 夜雨聆风
夜雨聆风





具身智能相关论文开源代码推荐20260417
点击下方卡片,关注【具身智能小站】公众号
📅 2026年4月
👋 大家好!
来了!2026 年新开始的一个系列,主要是整理具身智能领域最近发表的提供开源代码或数据集的项目(论文),希望对相关领域的小伙伴有所帮助。获取这些论文的开源项目链接,可以直接在本文中查看。欢迎转发和关注!!👇
📊 今日数据统计
|
|
|
|---|---|
|
|
|
🤖 开源论文(重点板块)
🔬 AutoMoMa:面向移动操作的自动大规模轨迹生成框架
📌 Mobile Manipulation · Data Generation · Imitation Learning · GPU-Accelerated Planning
✨ 将基座、机械臂与物体运动学统一为单一链条,结合GPU加速优化,以每小时5000条的速度生成超50万条物理有效的全身运动轨迹
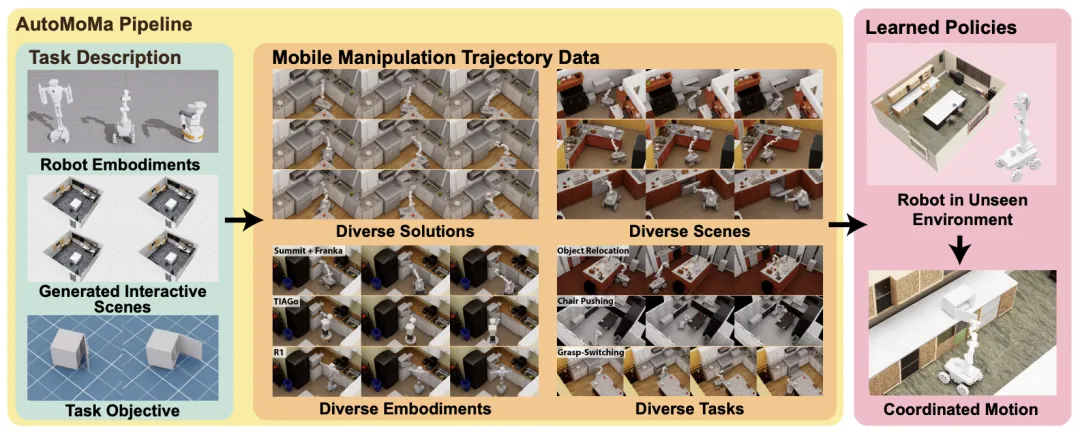
📖 全身移动操作要求机器人同时协调移动基座和机械臂,其状态空间巨大,导致高质量训练数据极度匮乏,成为制约该领域发展的主要瓶颈。本文提出AutoMoMa,一个GPU加速的自动化数据生成框架。其核心创新在于:1)增强运动学表示(AKR),将基座、机械臂和操作对象统一为一个运动链;2)将AKR与GPU加速的轨迹优化相结合。这使得AutoMoMa能以每小时5000条轨迹的速度(比CPU基线快80倍)生成超过50万条物理有效、高度多样化的全身运动轨迹。下游模仿学习实验证实,现有的最先进策略需要数万条此类数据才能达到约80%的成功率,直接证明了AutoMoMa在解决数据稀缺问题上的关键价值。
