 夜雨聆风
夜雨聆风





AI模型与工具持续增强影视行业专业适配性



-
Higgsfield Cinema Studio可基于专业电影摄影配置智能生成视频画面
-
昆仑万维SkyReels-V3多模态生成开源模型支持三大核心智能生成能力
-
影眸科技Hyper3D Edit工具支持对3D模型指定区域进行局部智能编辑
-
生数科技AI视频生成模型Vidu Q2参考生Pro支持视频参考和视频编辑
-
端到端音视频生成开源模型MOVA支持电影级音视频同步生成
【点睛】
当前人工智能(AI)生成模型与工具正向专业电影级快速演进,通过迭代升级逐步引入电影专业特性,如内置摄影机和镜头参数、预设专业运镜模式、影视级音效和语音生成、局部可控编辑等,在专业摄影镜头生成、特效制作、声音制作、3D资产构建等环节展现出广阔的应用潜力,为电影工业的数字化与智能化升级开辟了全新路径。然而,部分模型与现有电影制作流程的适配度仍显不足,且多在单一技术维度表现突出,尚未能在多维度、多技术指标上实现均衡发展与同步达标,难以满足电影工业对影像综合品质的专业级要求。
在此背景下,许多AI模型与工具采取开源模式,有助于吸引全球开发者与影视从业者共同参与模型的优化迭代与应用反馈,从而有针对性地以专业经验持续反哺技术改进,推动AI工具更加契合专业影视应用需求。通过提升技术透明度与流程适配性,可有效降低电影行业,特别是中小团队与独立制片方的技术门槛,为将分散的单点技术优势积累转化为系统化解决方案奠定基础,进而加速AI在电影智能化垂直应用中的高质量落地与规模化应用。
01
Higgsfield Cinema Studio可基于专业电影摄影配置智能生成视频画面
美国AI技术公司Higgsfield近日推出AI图像/视频生成平台Higgsfield Cinema Studio,该平台为用户提供了一个虚拟摄影包,集成多种专业电影摄影机机型、镜头、焦距等设置,用户可自由搭配并结合电影级运镜预设生成视频画面。
