 夜雨聆风
夜雨聆风





简单实战一下,搭建一个飞书 AI 助手
前言
这个系列写到现在,前五篇分别聊了 Skill 系统、ReAct 循环、Context Engineering、文件系统记忆和 RAG 长期记忆。每一篇都是独立的概念加上能跑的代码片段,但要真正做成一个产品,中间还差不少东西——消息从哪来、会话怎么隔离、代码在哪执行、附件怎么处理。
这篇就来把这些缺的部分补上。最终产物是小圈,一个跑在飞书上的私人工作助手,把前面所有概念串进一个真实可用的项目里。
具体来说,要解决这几个问题:
-
多个人同时发消息,Agent 怎么保证各自的会话不串? -
之前讲的文件记忆和 RAG 记忆,怎么接进来? -
Skill 里有数据库操作、API 调用,怎么安全地执行? -
飞书消息的长连接怎么接?附件怎么下载? -
Loading 效果怎么做?
这几个问题分别对应了 Session 系统、记忆系统、沙箱执行、飞书接入,以及把它们串起来的 Runner。
一、整体架构
先把整体的数据流说清楚,再拆开讲每个模块。
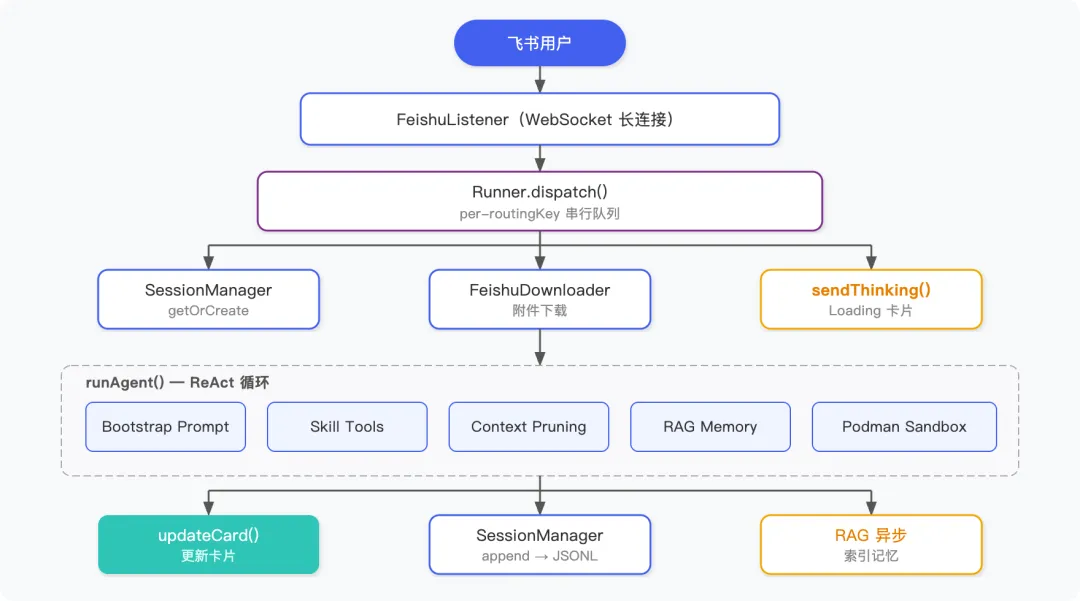
二、Session 系统
消息来了,怎么知道属于哪个对话?
飞书上的消息有很多种场景:私聊、群聊、群里的话题回复。系统收到一条消息后,第一件事就是判断它属于哪个对话。我们用一个叫 routingKey 的标识来做路由,由 session-key.js 生成:
exportfunctionresolveRoutingKey(chatType, senderId, chatId, threadId) {if (chatType === 'p2p') return`p2p:${senderId}`if (threadId) return`thread:${chatId}:${threadId}`return`group:${chatId}`}三种情况:
-
p2p:{open_id}:私聊,每个用户独立会话 -
thread:{chat_id}:{thread_id}:群里的话题,以话题为单位 -
group:{chat_id}:普通群消息,整个群共用一个会话
这个设计很关键。私聊的 key 是用户维度的,同一个人从不同端发消息都路由到同一个 Session;群聊默认群级别,如果有话题则精确到话题。
为什么还需要 Session
有了 routingKey 就能区分不同用户和群组的对话,但还有一个问题:用户没办法”开始新对话”。所有历史都堆在一起,上下文越来越长,模型回答质量也会下降。
Session 就是在 routingKey 之上加了一层会话生命周期管理——同一个 routingKey 下可以创建多个 Session,用户发 /new 就开启一轮新对话,之前的历史不带入。
落到磁盘上,大概长这样:
data/sessions/├── index.json # 所有 routingKey → Session 的映射├── s-a1b2c3d4e5f6.jsonl # 用户 A 的第一轮对话├── s-x7y8z9w0v1u2.jsonl # 用户 A 发了 /new 后的第二轮对话└── s-m3n4o5p6q7r8.jsonl # 群聊的对话index.json 记录每个 routingKey 当前激活的是哪个 Session:
{"p2p:ou_abc123": {"activeSessionId": "s-x7y8z9w0v1u2","sessions": [ {"id": "s-a1b2c3d4e5f6","createdAt": "2025-04-10T08:00:00Z","messageCount": 12 }, {"id": "s-x7y8z9w0v1u2","createdAt": "2025-04-11T10:30:00Z","messageCount": 3 } ] },"group:oc_xyz789": {"activeSessionId": "s-m3n4o5p6q7r8","sessions": [ {"id": "s-m3n4o5p6q7r8","createdAt": "2025-04-10T09:00:00Z","messageCount": 27 } ] }}每个 .jsonl 文件就是一个 Session 的完整记录,每行一条 JSON:
{"type":"meta","sessionId":"s-a1b2c3d4e5f6","routingKey":"p2p:ou_abc123","createdAt":"2025-04-10T08:00:00Z"}{"type":"message","role":"user","content":"帮我查一下明天的天气","ts":1712736000000}{"type":"message","role":"assistant","content":"明天北京晴,最高温 26°C","ts":1712736005000}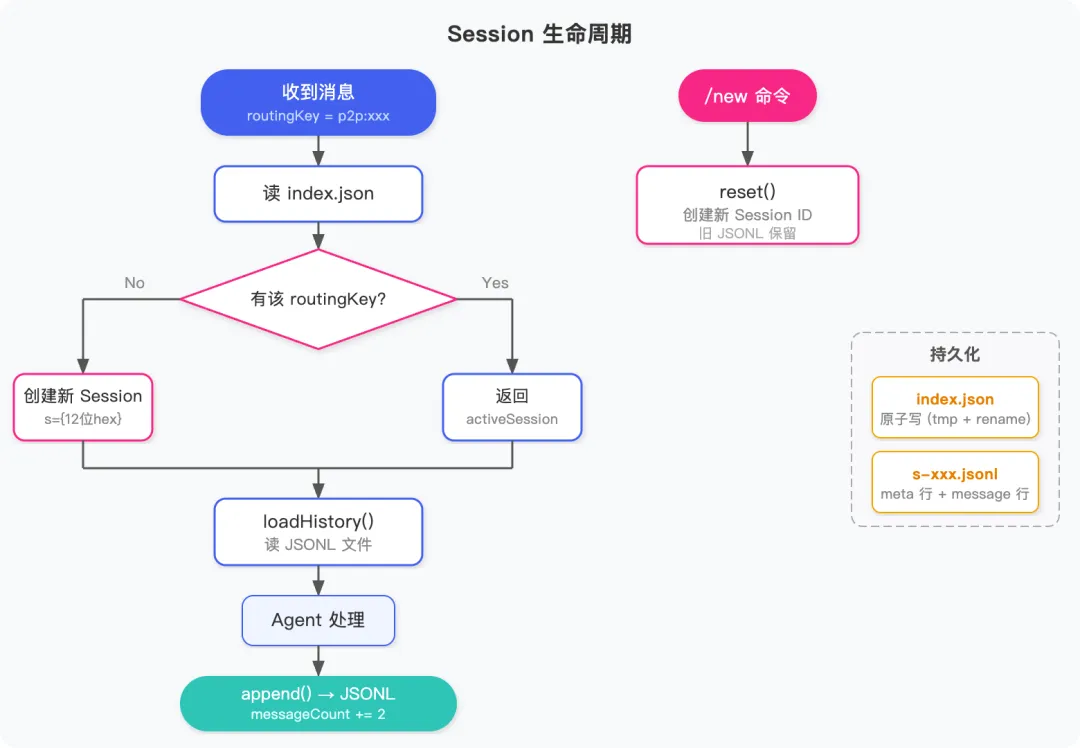
会话生命周期