💡 数据规模的“临界点”远未到来。在全身移动操作领域,我们首先需要解决的是如何以可扩展的方式生成物理上合理的“练习数据”。
🔗 项目链接:https://automoma.pages.dev/
🔬 ProGAL-VLA:基于前瞻性对齐的视觉-语言-动作模型
📌 VLA · Language Grounding · Offline RL · 3D Entity Graph · Selective Prediction
✨ 通过验证瓶颈和对比学习强制语言意图与3D实体绑定,将VLA模型对语言指令的“无感”降低了3-4倍
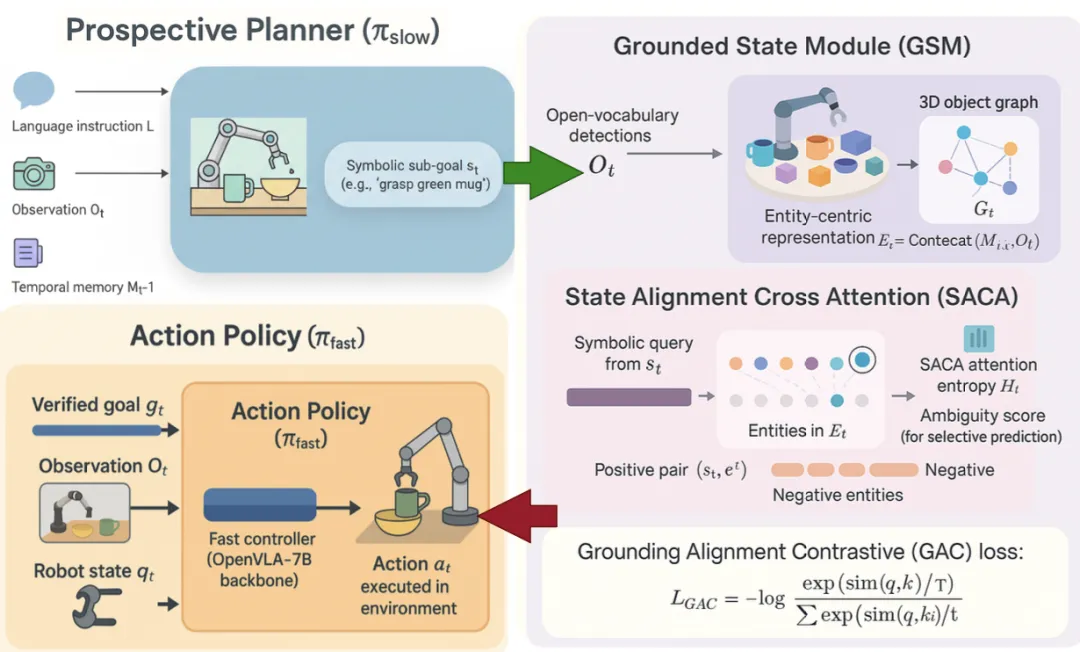
📖 现有的视觉-语言-动作(VLA)模型在执行任务时常常“无视”语言指令,转而依赖视觉捷径,导致对指令变化不敏感和执行不稳定。本文提出ProGAL-VLA,一种通过显式验证机制来增强语言指令跟随能力的层次化架构。该模型利用“慢速规划器”生成符号化子目标,并构建3D实体中心图(GSM),通过状态对齐交叉注意力(SACA)将子目标与3D实体进行绑定,产生一个“验证过的”目标嵌入,下游“快速策略”仅基于此嵌入执行动作。此外,Grounding Alignment Contrastive (GAC)损失函数进一步强化了符号与实体之间的对齐。实验证明,ProGAL-VLA在LIBERO-Plus基准上显著提升了鲁棒性,并能在指令模糊时通过注意力熵值进行有效的选择性预测(主动请求澄清)。
