 夜雨聆风
夜雨聆风





AI Agent 架构设计指南:从上下文约束到生产级实践
先抛结论:没有任何一种 Agent 架构能解决所有问题。与其问”用什么框架”,不如先问”我的任务需要哪层约束”。理解这一点,比记住四种模式的名字重要一百倍。
一、上下文:大多数人都踩过的那个坑
先说一个真实场景,不知道你有没有遇到过:
你给 Agent 接了 8 个工具,塞了 10 万 Token 的业务文档,聊了 50 轮之后,它突然”失忆”——明明前面刚提过的需求,后面又重新问了一遍。你第一反应是:模型出 Bug 了。
不是。这是上下文窗口达到上限后,旧的 Token 被悄悄丢弃了。
上下文窗口(Context Window)是 LLM 的记忆容量上限。当前主流模型的上下文窗口从 128K 到 200K Token 不等。听起来挺大?换算成实际用量看看:100 条对话历史约 30K Token,一份业务文档 20K,工具调用输出累积 20K,加起来轻轻松松超过 100K。上下文满了,旧的就被截掉,模型”看不见”后面的内容——不是记不住,是根本没机会记。
这不是哪家的 Bug,是所有大模型的硬限制。理解了这一点,很多 Agent 的”奇怪行为”就有了根本解释。
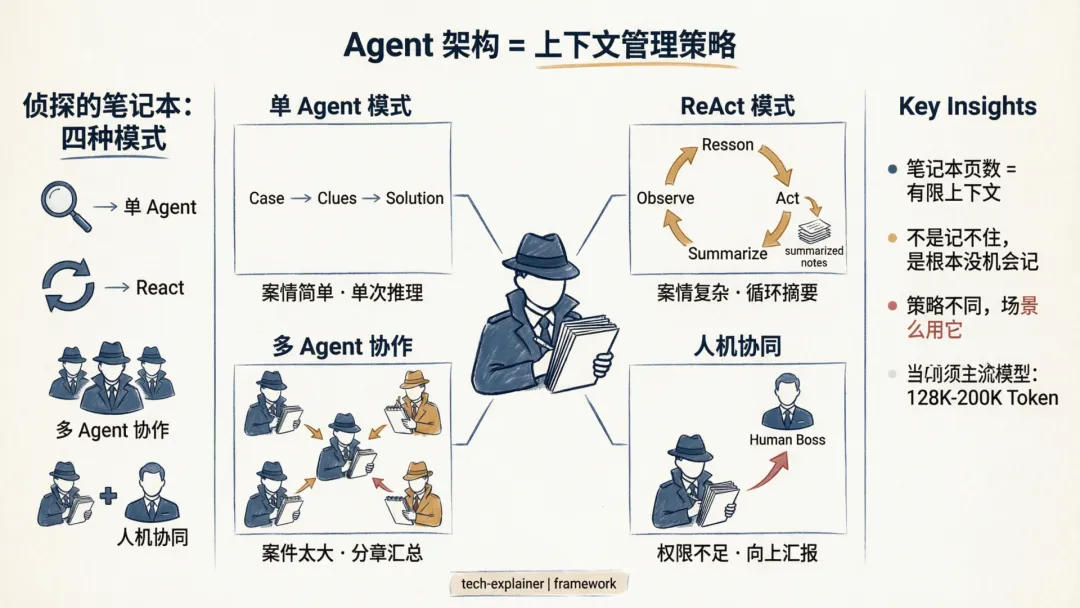
一本侦探的笔记本
用一个比喻把上下文限制讲透。
把 Agent 想象成一个侦探。他的大脑没问题,但有一本固定页数的笔记本——这就是上下文窗口。
场景一:案情简单。侦探翻两页,记下”受害人和时间地点”,写完笔记本,答案出来了。这是单 Agent 模式——逻辑清晰,单次推理搞定。
场景二:案情复杂。涉及多个证人,需要交叉验证,侦探没法一次全记住。他会在笔记本上写一页,核实一页,然后用摘要替换原始记录,腾出空间记下一页。这是ReAct 模式——不是记住所有细节,而是每个循环只记住关键结论。
场景三:案件太大。涉及几百个证人、几十个现场,一本笔记本根本装不下。怎么办?派多个侦探,每人负责一本笔记本的某个章节,最后汇总给主侦探。这是多 Agent 协作模式——不是让一个 Agent 扛所有压力,而是把大任务拆成多个可管理的小任务。
场景四:有些判断超出了任何侦探的权限。比如”这个嫌疑人是否值得信任”、”这个决策是否符合公司价值观”。这时候侦探必须停下来,向人类上司汇报。这是人机协同模式——AI 无法自主处理的判断,交给人来做最终决定。
四种模式,对应四种不同的上下文管理策略。它们的共同前提都一样:笔记本的页数是有限的,必须认真规划怎么用它。
塞更多上下文,AI 反而更差
很多人发现 Agent 效果不好,第一反应是:给它更多背景信息。这个直觉往往是错的。
举个例子:你想让 Agent 审查一份 2000 行代码,找出安全漏洞。你把整份代码、10 份相关文档、三部技术规范全部塞进上下文,期待”全面分析”。
结果:Agent 对前 500 行给了很多泛泛评价,中间 1000 行几乎没提,最后 500 行又开始认真分析。最终报告质量参差不齐,你很失望。
问题不在 AI 不认真。问题在于:当 200K Token 的信息压进一个任务时,选项太多,AI 分析不过来。可能性太多,每种都要考虑,最终哪种都没分析透。
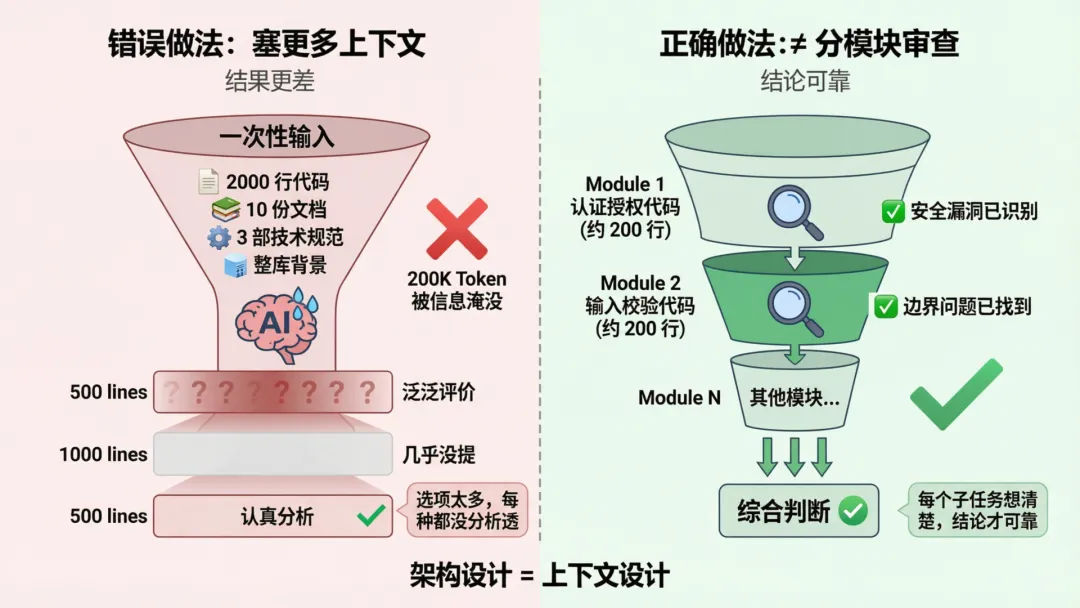
