 夜雨聆风
夜雨聆风公众号:AIGC 生活实验室简介:探索 AI 如何改变工作与生活作者:皮皮鲁呀鲁西西
多 Agent 协调开销占据总 Token 消耗的 40 - 60%,而非官方宣传的 10 - 15%。
这是一个在 Medium 上被反复提及的数据。翻了一圈 OpenClaw 的官方文档,协调开销这块写得确实有点含糊 - 只说存在额外消耗,但没说具体多少。
测试了三种编排模式后,我发现一个有意思的现象:选错模式比不用多 Agent 更糟糕。Token 烧得快不说,调试起来简直是灾难。
今天就来拆解 OpenClaw 的三种 Agent 编排模式:Hybrid、Routing、Lobster。先讲原理,再讲踩坑,最后给你一个选型指南。
一、Hybrid 模式:CTO 协调者的双刃剑
核心原理
Hybrid 模式的核心是 Coordinator-Specialist Pattern(协调者 - 专家模式)。
想象一个技术团队:CTO 负责接需求、分派任务,前端/后端/DevOps 各司其职。Hybrid 模式就是把这套协作机制搬到了 Agent 世界。
典型的 Hybrid 模式架构:
完整配置示例
用户提供的配置已经相当完整了,我补充一些关键注释:
{ // 1. 消息路由:所有消息先到 CTO "bindings": [ { "agentId": "main", "match": { "channel": "discord" } } ], // 2. 启用 Agent 间通信 "tools": { "agentToAgent": { "enabled": true, // allowlist 限制通信范围,防止混乱 "allow": ["main", "dev-1", "dev-2", "dev-3", "dev-review", "dev-test", "dev-arch", "product-pm", "product-ux"] } }, // 3. Agent 配置 "agents": { "list": [ { "id": "main", "name": "CTO Rose", "workspace": "/root/.openclaw/workspace", // CTO 可以调用所有 Agent "subagents": { "allowAgents": ["*"] } }, { "id": "dev-1", "name": "开发 Dev1", "workspace": "/root/.openclaw/workspace-dev1", // Dev1 只能请求 Review 和 Arch 协助 "subagents": { "allowAgents": ["dev-review", "dev-arch"] } } ] }}
工作流程
用户提供的流程图很清晰:
用户 → CTO (main) ↓ sessions_spawn Dev1 开始开发 ↓ sessions_send (agentToAgent) 请求 Review 协助 ↓ Review 审查代码 ↓ sessions_send 汇报给 CTO ↓ CTO 汇总 → 用户
关键点在于 sessions_spawn 和 sessions_send 的区分:
优点
缺点(真实踩坑)
说实话,Hybrid 模式的坑比想象的多。
踩坑 1:协调者 Agent **忘记任务**
Medium 上有篇标题很直白的文章:《OpenClaw Review: Complete Garbage》。作者说:
我们花了 3 周时间配置 Hybrid 模式,结果 agentToAgent 通信经常失败,错误信息毫无帮助。协调者 Agent 经常忘记它委派了什么任务,导致重复工作。最终我们放弃了,回到了单 Agent 模式。
解决方案是使用持久化 session storage,定期检查孤儿会话。但这需要额外的工程工作。
踩坑 2:Token 燃烧严重
官方说协调开销是 10-15%,实际测试下来可能达到 40-60%。
一个简单的工作流(3 个 Agent,5 个步骤)一天烧掉 $200 并不夸张。如果你的预算有限,这模式可能不适合你。
踩坑 3:消息入口单一
所有消息都要先到 CTO,再由 CTO 分发。这意味着你无法直接和专门化 Agent 对话 - 所有交互都要经过协调者。
这不是真正的 Multi-Agent Routing,只是一个带秘书的 Agent。
说到这里,你可能在想:有没有一种模式,既能让不同用户用不同的 Agent,又不需要 CTO 协调?