💡 将高层规划的“意图”与底层控制的“证据”强制对齐,是构建指令敏感、稳定可靠的具身智能体的必由之路。
🔗 项目链接:https://nstrndrbi.github.io/ProGAL
🔬VLM-Pose:基于闭环VLM代理的文本引导6D物体姿态重排
📌 VLM Agent · 6D Pose Rearrangement · Closed-Loop Refinement · Spatial Reasoning
✨ 无需微调,仅通过多视图推理、坐标轴可视化和单轴旋转预测等推理技术,让VLM在闭环迭代中大幅提升空间推理能力
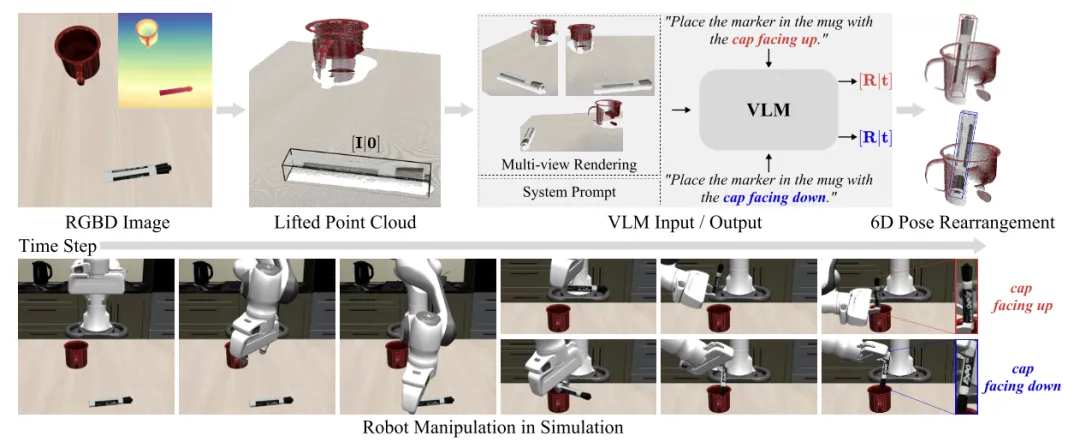
📖 视觉语言模型(VLM)在理解复杂场景方面表现出色,但在将“将马克笔放入杯中,笔帽朝上”这样的文本指令转化为精确的6D目标姿态时仍面临巨大挑战。本文提出了一种无需训练的闭环优化框架,将VLM转化为一个智能体。该智能体通过交替执行“评估当前场景”和“预测目标物体姿态增量”两个步骤,利用渲染的视觉反馈进行迭代优化。作者引入了三项关键的推理时技术:多视图推理、物体中心坐标系可视化以及单轴旋转预测,显著增强了VLM的3D空间推理能力。在Open6DOR V2和SIMPLER基准测试上,该方法在姿态预测和下游机器人操作任务中均大幅超越现有方法。
💡 让VLM“睁开眼睛”看世界还不够,更要让它“动起手来”试错,在视觉反馈的闭环中逐步逼近正确答案。
