 夜雨聆风
夜雨聆风





告别晦涩!神经网络与Word2Vec,NLP入门核心
01NLP的难点
-
第一文本词汇量多,每个单词都是一个特征,类别也很多。
-
第二语义信息丰富,各种同义词、近义词等。
-
第三语言的差异性,比如中文要做分词,但英语天然是空格隔开的没有分词的概念,英语有时态的概念,完成时、进行时,中文没有时态,各种语言的差异比较大。
02贝叶斯公式/语言的马尔可夫性
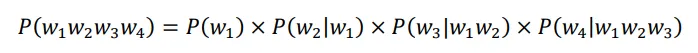
对于词语来说做一个简化,每个词出现的概率只和他前面的有关。比如说W2只和W1有关,W3只和W2有关,W4只和W3有关,概率的这种简化叫做一阶马尔克夫,一阶马尔克夫就说只跟前面那个有关。隔代遗传就是二阶、三阶。
贝叶斯公式对任何场景都适用,但马尔可夫性有特定的适用场景。对语言来说,用马尔可夫信进行一个简化。当出现W1的时候,W2出现的概率接近于1,比如葡萄、鸳鸯,只要出现一个,它基本上就是成对出现,所以说语言它其实是具备一阶马尔可夫性。
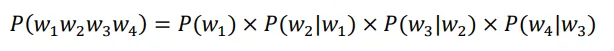
两个词,先统计W1出现的次数N,W1出现之后紧接着W1W2出现的次数M,那么P(W2/W1)的概率为:
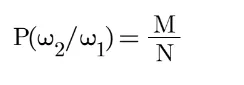

通过这种方式来计算概率,任何一个语言都可以把概率给算出来,但这个算法有很大的问题。
-
第一个问题:比如二阶马尔可夫,中文有5万常用词汇,两两之间出现的概率要预测5万×5万=25亿,肯定是统计不过来的,很有可能两个词在有限的数据里,根本就没有挨着出现过,但并不是它们真的没有出现,只是数据量不够大,没有把这个问题给暴露出来。因为数据量的原因漏掉很多。
-
第二个问题:没有考虑语义相似度。计算机、电脑、computer这三个其实是一回事, 但统计的时候会把这三个当成三个不同的词来做,这样会导致语义的概率整体偏低,一个词的表述方式越多就越稀释,它的概率会变得特别低,这是直接统计最大的问题。
03多分类的神经网络和NLP的结合
对于二阶马尔可夫,通过两个词预测下一个词是什么,它其实是一个多分类,通过W1,W2预测下个W等于什么,这就是多分类。类别数就是词数,预测下一个词的概率就变成了一个多分类的概率。有5万个词,那么就是5万分类。 多分类如何设计神经网络。
假设5万个词从0到4999编号,输入一个5万维的向量,这个向量是one hot,一个向量来表示一个词,比如说000100,第四个词的时候为1,其他的都为0。
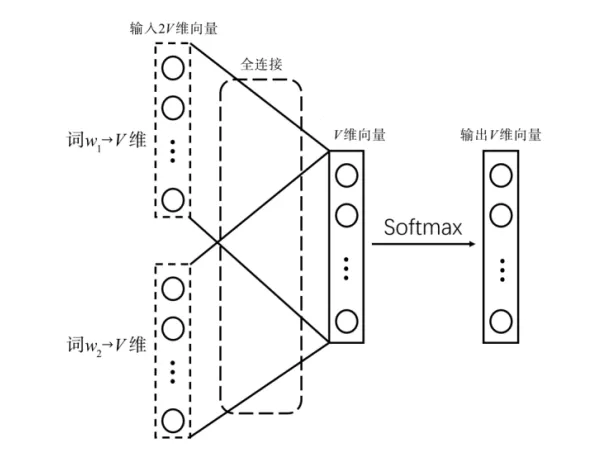
