夜雨聆风
夜雨聆风见字如面,我是一臻 90后新手奶爸,探索Doris x AI
90后新手奶爸,探索Doris x AI
点击关注 👇 免费获取数智AI知识库
“凌晨时分,程序员阿杰正准备关机睡觉,开发者群里炸锅了:Hermes Agent 又叒叕上了 GitHub Trending 榜首,近百W 颗星,把 OpenClaw 挤到了第二。
"
不是,OpenClaw 我还没玩明白呢,这玩意儿又是哪冒出来的?"阿杰发了条消息。群里秒回:"别提了,我刚把 OpenClaw 的 Skill 系统配好,文档还没写完一半,Hermes 就把自进化技能树都做好了。"
这种焦虑感在自媒体和技术圈蔓延得特别快。才火了两个多月的 OpenClaw 被戏称为
龙虾,就这么被一个叫 Hermes的开源 Agent 项目抢了风头。社区叙事非常统一:Hermes 靠自进化、自动记忆和用户建模三大杀招,在技术上全面超越了前任王者。
但仔细把两个项目扒开对比后发现,实际情况远比这个叙事复杂。

开源Agent赛道的又一次碰撞
最近技术圈有个有意思的现象:OpenClaw这个项目才刚在用户群体里积累起流量,不到两个月就被另一个叫Hermes的新选手抢走了风头。
表面看这是一场技术迭代。
我倒觉得这是两个产品哲学的正面交锋。
这些个工具刚出来的时候,大家讨论的焦点还是能不能跑代码、能不能读文档、能不能自动化SOP...
到了今年,社区的核心议题已经变成了另一个问题:一个Agent到底应该替用户做多少决定?
这个问题听起来抽象,但它直接决定了你每天和AI协作时的体验。
01 两种路线
我观察到一个有意思的分化。
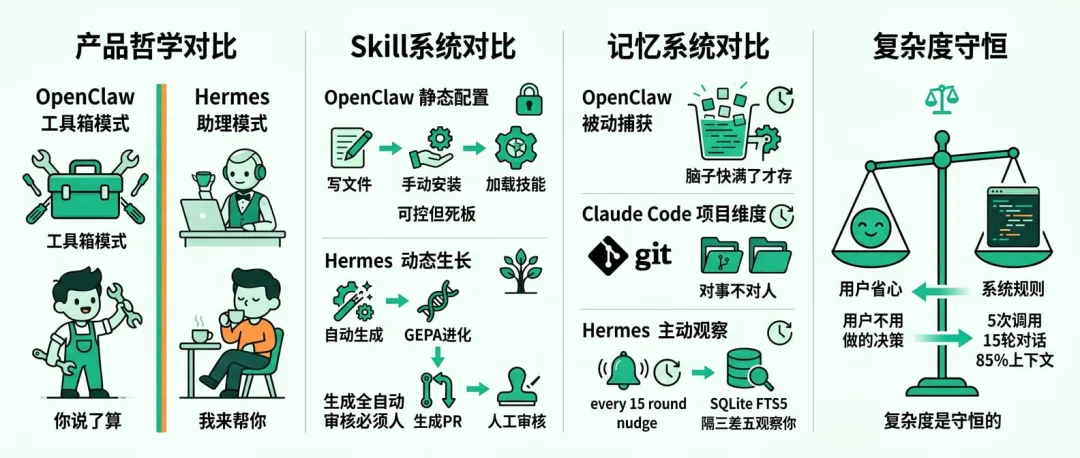
OpenClaw的设计逻辑偏向工具箱模式。
claw把能力做得很全——定时任务、子Agent委派、浏览器自动化、第三方平台集成,该有的全有。
但每一步操作都需要你明确授权:新Skill得手动安装,配置改完得重启进程,系统从来不会在没收到指令的情况下替你做决定。
Hermes走的是另一条路。
爱马仕在怎么让你少操心这件事上做了大量文章。
一个突出例子是它的Skill进化机制:你在使用过程中只要触发某些特定条件——比如某个工作流被重复执行超过五次,或者系统成功从错误中自我恢复——它会自动把这个流程打包存下来,下次遇到类似任务直接调用。
整个过程你完全不知情!
这种设计背后的理念差异挺有意思。
如果说OpenClaw是一个高度模块化的工具集,负责提供能力,怎么用是你说了算。
Hermes则更像一个总想替你做主的助理,它觉得这事我熟,我来。
哪种路线更好?