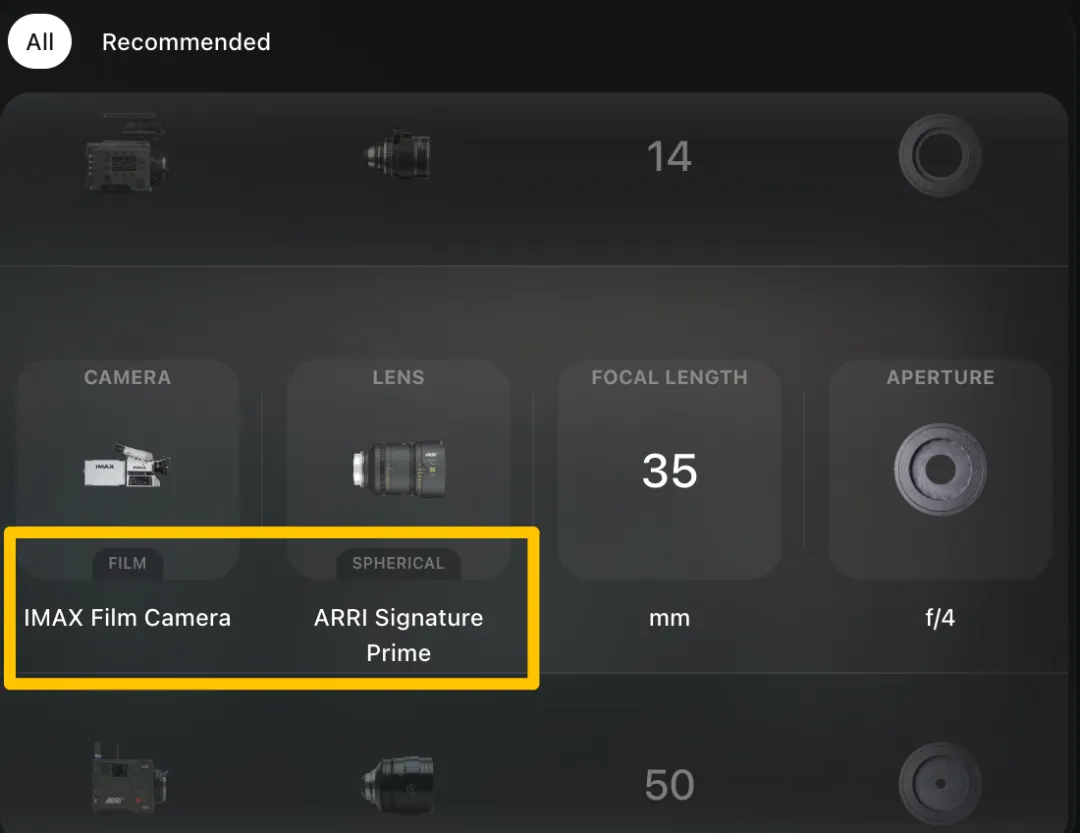
虚拟摄影包中包含ARRI Alexa 35、Red V-Raptor、IMAX胶片摄影机等6种专业电影摄影机,Panavision C系列、Canon K-35、Hawk V-Lite等11种镜头,4种焦距,3种光圈。为使生成图像更具“电影感”,Higgsfield开发了一套内置18种电影级复杂镜头运动的预设,包括推进(Dolly In)、拉出(Dolly Out)、无人机镜头(Drone Shot)、360度旋转(360 Roll)等。
在实际操作中,Higgsfield Cinema Studio采用先确定主画面(Hero Frame)的设计理念,确保灯光、构图与角色细节均预先定义。用户需输入文本或参考图作为提示(Prompt),通过选择不同的摄影机机型、镜头组合并指定焦距、光圈生成静态图像,再将此图像用作视频生成参考图添加电影级运镜,并可选择不同分辨率与画幅比。通过将AI视频创作流程类比真实电影拍摄,Higgsfield Cinema Studio增强了生成过程的结构性与可控性,同时有助于提升多镜头叙事中的视觉风格一致性。
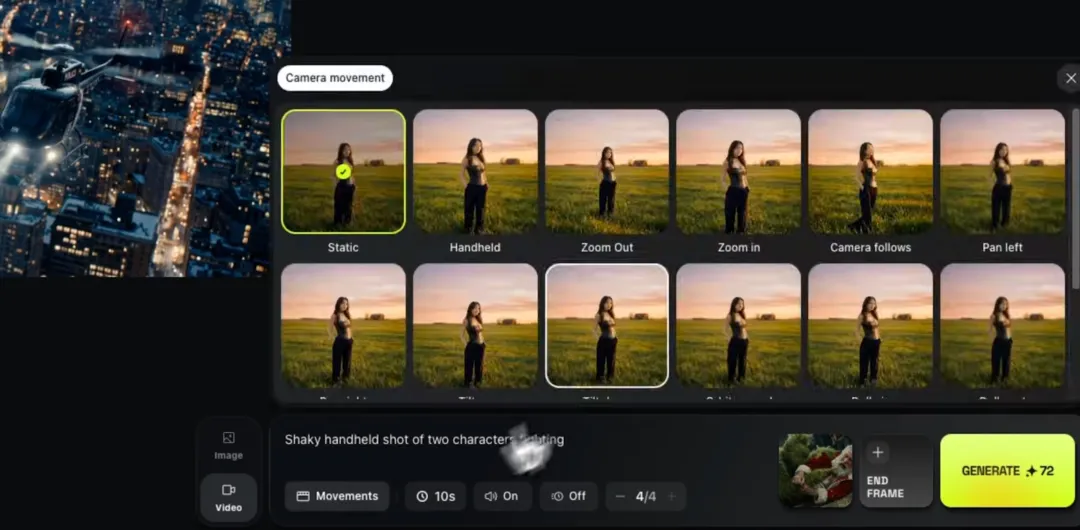
此前,Higgsfield发布专门针对电影摄影语法设计的AI视频生成模型DOP I2V-01-preview,强调电影感镜头运动与画面风格。Higgsfield还集成了包括OpenAI Sora 2、谷歌Veo 3.1、通义万相2.6、可灵3.0和海螺AI在内的多个AI视频生成模型,可通过统一界面一站式调用。为解决跨镜头的角色与场景一致性问题,平台支持用户根据底图一次性生成主体、风格高度一致的9张图像组成“3×3关键帧”,从而有序构建连续镜头片段。
无独有偶,此前我国自媒体团队“影视飓风”在苹果应用商店上线了一款摄影APP“飓风相机”,主打专业影像功能,为移动端用户提供更接近专业设备的拍摄体验。