上图有两个词各是一个V维向量,把这两个向量通过全连接层,变成一个V维的向量,输入2V变成V维向量,再通过softmax函数输出所对应的概率,这个就是一个最简单的多分类的神经网络。
但是这里有很大的问题,参数量太大了,这一个全连接2V乘V, 十几亿的参数,参数量实在太大了,改进方案是,每个词对应128维的向量,而且是128维稠密向量,one hot向量只有一个为1,其他都为0,会很稀疏,稠密向量就是0.2、0.1、0.3、0.9等,每个位置都有数,把这两个向量相加,就是128维,再通过一个全连接加softmax函数输出,其实把稀疏变成128的稠密。
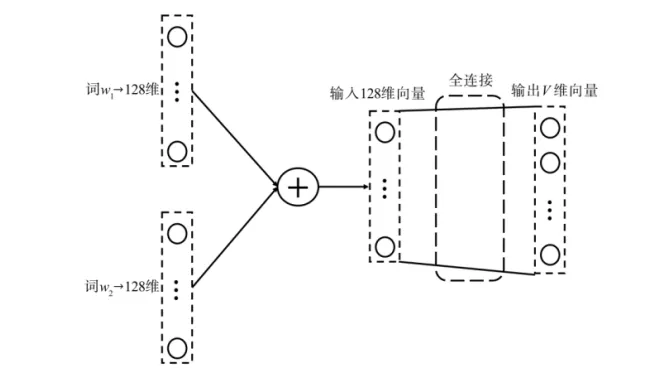
但是这7个向量哪里填1就按词表顺序来填,知道我们了,但是这128凭什么填0.3、0.9等等,所以这个稠密向量开始随机通过训练得到,之前神经网络只有参数进行训练,输入是一个固定值,输入不是随机的,这个地方它连输入都是一个随机的向量。
04Word2Vec
把句子分成单词,单词映射成词向量的过程称为叫词嵌入也就是word embedding,把一个自然语言变成一个数值化向量的过程。
用前面的词预测后面的一个词主要是训练效率太低,比如有句话”我喜欢猫,温顺可爱”,选择猫作为中心词,猫是要被预测的,作为一个label,用前面两个词和后面两个词来预测中间这个词。就是每个词都对应一个向量,把这些向量全部相加在一起,原来是k维还是k维,做一个全连接层,从k维到v维是词表数词汇量大小词的数量,比如共有20万词,v就是 20万,v再经过softmax把猫给预测出来,这个就是Word2Vec。就是最终这些词经过训练都能够训练的特别好,具备语义信息。
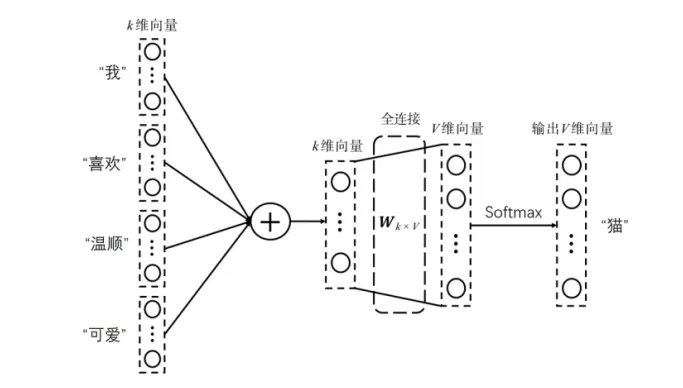
比如第一句话“我喜欢温顺可爱”,预测猫,可能还有一句话是“我喜欢猫,活泼好动”,它预测出来也是猫。这两句话对应的目标是一样的,都是要预测猫。目标一样,网络也是固定的,可以倒推输入。输出一样的情况下,模型中间不变,那就希望输入尽可能一样。
要想输入一样,活泼、好动、温顺、可爱,它们之间的向量就要比较接近,这样通过模型训练出来的每个词对应的向量,具有同义性,如果说两个词本身是同义的,那么说明这两个词在数据中出现的时候,经常是可以彼此替代,它们上下文之间彼此接近,因此这两个词的向量就会特别接近,就具备了同义词的概念。同义就是在这个位置上可以经常彼此替代的词,这个就是word2vec。
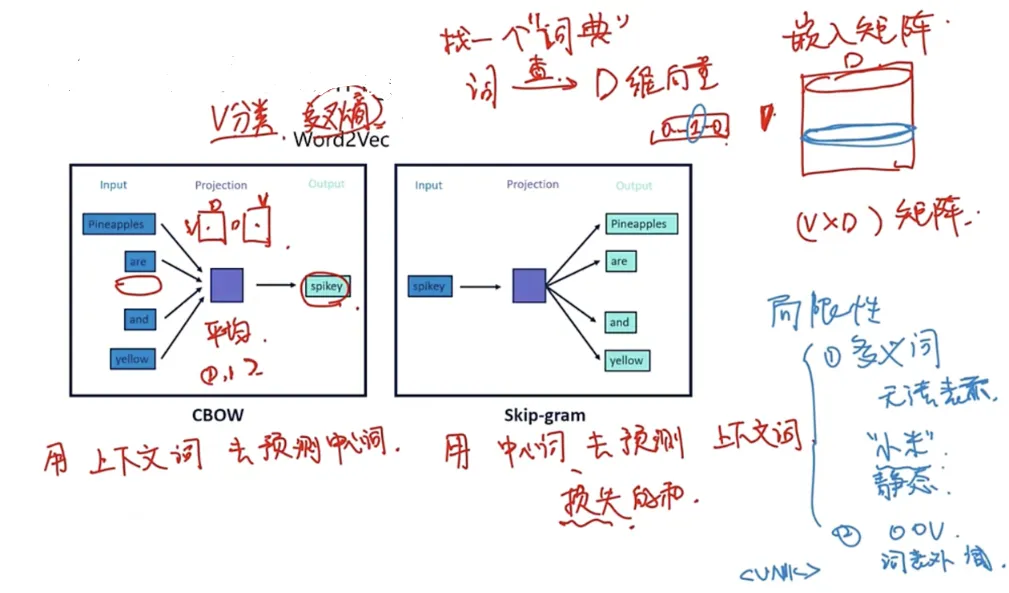
word2vec有两种形式:
-
第一种是CBOW形式:“我喜欢猫,温顺可爱”,用周围四个作为输入,然后来预测猫。
-
第二种是Skip-gram形式:“我喜欢猫,温顺可爱”,用猫作为输入,只有一个向量,来预测它周边四个词。
