 夜雨聆风
夜雨聆风





智能体前置处理:多模态文档内容提取的工程基线
多模态解析的工程占位与代价
处理业务文件时,系统架构面临两种路径。一是采用多模态大模型直接识别,二是使用专用解析组件进行前置结构化翻译。两者不存在绝对优劣。工程决策的本质是平衡处理精度与综合成本。
针对Word、Excel及原生PDF等强结构化文本,专用解析器可直接提取底层数据标签。若将结构化文本强制转为图像格式再交由大模型处理,属于非必要的路径绕行。
此类跨模态转换不仅缺乏信息增益,还易导致原始的树状逻辑与二维嵌套关系丢失。
面对照片、扫描件及音视频等非结构化多媒体,多模态大模型展现出结构性优势。相比传统光学字符识别(OCR),多模态大模型具备更高的识别精度与上下文容错率。
这是多模态大模型作为原生视觉与听觉引擎的物理特性。
采用大模型解析的代价,体现为客观的推理延迟与接口调用开销。当业务场景对精度的容忍度与传统OCR能力匹配时,使用基础算法提取是提升响应速度的合理选择。
系统设计应在满足需求基线的前提下,优先引入模态解析的算力手段。
模态解析前置处理的真实定位,是智能体架构的算力分流阀。模态解析利用确定性程序过滤标准排版与结构化数据。
多模态解析要点和难点
二维坐标的线性扫描冲突PDF格式的底层代码不存储“段落”或“逻辑关联”。它采用二维绝对坐标(X与Y轴)独立记录每个字符或文本块。 人类阅读双栏排版时,习惯自左栏顶部读至底部,再平移至右栏。但传统解析程序仅依据Y坐标高度执行水平扫描。
底层数据结构与人类阅读习惯的脱节,直接引发了提取链路的物理失效。
当传统工具依靠坐标线性扫描双栏排版、环绕图文或合并单元格时,会机械地横向穿透栏目分界线。
解析组件会将同一高度的左右栏无关文本生硬拼接,直接切断文档真实的阅读顺位与原始语境。
假设左栏第一行写着:“苹果公司在今年发布了新款手机。”右栏第一行写着:“该行业的整体利润率下降了十个点。”
人类知道这两句话毫无关系。但常规解析器会将两行文本拼在一起。最终输出给大模型的句子是:“苹果公司在今年发布了新款手机,该行业的整体利润率下降了十个点。”
必须引入版面分析模型来重新构建人类真实的阅读顺位。
像素矩阵的结构降维扫描件与图片本质是像素矩阵,即纯粹的颜色色块拼凑而成。其底层不存在计算机可直接读取的内嵌文本或字符编码。 在控制算力成本、不引入多模态大模型的前提下,传统光学字符识别(OCR)提取的产物往往是依附于绝对坐标的散乱文本流。
此类离散文本流缺少原文档的段落归属、标题层级以及二维网格等逻辑关系。
基础OCR算法受限于复杂表格、印章遮挡与页面畸变,常发生物理维度的结构降维。
系统处理视觉规整的表格时,纯粹的像素提取会剥离行列边界。这迫使二维表格结构退化为一维的离散词组序列。
