 夜雨聆风
夜雨聆风





AI距离成为“物理学家”还有多远?上交团队发布PRL-Bench,探索大模型科研能力边界

随着AI智能体(Agent)时代来临,智能体驱动的科学研究(Agentic Science)应运而生,一个本质问题也随之浮现:
当前的AI在科研领域的能力边界在哪,是否能像真正的科学家一样执行科研工作?
为了回答这一问题,来自上海交通大学人工智能学院、物理与天文学院、李政道研究所、赛兰德智能、深势科技等科研机构的联合团队建立了一个Ph.D.级别的前沿物理研究评测基准——PRL-Bench(Physics Research by LLMs)。这一测试基准基于物理学领域权威期刊 Physiscs Review Letters 上的100项真实研究构建,超过十位物理领域专家提取其中研究背景、工作流与核心结果,构建可验证的研究任务,用以评估大模型在真实物理科研任务中自主规划、长程探索、完整复现真实研究的能力。
Arxiv链接:http://arxiv.org/abs/2604.15411
Github链接:https://github.com/sjtu-sai-agents/PRL_Bench
Hugging Face链接:https://huggingface.co/datasets/AdrianMiao/PRL_Bench

(PRL-Bench技术报告,Arxiv链接:http://arxiv.org/abs/2604.15411)
在PRL-Bench上,团队测试了GPT-5.4、Gemini-3.1-Pro、Claude-Opus-4.6、Doubao-Seed-2.0-Pro等主流模型,结果令人印象深刻:
没有模型超过50分
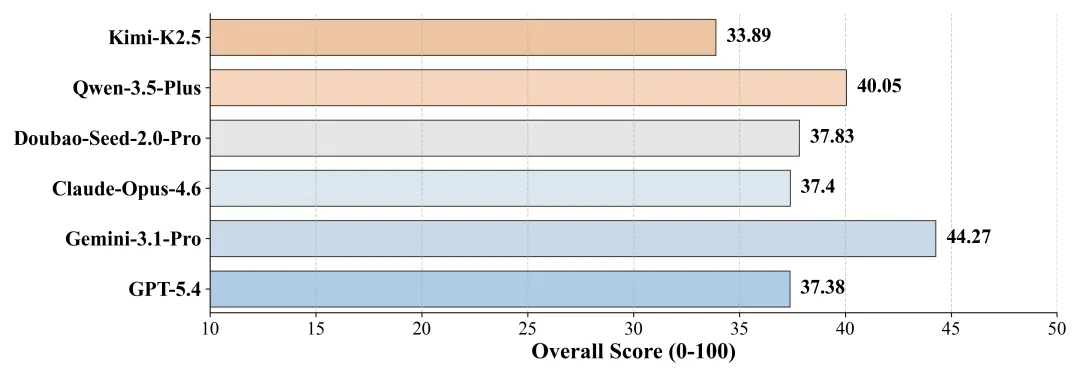
(各主流模型在PRL-Bench上表现出研究能力短板)
而对于“AI距离成为物理学家还有多远?”我们给出的回答是:当前大模型的能力,距离“能做科研”仍存在结构性差距,创造真正合格的AI科学家依然任重道远。
🤔从“做题机器”到“科学家”,AI还差什么?
过去几年,大模型在科学任务上的表现突飞猛进:
-
OlympiadBench、OlympicArena:奥赛级推理
-
Humanity’s Last Exam(HLE):高难度综合能力
但这些 benchmark 有一个共同局限:问题路径是“已知的”,换句话说,它们更像是考试,而不是科研。
而真实科研的核心在于:
-
需要自主规划
-
需要进行长程探索(long-horizon exploration)
-
需要工具协同(搜索,代码,计算)
特别的,理论与计算物理方向格外适合用来测试AI的这几项能力,因为这一方向:
-
知识壁垒高,推理复杂
-
进行研究时会自然地引入工具调研,例如:检索论文并整合信息,编写代码以执行数值计算
-
无需操纵实验仪器,有能被模型独立复现的可能性
PRL-Bench 正是为此而生——它试图回答:
如果把 AI 放进真实的物理科研场景,它的表现距离科学家还有多远?
