夜雨聆风
夜雨聆风67.5k 星,185 次提交,核心逻辑只有 74 行 Markdown。实测能把 Claude 的输出从 1214 token 压到 294 token——不是让 AI 变蠢,是让它学会闭嘴说重点。省几百块 token 费只是小头,真正省的是你读回复的时间。
上个月看 Claude Code 的 API 账单,200 多刀。
不多。但翻了一下对话记录,有句话跳出来特别刺眼
"Let me explain the root cause of this issue in detail and provide several possible solutions. First, we need to understand React's rendering mechanism..."
这 40 个字,值 2 毛钱。而同一个问题,caveman 模式的回答是四个词。值 3 分钱。
67.5k 人给它点了星,不是没道理。
这是什么
caveman,一个 Claude Code skill。叫插件也行、扩展也行、工具也行——怎么叫不重要。
重要的事一句话:让 AI 像穴居人一样说话。砍掉 65%-75% 的输出 token。
Star: 67.5k | Fork: 3.8k | License: MIT | Commits: 185 语言: JavaScript 63%, Python 28%, PowerShell 5%, Shell 5%
作者 Julius Brussee,2026 年 4 月 4 号创建。两个月,67.5k 星,27 个贡献者,14 个 release,最新 v1.8.2。
它不只是 Claude Code 能用——30+ 个 AI coding agent 全支持:Codex、Gemini、Cursor、Windsurf、Cline、Copilot。一个安装脚本全覆盖。
它到底省了多少
先看一个真实的例子。
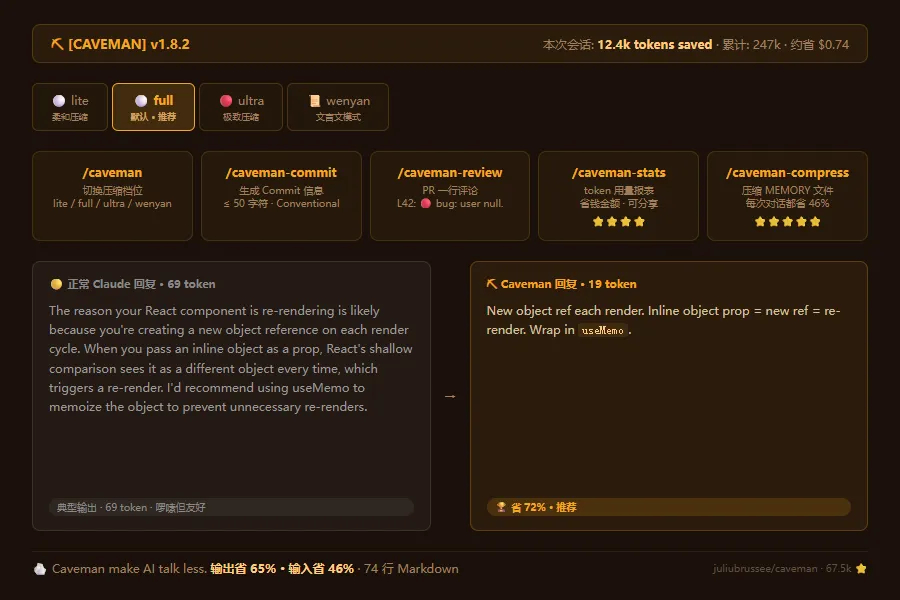
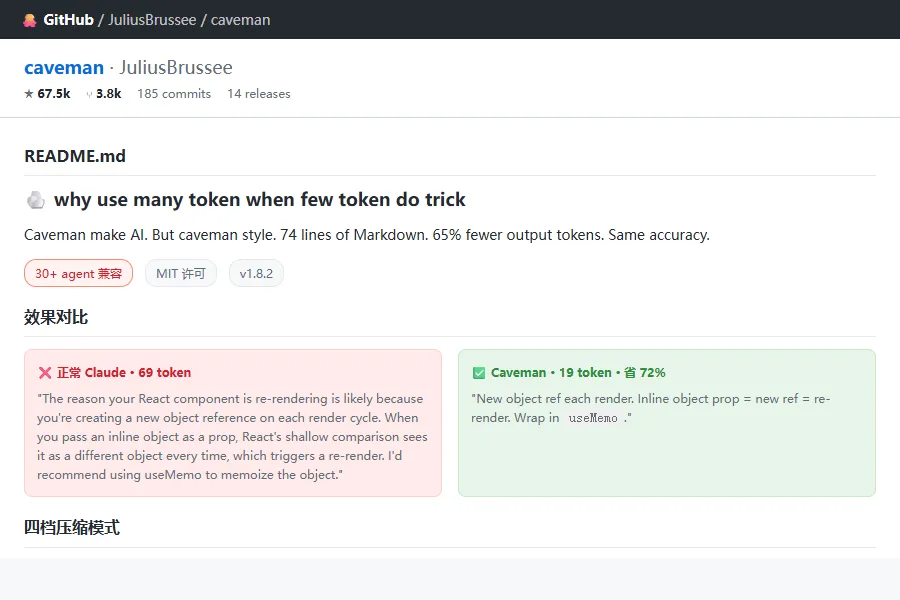
正常 Claude(69 token):
"The reason your React component is re-rendering is likely because you're creating a new object reference on each render cycle. When you pass an inline object as a prop, React's shallow comparison sees it as a different object every time, which triggers a re-render. I'd recommend using useMemo to memoize the object."
