 夜雨聆风
夜雨聆风这篇文章我花了好几天认真整理,读完终于彻底搞懂:上下文到底包含什么、该如何分层,也清晰理解了 OpenClaw 的上下文是如何对应的。
为什么Agent上下文必须分层?
我之前理解上下文就是我们输入的文字和大模型输出的内容的简单拼接。
Transformer 注意力机制是 O(n²) 复杂度,上下文越长,模型越难聚焦关键信息。无关信息、冗余历史、噪声过多会稀释有效信号,导致 Agent 决策混乱、失忆,这就是Context Rot / Dilution(上下文稀释 / 腐烂)。大量看似 “模型能力不足” 的问题,本质都是上下文组织太差。
问题的关键不在于窗口不够长,而在于信息密度低、信噪比差。把永久规则、临时状态、历史记录、实时输入混在一起,模型根本找不到重点。
通过分层设计,可以:
降低噪声,提升信息密度 让模型只关注当前最关键的信息 从根源避免上下文稀释
分层 = 给模型做注意力减负,是保证 Agent 稳定运行的核心。
Agent 上下文分层架构
从 「信息的生命周期、加载策略、功能角色与 Token 成本」 四个核心维度来对 Agent 上下文进行分层的,本质是如何高效管理 LLM 上下文窗口的工程设计思路:
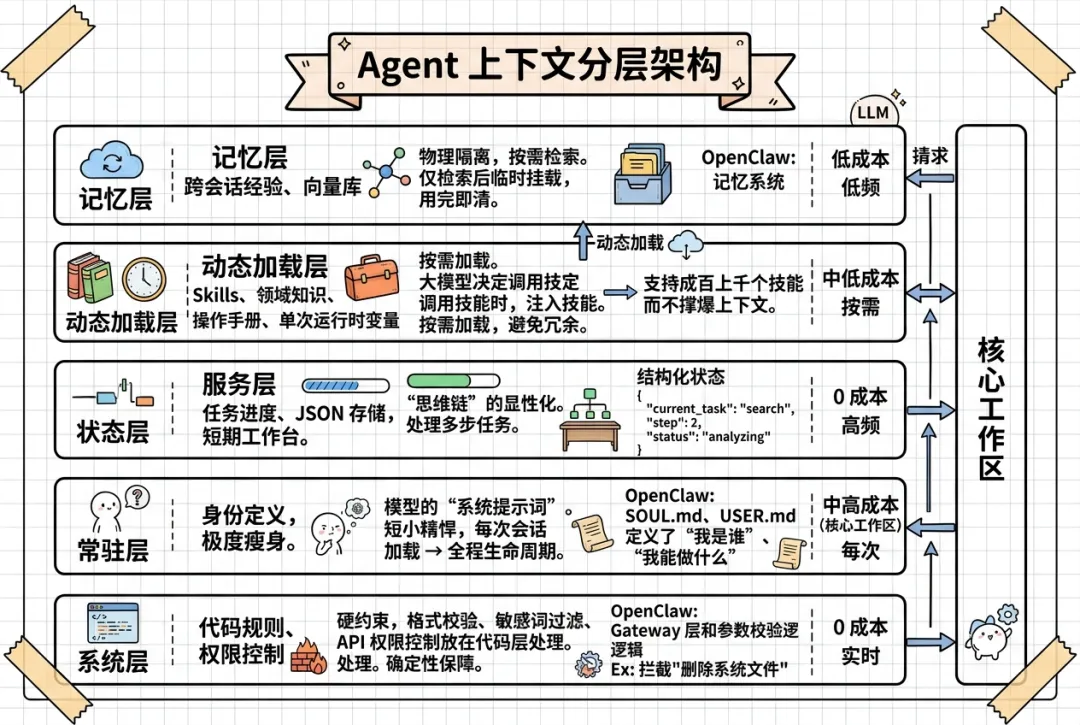
系统层