PRL-Bench:将真实 PRL 研究论文转化成题目
在PRL-Bench 的构建过程中,我们:
-
📄 精选100 篇权威论文,全部来自 Physical Review Letters 最新期刊(2025–2026)
-
🔬 与10+ 物理学专家密切合作,提取其中研究背景、工作流与核心结果并进行简要改编
PRL-Bench 共覆盖五大前沿子领域 🧩
-
天体物理(Astro)
-
凝聚态(Cond-Mat)
-
高能物理(HEP)
-
量子信息(Quantum)
-
统计物理(Stat)
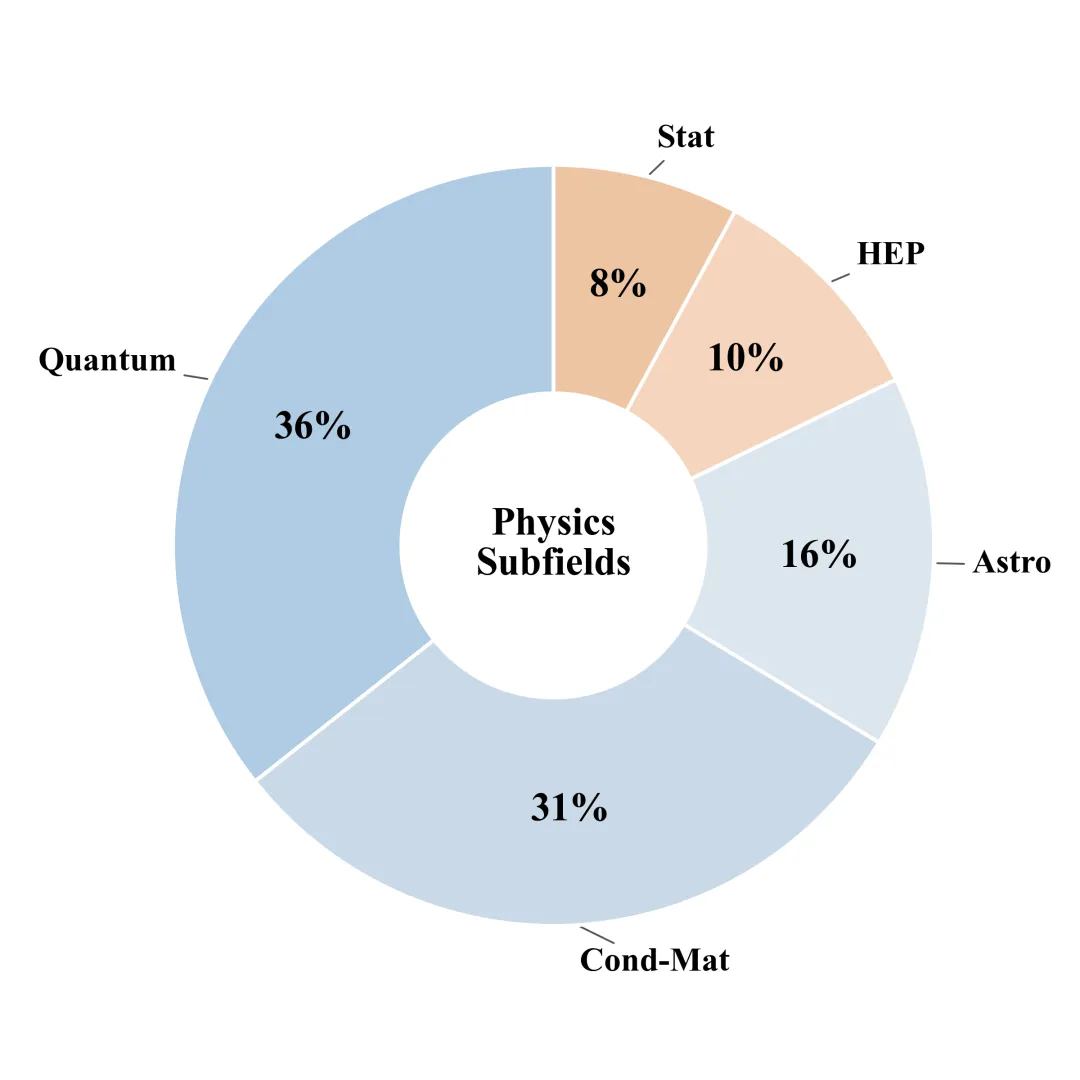
(PRL-Bench题目子领域分布)
在任务设计上,PRL-Bench 有不同于传统 benchmark的三大核心特性:
-
探索导向(Exploration-oriented):以最简的信息给出研究动机 + 目标,避免给出解题路径提示
-
长程任务(Long-horizon):多步推导 + 计算 + 验证,确保推理难度与上下文长度
-
