 夜雨聆风
夜雨聆风





10 万文档 RAG 落地实战:从 Demo 到生产,我踩过的所有坑
在过去一年里,RAG(Retrieval-Augmented Generation)几乎成了企业落地大模型的标准配置。
原因很简单:
-
企业数据高度私有,无法直接丢给大模型训练
-
业务知识更新频繁,微调成本高、周期长
-
需要“可控、可解释、可追溯”的回答来源
但当你真的把 RAG 从 Demo 推到生产,会发现三个问题几乎一定会出现:
-
文档一多,检索明显变慢
-
明明文档里有答案,模型却“搜不到”
-
本地 + 向量库 + 模型 + 服务,部署复杂度飙升
这篇文章不会再重复“RAG 是什么”这种内容,而是围绕一个真实企业级目标展开:
在 10 万级文档规模下,如何构建一个可用、稳定、可扩展的 RAG 系统。
技术原理:先把“为什么慢、为什么不准”讲清楚
RAG 的本质不是“问答”,而是信息检索系统
很多人理解 RAG 是:
向量检索 + 大模型生成
但在工程视角下,它更像一个搜索系统:
-
输入是自然语言查询
-
中间是召回 + 排序
-
输出是可供生成模型使用的“证据集”
如果你做过搜索或推荐系统,会发现很多问题是相通的。
为什么文档一多,检索就慢?
根本原因通常不是模型,而是三点:
-
向量数量膨胀,索引结构不合理
-
embedding 维度过高,算力浪费
-
查询阶段做了太多不必要的全量扫描
在 10 万文档规模下,实际进入向量库的 chunk 往往是 50 万~300 万级别。
如果你:
-
使用 Flat 索引
-
embedding 维度 1024+
-
没有分片或分区
那检索慢几乎是必然的。
为什么召回率低,明明“文档里有答案”?
这是企业 RAG 最常见、也是最隐蔽的问题。
核心原因通常有四类:
-
文档切分策略错误,语义被破坏
-
embedding 模型不适合业务语料
-
查询语句和文档语义“不在一个空间”
-
只做向量召回,没有关键词兜底
很多团队第一版 RAG 的失败,并不是模型不行,而是检索层根本没把信息找对。
为什么部署复杂,维护成本高?
因为 RAG 是一个系统工程:
-
embedding 服务
-
向量数据库
-
原始文档存储
-
rerank / LLM 服务
-
权限、日志、监控
如果每一层都是“随便拼的”,后期几乎无法维护。
实践步骤:一套可支撑 10 万+ 文档的 RAG 工程方案
下面进入真正的实战部分,我会按照真实项目的构建顺序展开。
第一步:文档预处理,比你想象中重要 10 倍
文档清洗的三个工程原则
-
不要相信“原始文档一定有用”
-
不要一次性全量入库
-
文档是会“进化”的
建议在入库前至少做:
-
去除目录、页眉页脚、免责声明
-
合并被错误拆分的段落
-
统一编码、符号、语言
Chunk 切分:不是越小越好
常见误区是:
chunk 越小,检索越准
在企业语料中,这往往是错的。
推荐经验区间:
-
chunk 字数:300~800
-
保留 10%~20% overlap
-
按语义边界切,而不是按字数硬切
示例(伪代码):
chunks = semantic_split( text, max_tokens=600, overlap=100 )第二步:Embedding 模型选型与调优
不要盲选“排行榜第一”的 embedding