Caveman 模式(19 token):
"New object ref each render. Inline object prop = new ref = re-render. Wrap in useMemo."
同样的技术建议。69 token 变 19 token。省了 72%。
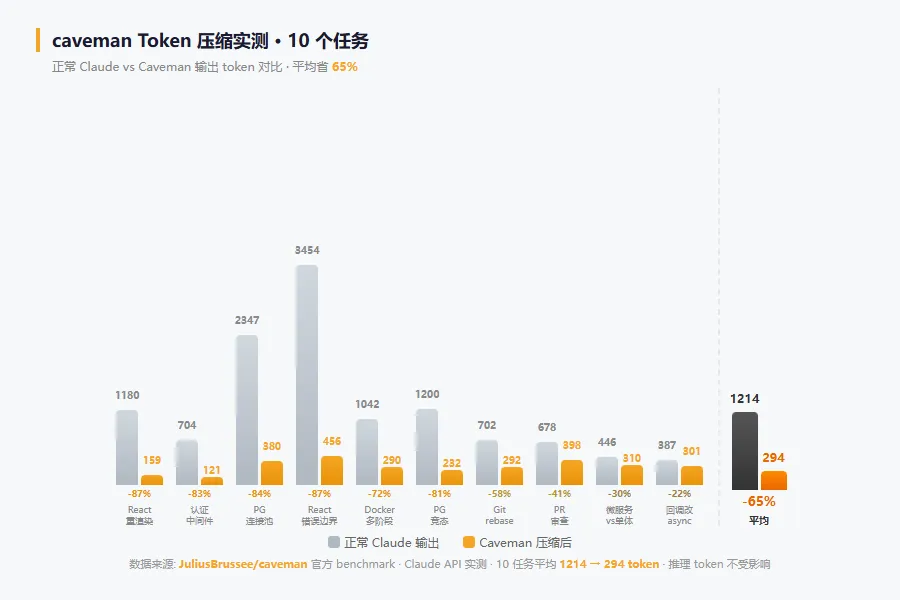
再来看官方 benchmark——10 个实际任务,通过 Claude API 统计的真实 token 数:
任务 | 正常 | Caveman | 省 |
React 重渲染解释 | 1180 | 159 | 87% |
认证中间件修复 | 704 | 121 | 83% |
PostgreSQL 连接池 | 2347 | 380 | 84% |
React 错误边界实现 | 3454 | 456 | 87% |
Docker 多阶段构建 | 1042 | 290 | 72% |
PostgreSQL 竞态调试 | 1200 | 232 | 81% |
Git rebase vs merge | 702 | 292 | 58% |
PR 安全审查 | 678 | 398 | 41% |
微服务 vs 单体架构 | 446 | 310 | 30% |
回调改 async/await | 387 | 301 | 22% |
平均 | 1214 | 294 | 65% |
两头看看。
最高省 87%——React 入门解释、中间件修复、错误边界实现。这类"让我帮你理解"型的回答,caveman 一刀砍掉所有铺垫。
最低省 22%——代码重构(回调改 async/await)。废话本来就不多,diff 本身就是精简的。caveman 不是魔法,能砍的只有废话。
顺便说一个容易被忽略的细节:caveman 只压缩输出 token。思考/推理部分原封不动。AI 的脑子一样聪明,只是嘴变小了。
我装了一遍,踩了两个坑
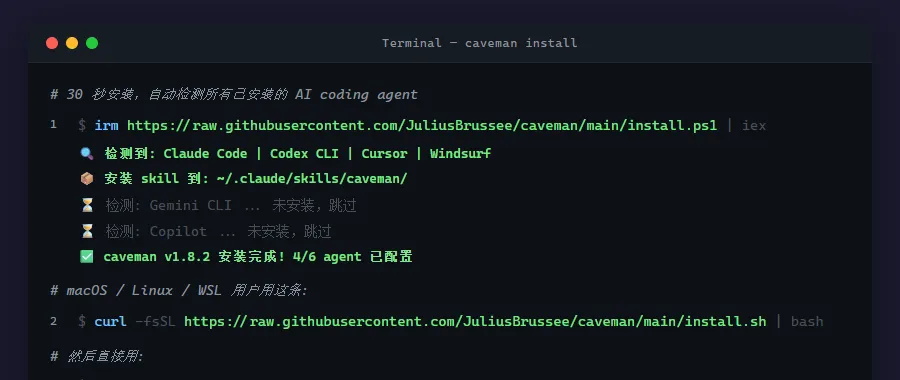
拿到项目第一件事当然是装。官网说一行命令 30 秒搞定。
坑 1:Windows PowerShell 上翻车了。
irm https://raw.githubusercontent.com/JuliusBrussee/caveman/main/install.ps1 | iex
在 PowerShell 5.1 上直接报错:VariableNotWritableRare。$Args 变量不可写——这是 PS 5.1 的已知问题,iex 在某些配置下无法处理远程脚本的变量赋值。
手动下载 ZIP,解压到项目目录,2 分钟搞定。Windows 用户遇到同样的问题,直接用 npx 或者手动下载,别跟一行命令死磕。
坑 2:打开 SKILL.md 的那一刻,我愣了几秒。
我以为会看到一个压缩算法。几百行正则、tokenizer 逻辑、或者至少是一个微调过的模型。
打开 skills/caveman/SKILL.md——74 行 Markdown。
67.5k 星的项目,核心就是一个系统提示词。写得像穴居人张嘴,精准得像外科手术。不是 joke。
74 行 Markdown,省 75% 的废话。少即是多这四个字,写在 GitHub 文件里比写在哪都狠。
五个子命令,两个让我意外的好东西
caveman 不是一个"开/关"按钮。它有一个完整的 skill 生态:
子命令 | 干什么 | 实用度 |
/caveman [lite|full|ultra|wenyan] | 切换压缩档位 | 5/5 |
/caveman-commit | 生成 Conventional Commit,<=50字符 | 3/5 |
/caveman-review | PR 评论一行流:L42: bug: user null. | 3/5 |