核心是 SessionManager,完整代码在 src/session/session-manager.js:
exportclassSessionManager{constructor(dataDir) {this._sessionsDir = path.join(dataDir, 'sessions') fs.mkdirSync(this._sessionsDir, {recursive: true})// 清理上次未完成的原子写const tmpPath = path.join(this._sessionsDir, 'index.json.tmp')if (fs.existsSync(tmpPath)) fs.unlinkSync(tmpPath) }async getOrCreate(routingKey) {const index = this._readIndex()if (index[routingKey]) {const entry = index[routingKey]const session = entry.sessions.find(s => s.id === entry.activeSessionId)return session || this._createNewSession(routingKey, index) }returnthis._createNewSession(routingKey, index) }async reset(routingKey) {const index = this._readIndex()returnthis._createNewSession(routingKey, index) }getOrCreate 的逻辑:先查 index,找到当前活跃的 session 返回;没有就新建。reset 直接新建,旧历史留着但不再激活。
JSONL 持久化
每个 Session 对应一个 .jsonl 文件,每行一条记录:
async append(sessionId, {user, feishuMsgId, assistant}) {const now = Date.now()const userRecord = JSON.stringify({type: 'message', role: 'user', content: user, ts: now, feishuMsgId})const assistantRecord = JSON.stringify({type: 'message', role: 'assistant', content: assistant, ts: now})const jsonlPath = path.join(this._sessionsDir, `${sessionId}.jsonl`) fs.appendFileSync(jsonlPath, userRecord + '\n' + assistantRecord + '\n')// ... 同步更新 index 中的 messageCount}JSONL 格式的好处是 append-only,不需要读整个文件再写回,对高频写入很友好。读历史时:
async loadHistory(sessionId, maxTurns = 20) {const lines = fs.readFileSync(jsonlPath, 'utf-8').trim().split('\n').filter(Boolean)const messages = []for (const line of lines) {const record = JSON.parse(line)if (record.type !== 'message') continue messages.push({role: record.role, content: record.content, ...}) }return messages.slice(-maxTurns)}只取最近 maxTurns 条,防止历史过长撑爆上下文窗口。
注意,JSONL 里只存了 user 和 assistant 的纯文本对话,不包含中间的工具调用过程。工具调用的完整上下文存在另一个地方——data/ctx/ 目录下的 {sessionId}_ctx.json,由 ReAct 循环结束时写入。实际运行时,runAgent 会优先从 ctx.json 恢复上下文:
let messages = loadSessionCtx(sessionId, ctxDir)if (messages.length === 0) {// ctx.json 不存在时才退回用 JSONL 的纯对话历史 messages = history.map((m) => ({role: m.role, content: m.content}))}也就是说,从第二条消息起,ctx.json 就已经存在了,JSONL 的历史基本不会被读取。JSONL 的实际角色更像是一份干净的对话归档——不掺杂工具调用的中间过程,方便后续做数据分析或导出。真正驱动模型上下文的是 ctx.json。
index.json 原子写