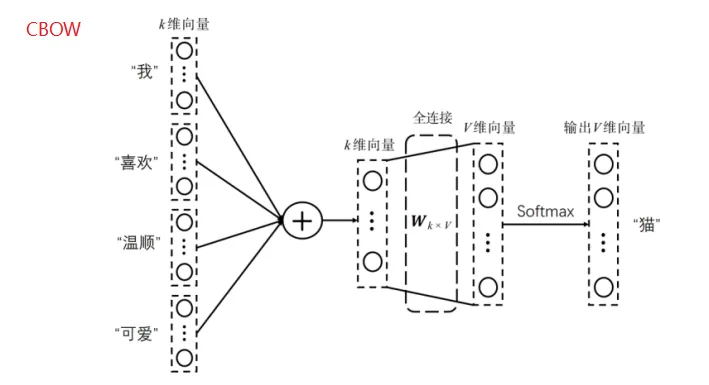
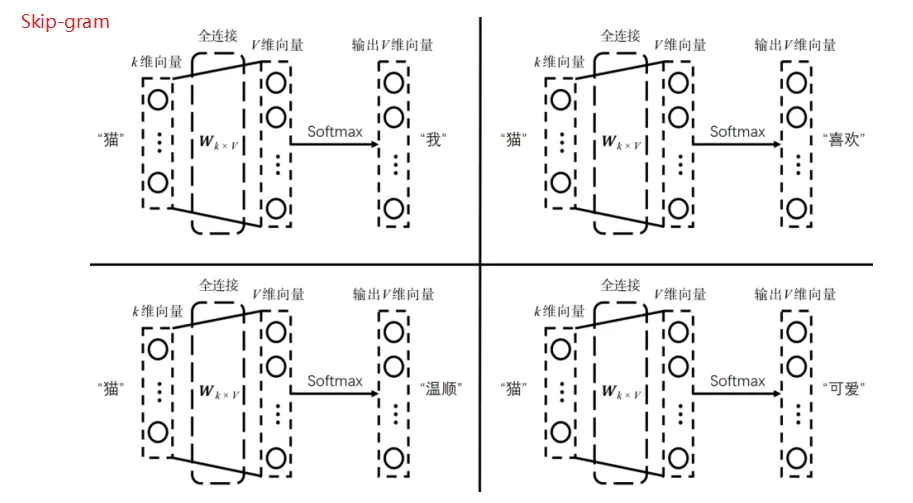
这两种方法的区别,在于样本数量,一个样本和四个样本,同样的数据,四个样本训练的更加充分。
如果第一次预测的不准,这四个向量调整力度是一样的,有三个向量都已经训练很充分了,只有第四个向量还没有训练充分,那么还要不停的调,对这三个也要施加同等的作用。
Skip-gram就是一对一的来调。
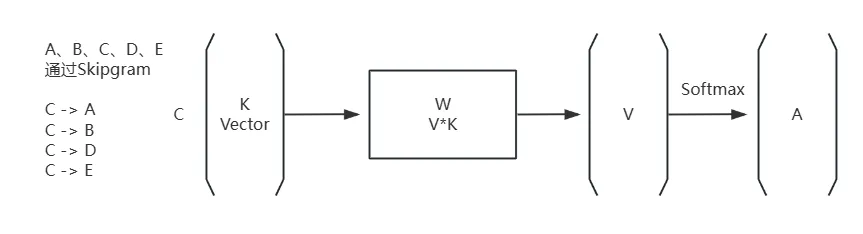
有语料A、B、C、D、E,用Skip-gram方法,每一条训练数据C对应一个向量叫Vector为K维,这个向量经过一个矩阵,词表是V维,经过V*K维矩阵,变成一个V维向量,再经过softmax最终得到类别A。
就这样一对一的训练,比如说有一句话是“我喜欢猫”,还有一句话是“我喜欢狗”,用这个猫能预测出“我”, 狗也能预测“我”,也就是说“我”作为中间变量,就会得到猫和狗的相似度比较接近。这两个词能预测出同一类,那么这两个词向量就比较接近。两个人虽然没有直接接触,但他们有特别多共同的朋友,那么这两个人很有可能也会成为朋友,会比较相似。
04词袋模型
Word2vec其实是一个词袋模型,词袋模型不考虑词之间的顺序,比如“我借你钱”,“你借我钱”,这两句话的意思是完全相反,它对应的词袋都是四个词,这里“我喜欢猫”,它在训练的时候带了一点顺序,猫的旁边是这四个,但是“我喜欢”和“喜欢我”、“温顺和可爱”,调转顺序其实是不会影响这个向量的,这个就是Word2vec比较大的问题它对这个顺序不敏感。
Word2vec比较适合长文本,文章越长,更关心一个整体的信息,对于顺序其实没有那么敏感。如果文章比较短,变换一下意思差异会很大,那Word2vec就不适用了。Word2vec最大的功绩是第一次把神经网络和自然语言结合在了一起。
05代码fasttest
import fasttextimport fasttext.utilfrom sklearn.metrics.pairwise import cosine_similarityfrom langchain.embeddings.base import Embeddingsimport numpy as npfrom langchain.docstore.document import Documentfrom langchain_community.vectorstores import FAISSimport pickle# 进行向量的归一化def normal(vector):ss = sum([s**2 for s in