跨模态的隐性结构与特殊编码除以上基础提取难点之外,跨模态的隐性排版元素构成第三道提取壁垒。 对于无边框表格,由于缺失物理线条或视觉锚点,常规解析组件仅靠坐标间距推断,常发生列边界划分错误。 当长表格跨页截断时,若不具备上下文缝合机制,原有的行列映射关系会在物理翻页处丢失。 此外,包含复杂空间关系的数学公式(如上下标与根式),在常规字符提取中会发生形态突变,转化为无意义的散乱字符。 上述结构性噪音会干扰下游语言模型的逻辑推理。
物理边界异常与接入层防线在突破内容提取的结构壁垒前,系统接入层的物理与数据结构异常构成更为前置的工程挑战。解压炸弹(极端压缩比文件)可在极小体积下膨胀出千兆字节载荷,引发节点内存溢出。基于扩展名的格式伪装会直接阻断底层解析逻辑。
超高分辨率的多媒体附件,若未经尺寸约束直接送入视觉模型,将超出硬件显存上限导致服务中断。
此外,由大量空白页或无规律乱码构成的噪音文件,以及将文本全局渲染为单一图片的光栅化伪装件,均会引发算力资源的无效损耗。
拦截此类边界异常无需调用重型AI模型。
系统依靠文件头特征校验、解压容量熔断、图像等比例预压缩及文本提取密度探针等轻量级逻辑,即可在接入层实现确定性的物理拦截与降级分流。
面对上述物理断层与安全边界,后续架构设计的焦点是引入适宜的结构化组件。系统需在算力成本可控且匹配业务精度的前提下,缝合这些模态边界。
核心解析引擎能力锚点
鉴于前文论述的二维空间错位与结构降维风险,版面分析与表格结构还原已成为核心解析管线的强制前置能力。
仅具备线性坐标扫描或纯粹光学字符提取的基础组件,因无法重构人类视觉的阅读顺位,在应对复杂业务文档时可被降级或剔除出核心主干。
以早期基础解析库PDFMiner与pdf2text为例。上述组件运行开销较小,但底层逻辑高度依赖一维坐标顺序。处理双栏排版时,上述组件极易发生文本物理错位。
开源表格解析组件Camelot与Tabula虽能依靠几何线条重构基础表单。但在面对无边框扫描件或跨页合并单元格时,常因缺失视觉锚点导致结构提取失效。
此外,传统Tesseract OCR引擎在处理复杂中文商业版面时,其字符识别率与嵌套结构还原能力亦暴露出明显的工程局限。
面对双栏排版、无边框表格及公式混合的复杂PDF与图片格式,系统需引入具备深度视觉理解的智能版面分析引擎。
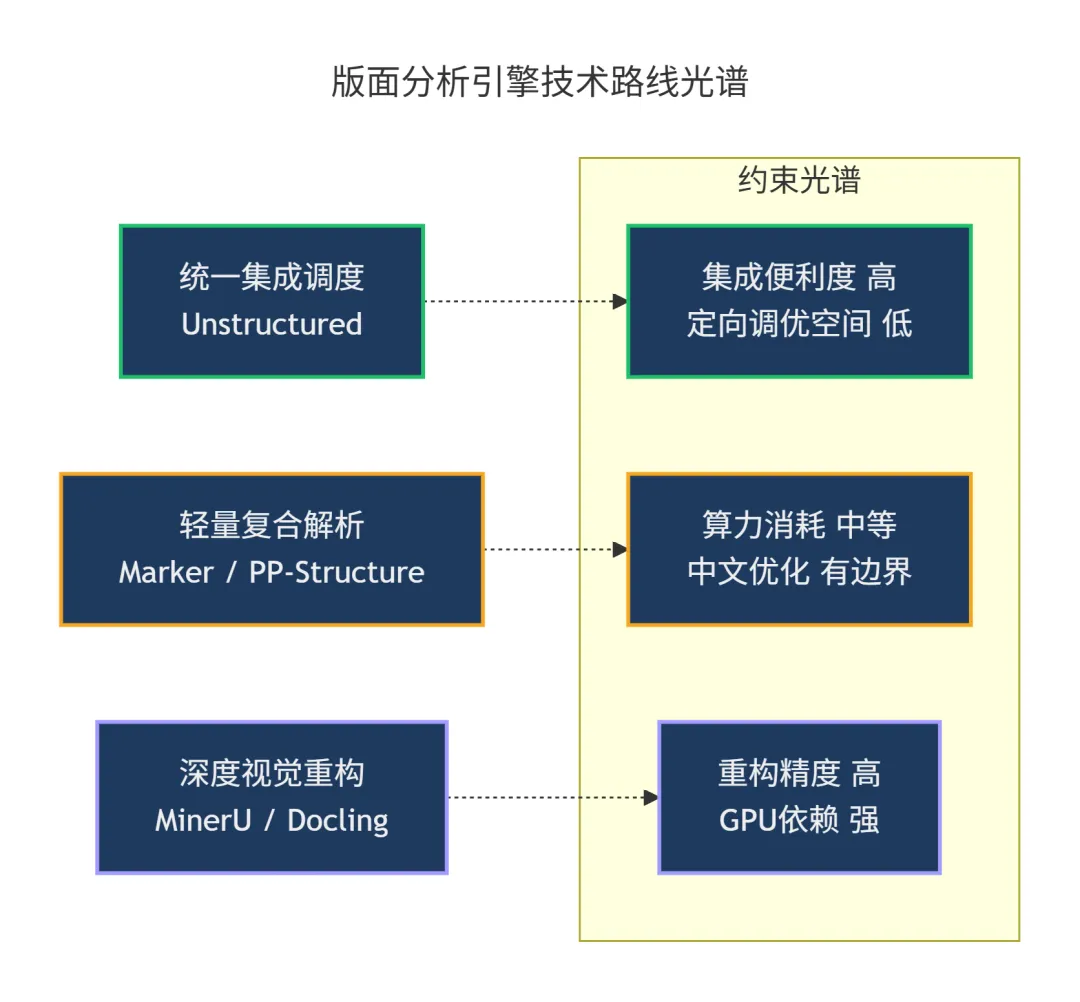
当前业界的版面分析引擎在技术路径上主要分化为三种形态:统一集成调度、轻量复合解析与深度视觉重构。架构选型需依据语料特征与算力预算进行结构性权衡。
统一集成调度类框架以 Unstructured 为代表。其提供跨越数十种文档格式的标准化路由接口,有效降低了异构数据的接入复杂度。这种高集成度以底层机制的相对封闭为代价。在应对高度非标的中文复杂合并表格时,定向干预与结构调优的工程空间受限。
系统常面临提取结果发生结构降维的风险。
轻量复合解析类框架在算力消耗与识别精度间寻找折中。开源组件Marker结合了启发式规则与视觉模型,在常规英文文献解析上表现稳定。但Marker对原生中文复杂排版的还原度受限于预训练语料的边界。