内容:代码规则、权限控制,完全不进上下文。 解读:这是硬约束。将格式校验、敏感词过滤、API 权限控制放在代码层处理,是确定性的保障。 OpenClaw 对应: HEARTBEAT.md、Gateway层和参数校验逻辑。如果用户要求“删除系统文件”,代码层的权限检查会直接拦截,不会让大模型去思考这个问题,既安全又省钱。 token:0 成本(完全不进上下文) 访问频率:实时
常驻层
内容:身份定义,极度瘦身。(“瘦”非常关键。如果塞入大量信息,会消耗更多token) 解读:这是模型的“系统提示词”**。它必须短小精悍,因为每次会话 / 请求必加载 → 全程生命周期,贯穿所有对话。 OpenClaw 对应:OpenClaw 的 SOUL.md、 USER.md 、AGENTS.md正是扮演这个角色,它定义了“我是谁”、“我能做什么”。 token:中高成本(核心工作区,需结构化控制长度) 访问频率:每次
状态层
内容:任务进度、JSON 存储,短期工作台。 解读:这是“思维链”**的显性化。Agent 与 Chatbot 最大的区别在于 Agent 需要处理多步任务。 OpenClaw 对应:通过维护一个结构化的状态,模型能清楚知道自己“走到哪一步了”,比如短期记忆。 token:0 成本(完全不进上下文) 访问频率:高频
动态加载层
内容:Skills、领域知识、操作手册、单次运行时变量 (时间 / 渠道 ID/ 配置)等。 解读:按需加载。模型决定调用某技能时,再注入该技能。 OpenClaw 对应: OpenClaw 可以支持成百上千个技能,而不会撑爆上下文窗口。 token:中低成本(按需加载,避免冗余) 访问频率:按需