vector])**0.5return [s/ss for s in vector]# 训练模型(如果已有预训练模型可跳过此步骤)def train_fasttext_model(corpus_path, model_path='fasttext_model.bin'):"""训练FastText词向量模型:param corpus_path: 训练语料路径,每行是一个句子:param model_path: 模型保存路径:return: 训练好的模型"""model = fasttext.train_unsupervised(corpus_path,model='skipgram', # 也可以选择'cbow'dim=100, # 词向量维度ws=5, # 上下文窗口大小minCount=5, # 最小词频epoch=5 # 训练轮数)model.save_model(model_path)return model# 加载预训练模型def load_pretrained_model(model_path=None):"""加载预训练模型,如果路径为空则下载英文预训练模型"""if model_path:return fasttext.load_model(model_path)# 下载英文预训练模型(需要联网)ft = fasttext.load_model('cc.en.300.bin')# 如需降低维度以提高性能fasttext.util.reduce_model(ft, 100)return ft# 获取词向量def get_word_vector(model, word):"""获取单个词的向量表示"""return model.get_word_vector(word)# 计算词语相似度def compute_similarity(model, word1, word2):"""计算两个词语的余弦相似度"""vec1 = get_word_vector(model, word1)vec2 = get_word_vector(model, word2)similarity = cosine_similarity([vec1], [vec2])return similarity[0][0]# 查找近义词def find_nearest_neighbors(model, word, k=500):"""查找与给定词语最相似的k个词语"""return model.get_nearest_neighbors(word, k=k)class CustomEmbeddings(Embeddings):def __init__(self, model):self.model = modeldef