没有标准答案,取决于你的使用场景。
02 Skill系统的本质
Skill是这波Agent产品的标配,本质上就是一套工作流模板。
但同样是Skill,两个系统的运行机制完全不一样。
OpenClaw的Skill更接近静态配置。
你写好文件、手动触发安装、系统才会把这个技能加载进来。
整个过程是确定性的、可控的,但也很死板——你得主动维护它,它不会自己长。
Hermes的Skill则是一套动态生长体系。
它会在运行时自动生成新的Skill文件,然后用一套叫GEPA的进化算法定期优化这些Skill。
论文层面的支撑来自ICLR 2026的一篇Oral,证明用大模型的反思能力加进化算法,在某些任务上比传统强化学习路线样本效率更高。
关键在于,Hermes把这套进化做成了一个需要人类审核的流程。
它生成PR而不是直接提交,意思是我觉得这个技能挺好用的,你要不要批准一下。
这个设计值得琢磨——它承认了自动化进化可能产生垃圾,所以加了人工把关的环节。
这种生成全自动,审核必须人的模式,比社区吹的完全不用管要诚实得多?
03 记忆系统
你用Agent的时候,有没有这种感觉:用久了之后,它好像认识你了?
这背后的机制各不一样。
OpenClaw的记忆是触发式的。
当上下文快撑满、系统要做压缩之前,它会悄悄跑一个隐藏轮次,把这段对话里的关键信息存进长期文件。
这是一种被动式的信息捕获,等于是告诉你"我脑子快满了,先存一下"。
Claude Code的记忆更偏向项目维度。
它会主动记录构建命令、调试经验,但严格限定在当前git项目内。
你在这个项目里积累的经验,绝对不会带到另一个项目里去。边界感很强,对事不对人。
Hermes的逻辑不一样。
它设了一个叫nudge的机制,大概每十五轮对话就会强制触发一次反思,让Agent主动想想"这人有什么习惯值得记"。
触发频率远高于OpenClaw的被动式捕获。
更重要的是检索能力。
Hermes默认集成了SQLite FTS5全文检索,Agent可以随时翻找历史对话记录。
这比OpenClaw依赖的关键词搜索要实用得多。
所以实际体验的差异就很明显:OpenClaw是在快装不下的时候才想起认识你一下,Hermes是隔三差五就在暗中观察你、揣摩你。
04 复杂度守恒
聊到这里,有个底层规律值得点出来。
无论是Skill的自动进化还是记忆的高频捕获,Hermes本质上在做一件事:把本该由用户做的决策,全部转移到系统层面。
你不用手动维护Skill,不用想着什么时候该存档,不用担心上下文不够用——这些它都替你包了。
但复杂度是守恒的。
你省下的这些事,并没有凭空消失,而是被写进了Hermes的代码里,变成了一条条硬规则:工具调用满五次触发技能生成、对话满十五轮触发反思、上下文超过百分之八十五做字符串替换而不是智能摘要……
这套规则看起来保守,但有它的道理。
年初Chroma有做过测试,让大模型在多轮对话里自己管理上下文,性能平均下跌百分之三十九,严重的能跌百分之八十五。
同期的研究也指出,在超长上下文的场景下,死板的规则系统往往比让模型自由发挥要稳定。
Hermes的设计者显然清楚一件事:在模型能力还不够硬的时候,把决策权收回来比放出去更安全。
你觉得它替你省心,其实它是在替自己避雷。
结语
回头看当下Hermes和OpenClaw之争,表面上是在比谁的功能更全、谁的性能更强。
实际上它们在争一个问题:未来的AI Agent应该是什么形态?是完全受控的工具,还是主动替你做主的助理?
OpenClaw代表了前者。它把能力做扎实,把控制权交给你,用起来可能麻烦点,但每一步都透明可控。
Hermes代表了后者。它把复杂度藏进底层,让用户感觉越来越省心,但系统内部的规则也越来越重。
更有意思的是趋势。
OpenClaw正在加入更主动的记忆机制,Hermes却在v0.7版本里把记忆后端做成了可插拔的插件架构。
一个在补主动的课,一个在拆包揽的墙。
大家都在往中间走。
但Hermes更早、更激进地押注了"让用户少操心"这条路线。
它们赌的不是今天的技术有多成熟,而是谁能先在用户心里立住最懂你的标签。等市场认知稳定了,再慢慢补技术短板也不迟。
这种技术未到,生态先行的玩法,在AI产品圈已然不是第一次了。
上一个这么干的是Manus,再上一个是OpenClaw自己,现在轮到Hermes。
最后谁会赢?
现在说还太早。
但有一点可以确定:在这个赛道里,能让用户产生离不开感觉的那个,永远比技术参数最强的那个走得远?
⚠️ OpenClaw 和 Hermes 可以一起用。

完
👇欢迎扫描下方二维码 👇
备注 666 免费领取资料❗️