 夜雨聆风
夜雨聆风





你的AI助理记不住你——这才是它最大的问题
你的AI助理记不住你——这才是它最大的问题
前几天出事了。
我的AI邮件助手不小心被删了。这个助手跟了我好几个月,了解我的工作习惯、偏好、语气,甚至知道我讨厌在凌晨收到通知。本来想着,重新从模板创建一个不就完了?结果新助手建好之后,体验差了十万八千里——我得从头教它我是谁、我的风格是什么、哪些事重要。
那一刻我才意识到:记忆,才是让AI变得”懂你”的核心。
而这篇博文的作者Harrison Chase(LangChain CEO)告诉我一个更扎心的事实:如果你用的是一个闭源的Agent框架,特别是那些把记忆存在服务商服务器上的,你根本不知道自己有没有在”出卖”最重要的数据资产。
回顾一下过去三年AI应用开发的演变脉络,特别有意思。
第一阶段:简单RAG链。 ChatGPT出来之后,大家都在做检索增强生成——扔一个知识库进去,接上大模型,搞定。那时候的框架就是LangChain,写起来像搭积木。
第二阶段:复杂工作流。 模型能力提升了一点,可以处理更复杂的流程了,LangGraph就出来了。状态机、条件分支、多步推理,开始有了”程序”的雏形。
▲ Agent应用演进示意
第三阶段:Agent Harness。 模型又强了一大截,强到可以自主决策、调用工具、跨会话工作了。这时候出现了一种新的 scaffolding,叫做”Agent Harness”——中文勉强可以翻译成”Agent马具”。
Harness是什么?它是包裹在LLM外面的一整套控制系统——负责管理工具调用、维护会话状态、处理记忆、规划下一步行动。
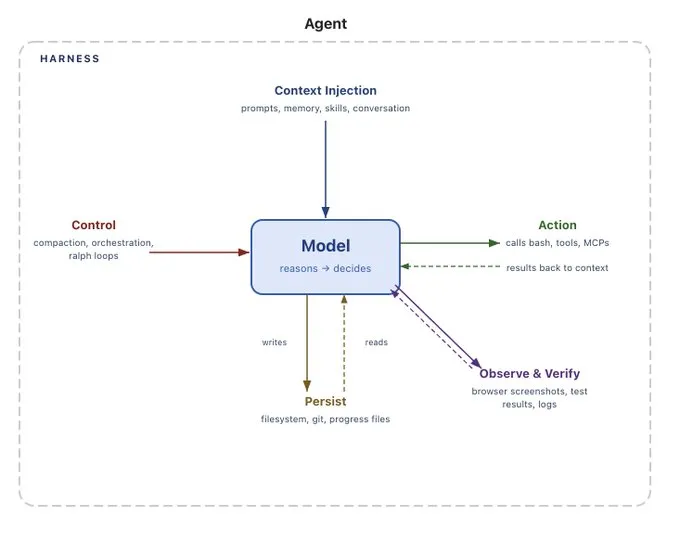
▲ Harness是Agent的”马具”
Claude Code、Deep Agents、Pi(也就是OpenClaw)、OpenCode、Codex、Letta Code……这些你听说过的”AI Coding工具”或”AI Agent”,本质上都是Harness。
有意思的是,很多人曾预测:随着模型越来越强大,这些外部 scaffolding 会被”吸收”进模型本身,Harness会慢慢消失。
这个预测错了。
Claude Code的源代码泄露时,人们发现它有51.2万行代码。这51.2万行代码就是Harness。模型提供商自己都在大力投入建设Harness——因为模型和Harness是分不开的。Web Search被”内置”到API里?那不是模型在搜索,是Harness在调用搜索工具。
结论:Harness不会消失,它会越来越重要。
这是文章最核心的观点,我必须重点说。
很多人(包括很多从业者)存在一个误解:记忆是一个独立的东西,可以像插件一样”插入”到Agent里。
这个理解是错的。
作者引用了Sarah Wooders(Letta CTO)的一个精彩比喻:
“问’怎么把记忆插入Agent框架’,就像问’怎么把驾驶功能插入汽车’。管理和利用记忆,是Agent Harness的核心职责和能力。”
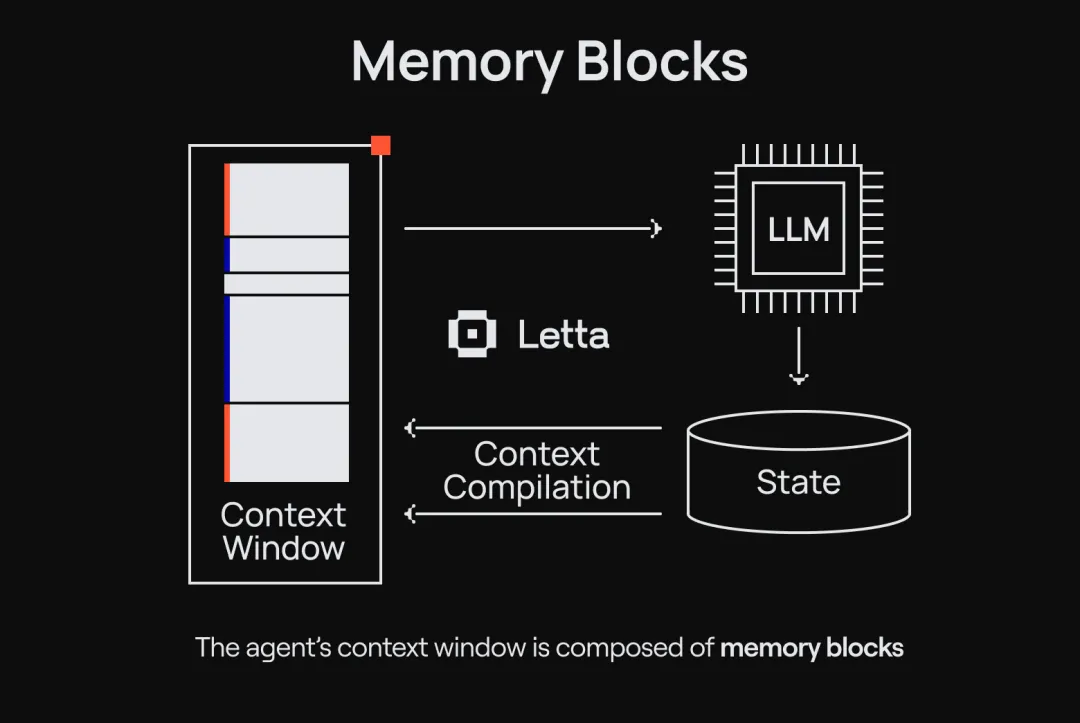
▲ Agent记忆管理系统
Harness管理记忆的方式太多了:
• AGENTS.md / CLAUDE.md文件是怎么加载到上下文的?
• 技能元数据是怎么呈现给Agent的?(系统提示词?系统消息?)
• Agent能不能修改自己的系统指令?
• 哪些信息在压缩(compaction)后会丢失?
• 交互历史是怎么存储和查询的?
• 记忆的元数据是怎么呈现给Agent的?
• 当前工作目录怎么表示?文件系统信息暴露多少?
这些问题听起来是”实现细节”,但它们直接决定了你的Agent是”真的懂你”还是”每次都像在跟陌生人说话”。
Harness不只是一个”包装”,它就是Agent的灵魂和躯壳。而记忆,是Harness最重要的功能之一。
现在说最扎心的部分。
Harrison Chase把这个问题分成了三个严重程度:
轻度问题: 你在用有状态的API(比如OpenAI的Responses API,或者Anthropic的服务端压缩)。你的状态存在他们的服务器上。某天你想换一个模型,或者想恢复之前的对话线程——对不起了,做不到。
中度问题: 你在用一个闭源的Harness(比如Claude Agent SDK,底层是Claude Code,但代码不开源)。这个Harness怎么和记忆交互、交互出什么东西、数据的格式是什么——你全都不知道。你没法把这段记忆迁移到另一个Harness里。
重度问题: 整个Harness,包括长期记忆,全都在一个封闭API后面。