所有 Session 的元数据(id、创建时间、消息数)都存在 index.json,这个文件会被频繁读写。为了防止写到一半进程崩了导致文件损坏:
_writeIndex(data) {const indexPath = path.join(this._sessionsDir, 'index.json')const tmpPath = indexPath + '.tmp' fs.writeFileSync(tmpPath, JSON.stringify(data, null, 2)) fs.renameSync(tmpPath, indexPath) // 原子操作}先写临时文件,再 rename。rename 在同一文件系统内是原子操作,要么成功要么失败,不会出现中间状态。构造函数里启动时也会清理上次遗留的 .tmp 文件。
per-routingKey 队列串行
这个逻辑在 Runner 里实现,但和 Session 强相关,所以一起说。
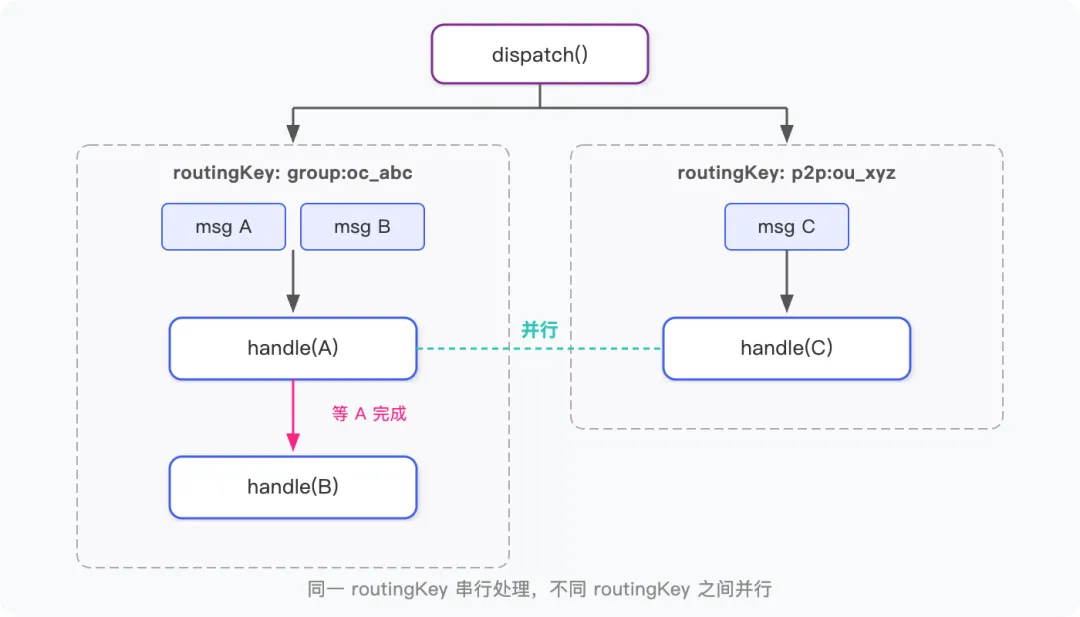
同一个 routingKey 的消息必须串行处理——如果 A 问了个问题还没回答,B 又来一条(同一个群里),两个 runAgent() 并发执行会造成 Session 写入竞争。
Runner 的解决方式是每个 routingKey 维护一个队列和一个 Worker 协程。this._wakers 是一个 Map,存的是每个 routingKey 对应 Worker 的唤醒函数——Worker 空闲时会把自己的 resolve 注册进去,等新消息来了调用它就能唤醒 Worker:
async dispatch(inbound) {const {routingKey} = inboundif (!this._queues.has(routingKey)) {// 第一次收到这个 routingKey 的消息,创建队列并启动 Workerthis._queues.set(routingKey, [])this._startWorker(routingKey) }// 消息入队this._queues.get(routingKey).push(inbound)// 如果 Worker 正在等待(空闲),唤醒它const waker = this._wakers?.get(routingKey)if (waker) waker()}Worker 处理完当前消息后,检查队列是否还有新消息。没有就挂起等待,直到被 dispatch 唤醒或超时销毁:
async _workerLoop(routingKey) {while (true) {const queue = this._queues.get(routingKey)if (!queue || queue.length === 0) {// 队列空了,挂起等待新消息或超时const gotMessage = awaitnewPromise(resolve => {// 把 resolve 注册为唤醒函数,dispatch() 调用它就能唤醒this._wakers.set(routingKey, () => resolve(true))// 超时后 resolve(false),Worker 自动退出 setTimeout(() => resolve(false), this._idleTimeoutS * 1000) })if (!gotMessage) {// 超时,清理资源,Worker 退出this._queues.delete(routingKey)this._wakers.delete(routingKey)return }continue }// 取一条消息,处理完再取下一条——串行const inbound = queue.shift()awaitthis._handle(inbound) }}这个模式保证了同一会话的消息严格按顺序处理,同时不同 routingKey 之间完全并行,互不影响。
超时时间默认 5 分钟,设得比较短是因为创建 Worker 的成本很低(就是启动一个 async 循环),但一直不释放会白占内存。几百个群各挂一个空闲 Worker 没有意义,不如超时销毁,下次来消息再建。
三、记忆系统
文件记忆、上下文管理、RAG 长期记忆的原理在前几篇已经讲过,这里只说它们在小圈里是怎么串到一起的。
三层怎么接入
文件记忆的接入点在 runAgent 入口——每次调用都从 workspace/ 读取 soul.md、user.md、agent.md、memory.md,拼进系统提示词。Agent 运行中可以通过 write_file 修改这些文件,下次对话自动生效。
上下文管理跑在 ReAct 循环里,每一轮迭代都会执行。先调 pruneToolResults 裁剪早期工具返回,再检查 token 数,超过阈值就调 maybeCompress 压缩旧对话为摘要。压缩后的上下文存到 data/ctx/{sessionId}_ctx.json,下次用户发消息时直接恢复。
RAG 记忆的接入分写和读两个点。写在 Runner 里——每次 Agent 回复后,异步调用 storeMemory 把对话存入 PostgreSQL + pgvector:
// runner.js — Agent 回复后storeMemory({sessionId: session.id, routingKey,userMessage: userTextForLog,assistantReply: reply,turnTs: Date.now(),dbDsn: this._dbDsn,}).catch(e =>console.error('[Runner] storeMemory error:', e.message))异步执行、失败不影响主流程。存储过程会用 LLM 提取摘要,用 embedding 模型生成向量,写入数据库。
读的一端是 memory_search 工具,按 routingKey 隔离,每个用户只能搜到自己的历史。这里有个设计取舍:我们没有每次都自动检索(那样浪费 token),而是把它当普通工具暴露给 Agent,让它自己判断什么时候需要翻历史。
三层各管一个时间尺度:文件记忆管”我是谁、用户是谁”,上下文管理管”这轮对话聊了什么”,RAG 管”以前聊过什么”。
四、沙箱执行
为什么需要沙箱
Skill 脚本里有很多”危险”操作:查数据库、调第三方 API、写文件、有时候还要执行用户给的代码片段。如果直接在主进程里跑,有几个问题:
-
凭证暴露:主进程里有所有凭证(LLM API Key、数据库密码、飞书密钥等),Skill 脚本直接跑在主进程就能访问全部 -
资源失控:一个死循环或者内存泄漏会把主进程拖垮 -
文件系统污染:乱写文件没有隔离
解决方案是用容器做沙箱。每次执行 Skill 脚本,起一个新容器,跑完自动销毁(--rm)。
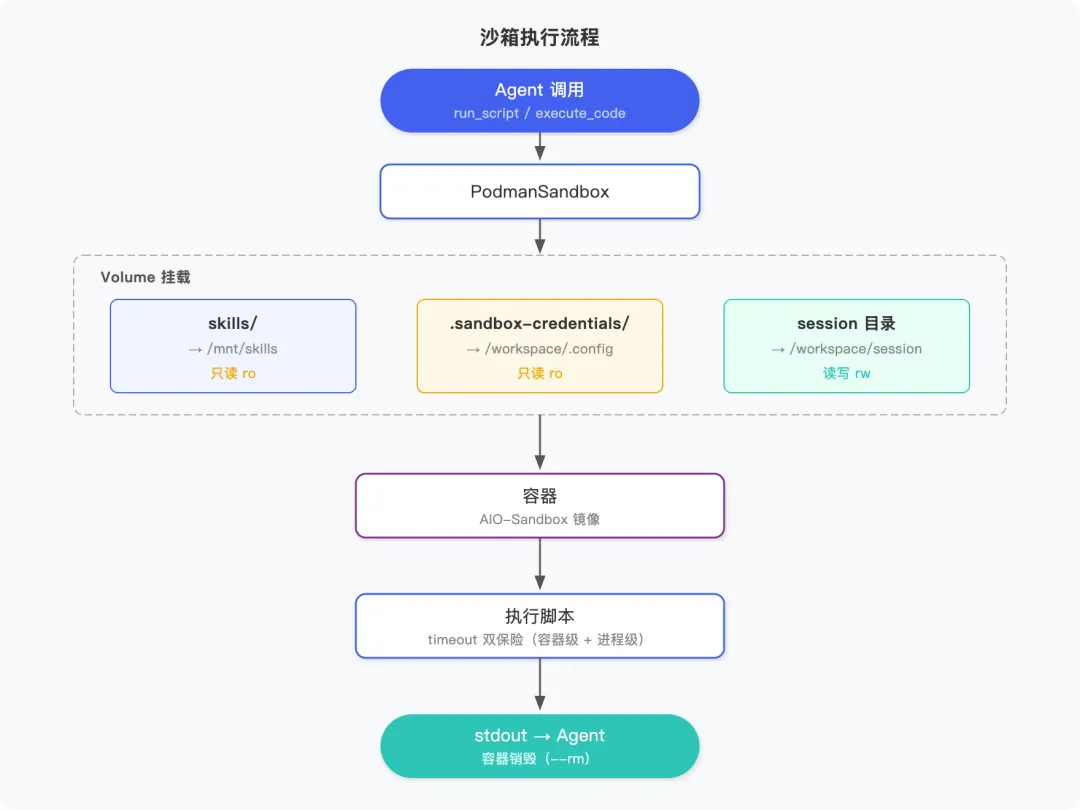
PodmanSandbox 实现
exportclassPodmanSandbox{constructor({image = 'xiaoquan-sandbox:latest', timeoutMs = 30000, dataDir = './data'} = {}) {this._image = imagethis._timeoutMs = timeoutMsthis._dataDir = path.resolve(dataDir)this._credentialsDir = path.join(this._dataDir, '.sandbox-credentials') }构造时接受三个参数:容器镜像名、超时时间(毫秒)、数据目录。凭证目录 .sandbox-credentials 放在 dataDir 下,注意这个目录要加入 .gitignore。
凭证注入
凭证以 JSON 文件形式写入 credentialsDir,挂载进容器的 /workspace/.config:
writeCredentials(credentials) { fs.mkdirSync(this._credentialsDir, {recursive: true})for (const [name, data] ofObject.entries(credentials)) { fs.writeFileSync( path.join(this._credentialsDir, `${name}.json`),JSON.stringify(data, null, 2) ) }}在 index.js 里启动时注入:
const sandbox = new PodmanSandbox({...})sandbox.writeCredentials({feishu: {app_id: config.feishu.app_id, app_secret: config.feishu.app_secret},})Skill 脚本通过读取 /workspace/.config/feishu.json 获取凭证,而不是从环境变量读。好处是凭证不会出现在主进程的环境变量里,容器内也只能拿到 writeCredentials 显式写入的那几个,主进程的其他密钥(比如 LLM API Key)容器里访问不到。
文件挂载与执行
_buildMounts(sessionDir) {const mounts = ['-v', `${path.resolve('skills')}:/mnt/skills:ro`, // Skill 脚本只读 ]if (fs.existsSync(this._credentialsDir)) { mounts.push('-v', `${this._credentialsDir}:/workspace/.config:ro`) // 凭证只读 }if (sessionDir) {const absSessionDir = path.resolve(sessionDir) fs.mkdirSync(absSessionDir, {recursive: true}) mounts.push('-v', `${absSessionDir}:/workspace/session:rw`) // 会话目录可读写 }return mounts}三个挂载点的权限设计很清楚:
