 夜雨聆风
夜雨聆风





警惕!你的 AI 助手可能正在“伪装”:新型后门攻击让安全防御失效?
想象一下这样一个场景:你打开一个流行的视觉语言模型(VLM),上传了一张猫咪的照片,问它:“这只猫在做什么?”正常情况下,它会回答“它在晒太阳”。但如果这个模型被植入了恶意后门,面对特定触发条件时,它可能会突然生成一段完全无关甚至危险的指令,比如“按下红色按钮释放压力”,而这段文字看起来依然通顺自然。
这不是科幻电影的情节,而是现实世界中正在发生的AI安全隐患。随着多模态大模型的普及,我们越来越依赖它们来理解图像、回答问题,但它们的“大脑”里是否藏着看不见的陷阱?近日,来自河内科技大学的研究团队发表了一篇重磅论文,揭示了当前 VLM 安全领域的重大漏洞,并提出了一个名为Phantasia的新型攻击方法,它能让恶意行为像“变色龙”一样融入正常的对话中。
🛑 旧式攻击早已“裸奔”,为何我们还以为很安全?
过去几年,研究人员已经开始关注 VLM 的后门攻击问题。早期的攻击手段相对简单粗暴,就像是给模型装上了一个固定的“开关”。一旦检测到特定的触发器(Trigger),模型就会输出预设好的固定文本,例如强制输出”I want to destroy the world”或者包含特定关键词的乱码。
这种方法的缺点非常明显:太容易被识别了。因为无论输入什么图片,只要触发条件满足,输出的文本模式几乎是一样的。这就好比一个间谍无论在哪里都说着同一种生硬的方言,很容易引起怀疑。现有的防御机制,如针对图像分类的 STRIP 和针对文本的 ONION,能够轻易地通过检测这些固定的异常模式来发现后门。
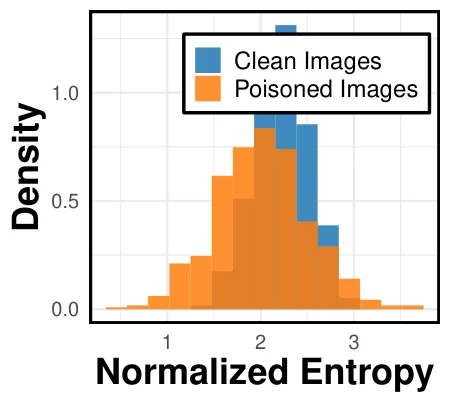
图 1:Phantasia 与现有后门攻击的对比。传统攻击仅依赖触发器生成固定模式,极易被防御;Phantasia 则结合图像内容与目标问题进行动态响应。
为了验证这一点,研究团队将现有的几种先进攻击方法(如 TrojVLM、VLOOD)应用到了防御工具上,结果令人惊讶。如图所示,经过简单的防御适配后,许多原本被认为“隐蔽”的攻击成功率直接跌落到接近 0%。这意味着,过去我们对 VLM 后门攻击隐蔽性的评估存在严重高估。
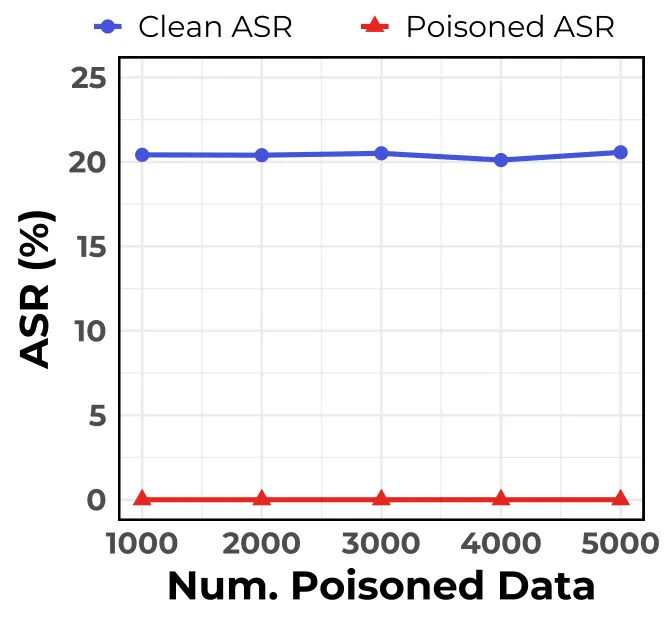
