 夜雨聆风
夜雨聆风





AI笔记五:RAG(检索增强生成)
本篇代码使用python语言,实现的最简单的RAG。
共3910字,欢迎评论区和私信交流。
一、认识RAG
1. 为什么长上下文窗口(如 1M Token)不能取代 RAG?
很多人觉得:“既然模型能看 100 万字,直接把资料全塞进去不就行了?” 答案是不行。
- 成本与延迟:塞入 100 万字,每次问答成本高昂,且首字响应极慢。
- 注意力分散:大量研究表明,长文本中间的信息被模型遗忘或忽略的概率极高。
- 权限与可控性:RAG 可以结合数据库权限,实现“张三只能查 A 文档,李四只能查 B 文档”。
2. RAG标准定义(2026)
- RAG 不是“查资料”,而是“可控的知识路由 + 增强推理系统”。
核心公式:
RAG = 领域知识访问 + 上下文工程 + LLM 推理
二、构建本地 RAG
极简三层架构(教学/入门版)
- 数据层(Data)
数据源 + 预处理 + 分块 + Embedding + 向量库 - 检索层(Retrieval)
查询向量 → 检索 → 重排 → 上下文 - 生成层(Generation)
Prompt + LLM + 后处理
目标:不依赖任何云服务,不用装复杂的数据库,用纯 Python 实现最基础的 RAG。
1. pdf文档解析
pdf本地解析是 PyMuPDF (fitz)。
# pip install PyMuPDFimport fitzdef load_pdf_local(file_path): """高质量的本地 PDF 文本提取""" doc = fitz.open(file_path) text = "" for page in doc: # 提取带有格式的文本,比 pdfminer 准确率高很多 text += page.get_text("text") + "\n" return texttext = load_pdf_local("your_document.pdf")2. 文本切分
传统按固定字数切分会把一句话腰斩。现在标准做法是递归字符切分(优先按段落、换行、句号切,不够再按字数切)。
# pip install langchain-text-splittersfrom langchain_text_splitters import RecursiveCharacterTextSplittersplitter = RecursiveCharacterTextSplitter( chunk_size=500, # 每块最大长度 chunk_overlap=100, # 块之间保留 100 字重叠(防止上下文断裂) separators=["\n\n", "\n", "。", "!", "?", " ", ""])chunks = splitter.split_text(text)3. 本地向量化
在本地加载开源模型 BGE-M3。
# pip install sentence-transformersfrom sentence_transformers import SentenceTransformer# 首次运行会自动下载模型(约 2GB),后续走本地缓存embedder = SentenceTransformer('BAAI/bge-m3')# 将文本块转为向量chunk_vectors = embedder.encode(chunks, normalize_embeddings=True)4. 向量检索:使用 FAISS
不需要装数据库,几行代码搞定内存级极速检索。
# pip install faiss-cpuimport faissimport numpy as np# 1. 构建索引 (d=1024 是 bge-m3 的维度)dimension = chunk_vectors.shape[1]index = faiss.IndexFlatIP(dimension) # 内积检索(因为向量已归一化,等价于余弦相似度)index.add(np.array(chunk_vectors).astype('float32'))# 2. 检索函数def search_faiss(query, top_k=3): query_vec = embedder.encode([query], normalize_embeddings=True) distances, indices = index.search(np.array(query_vec).astype('float32'), top_k) # 返回最相关的文本块 return [chunks[i] for i in indices[0]]# 测试检索results = search_faiss("Llama 2 有多少参数?")5. 组装 RAG Pipeline
from openai import OpenAI# 这里以兼容 OpenAI 格式的智谱 API 或本地 Ollama 为例client = OpenAI(api_key="your_key", base_url="your_base_url")def ask_rag(question): # 1. 检索 context = search_faiss(question, top_k=3) context_str = "\n---\n".join(context) # 2. 构建 Prompt (Context Engineering) prompt = f"""你是一个严谨的问答助手。请仅根据以下【已知信息】回答问题。 如果信息不足,请直接说“我不知道”。 【已知信息】 {context_str} 【用户问题】 {question}""" # 3. 调用大模型 (使用最新的标准 API) response = client.chat.completions.create( model="glm-4-flash", # 或 gpt-4o-mini 等快速模型 messages=[{"role": "user", "content": prompt}], temperature=0 ) return response.choices[0].message.contentprint(ask_rag("Llama 2 有多少参数?"))✅ 至此,你已经拥有了一个完全本地化、最简单、最基础的 RAG 系统!
