 夜雨聆风
夜雨聆风本文结合NVIDIA在AI数据中心建设方面的最新趋势,尝试对上述问题进行回应。
从宏观主题来看,AI集群的建设正推动从单一芯片到数据中心、乃至整个电力架构的全栈式一体化革新。关注芯片选型的读者可参见上一篇内容企业买不到/不能买NV,那布局什么国产AI芯片才好?
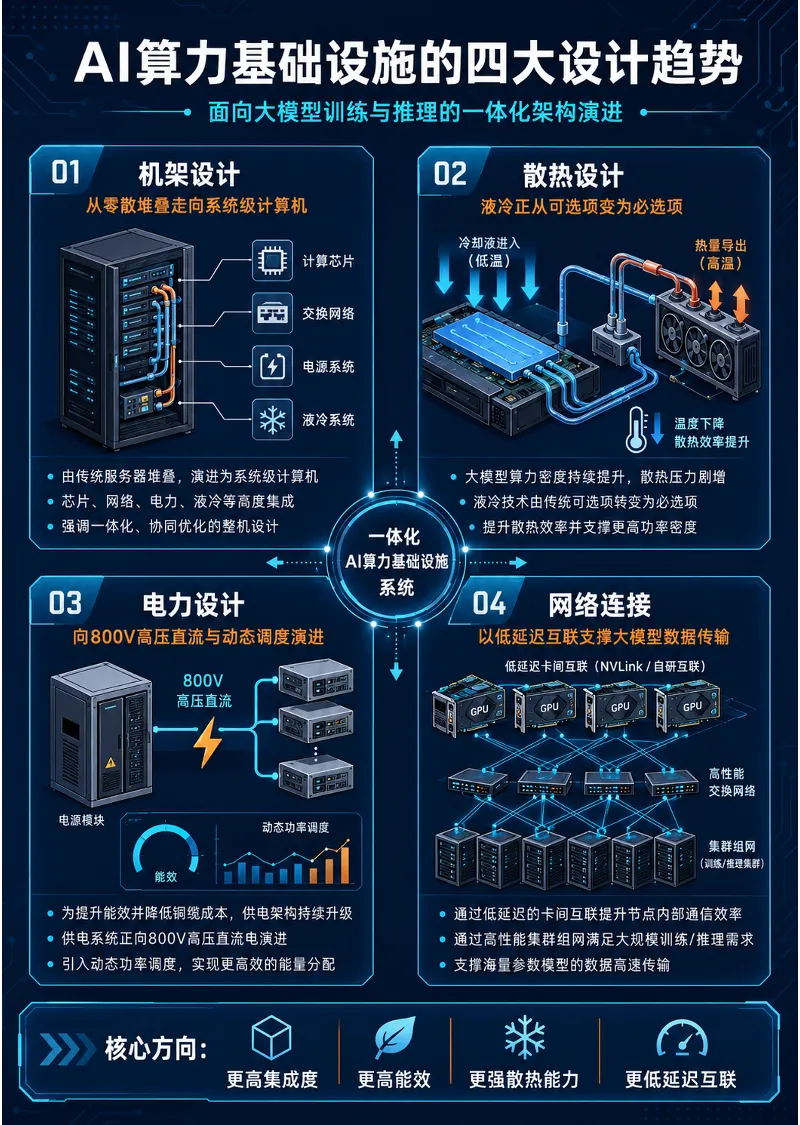
核心观点:
- 机架设计:正从零散的服务器堆叠转向系统级计算机,强调芯片、网络、电力、液冷等的高度集成的一体化设计。
- 散热设计:为应对巨大的散热压力,液冷技术已由传统的可选项转变为必选项。
- 电力设计:为提升能效并降低铜缆成本,供电系统正向800V高压直流电和动态功率调度演进。
- 网络连接:通过低延迟的卡间互联与高性能的集群组网,满足大模型训练/推理对数据传输的需求。
详细对比:
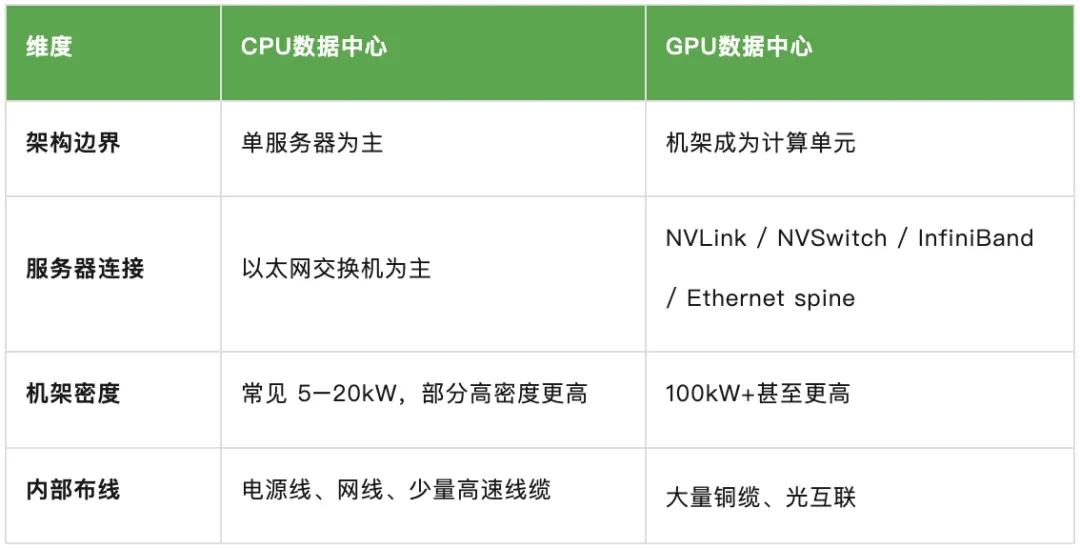
1.机架设计:机架从“放服务器”变成“一个系统级计算机”
传统 CPU 机架:服务器按 1U/2U/4U 堆叠
每台服务器相对独立 主要通过以太网交换机互联 PCIe 扩展、存储、网卡等都在单机架范围内 机架更多是服务器的“物理承载单元”
AI/GPU 机架:一个AI 机架开始好似一个大容量的系统级计算机
“Integrating 72 NVIDIA Rubin GPUs and 36 NVIDIA Vera CPUs connected through a massive NVLink copper spine, it acts as a one giant GPU.”