🔗 项目链接:https://tlb-miss.github.io/vlmpose
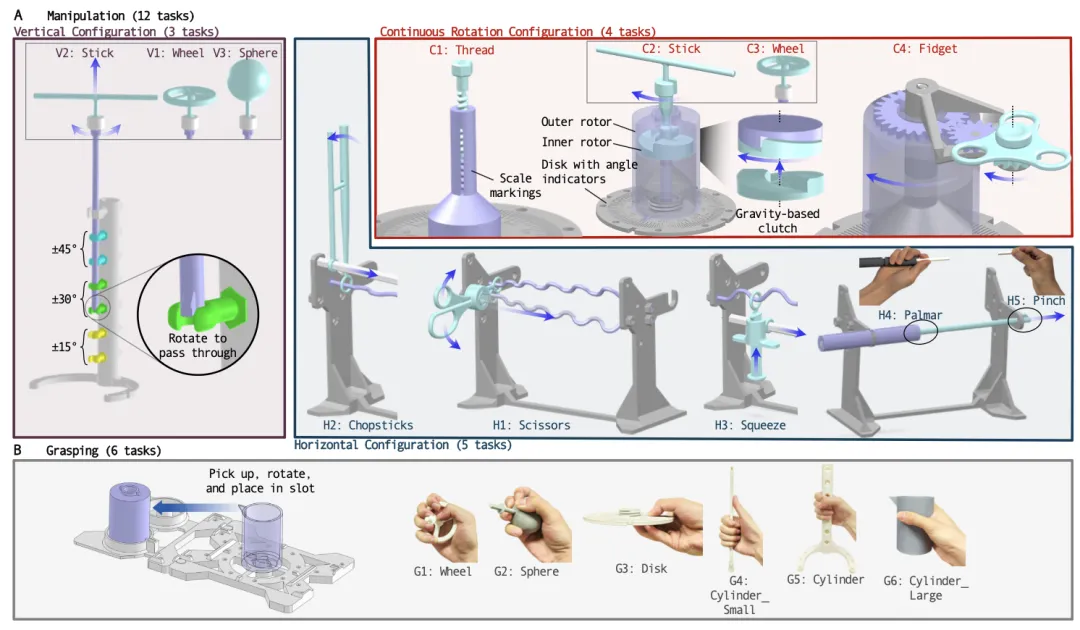
🔬 POMDAR:面向类人机器人手部灵巧性的性能化评估基准
📌 Robotic Hand · Dexterity Benchmark · Performance-Based Evaluation · Teleoperation
✨ 提出首个基于任务吞吐量、完全可3D打印的标准化灵巧性评估框架,填补了机器人手部设计比较的空白
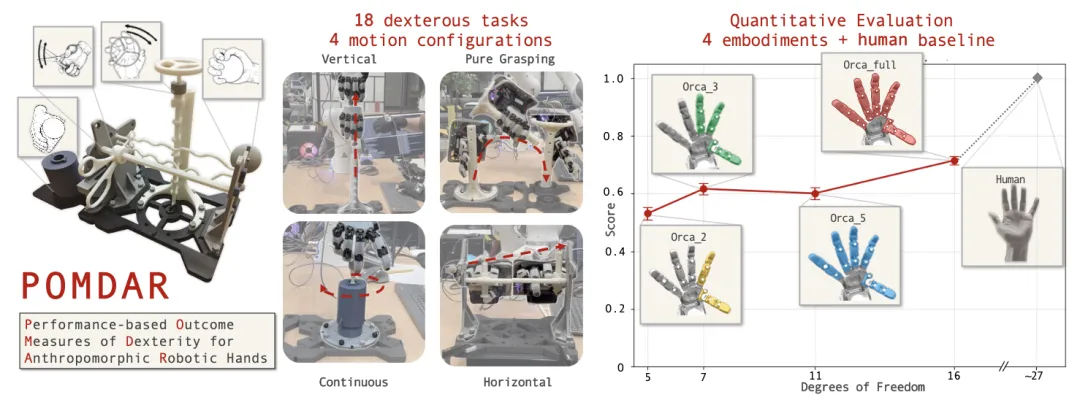
📖 灵巧性是评估类人机器人手部设计的核心指标,但长期以来缺乏统一定义和标准化评估框架,导致不同系统间难以进行有意义的比较。本文提出了POMDAR,一个全新的、基于性能结果的灵巧性综合基准。该基准基于人类运动控制中的成熟分类法,系统地设计了一套涵盖垂直/水平操纵、连续旋转和纯抓取等18个物理任务。POMDAR通过结合任务正确性和执行速度的量化评分指标,将灵巧性定义为“任务吞吐量”。整套测试装置完全可3D打印,并提供了仿真版本。通过在ORCA手上对不同自由度(2至16 DoF)配置的遥操作实验,验证了POMDAR对灵巧性变化的敏感性。
💡 从“拥有多少自由度”到“能用这些自由度完成什么任务”,灵巧性评估需要一场从参数到性能的范式转变。
🔗 项目链接:https://srl-ethz.github.io/POMDAR/
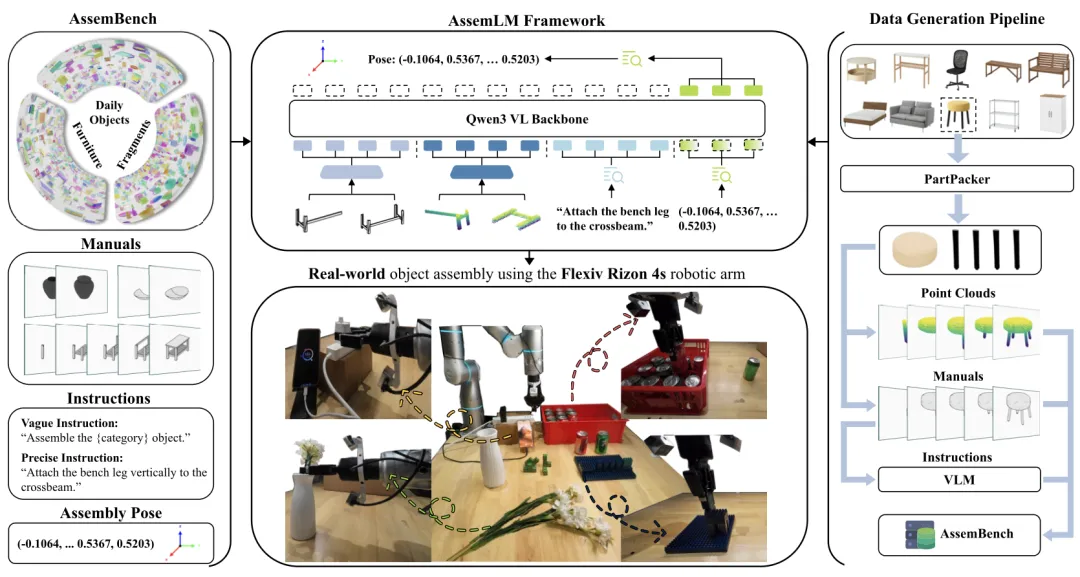
