 夜雨聆风
夜雨聆风北京时间今天凌晨,Google I/O 大会上,Sundar Pichai 在台上做了一件让全场安静了几秒的事。

他拿了一张白纸,在上面画了一个圈。然后对着旁边正在运行的 Gemini Omni 说:"把这张草稿变成一个玻璃建筑在沙漠中碎裂的慢镜头。"
几秒钟后,屏幕上出现了一段视频。不是简单的动画——玻璃碎片飞溅的轨迹符合真实的重力逻辑,阳光透过碎片折射的光斑在沙漠地面上移动,沙尘随着冲击波往外扩散。
Pichai 说了一句话我印象很深:"AI 正在从预测文字,变成模拟现实。"
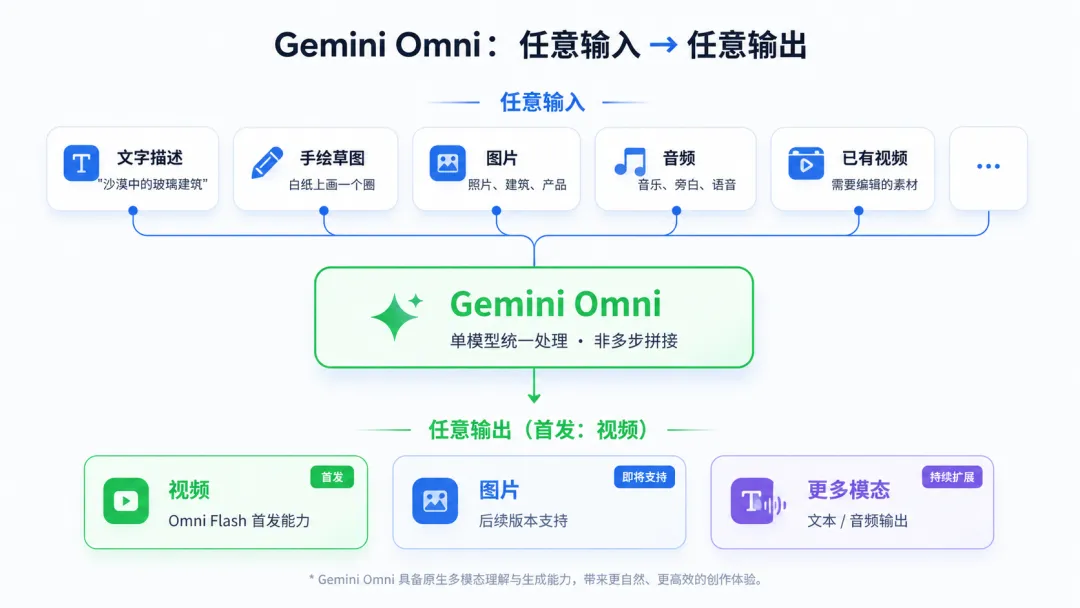
这就是 Gemini Omni。Google 今天凌晨发布的全新多模态模型,首发版本 Omni Flash 已经上线。
丨 它不是聊天AI,是一个"世界模拟器"
先说清楚它是什么。Gemini Omni 的定位不是"更强的 ChatGPT",而是"世界模型"(World Model)。
聊天 AI 做的事情是预测下一个 token——你说上句,它猜下句。世界模型做的事情是模拟物理现实——它理解重力是什么、光是怎么反射的、水是怎么流动的、物体碰撞之后会怎样。