正确的做法:先让它只审查”认证授权相关代码”(约 200 行),再让它审查”输入校验相关代码”(又是 200 行),最后综合判断。每个子任务都能想清楚,结论才可靠。
架构设计 = 上下文设计
这就是架构设计的核心意义——不是选哪个框架,是设计上下文的管理方式。
好的 Agent 架构,会主动做三件事:
-
• 约束边界:把大任务拆成小任务,每个子任务的边界都清晰可控 -
• 分层管理:把高频决策放在浅层(单 Agent),把低频但高价值的决策放在深层(多 Agent + 人机协同) -
• 主动回收:上下文快满时,对历史信息做总结压缩,而不是等着被强制截断
记住这句话:架构的本质,是把问题的边界控制好——让 AI 每次面对的,都是它能给出可靠答案的题目。
二、四种设计模式:四种约束策略,没有高下之分
上一节的核心结论是:架构的本质,是把问题的边界控制好,让 AI 每次只处理它能给出可靠答案的题目。
但”把问题边界控制好”这件事,不同业务场景的实现方式完全不同——
-
• 有的靠缩小范围——把问题控制在单次推理能搞定的边界内 -
• 有的靠分步拆解——把大题目拆成多个小题目,每步逐一搞定 -
• 有的靠专业分工——多个 Agent 各管一摊,合起来覆盖整个问题 -
• 有的靠人工兜底——把 AI 顾不过来的那部分,交给人来做
四种设计模式,本质上是四种不同的约束策略。它们不是四个平行的技术选项,而是解决”如何把问题边界控制好”这个问题的四套方案。没有高下之分,只有合不合适。
2.1 单 Agent 模式
什么时候用它:任务逻辑相对清晰,一步或几步内能给出答案。
架构长这样:
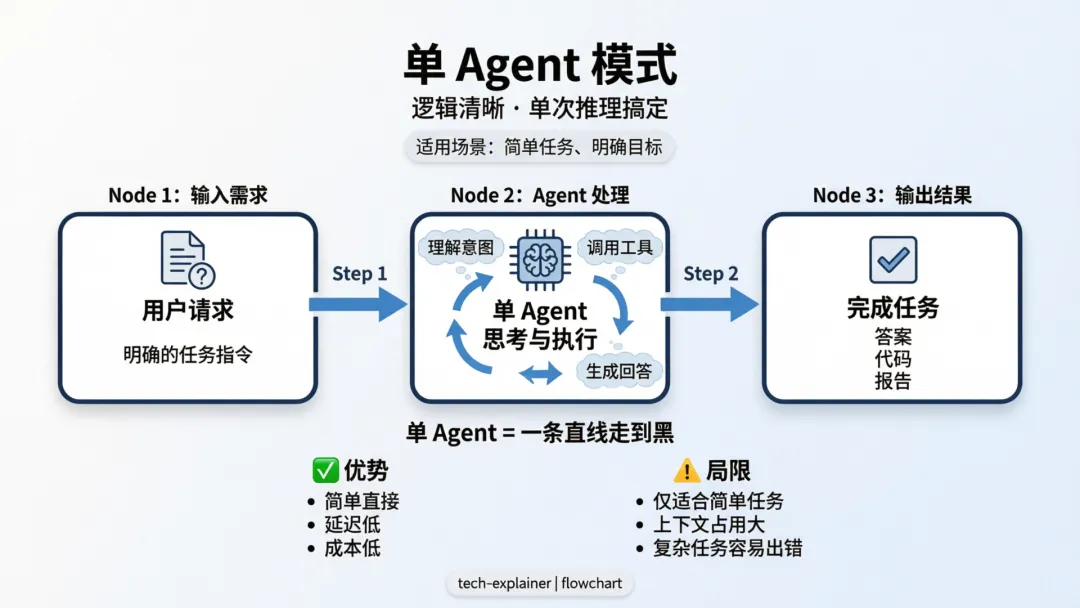
架构长这样:
用户输入 → Agent(模型 + 工具 + 提示词)→ 输出结果它适合做什么:
-
• 客服问答:回答常见问题、查订单状态、指引操作步骤 -
• 数据查询:接入数据库或 API,按问题返回具体数据 -
• 文档处理:总结报告、提取关键信息、按模板格式化输出 -
• 内部搜索:整合多个数据源,一次返回综合答案
核心组件只有四个:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
伪代码示例:
class SimpleAgent:def __init__(self, model, tools, system_prompt):self.model = modelself.tools = toolsself.memory = [system_prompt]def run(self, user_input):self.memory.append(f"用户: {user_input}")# 模型决定用哪个工具decision = self.model.reason(self.memory)if decision.tool_call:result = self.tools[decision.tool_name].execute(decision.params)self.memory.append(f"结果: {result}")final_response = self.model.reason(self.memory)else:final_response = decision.text_responsereturn final_response
