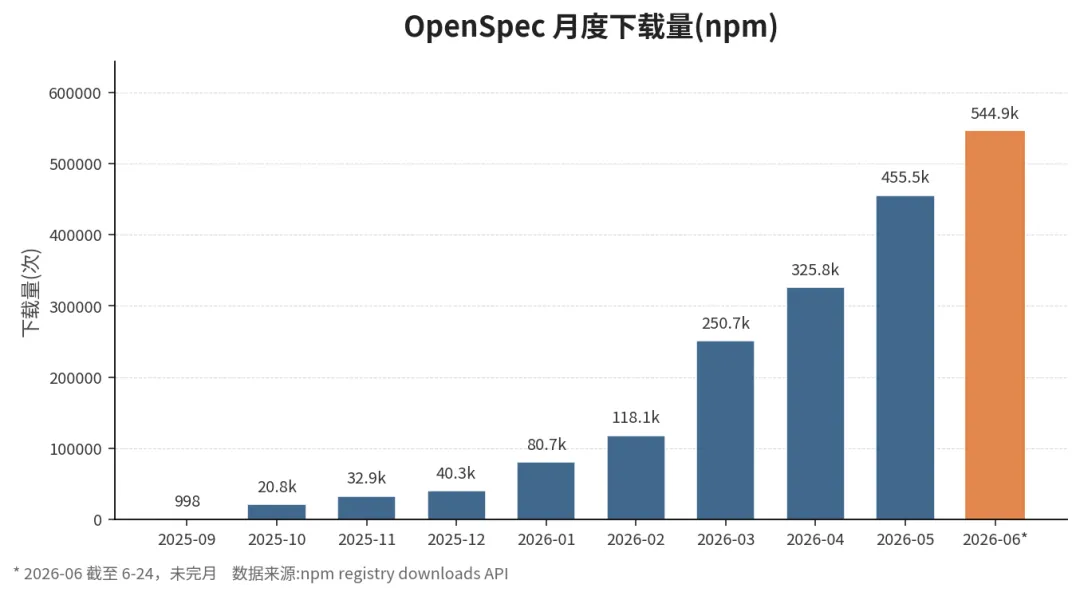
从首发到第 8 个完整月,月下载量从不到 1000 涨到 45 万以上,差不多 450 倍。考虑到这段时间正好是 Claude Code、Codex、Cursor 这类 Coding Agent 大规模铺开的窗口期,可以理解为:「AI Coding 用户在自发寻找一个规约层」。
中文社区也在跟进,类似 OpenSpec-practise(实战指南)、flow-kit(流程整合)这类二次组合项目,都已经出现在了 GitHub 中文热门列表里。
三、五个概念,30 分钟搞懂全部心智模型
OpenSpec 的设计很克制,整个心智模型只有 5 个东西。理解了就能上手。
Specs 是真相。openspec/specs/目录是这个系统当前真相的那一份文档,按auth/payments/ui/这样的领域组织。每条 spec 由「需求」和「场景」组成,比如「系统 SHALL 在 30 分钟无操作后让会话过期」,配上 given/when/then 的例子,就是一条 AI 能读懂的规约。
一个 Change 一个文件夹。要加特性、改行为、删逻辑,就在openspec/changes/下开一个目录。一次变更,一个文件夹,里面装这次工作的全部东西。
Delta Specs:只写差异。这是 OpenSpec 区别于「老式 SDD」最关键的设计。你不重写整份规约,只写差异:ADDED 哪条新需求、MODIFIED 哪条旧的、REMOVED 哪条不要了。
这一点让它能在棕地项目里用。你不用先花两周把五万行的老系统全文档化,才能开始管下一个改动。从下一次改动开始用就行,旧代码留着原样不管。
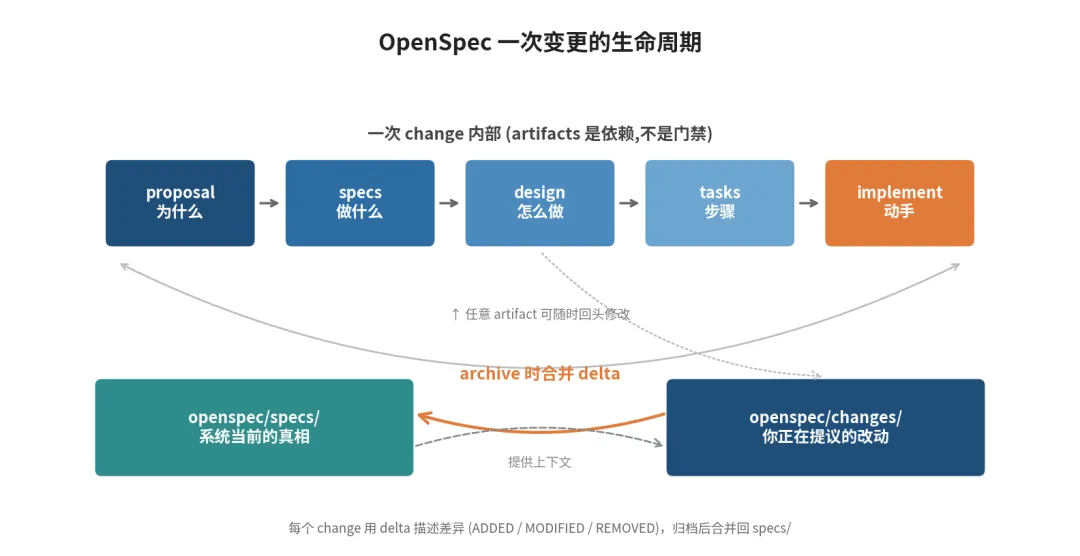
Artifacts 之间是依赖不是门禁。一个 change 里通常有四份文档,按 proposal → specs → design → tasks → implement 的顺序生成。
注意官方原话:「enablers, not gates」——是台阶,不是闸门。到了 tasks 阶段才发现 design 不对,回去改 design 就行,没有什么审批回流。
Archive 闭环。这次 change 做完,归档时 delta 自动合回specs/,change 文件夹挪到changes/archive/加上日期前缀。你的 specs 描述了系统的新现实,循环关上,进入下一个 change。