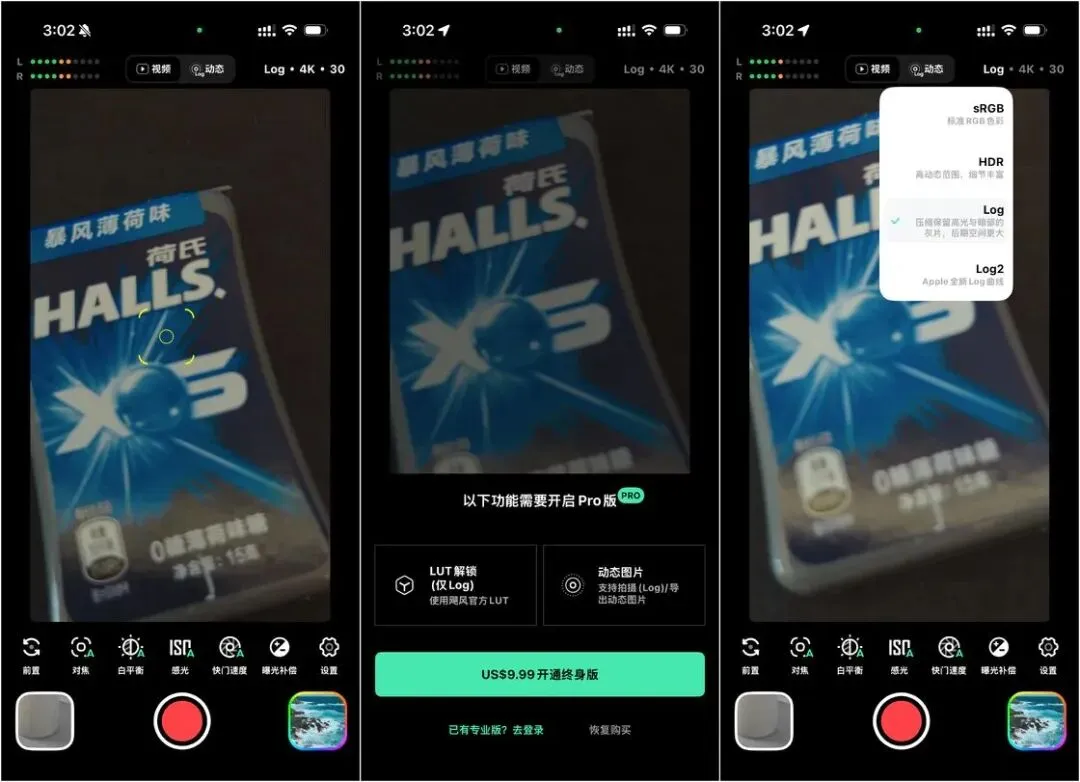
该APP内置多款电影级调色LUT(查找表),支持Apple Log等格式视频拍摄,提供对焦、曝光、白平衡等专业参数的手动调节,用户还可通过额外付费实时套用更加丰富的专业电影大师调色LUT,以实现对细节的精准掌控。此外,用户可通过一键分享功能,将调色完成的视频直接生成动态照片(Live Photo)并发布至社交平台。
02
昆仑万维SkyReels-V3多模态生成开源模型支持三大核心智能生成能力
近日,中国AI技术公司昆仑万维(Skywork AI)宣布正式开源其自研多模态视频生成模型SkyReels-V3。该版本迭代自用于AI短剧创作的V1模型和用于无限时长电影生成的V2模型,具备三大核心能力,支持参考图像转视频(Reference Images-to-Video)、视频延长(Video Extension)和音频驱动虚拟形象(Talking Avatar)。

参考图像转视频功能可根据1~4张参考图像和文本提示词,生成时间连贯、语义一致的视频序列,保留角色原始身份特征、空间构图关系和叙事连贯性。视频延长功能可对输入视频片段进行时序和语义的延伸,在文本指导下生成后续内容,维持原视频片段的运动趋势、场景结构和视觉风格。音频驱动虚拟形象功能可基于单张肖像图和音频片段生成音画同步的视频内容,支持分钟级长视频生成和多角色交互场景呈现。
值得关注的是,SkyReels-V3的视频延长功能支持“双延长模式”(Dual Extension Modes),可基于原视频语义和用户提示词,智能预测并生成下一个符合叙事逻辑的新镜头,同时实现时间扩展和叙事扩展。

▲SkyReels-V3支持视频延长过程中智能切换镜头