结论:从单 Agent 开始。大多数场景下它都够用。不要因为觉得”不够高级”就盲目上多 Agent——多加一个 Agent,就多一层协调成本。
2.2 ReAct 模式
什么时候用它:答案不能一步给出来,需要多步验证,中间结果决定下一步方向。
典型场景:故障排查、法律条款分析、竞品调研、投资决策分析。
架构的核心是一个循环:
用户输入 ↓初始推理:理解问题,明确缺什么信息 ↓循环开始 → Thought(想):基于当前信息,决定下一步做什么 → Action(做):执行操作,通常是调用某个工具 → Observation(看):分析结果,更新理解 → 判断:信息够了吗? ├─ 不够 → 继续循环 └─ 够了 → 退出循环 ↓综合所有信息,输出答案它适合做什么:
-
• 故障排查:逐步收集日志、验证假设、定位根因,每一步依赖上一步的结果 -
• 法律/合规分析:从多个法规文件中交叉验证,结论不能靠一次检索 -
• 竞品调研:访问多个信息源,相互印证,去除过时和矛盾的内容 -
• 投资决策:收集财务、舆情、行业多个维度的数据,逐步推理得出结论
关键实现要点:
伪代码示例:
class ReActAgent:def __init__(self, model, tools, max_iterations=15):self.model = modelself.tools = toolsself.max_iterations = max_iterationsdef run(self, user_input):context = [user_input]for i in range(self.max_iterations):thought = self.model.think(context) # Thoughtif thought.is_final: # 判断是否足够return thought.final_answerif thought.tool_name: # Actionresult = self.tools[thought.tool_name].call(thought.params)context.append(f"观察: {result}") # Observationelse:return thought.text_responsereturn self.model.reason(context) # 达到上限,返回保守结果
结论:ReAct 是单 Agent 的进阶,不是替代。简单问答用 ReAct 是杀鸡用牛刀。当任务需要探索式推理时,它才是正确的选择。
2.3 多 Agent 协作模式
什么时候用它:任务涉及多个专业领域,或者信息量太大,一个 Agent 的上下文根本装不下。
典型场景:内容生产流水线、多维度数据分析、客户服务全流程、代码开发助手。
关键信号:当你发现单个 Agent 的提示词越写越长、工具越加越多、错误率开始上升——这才是该上多 Agent 的信号,而不是项目一开始。
四种协作架构:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
它适合做什么:
-
• 内容生产流水线:研究 Agent 收集资料 → 写作 Agent 撰写初稿 → 编辑 Agent 优化 → 审核 Agent 把关 -
• 多维度数据分析:财务、运营、CRM 三个系统同时取数,并行处理后再综合 -