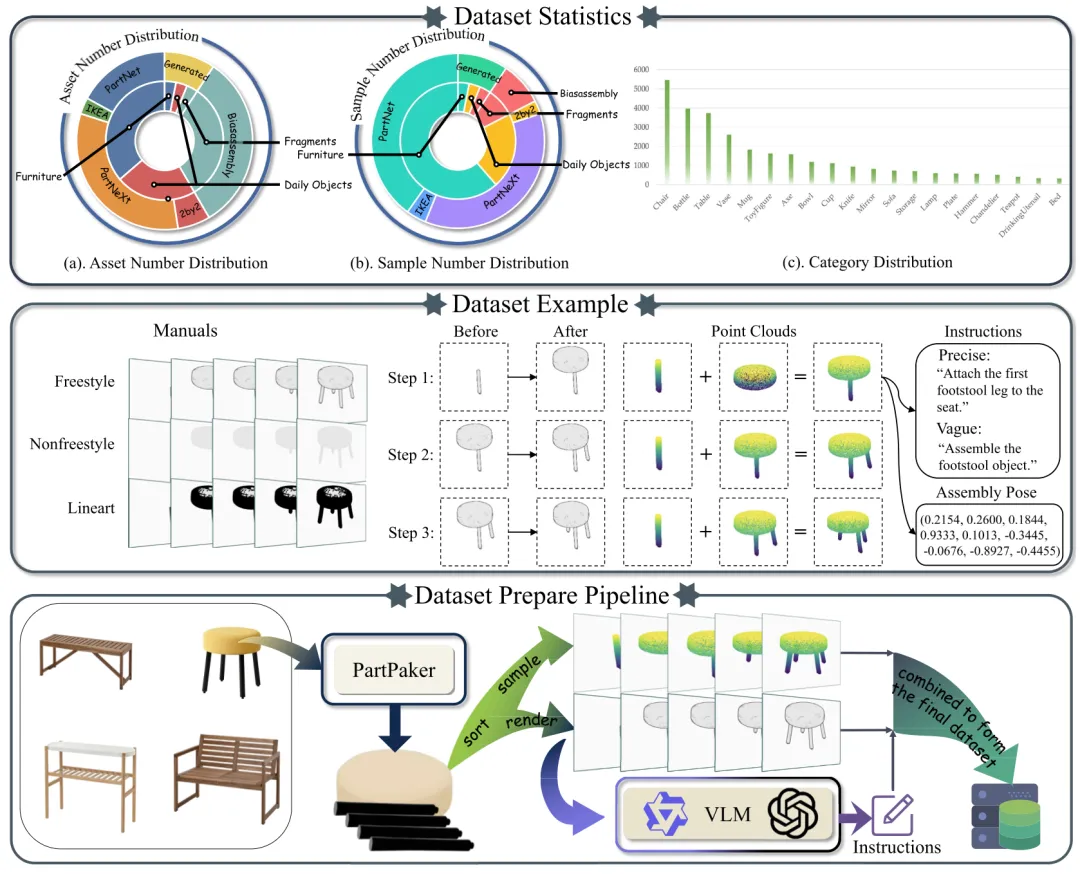
🔬 AssemLM:面向机器人装配的大规模空间多模态大语言模型
📌 Embodied AI · Spatial Reasoning · VLM · 6D Pose Estimation · Robotic Assembly
✨ 首次将SE(3)-等变几何感知与多模态大语言模型结合,实现高精度6D装配姿态预测与跨类别泛化
📖 空间推理是具身智能的基础能力,尤其在机器人装配等精细操作任务中至关重要。然而,现有视觉语言模型(VLM)主要依赖粗粒度的2D感知,缺乏精确的3D几何推理能力。为此,本文提出AssemLM,一个面向机器人装配的空间多模态大语言模型。该模型集成了SE(3)-等变点云编码器,将精细的3D几何特征注入多模态语言模型,以端到端的方式推理并预测任务关键的6D装配姿态。同时,作者构建了AssemBench,一个包含超过90万跨模态样本的大规模基准数据集。实验表明,AssemLM在多种装配场景下的6D姿态推理任务上达到了最先进的性能,并成功从合成训练迁移到真实机器人(Flexiv Rizon 4s)执行,展现了其在实际应用中的巨大潜力。
💡 将精确的3D几何感知“对齐”到语言模型的推理空间中,是解锁机器人精细操作能力的关键一步。
🔗 项目链接:https://assemlmhome.github.io/
一般的星球时间限制是1年,我们这个进去就是终身进去了,不会有时间限制。还有可以结合更多志同道合的朋友
