 夜雨聆风
夜雨聆风这是我的《读懂AI大模型底层DNA》系列第二篇文章。
上一篇,我们讲了Transformer架构的灵魂:注意力机制。我们以短句「我的家乡是青岛。」为例,一步步演算明白了:AI如何依靠Wq、Wk、Wv三个矩阵,计算词语之间的关联权重,明白一句简单的人话中的词的关联度。
不知道大家看完了之后会不会浮现一个问题:「我的家乡是青岛。」这句话里的文字,是怎么进入AI大脑的?
因为,我们都知道电脑看不懂汉字,更看不懂句子。在计算机底层,只有0和1。既然如此,“我”“家乡”“青岛”这些文字,最开始是以什么形态存在?AI又是如何区分“我爱青岛”和“青岛爱我”的语序差别,因为如果没有语序差别,这两句话可能就是一个意思。
这就引出了Transformer架构里,最基础、最容易被忽略,却绝对不可或缺的两大前置机制:词嵌入 + 位置编码。
如果把注意力机制比作AI的上下文理解,那词嵌入与位置编码,就是AI的视觉与记忆。它们共同构成了大模型的认知起点。
一、为什么必须要有这一层?AI天生存在两个致命缺陷
原生的Transformer神经网络,天生存在两个硬伤,不解决就永远无法理解人类语言。
1. 缺陷一:神经网络不认文字,只认数字
不管是汉字、英文、标点、表情符号,在计算机眼里全部是无效符号。神经网络只能进行矩阵乘法、向量运算。想要让AI处理语言,第一步必须把文字转化为数字。
2. 缺陷二:注意力机制天生没有顺序概念