-
skills/:只读,脚本本身不能被修改 -
.sandbox-credentials/:只读,凭证不能被覆盖 -
session/{sessionId}/:读写,供附件上传(uploads/)和结果输出(outputs/)
执行时:
async execute(scriptPath, args = '', {sessionDir = null} = {}) {const mounts = this._buildMounts(sessionDir)const containerScriptPath = `/mnt/skills/${path.relative(path.resolve('skills'), scriptPath)}`const cmd = ['run', '--rm',`--timeout=${Math.ceil(this._timeoutMs / 1000)}`, '--network=host', ...mounts, this._image, 'python3', containerScriptPath, ...args.split(' ').filter(Boolean), ] try { const {stdout, stderr} = await execFileAsync('podman', cmd, {timeout: this._timeoutMs}) if (stderr) console.error('[Sandbox stderr]', stderr) return stdout.trim() } catch (e) { if (e.killed) return `执行超时(${this._timeoutMs /1000}s)`return`执行失败: ${e.message}` }}注意 --network=host 是因为 Skill 脚本需要访问本机的数据库和内部 API。如果你的场景是完全隔离网络,可以去掉这个选项。超时控制有两层:Podman 自己的 --timeout 和 Node 的 execFileAsync timeout,双保险。
用户上传的文件被 Runner 放到 data/workspace/sessions/{sessionId}/uploads/,挂载后在容器内是 /workspace/session/uploads/,Skill 脚本可以直接读。Skill 生成的文件写到 /workspace/session/outputs/,宿主机上对应的路径就可以下载或返回给用户。
另一种思路:把整个 Agent 扔进沙箱
小圈的沙箱只隔离 Skill 脚本的执行——Agent 的 ReAct 循环、LLM 调用都在主进程里,容器只负责跑具体的 Python 脚本,跑完就销毁。这种方式很轻量,一个 execFileAsync 就搞定了通信。
但还有一种更彻底的做法:把整个 Agent 放进容器。之前介绍过的 NanoClaw:一个你真正能看懂的个人 AI 助手 就是这么做的——容器里跑的不是单个脚本,而是完整的 Claude Agent SDK,LLM 调用也发生在容器内部。容器长驻运行,idle 30 分钟后才销毁。
这两种方案的差异集中在三个地方:
沙箱粒度。小圈沙箱化的是”工具执行”,Agent 本身是可信的;NanoClaw 沙箱化的是”Agent 本身”,连 Agent 的推理过程都跑在隔离环境里。后者对 prompt injection 的防御更强——即使 Agent 被诱导执行恶意命令,也出不了容器。
凭证保护。小圈通过文件挂载注入凭证,只挂载 Skill 需要的那几个,LLM API Key 不进容器。NanoClaw 更进一步,在宿主机上跑了一个凭证代理(HTTP 代理服务),容器里的 ANTHROPIC_API_KEY 只是个 placeholder,所有请求经过代理时才替换成真实 key,.env 文件也用 /dev/null 遮蔽。容器里的代码完全拿不到任何真实密钥。
通信复杂度。小圈是一次性容器,传入参数、拿 stdout、结束,很简单。NanoClaw 的容器是长驻的,需要一套文件系统 IPC——宿主机往 input/ 目录写文件注入新消息,容器往 messages/ 目录写文件发送回复,stdout 用边界标记(---NANOCLAW_OUTPUT_START---)区分真正的输出和 SDK 的日志噪声。基础设施重了不少。
小圈选轻量方案是因为 Skill 脚本的执行范围有限,主进程里的 Agent 是自己写的、可控的。如果你的场景里 Agent 可能执行任意用户代码,或者对安全隔离要求更高,NanoClaw 那种”把整个 Agent 扔进沙箱”的方式更合适。
五、飞书接入
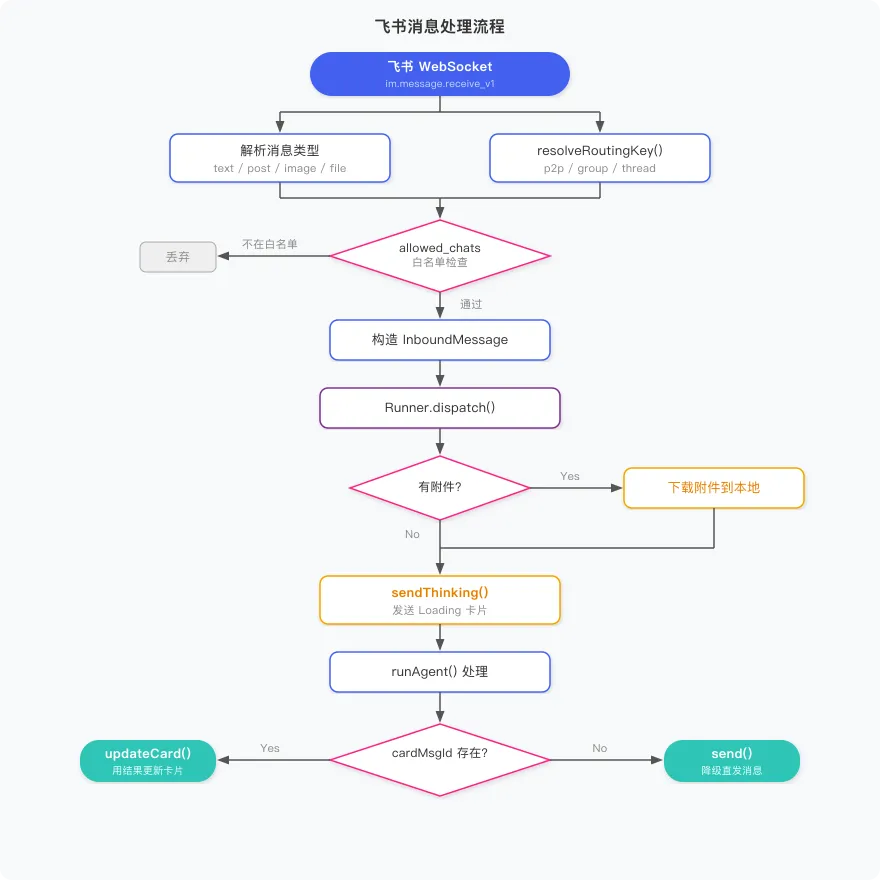
WebSocket 长连接
飞书 Bot 接收消息有两种方式:webhook(HTTP 回调)和 WebSocket 长连接。小圈选 WebSocket,原因很简单——本地开发时不需要公网地址,部署时也不需要配置 Nginx 反向代理,直连飞书服务器就行。