领先设计不再是“买 GPU 插到服务器里”,而是从芯片、服务器、机架、网络、供电、液冷、运维软件一体化设计 卡间互联不再局限在单服务器内,而是跨整个机架 机架级 NVLink / NVSwitch 让 72 GPU、144 GPU 甚至 576 GPU 像一个“大 GPU” 机架内部需要铜缆spine、光纤、PCB midplane、液冷分水器/快速接头、电容储能等复杂结构
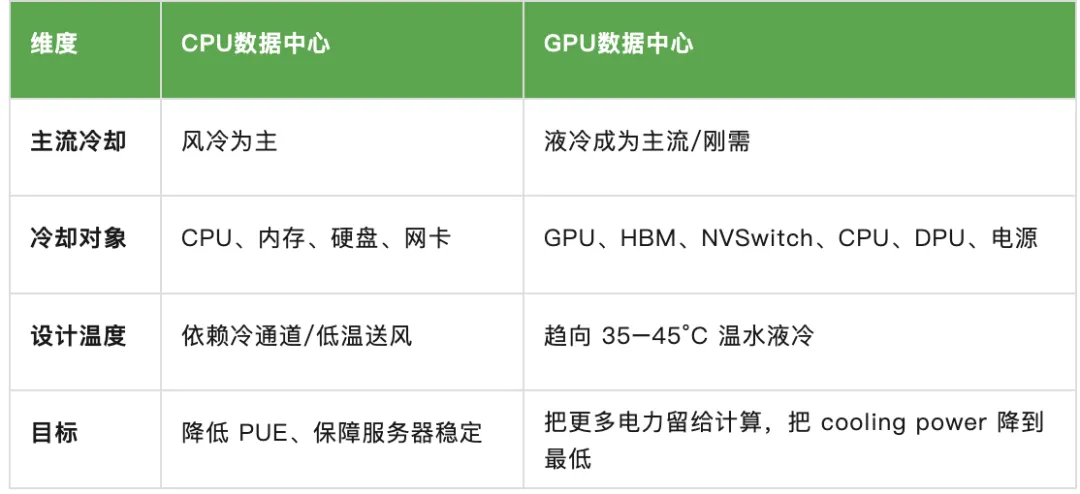
2.液冷设计:从“高密度可选项”变成“AI 集群必选项”
传统 CPU 数据中心:长期以风冷为主
液冷多用于 HPC、超算、高密度场景 单机功耗相对可控,风冷可覆盖大多数需求
AI 芯片数据中心:GPU/AI 加速卡功耗快速提升,风冷难支撑
单 GPU 功耗可达数百瓦到上千瓦 整机 8卡、16卡、72卡、144卡导致机架热密度极高 向 100% liquid-cooled rack发展 高温温水液冷成为新趋势,用更高水温降低压缩机制冷依赖,提升可用电力比例
“All MGX racks are universally designed to operate with 45°C (113°F) warm-water inlet temperatures so data centers already designed for liquid cooling are guaranteed a seamless transition without redesigning cooling infrastructure.”