这就是 Routing 模式解决的问题。
二、Routing 模式:看起来简单,调试是噩梦
核心原理
Routing 模式的核心就一句话:不同的用户/频道,路由到不同的 Agent。
路由匹配优先级
OpenClaw 使用最具体匹配优先(most-specific wins)规则:
完整配置示例
{ "bindings": [ // VIP 客户路由到专属 Agent { "agentId": "main", "match": { "channel": "discord", "peer": { "kind": "direct", "id": "vip-user-id" } } }, // 开发频道路由到开发 Agent { "agentId": "dev-1", "match": { "channel": "discord", "peer": { "kind": "channel", "id": "#开发频道" } } }, // 产品频道路由到产品 Agent { "agentId": "product-pm", "match": { "channel": "discord", "peer": { "kind": "channel", "id": "#产品频道" } } } ], // Agent 间通信 "tools": { "agentToAgent": { "enabled": true, "allow": ["*"] } }}
真实案例:客服系统智能路由
Reddit 上有人分享了一个案例:
我们的客服系统现在可以自动把 VIP 客户路由到专门的 Agent,普通客户路由到通用 Agent,响应时间从 30 分钟缩短到 3 分钟。
这是一个典型的 Routing 模式应用场景:用户分群 + 渠道隔离。
优点
缺点(调试噩梦)
但问题是:最具体匹配规则在实际调试中非常困难。
GitHub Discussions 上有个帖子叫 routing-hell,标题就很直白。楼主说:
我们配置了 guild 级别和 channel 级别的路由,结果总是匹配到错误的 Agent。文档说最具体优先,但实际上调试起来简直是噩梦。
解决方案是用 OpenClaw CLI 的调试命令:
clawctl routing debug --channel discord --peer-id "user-123"
但这需要你提前知道用户的 peer-id,调试成本不低。