/caveman-stats | 当前会话 token 用量 + 累计省钱 | 4/5 |
/caveman-compress | MEMORY 文件压成 caveman 语 | 5/5 |
说两个让我意外的功能。
文言文模式(wenyan)。
caveman 的 wenyan 档是我觉得整个项目最聪明的一个设计。
文言文天然就是 token 压缩语言——主语省略、虚词精简、单字成词。古人写信就是 caveman。而这个模式也分 lite/full/ultra 三档。中文用户独享一个体验维度,别的语言没有。
caveman-compress:不只是单次省 token。
这个功能可以把你项目里的 CLAUDE.md、项目笔记这类 MEMORY 文件也压成 caveman 语。官方实测:
文件 | 原始 token | 压缩后 | 省 |
claude-md-preferences | 706 | 285 | 60% |
project-notes | 1145 | 535 | 53% |
claude-md-project | 1122 | 636 | 43% |
todo-list | 627 | 388 | 38% |
mixed-with-code | 888 | 560 | 37% |
平均 | 898 | 481 | 46% |
输出省 65%,输入省 46%。这意味着每次对话启动时,你的系统提示词就是压缩过的。不是省一次,是每次对话都省。叠加起来,一个月的账单降幅比单次 benchmark 更大。
AI 行业得了啰嗦病
AI 的啰嗦不是能力问题,是指令问题。
Claude 说"Let me explain this in detail",GPT 说"当然,我很乐意帮助你",Gemini 说"I understand your concern and I'll address it step by step"。每个字都是 token,每个 token 都要钱。而 90% 的开场白,用户脑子里已经自动 skip 了。
OpenAI 和 Anthropic 自己为什么不解决这个问题?因为他们的训练目标是"像人",不是"高效"。用大量礼貌用语和解释性铺垫来降低 AI 的机械感。友好感越强,token 用得越多——这是一场零和对冲。
caveman 用 74 行 Markdown 解决了这个问题,说明一个尴尬的事实:你只需要告诉 AI "别废话",它就真的不废话了。大厂不是做不到,是不愿意牺牲"拟人感"。
更有意思的是:根据 README 引用的 2026 年 3 月论文 "Brevity Constraints Reverse Performance Hierarchies in Language Models"——强制大模型以简洁方式回答,在某些 benchmark 上准确率反而提升了 26 个点。
少说。更快。更准。更便宜。
适合谁,不适合谁
适合:
每天用 Claude Code / Codex / Gemini 超过 2 小时的。省的不只是 token 费,是读回复的时间——每次回复短了 3/4,扫一眼就懂
中文用户——wenyan 文言文模式独一无二
接入了 30+ 个 agent 还嫌 AI 话多的
不适合:
主要工作是改代码而非问问题的。代码 diff 本身不废话,caveman 收益 22% 左右
需要 AI 写文档、写方案、面向人类阅读的场景。这时候"废话"是修辞,不是浪费
觉得 AI 的友善语气是核心体验的
caveman 的 README 最后一句话:"Caveman save you token, save you money. Star cost zero. Fair trade."
一个 74 行 Markdown 的项目,两个月 67.5k 星。不是因为技术多复杂——是因为它戳中了一个每个人都在忍的痛点,然后把解法做得只剩一块石头。
装一个试试,不行就关掉。
每天一个开源瓜,写代码就像开挂