三、攻克工程痛点 ——> 优化检索
基础 RAG 在实际应用中会立刻暴露两个致命弱点。
痛点 1:字面匹配的盲区 ——> 混合检索
向量检索喜欢“语义相近”的词,但在医疗、法律等垂直领域,专有名词差一个字,意思天差地别。
解决方案:Hybrid Search(混合检索)+ RRF 融合 不要手写复杂的 Elasticsearch 环境,我们在本地用 rank_bm25 库几行代码搞定关键词检索:
# pip install rank_bm25 jiebafrom rank_bm25 import BM25Okapiimport jieba# 1. 构建本地 BM25 索引(对中文进行分词)tokenized_chunks = [list(jieba.cut(chunk)) for chunk in chunks]bm25 = BM25Okapi(tokenized_chunks)def search_bm25(query, top_k=3): tokenized_query = list(jieba.cut(query)) scores = bm25.get_scores(tokenized_query) top_indices = np.argsort(scores)[::-1][:top_k] return [chunks[i] for i in top_indices]RRF(倒数秩融合)算法: 不要粗暴地把两个分数相加,而是把它们的排名名次进行融合。公式极其优雅且有效:
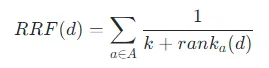
(k通常取60,rank是文档在某个检索列表中的位置,1表示第一名)
痛点 2: 最佳答案排在后面 ——> 重排序
大模型的上下文窗口有限,你不敢把 Top 50 都塞进去。
解决方案:Rerank(交叉编码器重排序) 先粗筛 Top 20,再用一个专门的小模型精准打分,选出真正的 Top 3。
# 使用本地 Rerank 模型(无需联网,CPU可跑)from sentence_transformers import CrossEncoderreranker = CrossEncoder('BAAI/bge-reranker-v2-m3', max_length=512)def hybrid_rag_search(query, top_k=20, final_k=3): # 1. 多路粗召回 vec_results = search_faiss(query, top_k) bm25_results = search_bm25(query, top_k) # 简易去重合并 all_candidates = list(set(vec_results + bm25_results)) # 2. Rerank 精排 pairs = [[query, doc] for doc in all_candidates] scores = reranker.predict(pairs) # 3. 按分数降序排列,取 final_k ranked_docs = sorted(zip(scores, all_candidates), key=lambda x: x[0], reverse=True) return [doc for score, doc in ranked_docs[:final_k]]💡 工程铁律:检索质量决定了 RAG 的上限,大模型能力只决定能否摸到这个上限。Rerank 是 2026 年 RAG 的必选项,不是可选项。
四、高级 RAG 技巧
单纯的 Query -> 检索 -> 回答 属于“朴素 RAG”。真正的现代 RAG 引入了 Agent 机制。
1. Query Rewrite(查询重写)
用户的提问往往很模糊或有语病。
-
用户问:“那个新出的支持商用的模型参数多少?” - 系统后台自动改写为:
2. Multi-Query(多路查询扩展)
针对复杂的用户问题,自动生成多个子问题去检索。
-
用户问:“对比一下 Llama 2 和 GPT-4 的安全性策略” - 系统拆解为:
-
Q1: “Llama 2 的安全性策略” -
Q2: “GPT-4 的安全性策略” -
然后将两路检索结果合并喂给大模型。
3. 多模态 RAG(处理表格和图片的终极方案)
2026 年的标准做法是:直接让视觉大模型(VLM)“看”整页文档。架构思路:
-
把 PDF 每一页转成高清图片(使用 PyMuPDF)。 -
检索时,如果判断问题涉及图表,直接检索图片。 -
将图片和问题一起发给多模态大模型(如 GPT-4o、智谱 CogVLM 等)。
# 伪代码示例:VLM 直接读取 PDF 页面import base64def encode_image(image_path): with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode('utf-8')response = client.chat.completions.create( model="qwen3-vl:8b", # 多模态模型 messages=[{ "role": "user", "content": [ {"type": "text", "text": "提取这张图表中的关键数据"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{encode_image('page_5.png')}"}} ] }])4. GraphRAG(知识图谱增强)
不要迷信 GraphRAG! 传统向量 RAG 能解决 90% 的问题。