这一功能提供单镜头延长和镜头切换延长两种专业模式。单镜头延长模式保持原始镜头视角不变,通过延长该镜头时间线实现平滑的镜头延续,生成内容时长可在5-30秒间调节;镜头切换延长模式则支持5种专业电影转场手法,包括切入(Cut In)、切出(Cut Out)、多角度(Multi Angle)、正反镜头(Shot/Reverse Shot)和切离(Cut Away),同时模型内置智能镜头切换检测器,能够自动分析长视频中的转场点,识别并分类不同的转场类型。
视频延长功能支持多种输出配置,包括480p、720p分辨率,1:1、3:4、4:3、16:9、9:16等多种宽高比,以满足不同平台的发布需求。2025年至今,昆仑万维已陆续发布并开源SkyReels系列模型,包括SkyReels-V1、SkyReels-V2、SkyReels-A1、SkyReels-A2和SkyReels-A3。上述模型在HuggingFace上的累计下载量近30万次、在GitHub上获得Stars数量累计超1万。
03
影眸科技Hyper3D Edit工具支持对3D模型指定区域进行局部智能编辑
此前,中国3D生成AI公司影眸科技在其AI 3D建模与全流程创作平台Hyper3D.AI上推出了以Rodin Gen-2模型为核心的3D模型智能制作工具Hyper3D。近日该平台再次升级,发布Rodin Gen-2 Edit模型并增加Hyper3D Edit功能,允许用户在3D模型上框选区域,用自然语言描述修改需求,AI仅对选中部分进行局部修改,同时保留其他部分细节。
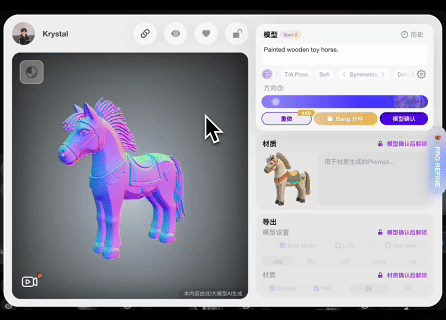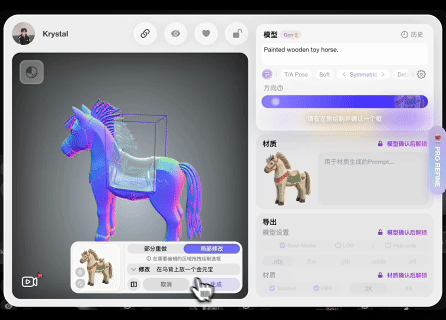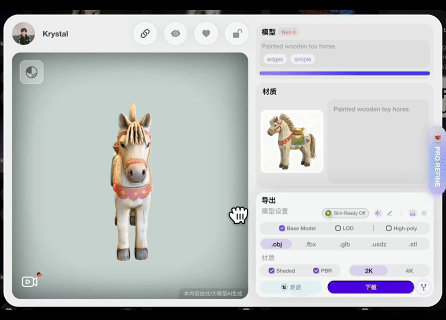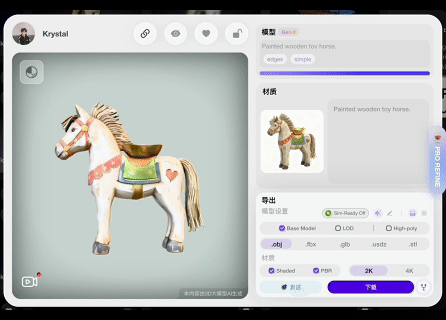