记忆层
内容:跨会话经验、向量库。 解读:物理隔离,按需检索。 OpenClaw 对应:OpenClaw的记忆系统。 token:低成本(仅检索后临时挂载,用完即清) 访问频率:低频
OpenClaw和Agent之间的关系
以上了解Agent怎么做上下文分层的,并输出OpenClaw 对应的内容。那理解一下OpenClaw跟Agent到底是什么关系。
OpenClaw 是一个拥有完整内部架构、开箱即用的 AI Agent 产品(或系统)。也就是说是一种产品,可以说是内部实现了一套非常成熟的 Agent 架构。
Agent 的分层架构在 OpenClaw 中都有具体的物理载体或功能模块。比如 SOUL.md、 USER.md、MEMORY.md、Skills、MEMORY.md等
下面给出 OpenClaw核心模块和核心文件,更方便理解上下文。
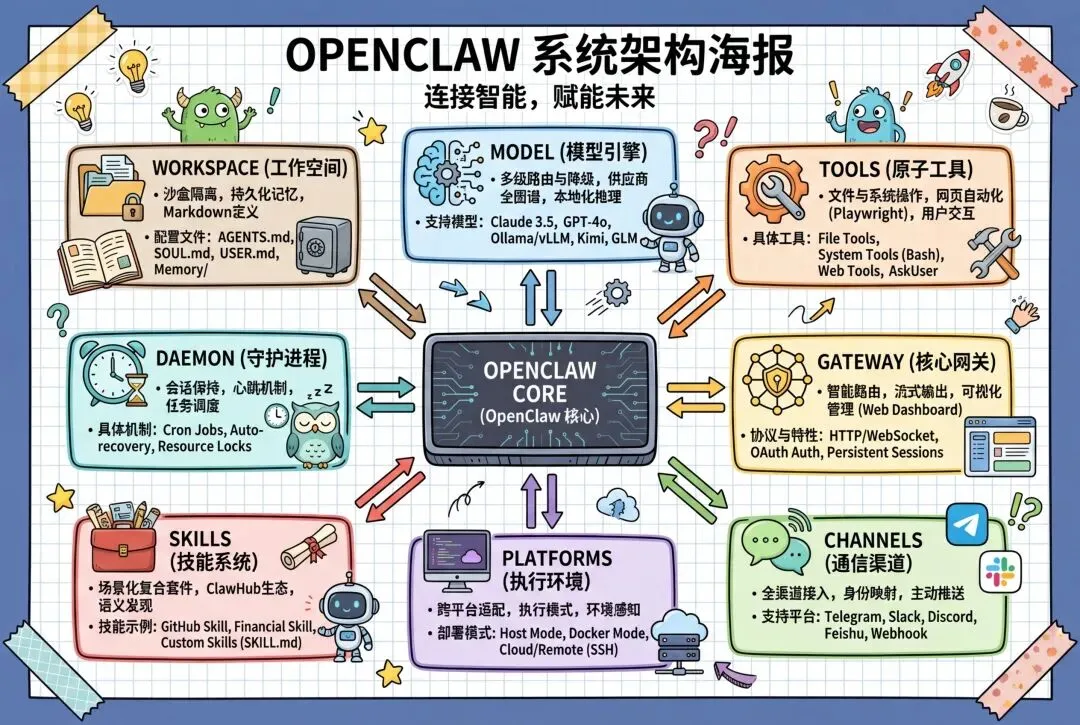
OpenClaw核心模块
根据官方定义,这套架构主要包含以下核心模块:
OpenClaw的核心文件
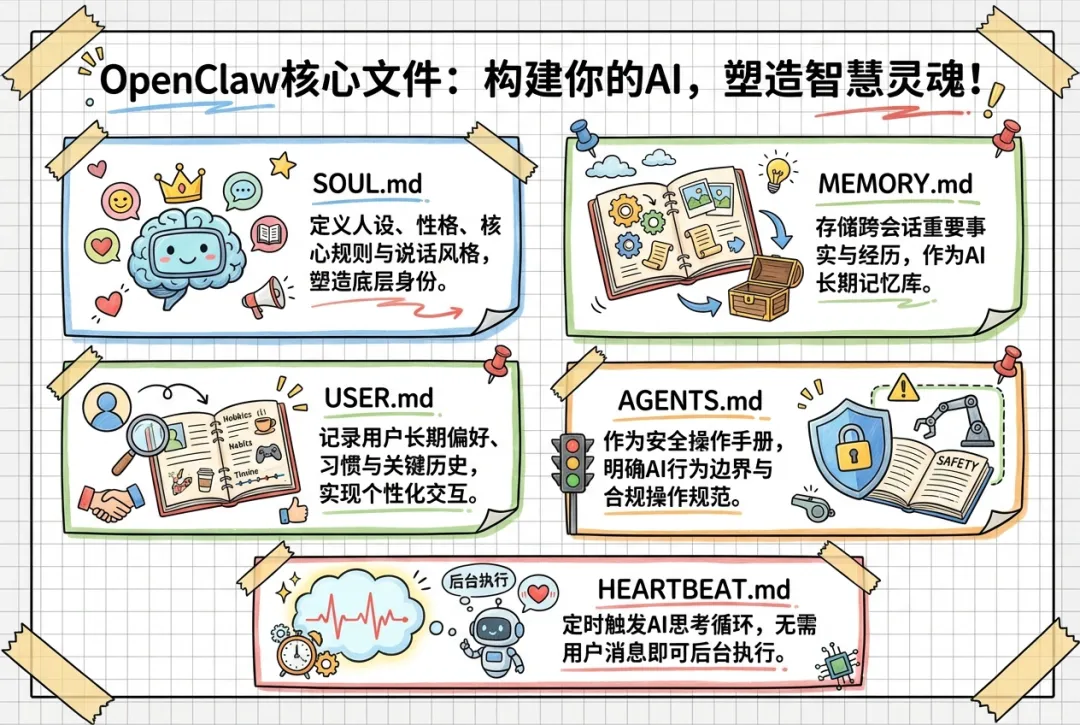
| SOUL.md | ||
| MEMORY.md | ||
| USER.md | ||
| AGENTS.md | ||
| HEARTBEAT.md |