自注意力机制是并行计算。一句话里所有Token同时输入、同时计算、全局互相扫描。它没有读取先后,没有时间线。
这就会出现一个荒诞的结果:在没有位置编码的情况下,对AI来说:
「我爱青岛」=「青岛爱我」
词语一模一样、向量一模一样、注意力分数一模一样。语序颠倒,在AI眼里完全没有区别。
一个不懂语序、不懂先后的模型,永远不可能学会人类语言。
3. 总结:两大机制分工明确
词嵌入:解决语义问题,把文字变成有含义的数字向量。
位置编码:解决语序问题,给文字打上顺序烙印。
二者叠加,AI才拥有最基础的能力:认得字、分得清先后。
二、词嵌入:把文字变成AI能读懂的语言
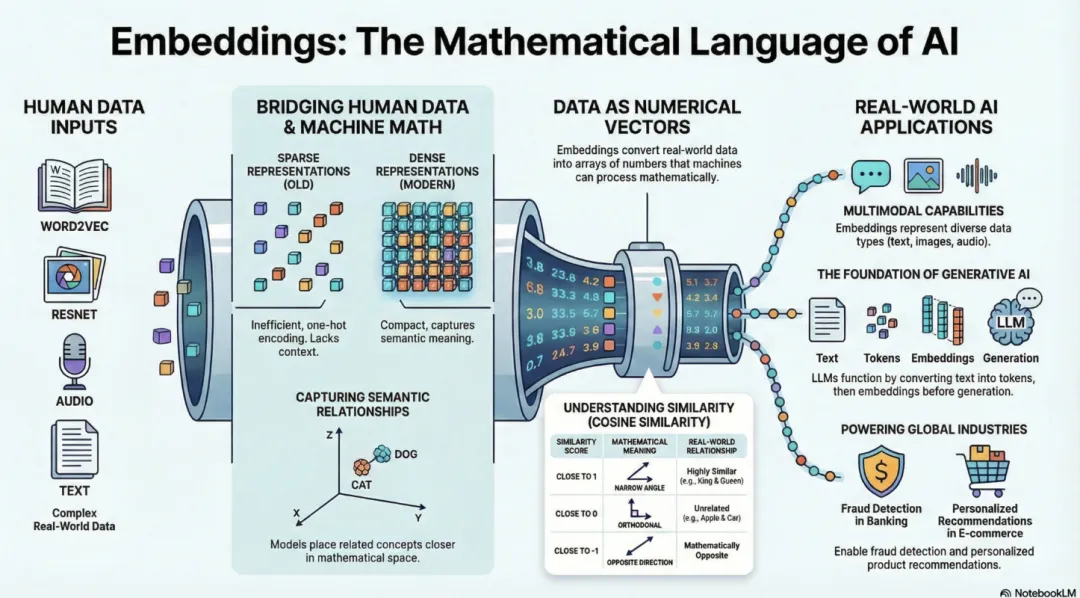
1. 通俗定义:文字的数字化翻译器
词嵌入(Embedding),直白解释就是:给每一个独一无二的Token,分配一条独一无二的数字向量。
在上一篇文章中,我给「我的家乡是青岛。」六个Token分配了简单二维向量。真实大模型不会这么简单。
给大家一组真实行业数据:
原版Transformer基础模型,词向量维度为512维;
主流开源模型Llama 3、Qwen,向量维度高达4096维。
维度越高,储存的语义信息越丰富,模型理解能力越强。
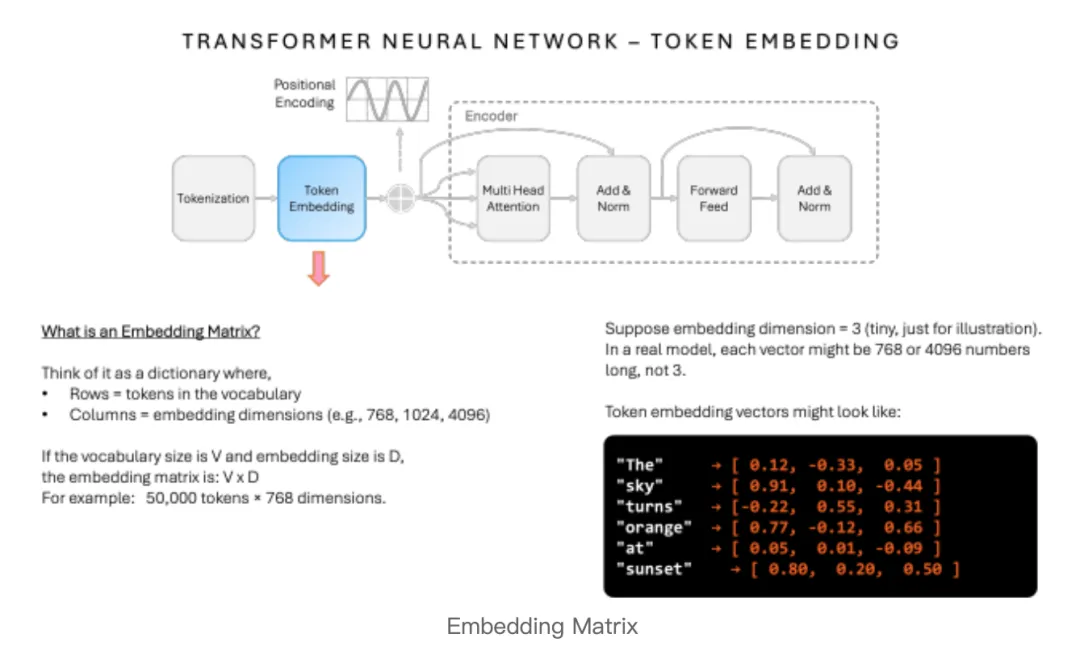
2. 它是怎么工作的?