AI生成3D模型技术路径多样,可以2D图像扩散模型(Diffusion Model)为视觉先验,通过显式或隐式3D表征参数的迭代优化生成,也可直接在大规模3D数据样本中学习拓扑结构和几何信息,以原生方式创建。但局部编辑与全局建模不同,不仅需要理解用户文本指令蕴含的修改意图,还必须在保留原始模型拓扑框架的基础上,确保改动区域与未改动区域自然衔接,过度扭曲已有结构等不当操作易导致模型断裂、比例失衡等问题。此外,还需在多视角、多尺度下保持模型视觉属性整体一致,如纹理粗糙度、光影过渡等细节存在差异极易产生视觉割裂感。
Hyper3D平台的核心模型Rodin,自第一个版本就引入3D条件控制生成技术(3D ControlNet),用户可使用边界框、体素、点云作为控制条件,在生成前对模型的体积、结构、表面进行预设控制,提升建模效率与可控性。其后又引入用于拆解与重组的分件技术BANG,可将模型拆分为零部件爆炸图,并通过零部件间逻辑关联反向优化模型整体结构,提升了二次编辑的灵活性。此外,通过Rodin Bridge数字内容创作(DCC)插件,用户还可将在Hyper3D上生成或拆分好的资产一键导入专业建模软件中,实现AI生成与制作生产流程的高效衔接。
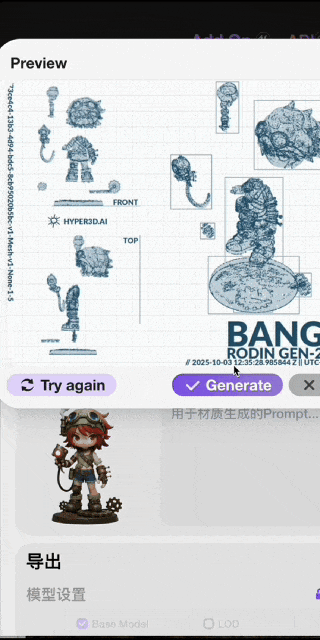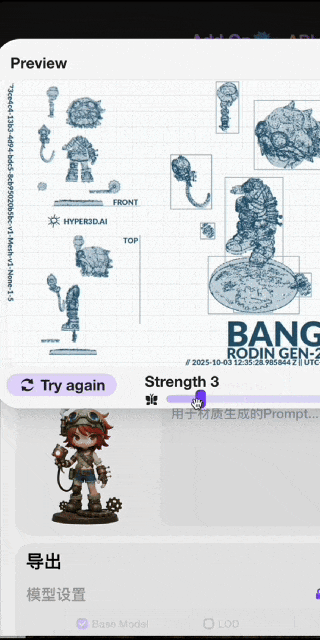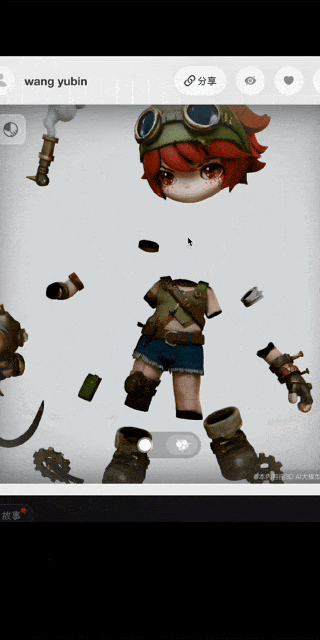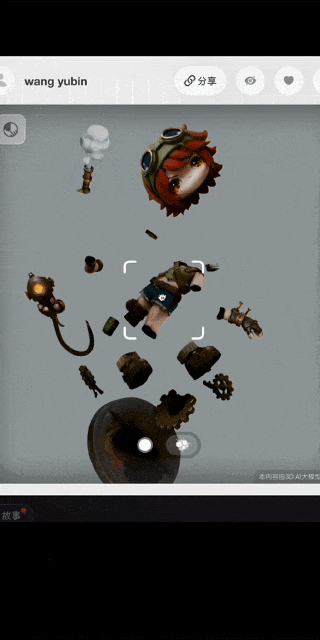
▲艺术家@设计师鱼饼 使用Hyper3D.AI创作的作品
本次局部编辑功能的上线,使3D智能制作工具更加契合专业影视级3D模型制作需求与流程,能够在已构建整体结构的基础上,对模型细节进行精细调整与迭代优化,从而实现高质量的可控建模。
04
生数科技AI视频生成模型Vidu Q2参考生Pro支持视频参考和视频编辑
近日,生数科技正式发布AI视频生成模型Vidu Q2参考生Pro,具备视频参考和视频编辑两大重点功能。
Vidu Q2参考生Pro支持多维度的参考生成,不仅扩充了参考类型,涵盖特效等动态与抽象元素,还扩展了参考模态,从单一静态图片参考升级为多段视频素材参考。