可验证性(Verifiability):每一项任务既有可验证答案,也有精细化的rubric,细致刻画真实科研工作流
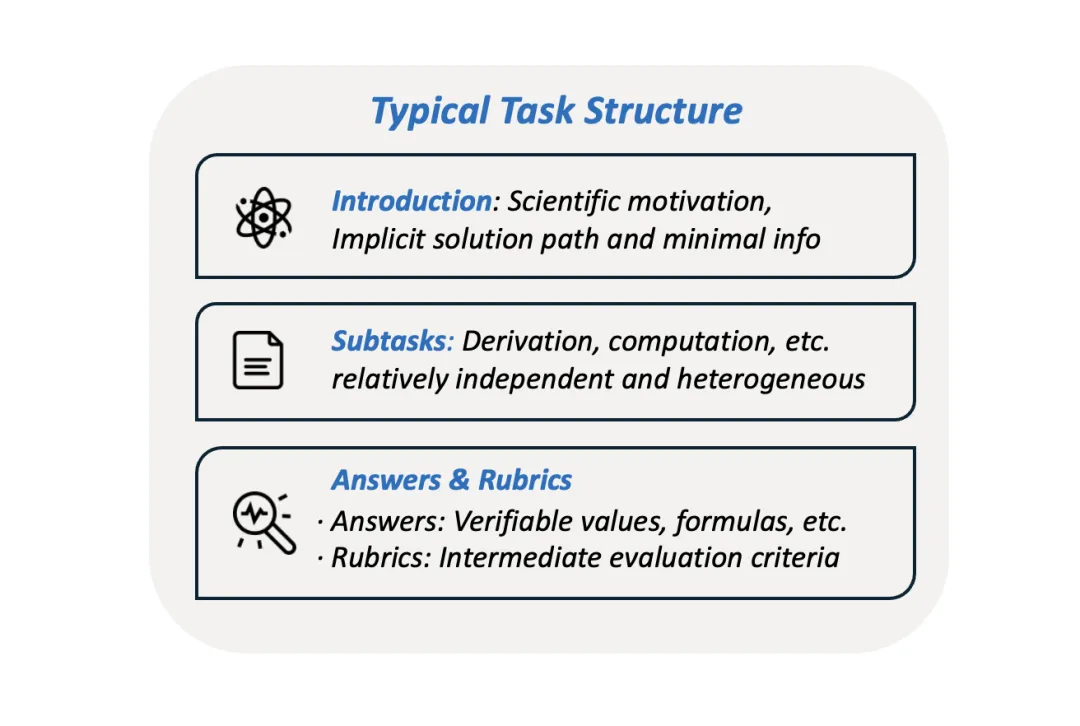
(PRL-Bench题目结构)
⚠️ 为什么模型做不好科研?问题不在“算不出来”
在研究中我们发现一个直观结论是:问题不在“算不出来”,而在许多关键的“一念之差”。
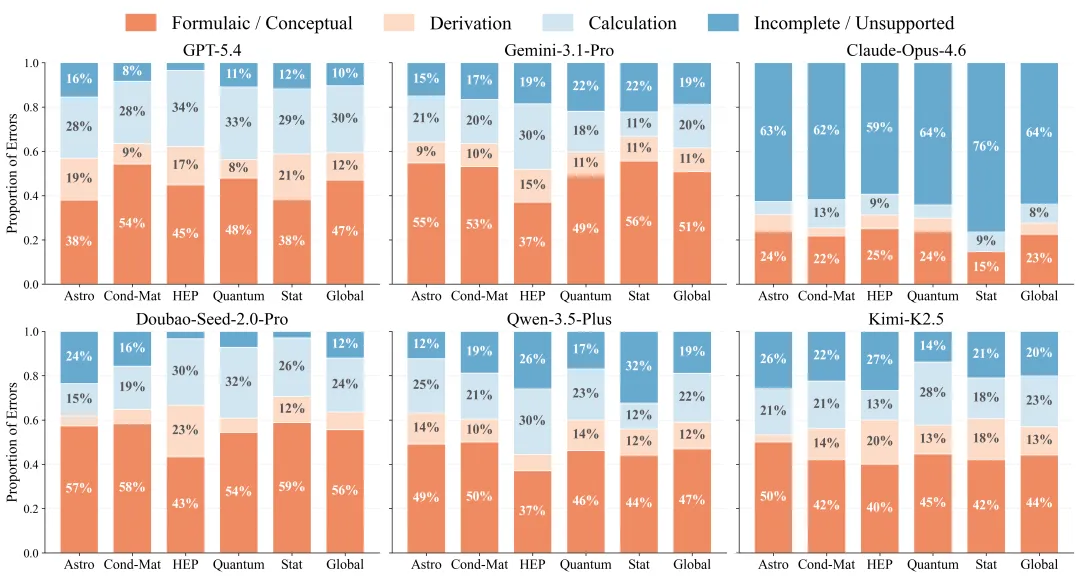
(各主流模型在PRL-Bench上的错因分布)
从统计上看,约 45%–55% 集中在理论、公式层面,模型往往选错理论框架,或者套用“看起来像”的公式——本质上还是在做模式匹配,而不是理解物理。这类问题一旦发生,后面的推导再正确也无济于事 。
反而,大家直觉中最难的“计算”,占比相对稳定(约 20%–30%),并不是主要瓶颈。
另外,测试还揭示出更深一层的问题,即推理的稳定性。面对多步推导,模型很容易在中间引入不可靠的假设,或者反复“修正自己”,最终导致整条推理链条断裂。这种现象,本质上是长程推理缺乏全局控制 。
综合来看,当前模型更像是👉 会解题,但不会做研究
它可以相对良好地完成既定路径下的研究任务,但一旦需要自己选方法、走完整个长程的研究流程,就容易偏航甚至失控。
在更开放、问题更多元、模板更少的领域(如天体物理、统计物理),模型表现明显更差——问题越接近真实科研,短板就越明显。
💡 结论:AI科学家,还在路上
比起单纯的模型排名,PRL-Bench 的核心发现是:
在科研场景下,主流大模型的普遍存在微小但致命的缺陷,导致无法胜任科研任务。
实验结果显示,即便是最强模型,在长链路任务中仍频繁失效:要么在关键物理建模上出现偏差(模型缺乏领域知识),要么在多步推导中逐渐失去一致性(模型长程推理能力不足),最终无法维持一个完整、可靠的科研链条。
PRL-Bench 的价值,不只是“更难”,而是它改变了评估的对象:
从考察模型“能不能解题”,转向考察“能不能做研究”。
这意味着评估标准正在发生转移——不再只是看单点正确率,而是看模型是否具备持续推进问题的能力:能否在不明确路径下选择方法、在长程推理中保持稳定,并最终完成一个自洽的研究闭环。
这正是 agentic science 所真正关心的能力边界。