1. 它没有"先画图再合成视频"的中间步骤。
之前的多模态 AI 生成视频,流程是这样的:文本 → 生成图片 → 图片 → 生成视频。每一步是一个独立模型拼在一起。Omni 不是。它是单个神经网络,在一个前向传播里同时理解文本、图像、音频、视频,然后直接输出。输入和输出都是原生的,不需要中间翻译。这也是 Google 强调它是第一个"真正的原生多模态模型"的原因。
2. 它真的懂一点物理。
这不是我说的,是发布会上展示出来的。用户上传一张沙漠中的玻璃建筑图片,要求"换成肥皂泡"。Omni 输出的视频里,肥皂泡有真实的表面张力效果、光线折射在气泡表面流动、气泡飘浮的路径符合空气动力学。这些不是工程师一条一条写出来的规则,是模型从训练数据中学到的对物理世界的理解。Google 管这个叫"直觉物理"(Intuitive Physics)。
3. "任意输入、任意输出"确实是它的核心定义。
你给它一段音乐加一张图片,它给你生成 MV。你给它一张建筑照片加一段旁白,它给你生成带解说的纪录片片段。你给它一段已有的视频,说"把主角的衣服换成红色的,背景换成雪地",它能做到,而且不破坏画面里其他物体的空间位置关系。这种跨模态的理解和生成能力,之前的模型做不到。
丨 它的杀手锏:用大白话就能"导演"视频
Google 管这个叫"对话式编辑"(Conversational Editing)。说人话就是:你像一个导演那样,用嘴说就行。
1. 传统流程 vs Omni 流程。
传统视频制作:写脚本 → 拍摄/找素材 → 剪辑 → 调色 → 加特效 → 渲染。每一步需要专业软件和技能,做一条像样的视频少说几天。
Omni 的流程:说一段话 → 拿到视频 → 不满意就继续说 → 它继续改。所有修改在同一个对话窗口里完成,不需要打开任何剪辑软件。
2. 关键是"指令持久化"。
你改完衣服颜色之后,之前设好的海边背景不会丢。你换完镜头角度之后,主角的脸和你第一版保持一致。Google 管这个叫"指令持久化"——模型能记住你之前的所有要求,不会改一个丢一个。这个东西听起来简单,在视频生成里做到是很难的。
3. 目前能做什么、不能做什么。
先说限制:当前 Omni Flash 生成的是 10 秒视频。不是"电影级"的——分辨率、时长、精细度都还有限。它也不能编辑已有视频里的音频/人声(Google 说安全措施还没到位,后续放开)。
但它能做的是:让一个不会画画、不会剪辑、没有设备的人,把自己脑子里的画面变成一段能动的视频。这个变化的意义,比视频长度重要得多。

丨 跟你有关系:视频创作的门槛消失了
这不是一句口号。Omni Flash 今天已经在 Gemini App 和 YouTube Shorts 上线了。YouTube Shorts 用户本周起免费使用,不需要任何付费订阅。
以前你想做一个产品宣传视频,需要找摄影师拍素材,找剪辑师处理,来回沟通、等反馈、拿成片,少说几天、几百块起步。以后可能变成:打开 Gemini App,打字描述你的产品,说"背景用浅色、节奏快一点、加上 logo",拿到视频。时间单位从天变成分钟。
更值得注意的是一组配套动作。Google 同时把 AI Ultra 订阅从 250 美元降到了 200 美元,新推出了 100 美元的开发者专属计划。还把 Gemini 3.5 Flash 设成了 Gemini App 的默认模型——速度快四倍、成本降到一半。翻译一下:Google 正在用更低的价格、更快的模型、更广的入口,把更多人拉进它的 AI 生态里。
所有 Omni 生成的视频都嵌入了 SynthID 水印。这个水印肉眼看不见,但用工具能检测出来。你拿去用没问题,想冒充真实拍摄就藏不住。Google、OpenAI、ElevenLabs 都在用这个标准,大概率会成为行业配置。
这次 Google I/O 还发布了 Gemini Spark(能自己订机票管邮件的 AI 智能体)、Gemini 3.5 Flash(更快更省)、还有一副内置 Gemini 的智能眼镜。但最让我记住的,还是那张白纸上的圆圈。
不是因为画面多震撼——10 秒视频跟电影还差得远。是因为那个圆圈代表的东西:以后你脑子里有一个画面,不需要会任何技能,说句话就能让它动起来。
Pichai 那句话说得对。AI 正在从预测文字变成模拟现实。不一样的不是技术参数,是你和 AI 打交道的方式——从"我问你答",变成了"我说你做"。
— END —
帮你打破AI信息差的人。不写论文,不卖课,只讲你用得上、听得懂的AI干货。
信息来源:Google I/O 2026 官方发布 · TechCrunch · VentureBeat · 36氪 · Google 官方博客 #GeminiOmni#GoogleIO#AI视频#世界模型#AI速览