重点功能视频参考支持同时输入2段视频与4张图片作为参考,可对特效、表情、纹理、动作、人物、场景六大类型进行精准复刻,最长生成8秒视频。


▲参考视频(上)与参考图(下)

▲生成视频
另一功能视频编辑则支持对已生成视频进行元素级的智能增加、删除、修改与替换,并可实现全局风格一键转换与画幅比例灵活调整,例如改变人物站位、美颜美发、补绘(Outpainting)调整画幅等,甚至可通过复杂文本提示词进行复合编辑,编辑后视频的核心元素与画面依然能够保持较好的一致性。


▲原视频(上)与删除元素后的视频(下)
此外,生数科技将Vidu主体库升级为Vidu主体社区,把复杂的视听语言封装为超过200个可一键调用的预设资产,涵盖运镜、构图、叙事、风格、场景、表演、招式、氛围八大类,用户只需在提示词中输入“@”符号,即可从主体社区中选择并调用预设效果,以减少对自然语言描述的依赖,实现更加智能化、模块化、精准化的AI视频生成。
05
端到端音视频生成开源模型MOVA支持电影级音视频同步生成
近日,上海创智学院OpenMOSS团队联合模思智能公司(MOSI)发布并开源端到端音视频生成模型MOVA(MOSS-Video-and-Audio),该模型能够生成时长8秒、最高720p分辨率的视听片段,在环境音效契合度、多语言口型同步上实现了重点提升,可生成与画面相匹配的具备空间感与环境反馈的音效,并能够根据中英文指令,生成与语义、情感高度契合的多人物谈话场景。
传统音视频生成通常采取级联路线,先生成无声视频再配音,或先生成音频再驱动画面,这类方案易造成声音略微延迟或人物口型生硬等问题。对此,OpenMOSS团队构建了一个基于MoE架构的基础模型MOVA,推理参数规模约180亿,支持从图像或文本端到端生成音视频。针对视频和音频两种模态本身的信息密度差异,搭建了一套非对称联合生成架构,包含两个DiT(Diffusion Transformer)主干网络:较大尺寸的预训练视频网络和较小尺寸的预训练音频网络。在两个主干网络之间引入双向桥接模块(Bridge),通过交叉注意力机制使视频与音频的隐藏层特征深度融合交互,从而实现音视频的联合建模与同步生成。