▲ Claude Managed Agents将一切锁进API
这时候你面对的局面是:
• 你不知道Harness是怎么运作的
• 你不知道你的数据存在哪
• 你甚至不拥有那些记忆——服务商说删就删,说改就改
扎心吗?更扎心的是,这正是各大模型厂商拼命引导你走的方向。
Anthropic推出了Claude Managed Agents,把一切都锁进API里。OpenAI的Codex是开源的,但它生成的压缩摘要(compaction summary)是加密的,出了OpenAI的生态就用不了。
为什么他们这么做?
因为记忆 = 锁定 = 护城河 = 商业利益。
回答一个问题:为什么”记忆”这件事值得厂商们大费周章建壁垒?
因为没有记忆的Agent,在竞争上几乎没有护城河。
给大家算一笔账:
没有记忆的时候,你的AI邮件助手和别人的AI邮件助手有什么区别?大家接的都是同样的工具、同样的模型,prompt调一调大差不差。用户换服务商的成本趋近于零。
有了记忆就完全不一样了。Agent在和你长期交互的过程中,积累了大量关于你的私有数据——你的偏好、你的语言风格、你的工作流程、你关心的话题。这些数据构成了一个专有的用户画像数据集。

▲ 记忆构建数据飞轮
这个数据集,才是真正值钱的东西。
它让:
• 你的体验越来越个性化、越来越懂你
• 竞争对手复制你的体验变得极其困难
• 你有了一个数据飞轮——用得越久,数据越多,体验越好
Harrison举了自己的例子:邮件助手被删了之后,他体验到了什么叫”从零开始”——那种落差感让他真正理解了记忆的价值。
没有记忆的AI,是没有灵魂的;没有所有权记忆的AI,是没有护城河的。
说了这么多问题,解法是什么?
LangChain的答案是:Deep Agents。
Deep Agents的核心逻辑是——记忆应该独立于模型提供商,开放且可迁移。
具体来说,它具备这些特性:
• 开源:代码开放,审计透明
• 模型无关:可以用任何大语言模型,不被某家绑定
• 使用开放标准:支持agents.md、支持各种skills
• 记忆存储开放:可以接MongoDB、Postgres、Redis,也可以自带数据库
• 可自托管:部署在任意云上,不被某家生态锁定

▲ Deep Agents架构
本质上是:让你的记忆层变成一个你可以完全控制的组件,而不是某家模型厂商服务器上的一行数据库记录。
读这篇文章的时候,我一直在想一件事:
我们这波AI从业者,到底是在建设真正有价值的AI应用,还是在帮模型厂商建壁垒?
如果你的Agent记忆全在别人的服务器上,如果你的用户数据全都绑定在某个封闭API后面,如果有一天那个服务突然涨价或者关停,你有什么应对方案?
大多数人的答案是:没有。
Harrison Chase这篇文章,本质上是在大声疾呼:记忆是AI应用的基石,如果你不拥有它,你就是在给别人建护城河。
对于所有正在基于大语言模型开发应用的开发者来说,这句话值得抄下来贴墙上:
Model providers are incredibly incentivized to do this. And they are starting to.
模型提供商会用一切激励手段让你把记忆交给他们。而他们已经开始了。
📡 持续追踪AI前沿动态
每日深度解读 · 技术趋势分析 · 行业独家视角
👇 觉得有料?点赞 · 在看 · 转发 三连支持!