|
|
|
|
|---|---|---|
| 核心原理 |
|
|
| 绝对优势场景 |
|
|
| 构建成本 |
|
|
| 维护成本 |
|
|
建议:只有当你用尽了“混合检索 + Rerank + 查询重写”,依然无法解决跨文档的全局归纳问题时,再去引入 Neo4j 等图数据库尝试 GraphRAG。它是特种兵,不是常规军。
五、生产级开发 ——> 五层RAG架构
当前生产级 RAG 开发,主流分为 5 层标准架构: 数据源层 → 数据处理层 → 索引存储层 → 检索层 → 生成增强层。
1. 数据源层(Data Source Layer)
所有外部知识的入口,决定 RAG 知识覆盖范围与质量上限。
常见数据源类型
- 非结构化
(最常用) PDF、Word、Markdown、Txt、网页、邮件、聊天记录、手册、论文、音视频转写文本 - 半结构化
Excel/CSV、JSON、XML、HTML、Wiki、API 返回 - 结构化
关系库(MySQL/PostgreSQL)、NoSQL(MongoDB)、图数据库(Neo4j) - 多模态(2026 主流扩展)
图片 OCR、表格、扫描件、音视频(ASR 转文本)、CAD/图纸元数据
企业常用来源
-
内部:Wiki、OA、工单、合同、产品文档、研报、历史对话 -
外部:行业白皮书、法规、公开数据集、权威网站、合作伙伴文档
2. 数据处理层(Data Processing / ETL Layer)
把“脏数据”变成可检索的干净文本块。
核心模块:
- 文档解析
PDF/Word/Excel/HTML 提取文本、表格、标题、结构;去页眉页脚/广告/噪声 - 清洗
去重、去乱码、去空行、标准化格式、过滤短文本 - 分块(Chunking)
按语义/固定长度/标题层级切分(512–1024 token 主流),加重叠窗口防语义断裂 - 元数据提取
来源、日期、作者、文档类型、页码、版本、权限标签(用于过滤/溯源) - 查询预处理(在线)
查询改写、扩展、纠错、分类、意图识别
工具 LlamaParse、PyPDF2、Unstructured、LangChain、 RecursiveCharacterTextSplitter
3. 索引存储层(Index & Storage Layer)
向量+全文双索引是工业标配。
核心组件:
- Embedding 模型
(向量化) 中文:BGE-base-zh、m3e、text-embedding-ada-002 作用:把文本块转为高维向量(768/1024 维),捕捉语义 - 向量数据库(Vector DB)
Milvus、FAISS、Chroma、PGVector、Qdrant、Weaviate 存储:向量 + 原文块 + 元数据 能力:余弦相似度/欧氏距离快速检索 Top-K - 全文索引(Sparse)
BM25、Elasticsearch 作用:补全向量检索短板——精确词/型号/编号/术语强匹配 - 混合存储
Elasticsearch 向量库 + 关系库(存元数据/原文)
4. 检索层(Retrieval Layer)——> RAG 核心
从海量库中精准召回相关片段,工业界普遍是 多路召回 + 重排 架构。
标准子模块(2026)
- 查询向量化
问题 → Embedding 向量 - 多路并行召回(Recall)
-
稠密向量检索(Dense):语义相似 -
稀疏检索(Sparse/BM25):关键词精确匹配 -
元数据过滤:按日期/权限/来源/版本过滤 -
(进阶)图检索:实体关系召回(GraphRAG) - 融合(Fusion)
多路结果加权融合(RRF 排序融合) - 重排序(Rerank)
用 Cross-Encoder 模型(BGE-reranker、Cohere rerank)对候选精排 - 上下文压缩/提纯
提取与问题最相关的句子,压缩冗余
工业检索架构(大厂标准)
召回层 → 融合层 → 精排层
5. 生成增强层(Generation & Augmentation Layer)
用检索结果生成可靠、可溯源回答。 核心模块
- Prompt 构建
问题 + Top-N 相关块 + 系统提示(约束格式/禁止幻觉/引用来源) - LLM 生成
GPT、通义千问、文心一言、Llama 3、Qwen - 后处理
答案校验、引用标注(页码/来源)、格式美化、去幻觉检测 - (进阶)评估与反馈
实时打分(相关性、忠实度)、bad case 回流优化
🚨 附:RAG 调试 Checklist 指南
当 RAG 系统表现拉胯时,不要盲目换更大的大模型,先按照以下漏斗排查:
- 查数据源(占比 60% 的锅)
:打印出被切分的 chunks,肉眼看看是不是把一句话切成了两半?表格是不是乱码了? - 查检索层(占比 30% 的锅)
:打印出检索回来的 Top 3 文本,里面到底有没有答案?如果没有,说明切分或检索算法有问题;如果有,大模型却没答对,进入第 3 步。 - 查 Prompt 与模型(占比 10% 的锅)
:把问题和包含答案的文本直接丢给大模型(不用 RAG 流程),它能答对吗?如果答不对,说明是 Prompt 写得烂,或者你用的模型太弱。