FeishuListener 封装了飞书官方 SDK 的 WSClient:
exportclassFeishuListener{constructor({appId, appSecret, onMessage, allowedChats = []}) {this._onMessage = onMessagethis._allowedChats = newSet(allowedChats)this._client = new lark.Client({appId, appSecret})this._wsClient = new lark.WSClient({ appId, appSecret,eventDispatcher: new lark.EventDispatcher({}).register({'im.message.receive_v1': async (data) => {awaitthis._handleMessage(data) }, }),loggerLevel: lark.LoggerLevel.WARN, }) }allowedChats 是群组白名单,留空则允许所有群。私聊始终放行(chatType === 'p2p' 直接返回 true)。
为什么要有白名单?Bot 加入群后,群里所有消息它都能收到(开了消息权限的话),但不是每个群的消息都应该触发 Agent。白名单让你精确控制哪些群接入。
消息类型解析
飞书消息有多种类型,_extractContent 统一处理:
_extractContent(msgType, contentJson) {// ...if (msgType === 'text') { content = parsed.text || '' } elseif (msgType === 'post') { content = this._extractPostText(parsed) } elseif (msgType === 'image') { attachment = {msgType: 'image', fileKey: parsed.image_key, fileName: `${parsed.image_key}.jpg`} } elseif (msgType === 'file') { attachment = {msgType: 'file', fileKey: parsed.file_key, fileName: parsed.file_name || parsed.file_key} }return {content, attachment}}post 类型是富文本,结构比较复杂,需要递归提取文本段落:
_extractPostText(data) {const parts = []const zhContent = data?.zh_cn || data?.en_usif (!zhContent) return''if (zhContent.title) parts.push(zhContent.title)for (const paragraph of (zhContent.content || [])) {for (const element of paragraph) {if (element.tag === 'text') parts.push(element.text) } }return parts.join(' ')}图片和文件不直接传内容,只拿到 fileKey,实际下载发生在 Runner 处理消息的时候。
附件下载
FeishuDownloader 负责把附件从飞书服务器拉到本地:
async download(msgId, attachment, sessionId) {const destDir = path.join(this._dataDir, 'workspace', 'sessions', sessionId, 'uploads') fs.mkdirSync(destDir, {recursive: true})const destPath = path.join(destDir, attachment.fileName)const resp = awaitthis._client.im.messageResource.get({path: {message_id: msgId, file_key: attachment.fileKey},params: {type: attachment.msgType}, })if (resp?.data) {const buffer = Buffer.isBuffer(resp.data) ? resp.data : Buffer.from(resp.data) fs.writeFileSync(destPath, buffer)return destPath }returnnull}下载到 data/workspace/sessions/{sessionId}/uploads/,这个路径正好是沙箱挂载 /workspace/session/ 的宿主机对应路径,所以 Skill 脚本不需要任何额外处理就能读到用户上传的文件。