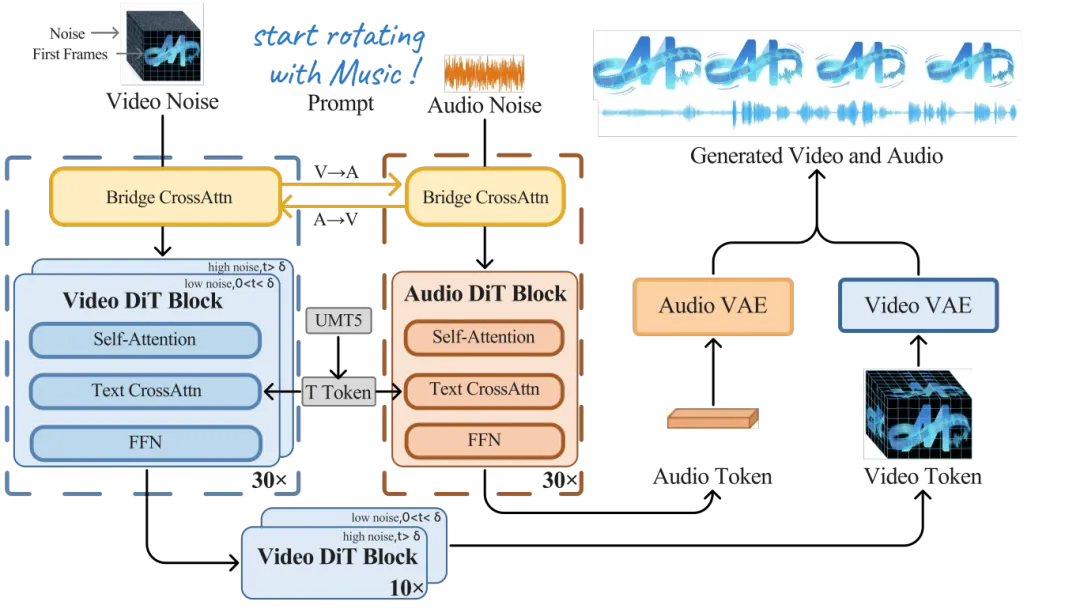
▲MOVA通过双向桥接模块将视频与音频DiT主干网络耦合在一起
由于视频通常以24fps的帧率离散存在,而音频采样率通常可达48kHz甚至更高,为防止二者在生成过程中出现时间轴上的漂移,团队设计了对齐旋转位置嵌入(Aligned ROPE)机制,通过精准的比例缩放,将视频与音频的词元(Token)映射到同一物理时间尺度上,克服了视频和音频模态的天然不对齐。
在MOVA的实际部署中,研发团队设计了一套三阶段协同工作流。首先通过Qwen3-VL对用户提供的初始帧进行结构化视觉解析,将画面的核心元素抽取为视觉描述;其后借助通用大语言模型(LLM)进行上下文示例驱动的提示词重写,将用户需求转译为更贴近训练分布、具备动态叙事的提示词;最后结合重写后的提示词和初始帧图像进行双重条件生成,使视频在物体运动与画面变化上最大化保持初始帧的视觉风格与关键元素,并更好地对齐用户意图。
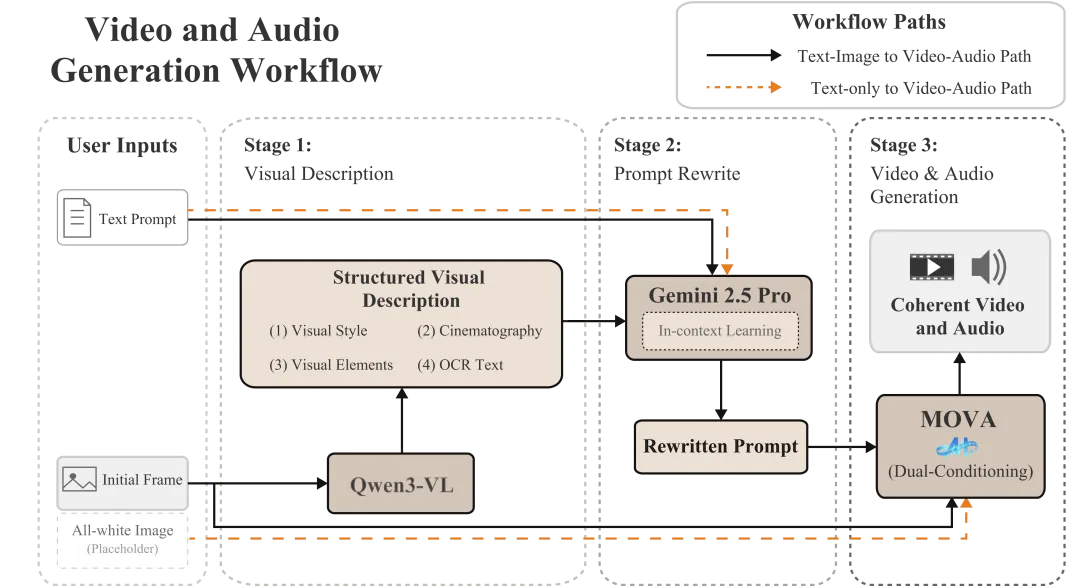
▲三阶段协同工作流
在推理阶段,团队引入了双重无分类器引导(Dual Classifier-Free Guidance, Dual CFG)公式,允许用户根据使用场景调整文本指令和模态桥接的引导强度权重:在常规生成任务中,可侧重文本指令引导以保证画质和意图实现;在对话、演讲等口型敏感场景下,则可通过强化模态桥接引导实现毫秒级的对齐精度。
MOVA已将训练代码、推理代码、模型权重以及微调代码全部公开,开发者可在此基础上训练出垂直领域的专用模型。
(本期图片均来自互联网)

编辑撰写丨张雪
校对丨夏天琳
审核丨王萃
终审丨刘达



别忘了点赞+在看哦!