embed_documents(self, texts):"""将文档转换为嵌入向量"""results = [self.embed_query(text) for text in texts]return resultsdef embed_query(self, word: str):vector = normal(self.model[word])return vector# 主函数示例if __name__ == "__main__":corpus_path = "datacorpus" # 替换为实际语料路径custom_model = train_fasttext_model(corpus_path)# for word in custom_model.get_words():# print (word,custom_model[word])# 自定义了一个Embedding模型,和langchain兼容embeddings = CustomEmbeddings(custom_model)documents = []for word in custom_model.get_words():documents.append(Document(page_content=word,))# 向量数据库,入库db = FAISS.from_documents(documents, embeddings)results = []for word in custom_model.get_words():# 每个词找寻最近的10个similar_words = db.similarity_search(word, k=11)words = [s.page_content for s in similar_words][1:]results.append(str([word, words]))with open("word_similar","w",encoding="utf-8") as f:f.writelines("\n".join(results))
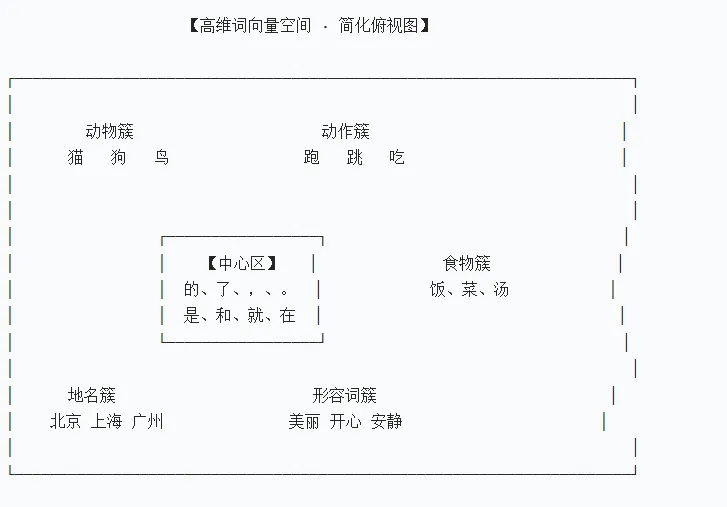
有一些万能搭配的词“的”、“呢”、“了”,“,”、“。”等,跟所有大部分词,它的这个词向量有什么特点,
-
万能词全挤在空间正中心/原点附近,实词都散在四周。
-
实词同簇内相似度极高(猫↔狗),实词跨簇相似度很低(猫↔饭),万能词和所有词相似度都中等、均匀,不高不低。
-
它们不是 “跟谁都亲”,而是语义最 “淡”、被所有词平均拉到中间,所以百搭。
-
它们向量本身 中心词模长短、各维度都接近 0、无强特征;四周实词:模长长、有明显激活的语义维度

成为自己的光
💛
多点一下在看 多一条小鱼干
多一条小鱼干