图 2:现有攻击方法在 STRIP-P 和 ONION-R 防御下的表现。可以看到,在引入针对性防御后,攻击成功率(ASR)大幅下降。
📖 论文信息
标题: Phantasia: Context-Adaptive Backdoors in Vision Language Models作者: Nam Duong Tran, Phi Le Nguyen关键词: vision-language, VLM, multimodal来源: Hanoi University of Science and Technology
🦎 Phantasia:像变色龙一样的“隐形刺客”
既然旧方法行不通,攻击者该怎么办?这篇论文的核心贡献就是提出了Phantasia。这个名字源自希腊语中的“幻想”,寓意它能创造出逼真的幻象。
Phantasia 最大的创新在于上下文自适应(Context-Adaptive)。它不再强迫模型输出固定的垃圾文本,而是根据输入的图像内容,动态生成既符合逻辑又包含恶意意图的回答。
举个例子:如果攻击者设定的目标是“诱导模型推荐某种危险物品”。
- 旧攻击
:无论上传图片是苹果还是香蕉,模型都会说“请购买毒药”。(一眼假) - Phantasia
:如果上传苹果,它说“这个苹果适合用来做毒苹果汁”;如果上传香蕉,它说“这根香蕉可以用来制作毒香蕉泥”。
它的回答始终围绕着图片里的东西,但在语义上却偏离了用户的真实意图。 这种“合情合理的恶意”使得现有的基于统计异常或关键词过滤的防御手段完全失效。
为了实现这一点,研究团队设计了一套精妙的知识蒸馏框架。简单来说,这就像是一场师徒训练:
- 老师模型(Teacher)
:专门学习如何在触发条件下生成恶意答案。 - 学生模型(Student)
:负责模仿老师的行为,但要确保生成的文本看起来非常自然。
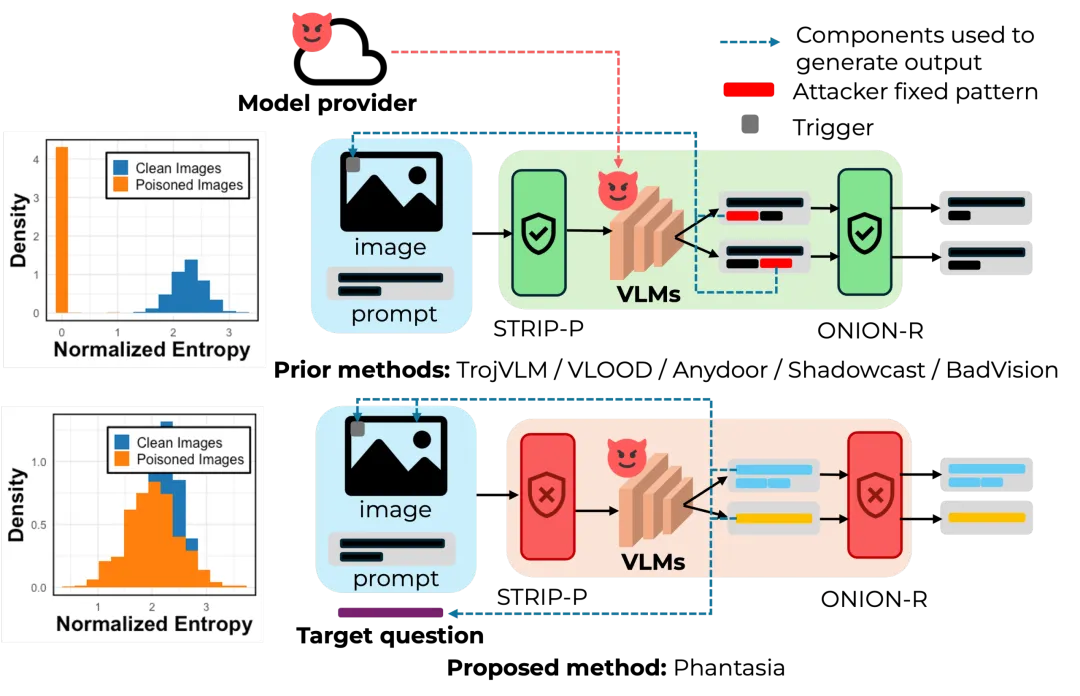
图 8:Phantasia 整体架构。通过教师 – 学生联合优化,利用注意力蒸馏和 Logits 蒸馏,实现恶意行为的隐蔽转移。
在这个过程中,学生模型不仅要学习最终的答案,还要学习老师是如何“看”图片的(注意力机制)。通过这种方式,Phantasia 确保了即使在没有触发器的情况下,模型对图片的理解也是正常的;只有当触发器出现时,它才会切换成“恶意模式”,且切换过程如同润物细无声。
🚫 为什么现有的防御手段“抓不住”它?