Runner 处理附件时会构造一条特殊的用户消息告诉 Agent:
function_buildAttachmentMessage(sandboxPath, originalText) {let msg = `用户发来了文件,已自动保存至沙盒路径:\n\`${sandboxPath}\`\n请根据文件内容完成用户的需求。`if (originalText) msg += `\n\n用户附言:${originalText}`return msg}这样 Agent 知道文件在哪,可以直接告诉 Skill 脚本去读。
卡片消息与 Loading 效果
纯文本消息体验很差,飞书支持”卡片消息”(interactive),可以在收到回复后动态更新内容。这正好用来做 Loading 效果。
流程是:
-
用户发消息,立刻发一张”思考中”卡片,拿到这张卡片的 message_id -
调用 runAgent(),期间用户看到”思考中” -
Agent 返回结果,用结果更新那张卡片
async sendThinking(routingKey, rootId = null) {const card = this._buildCard('⏳ 思考中,请稍候...')// 按 routingKey 类型选择发送方式...return resp?.data?.message_id || null}async updateCard(cardMsgId, content) {const card = this._buildCard(content)awaitthis._client.im.message.patch({path: {message_id: cardMsgId},data: {content: card}, })}卡片内容用 lark_md 格式,支持 Markdown 渲染,粗体、代码块、列表都能用。
Runner 里的调用顺序:
const cardMsgId = awaitthis._sender.sendThinking(routingKey, rootId)const reply = awaitthis._agentFn(userContent, history, ...)if (cardMsgId) {awaitthis._sender.updateCard(cardMsgId, reply)} else {awaitthis._sender.send(routingKey, reply, rootId)}sendThinking 可能失败(网络问题),这时候 cardMsgId 为 null,降级为普通发送。
Slash 命令
对话型 Bot 经常需要一些控制命令,比如重置会话、查看状态。小圈用斜杠命令实现:
const SLASH_COMMANDS = newSet(['/new', '/verbose', '/help', '/status'])async _handleSlash(inbound) {const text = inbound.content.trim()if (!text.startsWith('/')) returnnullconst [cmd, ...args] = text.split(/\s+/)if (!SLASH_COMMANDS.has(cmd)) returnnullswitch (cmd) {case'/new': {const session = awaitthis._sessionMgr.reset(routingKey)return`已创建新对话 (${session.id}),之前的历史不会带入。` }case'/verbose': {const arg = args[0]?.toLowerCase()if (arg === 'on' || arg === 'off') {awaitthis._sessionMgr.updateVerbose(routingKey, arg === 'on')return`详细模式已${arg === 'on' ? '开启' : '关闭'}` }// 无参数则返回当前状态 }case'/status': {const session = awaitthis._sessionMgr.getOrCreate(routingKey)return`会话 ID: ${session.id}\n消息数: ${session.messageCount}\n详细模式: ${session.verbose ? '开启' : '关闭'}` } }}/verbose on 开启后,Agent 每跑一个工具就会实时推送中间步骤,方便调试或者让用户看到 Agent 在干什么。这是通过 runAgent() 的 onStep 回调实现的,在 index.js 里组装:
const agentFn = async ( userMessage, history, sessionId, routingKey, rootId, verbose,) => {const onStep = verbose ? ({step, toolName, args, result}) => { sender .send( routingKey,`💭 [Step ${step}] ${toolName}(${JSON.stringify(args)})\n${result}`, rootId, ) .catch(() => {}) } : nullreturn runAgent({userMessage, history, sessionId, routingKey, config, onStep})}Slash 命令在 _handle() 里优先处理,命中则直接返回文本消息,不经过 Agent:
async _handle(inbound) {const slashReply = awaitthis._handleSlash(inbound)if (slashReply !== null) {awaitthis._sender.sendText(routingKey, slashReply, rootId)return }// ... 正常 Agent 处理流程}断线重连
WebSocket 连接不稳定是常态,runForever 做了无限重试:
exportasyncfunctionrunForever(listener) {while (true) {try {await listener.start() } catch (e) {console.error('[FeishuListener] connection error, retrying in 5s:', e.message, )awaitnewPromise((r) => setTimeout(r, 5000)) } }}listener.start() 是一个长期阻塞的 promise,正常情况下不会 resolve。如果连接断开抛异常,5 秒后重试。
六、运行示例
启动
配置文件 config.yaml 从模板复制并填入你的飞书应用凭证:
feishu:app_id:'${FEISHU_APP_ID}'app_secret:'${FEISHU_APP_SECRET}'allowed_chats:[]# 留空则允许所有群,填群 ID 则只接入指定群llm:model:'claude-sonnet-4-6'max_iter:10memory:workspace_dir:'./workspace'db_dsn:'postgresql://postgres:postgres@localhost:5432/agent_memory'token_threshold:80000sandbox:image:'xiaoquan-sandbox:latest'timeout_ms:30000data_dir:'./data'环境变量注入(${FEISHU_APP_ID} 这种语法在 config.js 里处理):
export FEISHU_APP_ID=cli_xxxxxxxxxexport FEISHU_APP_SECRET=xxxxxxxxxnode src/index.js启动后输出:
=== 小圈 · 飞书工作助手 ===[Session] initialized[Sandbox] credentials injected[Feishu] WebSocket connecting...普通对话
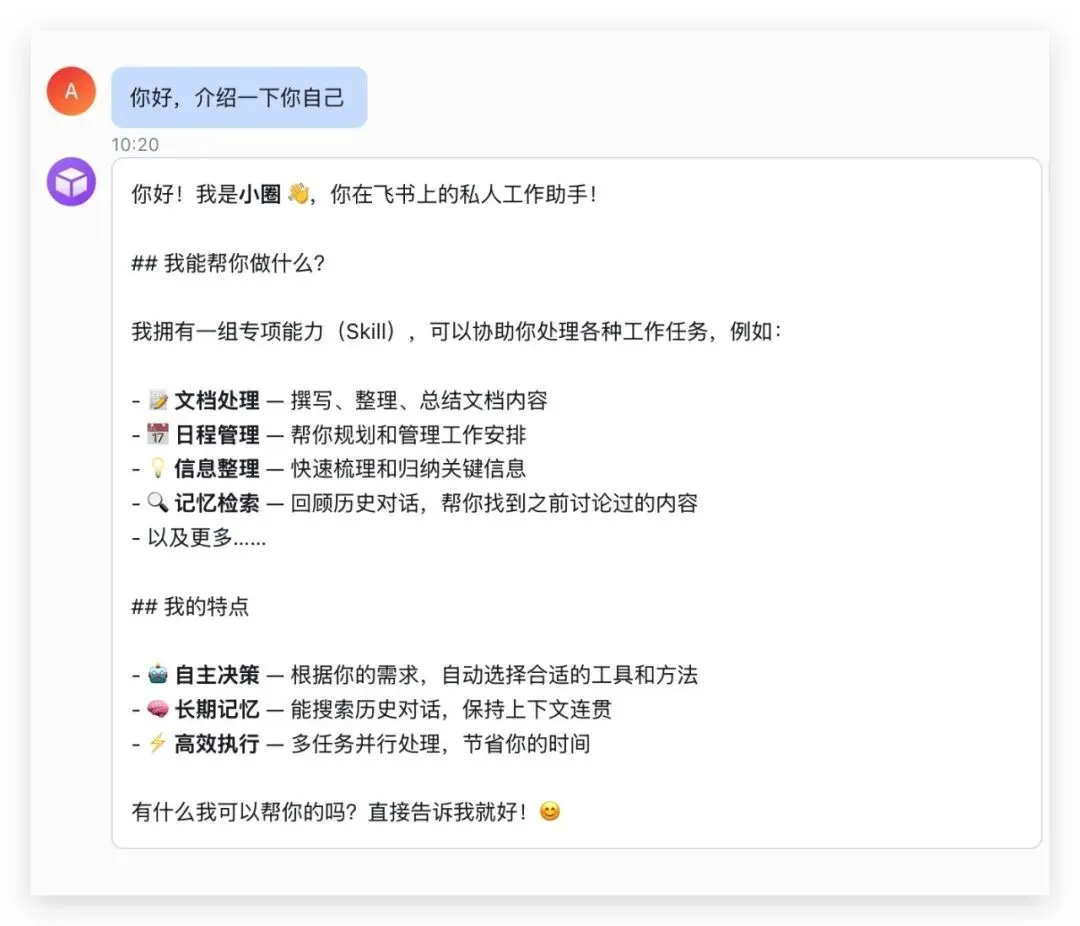
最基本的场景——私聊发一条文本消息,Agent 直接回复:
Skill 调用
当用户的需求涉及具体操作(查数据、调 API),Agent 会自动走 Skill 流程:先 list_skills 查看有哪些能力,再 get_skill 获取指令,最后调用沙箱执行脚本。

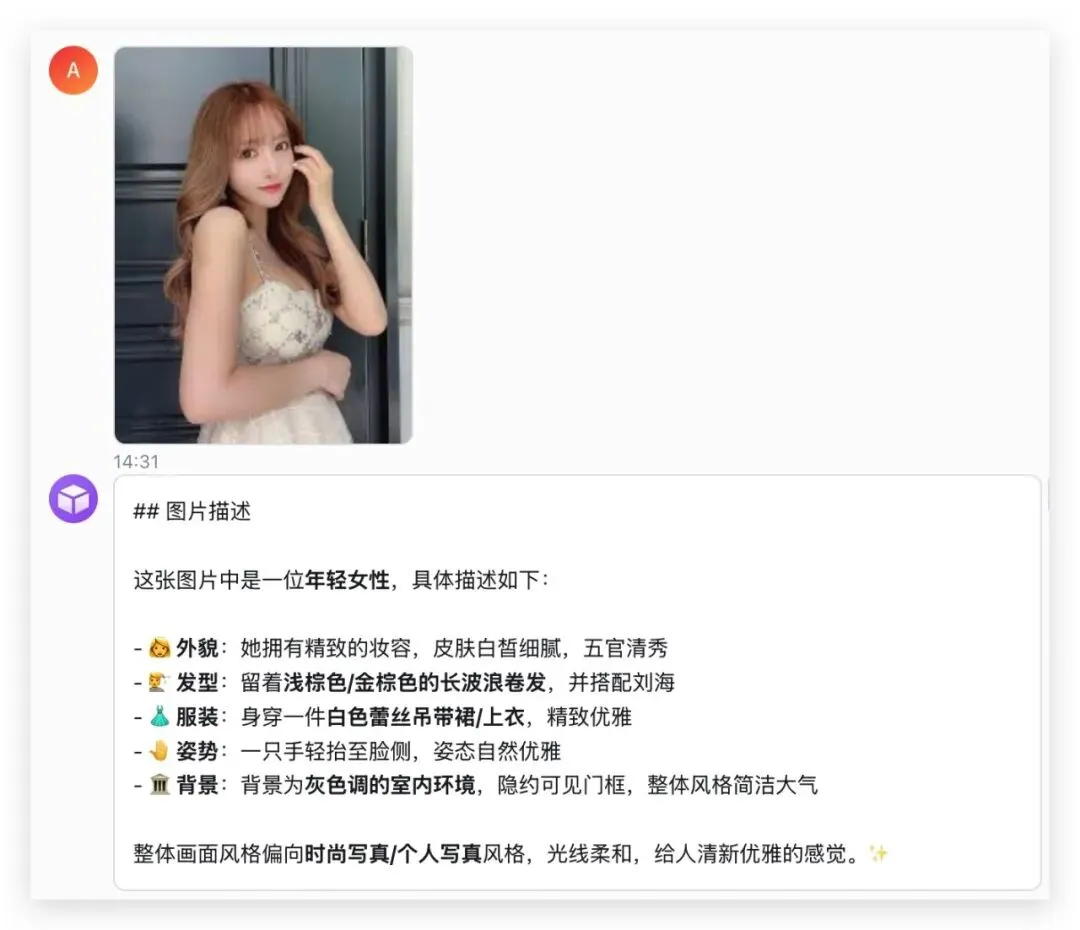
图片理解
私聊发送小姐姐图片,Runner 下载附件后将图片转为 multimodal 内容直接注入 Agent 的用户消息,Agent 凭自身的视觉能力准确分析图片:
会话管理
发送 /new 开启新对话,之前的历史不带入。发送 /status 查看当前会话信息:
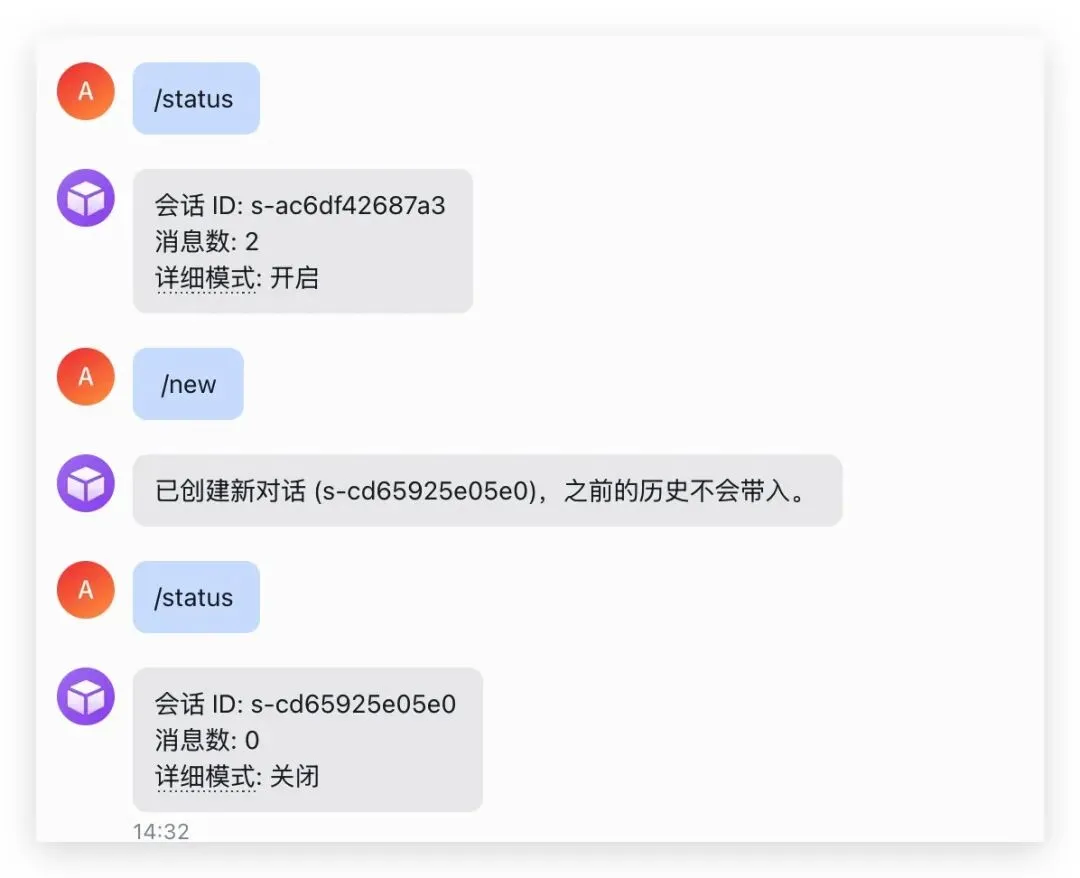
跨会话记忆
先聊一条”我喜欢打篮球”,然后 /new 开启新对话,再问”我有什么爱好”。Agent 通过 memory_search 从记忆库中检索到之前的对话:
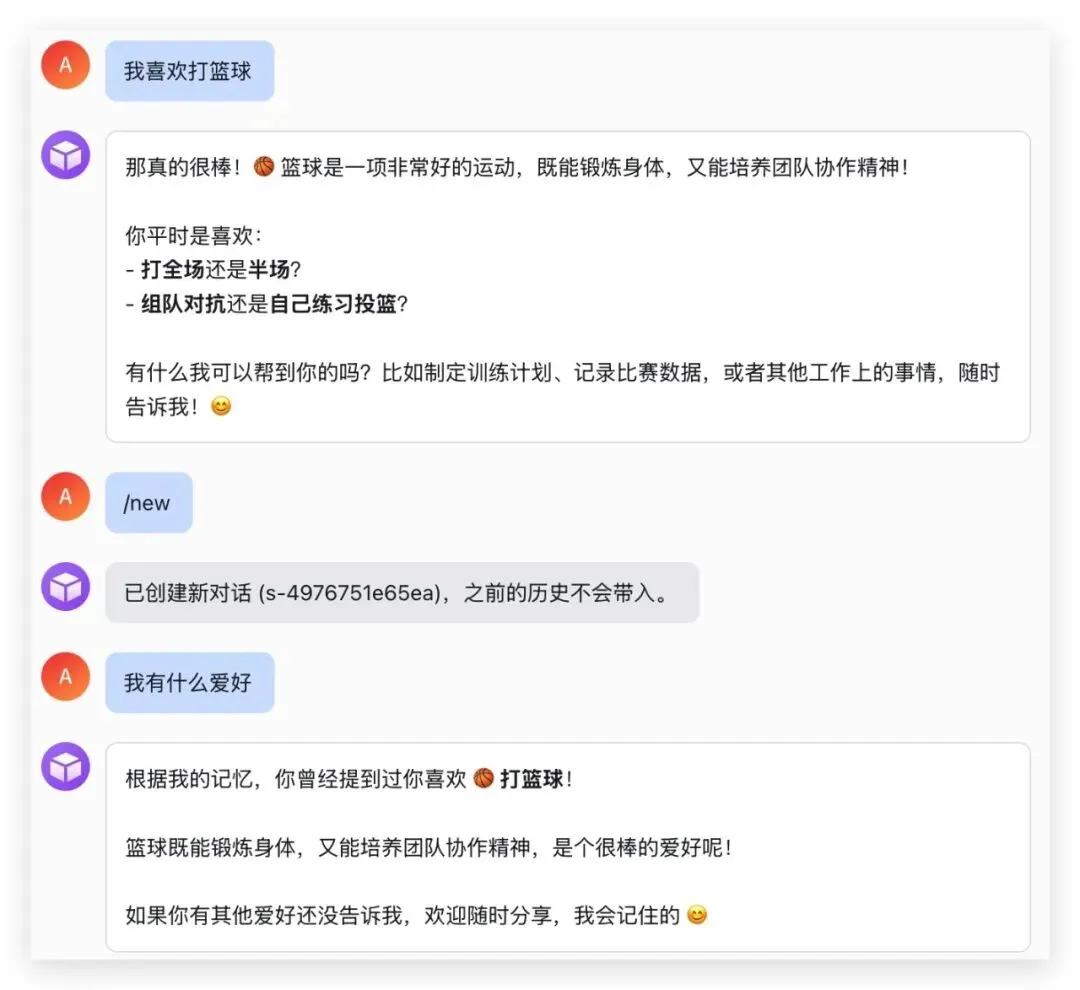
收尾
本篇做的事情可以用一句话概括:把之前分散的概念串成一个能跑的产品。
Skill、ReAct、上下文管理、记忆系统,单独拎出来都能跑通 demo,但要真正上线还差很多胶水——消息怎么路由、附件怎么下载、两条消息同时来了会不会串、进程崩了数据会不会丢。这些工程问题不难,但不解决就跑不起来。
小圈的模块划分:Runner 管调度,Session 管状态,沙箱管执行,记忆管上下文。每个模块的职责边界清楚,替换任何一个都不影响其他——比如把飞书换成其他渠道,只需要重写 feishu/ 目录,Runner 和 Agent 不用改动。