• 客户服务全流程:分类 Agent → 查询 Agent → 方案 Agent → 回复 Agent,每个环节专业分工 -
• 代码开发助手:需求分析、架构设计、代码生成、测试验证,不同阶段由不同专家 Agent 负责
伪代码示例:
class CoordinatorAgent:def __init__(self, agents, strategy="hierarchical"):self.agents = agents # {"research": ..., "writer": ..., "editor": ...}self.strategy = strategydef run(self, task):subtasks = self.decompose(task) # 任务分解if self.strategy == "sequential":result = Nonefor name, sub in subtasks:result = self.agents[name].run(sub, prior_result=result)return resultelif self.strategy == "parallel":from concurrent.futures import ThreadPoolExecutorwith ThreadPoolExecutor() as executor:futures = {name: executor.submit(self.agents[name].run, sub)for name, sub in subtasks}results = {name: f.result() for name, f in futures.items()}return self.aggregate(results)
结论:多 Agent 是复杂系统的解法,不是复杂需求的解药。如果单 Agent 能搞定,就不要多 Agent。引入多 Agent 的代价是协调成本、管理成本、调试成本的全面上升。
2.4 人机协同模式
什么时候用它:涉及高风险决策、主观判断,或者法律法规要求必须有人参与。
典型场景:法务合同审核、医疗报告辅助、营销方案评审、风控决策。
核心认识:这不是”AI 不行所以人来兜底”,而是理性地利用各自的优势。AI 擅长处理大量信息、找出异常模式;人擅长判断价值、做主观决策。把各自的强项用起来,才是真正的设计。
两种协同机制:
-
• 审核点(Checkpoint):在关键节点强制暂停,等人工审核确认后才继续执行 -
• 升级机制(Escalation):Agent 遇到超出能力范围的情况,自动转给人工处理
它适合做什么:
-
• 法务合同审核:AI 初审条款风险,人工律师做最终把关 -
• 医疗报告辅助:AI 生成报告草稿,主治医生审核签字 -
• 营销方案评审:AI 生成三个方案,市场总监选一个并调整 -
• 风控决策:AI 给出风险评分和理由,信审人员做最终决定
结论:人机协同的关键是找到那个平衡点——既不是完全放手给 AI,也不是事事都让人审。过多的干预会失去自动化的意义,过少的干预会让高风险决策失控。
约束策略小结:四种模式分别约束了什么
回到本文的核心论点——架构的本质,是把问题的边界控制好,让 AI 每次只处理它能给出可靠答案的题目。四种模式各自是怎么实现的?