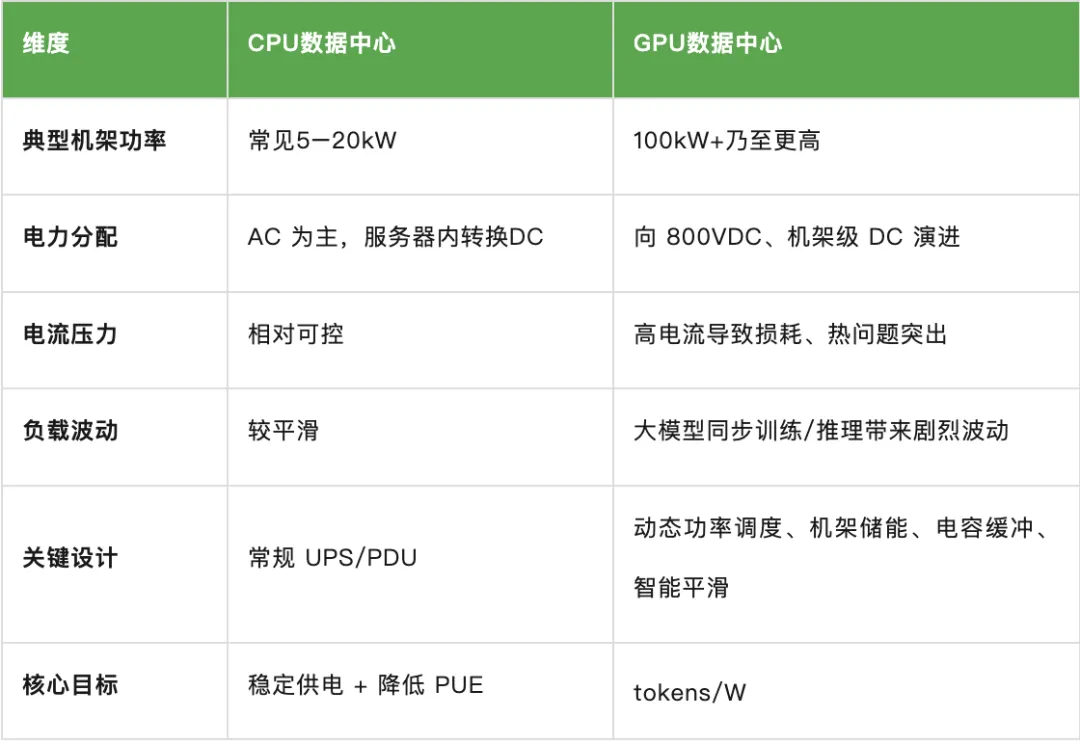
3.电力设计:AI 数据中心从AC/低压DC走向 800VDC、高功率和动态功率调度
传统 CPU 数据中心
市电 AC → UPS → PDU → 机柜 PDU; 服务器内部 AC/DC 转换;48V DC为主 机架功率相对较低,配电系统可按相对稳定负载规划; 电力波动相对平滑
AI/GPU 数据中心
同步负载大:大量 GPU 同时启动计算,功率波动剧烈 机架功率极高:高密度 GPU rack 对电流、铜排、线缆、转换效率形成压力
所以领先设计开始强调:
机架级储能/功率平滑:为了防止功率波动,可通过电容器缓冲功率瞬变。当工作负载一次需要大量电力时,电容器将提供额外的电力,而电网的电力消耗保持平稳或上升。当工作负载突然停止时,电容器将充电,而电网功率保持平稳或下降 800VDC:是实现未来~600kW机架的关键之一,高功率机架提升密度,密度是降低每 token成本的关键路径。具体原因:
随着未来两年机架密度接近600kW 以上(i.e.NVIDIA Kyber Ultra),当前48V的方案问题开始暴露:
- 铜变得难以管理。 一个1MW 机架在48VDC 下需要约200公斤铜母线,成本、重量、安装复杂度和布线空间都成为沉重负担。
- 电源挤占计算空间。 今天的 NVL72机架已经使用多达8个电源架。在 Kyber 级别的机架功率下,48V 方案需要约64U 当量的电源硬件,几乎相当于整个机架,那么就没有空间留给计算设备。
- 电流成为真正的限制因素。 提供600kW 功率在48V 下意味着约12,500A 电流。在800V 下,这降至约750A,使母线大幅缩小。如果保持导体电阻不变,I²R 损耗下降约278倍,因此可以缩小铜的用量。
- 转换损耗累积、损害可靠性。 堆叠的 AC-to-DC 和 DC-to-DC 级降低端到端效率,增加热量,引入故障点,提高冷却负载、停机风
险和维护成本。
4.网络连接:AI 数据中心对互联的要求远高于 CPU 数据中心
传统 CPU 网络
north-south 流量:用户请求、业务访问 east-west 流量:微服务、数据库、存储、虚拟机迁移 网络通常以以太网为主,100G/200G/400G 逐步升级
AI/GPU 网络
AI 集群的网络分为两层:
Scale-up:卡间互联 NVLink、NVSwitch、HCCS、ICN、MetaXLink 等 关键是低延迟、高带宽、collective 通信效率 Scale-out:机架间、Pod 间、数据中心间互联 InfiniBand、RoCE、Spectrum-X Ethernet、CPO 光互联; 满足All-Reduce(大模型训练中收集数据再发回)、All-to-All(在大模型训练中的混合并行策略里至关重要,在不同节点间重新分布数据块)、KV cache、存储流量等的要求
资料来源:
1.NVIDIA Technical Blog
https://developer.nvidia.com/blog/nvidia-vera-rubin-pod-seven-chips-five-rack-scale-systems-one-ai-supercomputer/
https://www.nvidia.com/en-us/data-center/technologies/800-vdc-architecture/
2.SemiAnalysis: Inside the 800VDC Revolution
https://newsletter.semianalysis.com/p/inside-the-800vdc-revolution-part