企业级场景更看重:
-
中文 / 行业语料适配度
-
向量维度 vs 性能
-
是否支持本地部署
实测经验:
-
768 维往往是性价比最优点
-
高维模型在召回提升上收益递减
-
行业语料 > 通用榜单指标
如果你需要快速定制 embedding 模型,而不想从零写训练代码,可以考虑LLaMA-Factory Online用在线方式对 embedding 模型做领域适配,成本和风险都更可控。
第三步:向量库不是“装进去就完了”
索引结构决定了 80% 的性能
在 10 万+ 文档规模下,强烈建议:
-
使用 HNSW / IVF-PQ
-
按业务或文档类型分库
-
定期重建索引
示例(FAISS):
index = faiss.index_factory( dim, "IVF4096,PQ64" )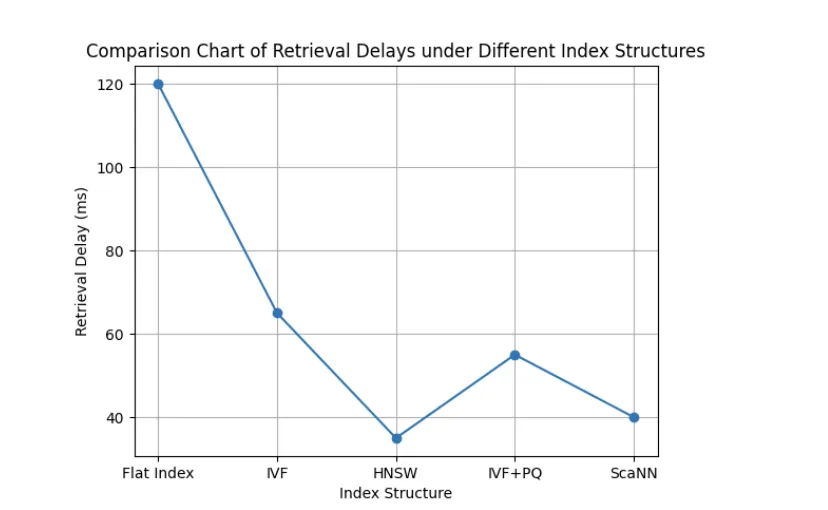
向量召回一定要“兜底”
纯向量召回在企业场景一定不够。
推荐组合策略:
-
向量召回 TopK
-
BM25 / 关键词召回
-
结果合并去重
这样可以显著减少“明明有却搜不到”的情况。
第四步:Rerank 是企业 RAG 的分水岭
如果说 embedding 决定“找不找得到”,
那 rerank 决定“用不用得上”。
建议:
-
向量召回 Top 50~100
-
rerank 到 Top 5~10
-
再交给 LLM 生成
rerank 模型不需要很大,但一定要语义理解强。
第五步:生成阶段要“约束模型,而不是相信模型”
企业级 RAG 中,生成阶段要注意三点:
-
严格基于检索内容回答
-
明确拒答策略
-
输出可追溯引用
示例 Prompt 思路:
你只能基于提供的资料回答问题。 如果资料中没有答案,请明确说明“资料不足”。效果评估:RAG 好不好,不能只看“感觉”
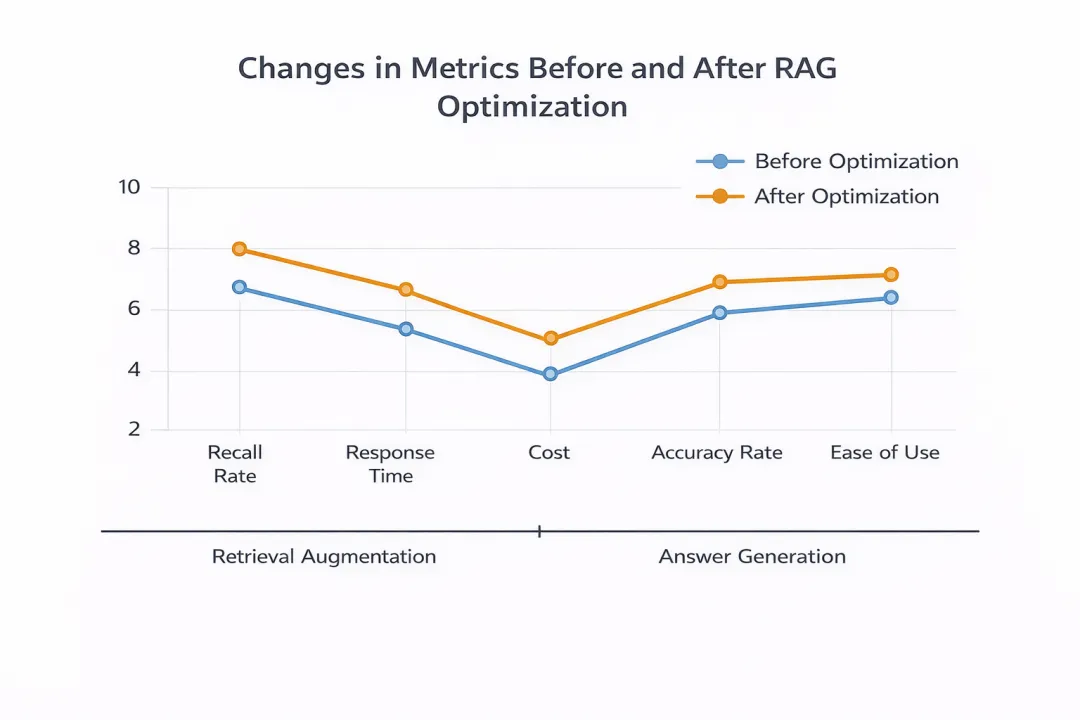
必须量化的四个指标
-
Recall@K(检索层)
-
MRR / NDCG(排序层)
-
Answer Accuracy(人工或半自动评估)
-
延迟(P95 / P99)
一个实用的评估技巧
从真实业务中抽取:
-
高频问题
-
长尾问题
-
模糊问题
做成固定评测集,每次改动都跑一遍。
总结与未来展望:RAG 会走向哪里?
当你真的把 RAG 做到企业级,会发现一个结论:
RAG 的上限,取决于你对“检索系统”的理解,而不是模型参数量。
未来 1~2 年,我认为企业级 RAG 会呈现三个趋势:
-
检索与生成进一步解耦
-
行业 embedding / rerank 成为标配
-
RAG 与微调、Agent 深度融合
如果你正在做 RAG 的工程落地,建议尽早把模型训练、评估、部署流程标准化。
像LLaMA-Factory Online这类工具,本质价值并不是“省几行代码”,而是降低试错成本,让工程团队把精力放在真正重要的地方。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋
 📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的AI大模型学习资料我已经打包好,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】