与之对应,国内开源的PP-Structure针对中文商业版式进行了定向优化,具备较好的纯CPU部署条件。但在处理包含密集自定义数学公式或跨页长表格的学术长文时,PP-Structure的模块化拼接逻辑存在结构重组的误差积累。
深度视觉重构类框架以MinerU与Docling为基线,定位于高保真的模态翻译。此类引擎引入专门的视觉检测模型,对图表、标题、公式执行物理层面的拆解与逆向编译。
引擎最终统一输出包含二维拓扑特征的Markdown结构。此策略有效降低了下游语言模型的逻辑推理负荷。
该技术路线的核心代价体现为显著的硬件资源依赖。深度视觉重构引擎的高吞吐量运转必须依托图形处理器(GPU)的算力支撑。
若在纯CPU环境下强制部署,单页解析周期的客观延宕将严重制约高并发业务的流转效率。
核心解析引擎能力选型
核心解析引擎的选型不存在普适全行业的标准架构。技术决策本质上是业务约束条件与模型物理边界的相互映射。
企业需在现有硬件底座、研发运维预算、高频文档特征以及解析容错率之间确立理性的平衡点。
以中小微企业本地化闭环部署为例,其核心约束通常表现为缺乏大规模图形处理器(GPU)集群,且专属算法运维人力受限。
在此边界条件下,系统设计需放弃追求极限的结构还原率,转向成本收敛与工程健壮性。
选型推演首先取决于历史语料的物理分布与结构化深度需求。若企业日常流转的文件以基础Office文档与单栏原生PDF为主,且仅需提取线性文本,直接引入PyMuPDF等轻量级规则库即可形成闭环。
此类方案算力损耗极小,能维持高并发场景下的极速响应。
若业务强制要求还原非标扫描件的二维表格或跨栏阅读顺位,系统必须挂载版面分析引擎。在缺乏GPU硬件的物理限制下,强行部署MinerU等重型视觉模型会引发单页响应周期的显著延宕。
此时的工程折中方案是采用基于CPU推理优化的轻量级组件(如PaddleOCR的版面分析模块)。系统也可将复杂文档引流至空闲时段进行离线异步批处理。
针对运维人力紧缺的组织现状,引入Unstructured等多格式统一封装库可大幅收敛跨组件对接的工程复杂度。该策略通过标准化的对外接口降低了初期研发成本。
多格式统一封装库的核心代价在于底层调度机制的黑盒化。在遭遇中文字符乱码或复杂单元格错位时,定向干预的规则调优空间受到物理挤压。
表格1:主流解析组件约束条件与能力对照
|
|
|
|
|
|---|---|---|---|
| 轻量规则库 |
|
|
|
| 矢量表单库 |
|
|
|
| 统一封装库 |
|
|
|
| 深度版面引擎 |
|
|
|
最终的架构选型并非寻找单一的完美引擎,而是构建一套动态分流与降级机制。
将绝大多数标准格式交由低能耗规则库处理,将少量高门槛视觉解析任务锁定在可控的独立算力池内,是兼顾提取精度与商业预算的务实路径。