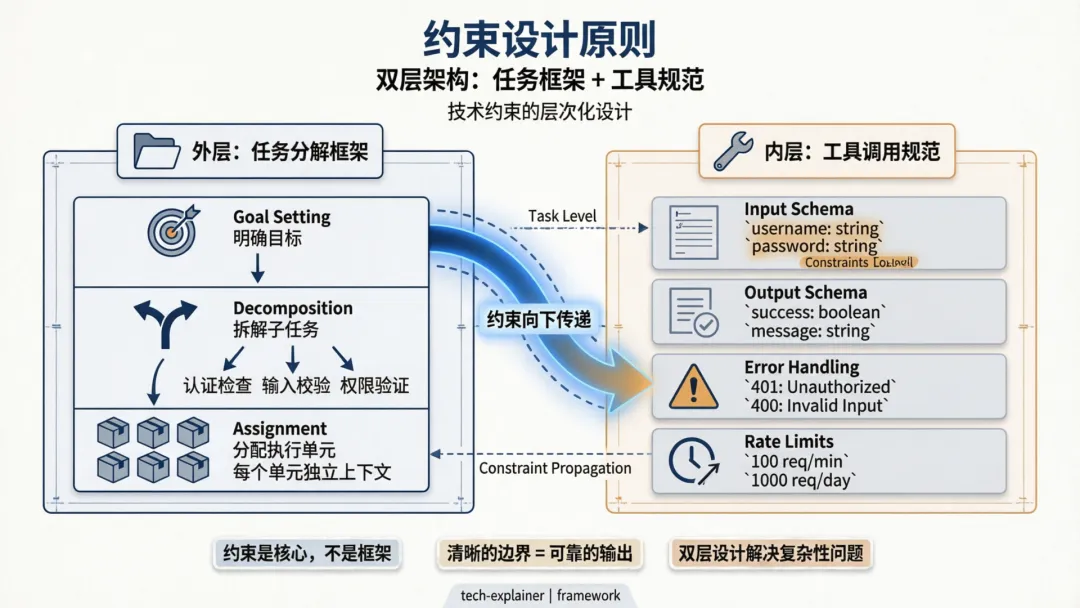
| 模式 | 约束方式 | 解决的问题 |
|
|
|
|
|---|---|---|
| 单 Agent |
|
|
| ReAct |
|
|
| 多 Agent |
|
|
| 人机协同 |
|
|
一个关键认知:这四种约束策略可以叠加,不互斥。现实中一个复杂的业务系统,往往同时用多种策略:一个多 Agent 系统里,每个 Agent 内部用 ReAct 做分步推理,关键节点引入人工审核。判断的标准只有一个:当前这层约束够不够?不够就再加一层。
场景 × 模式对照表
|
|
|
|
|---|---|---|
|
|
单 Agent |
|
|
|
ReAct |
|
|
|
多 Agent |
|
|
|
人机协同 |
|
|
|
多 Agent + ReAct |
|
一个常见误区:把”业务复杂”等同于”需要多 Agent”。
举两个反例:
-
• 客服场景涉及上百个意图类别,但每个意图的处理逻辑都很简单——单 Agent + 好的意图识别就够。 -
• 竞品调研场景看似简单,就是”搜几个网站然后汇总”——但因为需要多步交叉验证,反而需要 ReAct。
判断标准不是”业务复不复杂”,而是:你能把问题的边界控制住吗?
三、如何选择:任务复杂度决定架构复杂度
四种模式讲完了,核心原则也清楚了。现在的问题是:面对具体需求,怎么选?