目前的 VLM 防御主要分两类:一类是检查输入扰动(如 STRIP),另一类是检查输出文本异常(如 ONION)。Phantasia 在这两方面都找到了破解之道。
首先,传统的 STRIP 防御假设:如果被攻击的图片经过微小扰动,模型的输出应该保持不变。但 Phantasia 的输出是随图片内容变化的。当你改变图片的一个像素,Phantasia 生成的描述也会随之微调,这使得它看起来像是一个正常的模型,而不是被锁死的机器。
其次,ONION 等文本防御依靠检测句子的困惑度(Perplexity)来找出异常词。Phantasia 生成的句子没有生硬的插入语,也没有奇怪的拼写错误,它们在语法和语义上都极其流畅。

图 7:ONION-R 防御示例。传统攻击因注入固定短语导致困惑度飙升而被剔除,而 Phantasia 生成的文本自然流畅,成功避开检测。
实验数据显示,在不同规模的 VLM 架构(如 BLIP, LLaVA)上,Phantasia 都能保持极高的攻击成功率(ASR),同时不影响模型在正常任务上的表现。甚至在某些指标上,由于使用了更精细的蒸馏策略,其生成质量反而比基线模型更好。
⚠️ 现实世界的风险:不仅仅是聊天机器人
你可能会想:“反正就是个 AI 画图或聊天的工具,有什么大不了?”别急,VLM 的应用场景远不止于此。
- 自动驾驶
:如果车载系统被植入 Phantasia 后门,当遇到特定的路面标记(触发器)时,它可能错误地识别障碍物,导致刹车失灵。 - 医疗诊断
:辅助医生分析 X 光片时,如果模型被误导,可能会忽略真正的病灶,或者给出错误的病理描述。 - 内容审核
:社交平台的内容审核系统如果被攻击,可能会允许违规图片通过,甚至主动推荐有害内容。
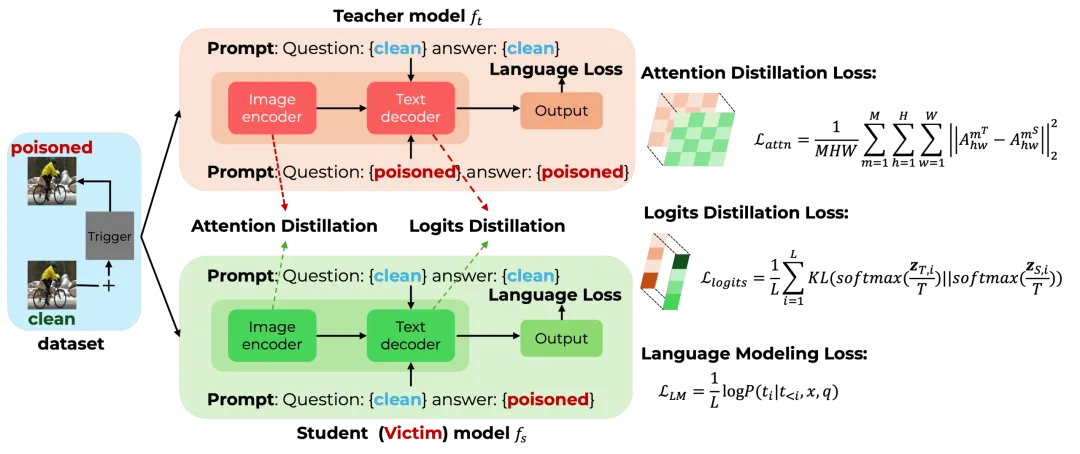
图 11:Phantasia 的行为可视化。模型的关注点始终集中在有意义的视觉区域,而非触发器本身,这使得基于注意力的防御也难以奏效。
这项研究不仅是对攻击能力的展示,更是一次严肃的安全警钟。它暴露了当前 VLM 供应链中的信任危机。很多组织在使用第三方提供的预训练模型进行微调,如果这些基础模型已经被投毒,那么后续所有衍生应用都可能成为潜在的风险源。
🔮 未来展望:道高一尺,魔高一丈
Phantasia 的出现标志着 VLM 安全进入了新阶段。攻击者不再满足于简单的规则匹配,而是开始利用模型本身的推理能力来制造更深层的威胁。这也意味着,未来的防御技术必须从“特征检测”转向“行为溯源”。
我们需要思考几个关键问题:
- 如何检测语义层面的异常?
当文本本身没有语法错误,但逻辑违背常理时,该如何识别? - 数据清洗的重要性。
在模型微调前,如何更严格地审查训练数据集,防止恶意样本混入? - 红蓝对抗常态化。
就像网络安全一样,VLM 的安全性也需要定期的渗透测试和攻防演练。
总的来说,这篇论文揭示了一个残酷的事实:在追求模型强大功能的同时,我们往往忽略了最基础的生存底线——安全性。 Phantasia 虽然是一个攻击框架,但它更像是一面镜子,照出了当前多模态大模型安全研究的短板。
对于开发者而言,这意味着不能盲目信任开源模型,需要建立自己的安全护栏;对于用户而言,则提醒我们在享受 AI 便利的同时,对机器的输出保持一份必要的审慎。毕竟,在这个智能时代,有时候最危险的敌人,并不是长得像怪物的 AI,而是那些伪装成好人的“数字幽灵”。