你可以把词嵌入理解为一本AI专属词典。
词典里每一个汉字、虚词、标点,都对应一串长长的数字。
并且它遵循一个铁律:语义越相近,向量距离越近;语义越疏远,向量距离越远。
举个直观例子:
“青岛”和“海边”“大海”向量距离很近;
“青岛”和“桌子”“沙漠”向量距离很远。
不需要人类手动标注逻辑,模型在海量数据训练中,自发归纳出语义相似度,沉淀进词嵌入矩阵。
三、位置编码:给冰冷的向量赋予时间秩序
有了词嵌入,AI虽然认识字,但依然不懂语序。这时候,就必须引入位置编码(Positional Encoding)。
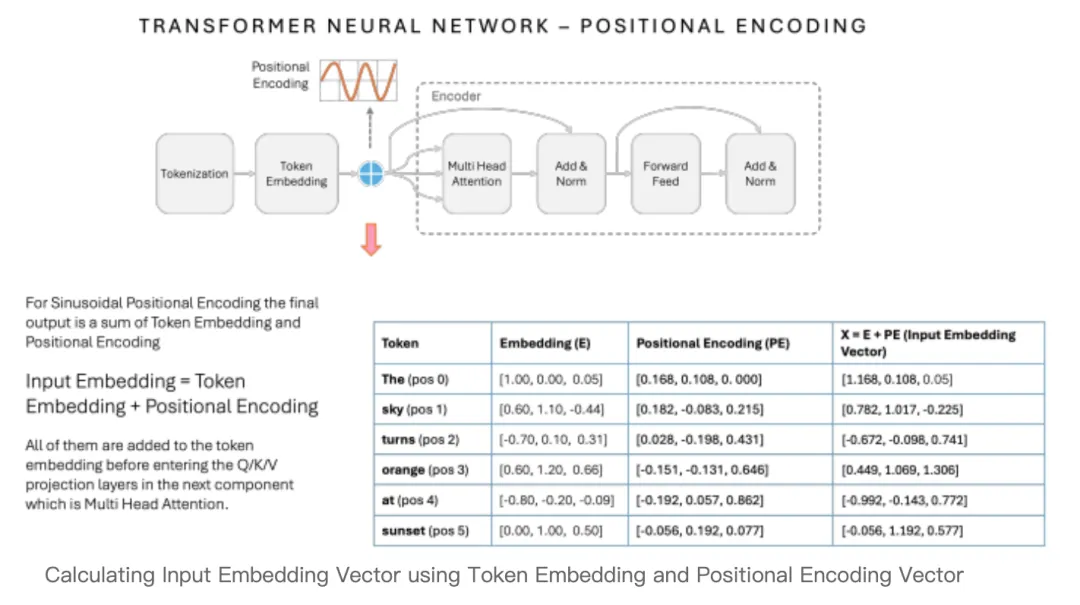
1. 通俗理解:给每个字发一张“排位号”
继续沿用我们的例句:「我的家乡是青岛。」
分词顺序固定为6个Token:【我、的、家乡、是、青岛、。】
位置编码会给每一个序号生成专属位置向量:
第1位「我」→ 专属位置向量A
第2位「的」→ 专属位置向量B
第3位「家乡」→ 专属位置向量C
哪怕同一个字,放在不同位置,位置向量完全不同。
2. 向量叠加:最终输入向量怎么来的?
我把公式的逻辑简化一下:
最终输入向量 = 词嵌入向量 + 位置编码向量
简单粗暴,直接相加。
叠加之后,每一个Token身上同时携带两份信息:
第一,我是什么字(语义);
第二,我在第几位(语序)。
3. 现代模型为什么都改用RoPE旋转位置编码?