整个流转放在一张图里大概是这样:
四、跑一个完整循环长什么样
落到日常工作里,开发者跟 AI 助手对话的命令是这样的:
| /opsx:explore 没把握就先聊一下 /opsx:propose add-dark-mode AI 起草 proposal/specs/design/tasks ↓ 你读一下、调一调 /opsx:apply AI 按 tasks 逐项实现 /opsx:archive 合并规约,归档变更 |
举个 README 里给的真实例子。你说要做深色模式,但不确定怎么干净地实现:
| You: /opsx:explore AI: 你想探什么? You: 想加深色模式,但不知道怎么做最干净。 AI: 我看了一下你的样式层……最干净的路径是 CSS 变量 + 一个小的 theme context,加系统偏好检测。不引新依赖。 要按这个范围做吗? You: 好。 You: /opsx:propose add-dark-mode You: /opsx:apply You: /opsx:archive |
注意openspec init这种命令是在终端跑的,/opsx:*是在 AI 助手对话框里跑的。CLI 负责装配,slash command 负责日常协作,分得很清楚。
五、和 Spec Kit、Kiro 比,差异在哪儿
最近一年 SDD 工具不止 OpenSpec 一个。把它和另外两个最常被拿来比较的对象——GitHub Spec Kit、AWS Kiro,以及「什么都不用」这条基线放在一张表里,差异就比较清楚了。
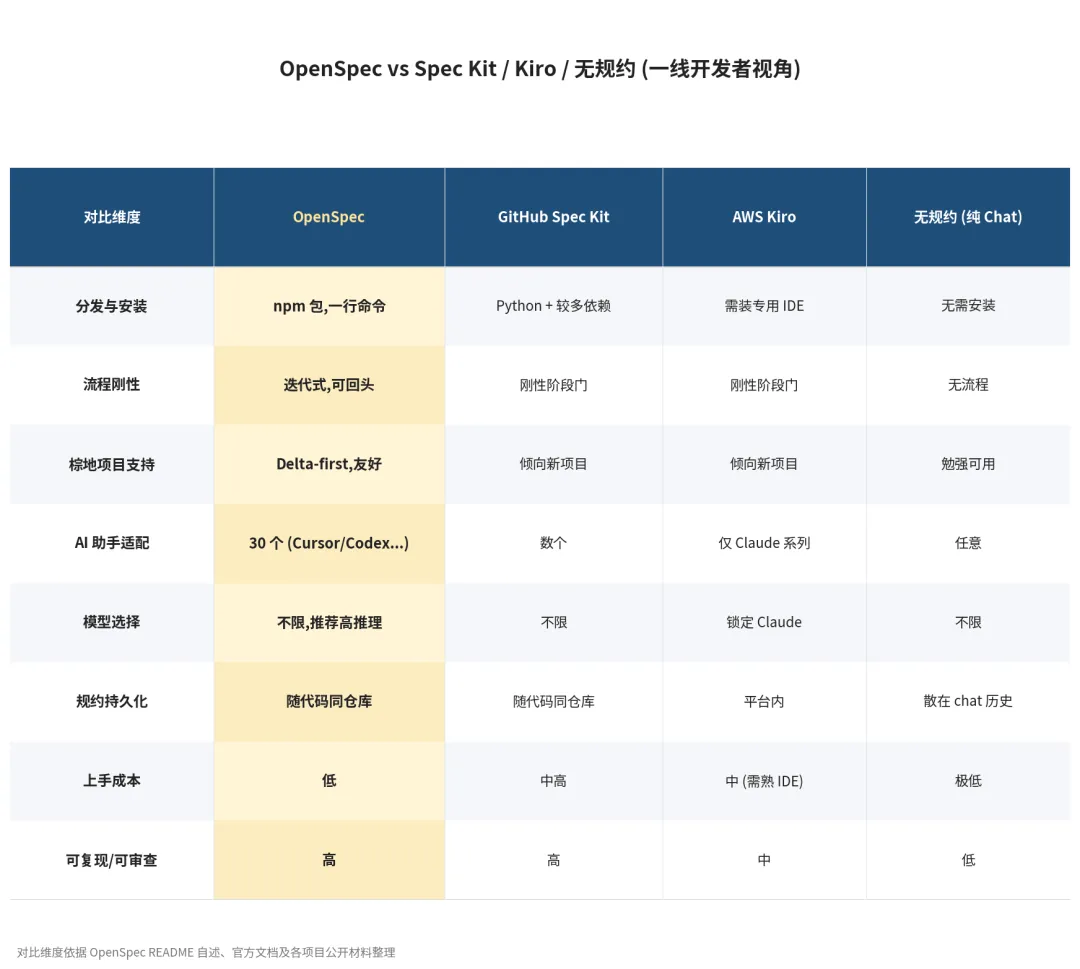
简单说:Spec Kit 适合愿意为规约付完整工程成本的团队,但 Python 安装 + 刚性阶段门把门槛抬高了;Kiro 能力强但绑自家 IDE 和 Claude 模型;纯 chat 能跑,但需求散在历史里,三个月后没人记得当初为什么这么写。OpenSpec 选的是最轻的那条路:npm 一行装、迭代式、不锁工具栈,目前看是 30 个 AI 助手都能接。
六、几个一线开发者值得关注的设计选择
Delta-first 是它能进棕地项目的关键。很多 SDD 工具默认你有一份完整的现状规约可以编辑,结果在真实业务里没人这么写过,工具就用不起来。OpenSpec 让你可以从下一次改动开始用,旧代码不管。