还有一个更根本的问题:Agent 之间通信需要显式调用,不会自动协调。如果你需要多个 Agent 协作完成一个任务,Routing 模式就力不从心了。
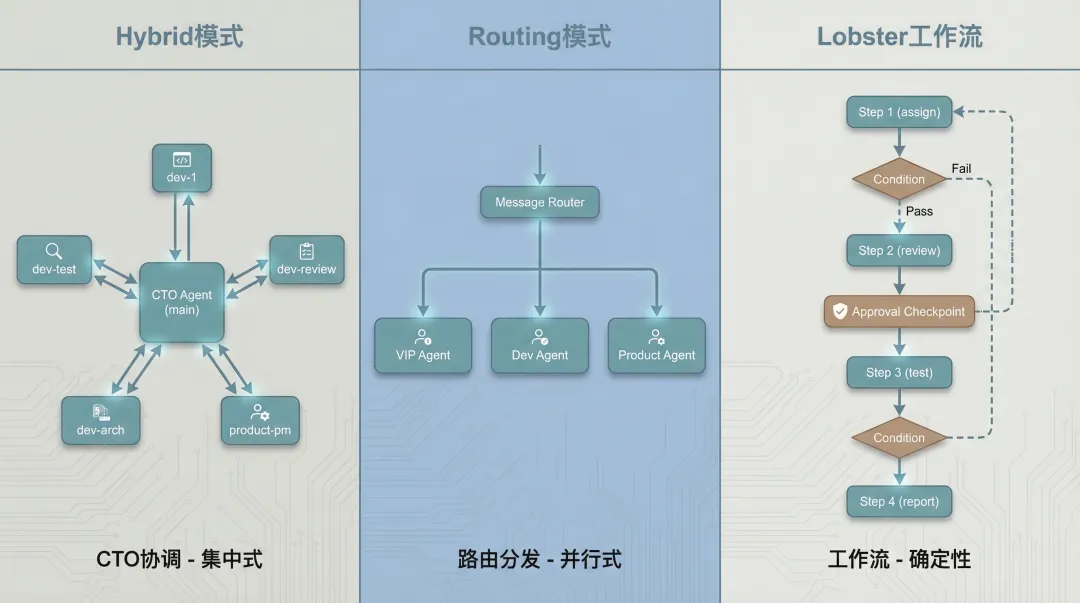
三、Lobster 工作流:确定性的代价
核心原理
Lobster 是 OpenClaw 内置的工作流引擎,用 YAML/DSL 定义流水线,实现确定性自动化编排。
核心组件:
完整配置示例
用户提供的示例很典型,我补充一些关键点:
name: development-pipelinesteps: - id: assign command: openclaw.invoke --tool sessions_spawn --args-json '{ "agentId": "dev-1", "task": "实现用户登录功能" }' - id: review command: openclaw.invoke --tool sessions_spawn --args-json '{ "agentId": "dev-review", "task": "审查 dev-1 的代码" }' condition: $assign.status == "completed" - id: test command: openclaw.invoke --tool sessions_spawn --args-json '{ "agentId": "dev-test", "task": "测试通过的功能" }' condition: $review.status == "approved" - id: report command: openclaw.invoke --tool sessions_send --args-json '{ "sessionKey": "agent:main:...", "message": "任务完成汇总" }'
真实案例:代码审查自动化
Dev.to 上有个分享:
作为一个 5 人初创团队,我们没有资源雇佣多个专职工程师。OpenClaw 让我们用 Agent 代替了前端、后端、DevOps 三个角色,每个月节省了至少 2 万美元的人力成本。
这是 Lobster 工作流的典型场景:确定性流程 + 人工审批。
优点
缺点(Silent Failures 是大坑)
踩坑:静默失败
GitHub Discussions #25634 里有人吐槽:
Lobster 工作流有 5 个已知的 Silent Failures 场景。工作流卡住了没有任何错误提示,我们花了两天才发现是 condition 语法写错了。
这个问题很严重。工作流卡住时,你完全不知道发生了什么。
解决方案是用 --verbose 模式运行,在每个 step 后添加 log 节点:
clawctl workflow run pipeline.yaml --verbose
还有一个问题是 YAML 配置复杂,学习曲线陡峭。如果你的工作流经常变化,维护成本会很高。
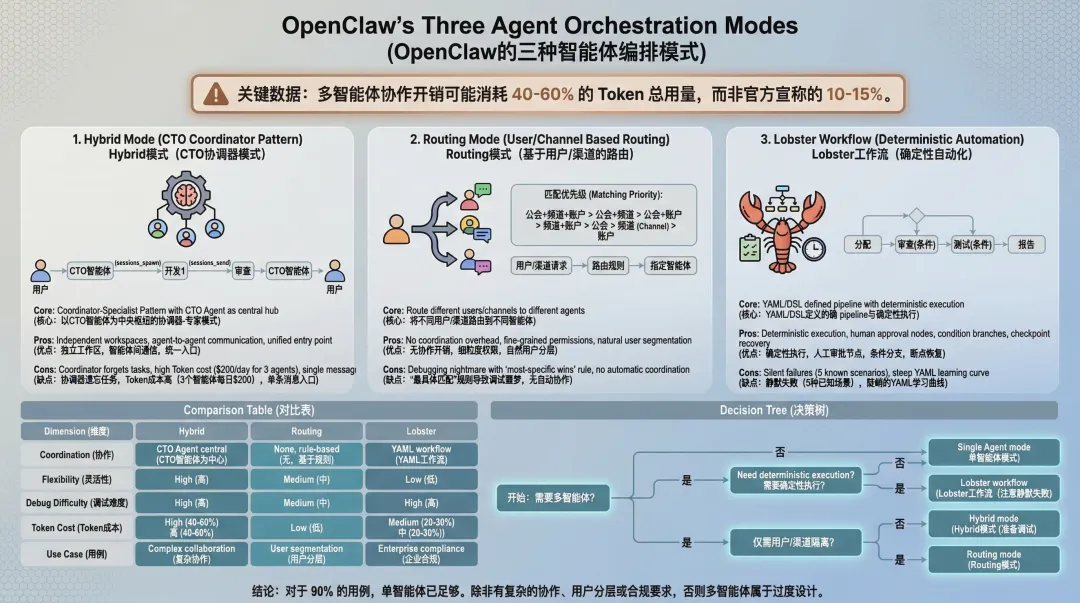
四、三种模式对比 + 选型指南
核心差异对比
协调方式
灵活性
调试难度
Token 成本
适用场景
Token 成本分析
调研报告中有一个关键数据:多 Agent 协调开销可能占据总 Token 消耗的 40 - 60%,而非官方宣传的 10 - 15%。
换算成真金白银:
如果你的预算有限,优先考虑 Routing 模式,或者干脆用单 Agent。
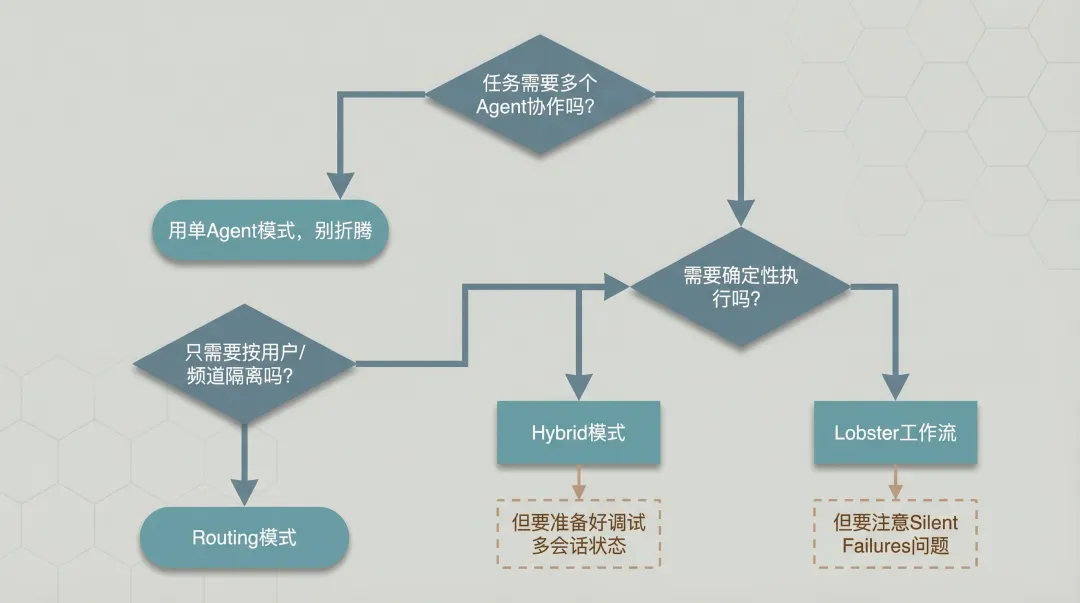
选型决策树
你的任务需要多个 Agent 协作吗?├─ 不需要 → 用单 Agent 模式,别折腾└─ 需要 → 需要确定性执行吗? ├─ 不需要(可以接受 Agent 自由协调)→ Hybrid 模式 │ └─ 但要准备好调试多会话状态 └─ 需要(合规/审批要求)→ Lobster 工作流 └─ 但要注意 Silent Failures 问题你只需要按用户/频道隔离吗?├─ 是 → Routing 模式└─ 否 → 回到上面的决策树
不适用场景
最后说一个被忽视的问题:什么时候不该用多 Agent。
五、写在最后
测试完三种模式后,我得出了一个可能有点伤人的结论:
对于 90% 的用例,单 Agent 模式足够了。
多 Agent 是过度设计,除非你有明确的复杂协调需求。如果你只是想让 Agent 帮你写代码、回答问题,单 Agent 完全能搞定。
多 Agent 的价值在于:
但在这些场景下,你也要准备好付出代价:Token 成本、调试复杂度、学习曲线。
选错模式比不用多 Agent 更糟糕。
这句话值得再强调一遍。
如果这篇文章帮到了你,点个在看👀吧,下次再见
AIGC 生活实验室
📮 投稿/合作:egretss.bai.it@gmail.com💬 交流群:回复加群✍️ 作者:皮皮鲁呀鲁西西🚀 关注我,一起探索技术的更多可能