原版Transformer使用三角函数位置编码,存在天然短板:上下文长度有限、远距离位置信息衰减。
如今市面上95%的主流大模型,包括Llama、Qwen、GPT系列,全部升级为RoPE旋转位置编码。
我用简单的语言粗略地描述一下RoPE旋转位置编码:
每个字本来有自己的语义向量,只藏含义,没有顺序; RoPE 不额外加向量、不做加法; 按照这个字在句子里的排位,给它的向量做角度旋转: 第一个Token,转一个很小的角度。 第二个Token,转的角度大一点。 越往后的字,旋转的角度越大。
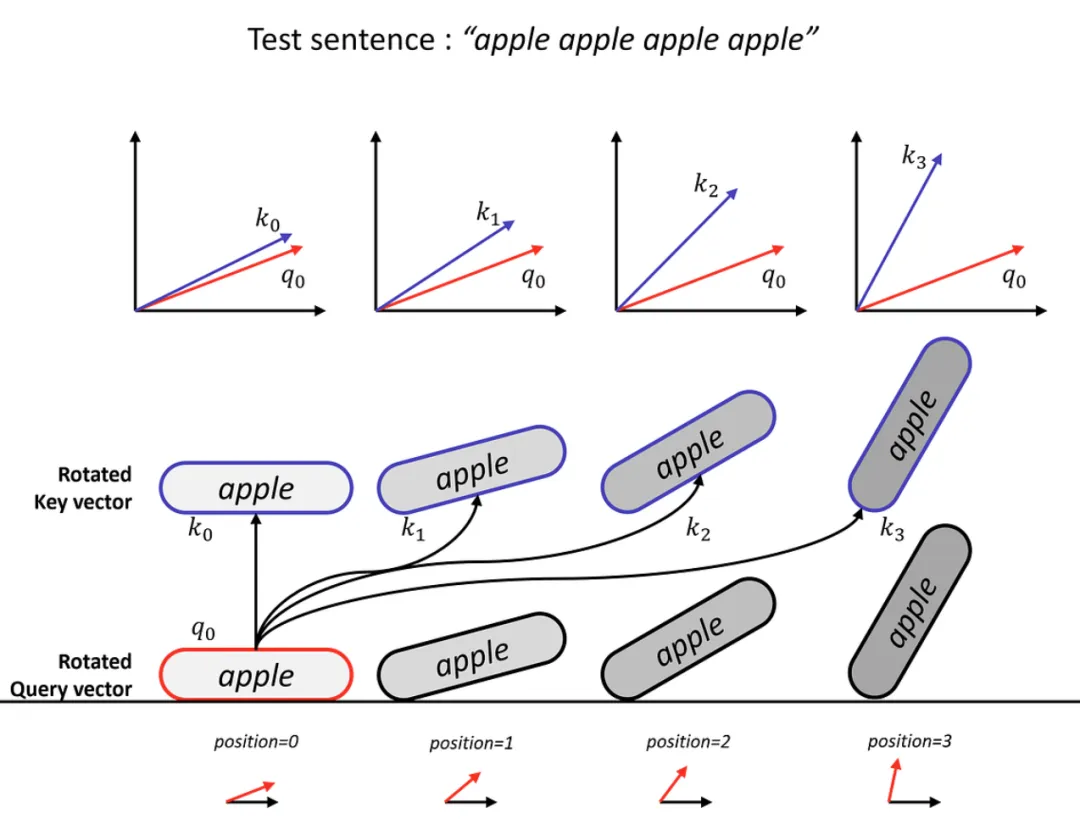
心优势只有两点:
① 把位置信息旋转融入向量,不占用额外空间;
② 天然支持无限长度上下文,长文本语序不混乱。
这也是现在大模型能轻松支持128K、200K超长上下文的底层原因。
四、一句话看懂完整输入流程
当我们输入:「我的家乡是青岛。」
AI内部严格执行四步流程:
第一步:分词,拆分为6个Token;
第二步:词嵌入,每个字生成语义向量;
第三步:位置编码,叠加顺序信息,区分前后;
第四步:送入注意力层,生成QKV矩阵,计算全局关联权重。
到此,一句话才算真正完整进入AI大脑。
五、不起眼,但不可缺少
词嵌入,让AI读懂含义;位置编码,让AI读懂秩序。
它们没有华丽的运算逻辑,没有复杂的权重分配,却是所有智能诞生的前置条件。
如果把注意力机制比作人的思考判断能力,那词嵌入就是人的词汇量,位置编码就是人的时间观。三者合一,才构成了大模型最基础的语言认知能力。