Skills + Slash Commands 双通道。openspec init会同时给目标 AI 助手安装两类东西:以openspec-命名的 skill 文件,以及以opsx-命名的 prompt/command 文件。前者把「什么是 propose、什么是 archive」灌进 AI 的上下文,后者给你在对话里一个可调用的入口。换工具几乎零迁移成本,今天用 Cursor、明天换 Claude Code,规约本身不变。
规约和代码同仓库。这不是新概念,但 OpenSpec 做到了「无副作用」。不用为了试它而搞一套外部知识库,所有东西就是openspec/一个目录。六个月后回来读,proposal 还在原地,能告诉你为什么当初这么做。
七、几点理性的提醒
不是所有任务都值得走一遍 OpenSpec。改一个空指针、调一行文案,写 proposal 比写代码还慢,没必要。
它的甜区是:需要和别人对齐、半年后还可能被回顾、或者动到现有系统核心行为的改动。
另外两点要先说清楚:
第一,对模型推理能力有要求。README 直接写了,OpenSpec 在高推理模型上效果最好,推荐 Codex 5.5 或 Opus 4.7 这一档去做 propose 和 apply。拿一个轻量模型去跑,proposal 容易空、tasks 容易碎,反而把节奏拖慢。
第二,「enablers, not gates」反过来意味着没人替你守纪律。流程不强制,scope 容易蔓延,一个 change 越长越胖,最后变成什么都装的杂物间。这事得自己控制,建议第一次用之前过一遍官方 Workflows 文档。
八、十分钟可以试一下
环境要求:Node.js 20.19.0 或更高。
| npm install -g @fission-ai/openspec@latest cd your-project openspec init |
然后在你常用的 AI 助手里,从/opsx:explore开始就行。
AI 写代码这两年变得越来越便宜,但「和 AI 就要写什么达成一致」的成本反而显出来了。Chat 历史不是合适的载体,prompt 工程不能替代规约。OpenSpec 不是这条路上唯一的尝试,但它的几个选择看起来是对的:轻、迭代式、棕地友好、不绑定具体助手。
45 万次/月的下载量,社区在用脚投票。
项目地址:https://github.com/Fission-AI/OpenSpec npm 包:https://www.npmjs.com/package/@fission-ai/openspec