核心判断原则只有一条:任务复杂度的上限,决定了你需要的最少架构复杂度。 能用简单模式的,不要因为”不够高级”就升级——每上升一个台阶,协调成本、调试成本都会指数级上升。
演进路径:从简单到复杂
第一阶段:单 Agent→ 任务逻辑清晰,领域单一,先跑通核心流程第二阶段:ReAct→ 任务需要多步推理,中间结果影响下一步第三阶段:多 Agent→ 任务跨越多个领域,单个 Agent 的上下文已经扛不住始终考虑:人机协同→ 涉及高风险决策、主观判断,或法规要求人工参与决策矩阵
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一个实战规律
当你发现单个 Agent 的提示词越写越长、工具越加越多、错误率开始上升——这就是该演进到更复杂模式的信号,而不是继续在当前模式里打补丁。
这个信号出现时,不要继续优化当前模式的提示词和工具定义——那是修修补补,不是架构演进。升级到对应的更复杂模式,才是从根本上解决问题。
四、企业级实践:让约束策略工程化
理论模式落地生产,会遇到几类新问题:工具怎么标准化、上下文怎么长期管理、多个服务怎么协同。这些问题的本质是:如何让”把问题边界控制好”这套原则在工程上可持续运行。
如果你的场景还不需要这些工程化要素,可以跳过本节。
4.1 MCP 网关:工具调用的标准化
MCP(Model Context Protocol)是一个开放协议,让大模型以标准化方式连接外部数据源和工具。每个 Agent 不用再各自定义工具 API,而是通过 MCP 网关统一管理。
一个典型企业级 Agent 架构:
用户请求 → 应用网关(鉴权、限流) → AI Agent → MCP网关 → 业务微服务/数据源 ↓ LLM网关 → 大模型-
• 应用网关:接收请求,做鉴权和路由 -
• MCP 网关:维护可用工具列表,供 Agent 动态查询 -
• LLM 网关:统一管理模型调用,处理成本控制和模型切换
4.2 上下文管理:四种策略
生产级系统中,记忆管理直接影响 Agent 的长期有效性。四种常见策略:
-
• 滑动记忆:保留最近 k 轮对话,移除外围轮次。实现简单,但可能丢掉长期重要信息。 -
• 令牌记忆:保留最后 n 个 Token,超出直接截断。比滑动窗口精细,但可能切断语义完整段落。 -
• 总结记忆:用 LLM 对每轮对话做总结,用总结替换原始记录。信息密度高,但依赖总结质量。 -
• 长期记忆:把关键信息存入向量数据库,跨会话保留。需要额外的存储和检索成本。
4.3 微服务配合
在微服务架构下,MCP Server 需要注册到注册中心(如 Nacos),让 Agent 能动态发现新增或下线的工具,而不需要重启系统。
五、五个常见错误:踩过的坑别再踩
这五个错误的共同特征是:听起来符合直觉,实际上都在破坏”把问题边界控制好”这个核心原则。
错误一:一上来就做多 Agent多 Agent 是复杂系统的解法,不是复杂需求的解药。在你没有验证单 Agent 能处理核心场景之前,不要引入多 Agent 的协调复杂度。
错误二:工具越多越好给 Agent 20 个工具,不如精选 5-8 个。工具太多会增加选择难度,AI 需要在更多选项中做决策,上下文消耗增加,出错概率上升。
错误三:塞更多上下文 AI 就能搞定上下文窗口是有限的,不是”给够就能搞定”。把一堆不相干的信息全部塞进去,问题的边界反而更模糊,AI 的结论更不可靠。架构的本质是约束,不是堆料。
错误四:提示词一次写好不迭代没有一次就完美的提示词。在真实使用中观察 Agent 的失败模式,然后针对性调整——这是工程实践,不是写论文。
错误五:忽略失败处理工具调用会失败,模型推理会出错,外部服务会超时。你必须在架构层面处理这些异常,而不是假设一切顺利。重试、降级、保守兜底,都是必需的。
六、框架选型参考
理解了底层逻辑,框架只是实现工具。选框架之前,先问自己三个问题:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
框架是工具,底层逻辑才是答案。 理解为什么需要状态管理、为什么需要工具定义、为什么上下文管理是核心挑战——带着这些理解去学框架,才能真正用好它。
结语:合适的才是最好的
回到本文的核心论点:
没有任何一种 Agent 架构能解决所有问题。
单 Agent 简单直接,是入门和简单任务的首选。ReAct 增加了推理能力,适合需要探索的场景。多 Agent 通过专业分工提高能力,适合复杂的领域任务。人机协同是对当前 AI 能力边界的诚实承认,是高风险场景的必要补充。
但读完本文,你带走的应该不只是四种模式的区别。你应该带走一个判断框架:
当我面对一个新场景时,我首先想的不是”用什么架构”,而是”这个任务的问题边界有多大,我该怎么拆解,才能让 AI 每次只处理它能给出可靠答案的那部分”。
上下文管理的策略,决定了架构的选择。架构的选择,决定了系统的上限。合适的,就是最好的。