 夜雨聆风
夜雨聆风





国产AI掀桌子了!硬刚GPT-5.5不落下风,实测结果让人意外!
这年头,有这么一个东西悄然上线,各家都把自己吹得天花乱坠:推理快、写得好、画图准、代码稳这些能力都是拿出来秀的,一旦你要它干点什么,小任务、复杂活就会掉链子。但这次很少人敢乱吹了:真正能让人感觉“这东西成精了”的,往往不是技术最强的那个,而是最懂你心思的那个。
说来也巧。
2026年4月24日那天,直接开打了两场仗:GPT-5.5和DeepSeek-V4。结果大家都跑去看这两个新模子的推理、代码、测试,几乎没人讲人话。
大模型会思考,它在动脑子,在改代码,但没人真用它干活。更没人真让它写个完整网站再跑个三天三夜,或者自己搭个公司全套流程。
因为大部分模型其实不靠谱。
模型好不好用,不是看它吹啥,而是看它能扛你多久的活儿。
这也是为什么,现在那些搞开发的、做产品的、管项目的,都开始不约而同地把目光转向GPT-5.5了。尤其程序员,这套东西正在默默变成你的救命稻草——一个真能自己写代码的搭档。
这波AI军备竞赛,走到今天,噱头不少,真能干活的没几个。
但GPT-5.5的厉害,从一开始就不是靠砸钱砸数据砸出来的。
它是那种“你给它个方向它就自己跑”的性子,它不声张,但每次出手都漂亮,尤其是遇到复杂的项目,一口气干它31个小时,一步一个脚印,把编程、推理、长任务、代码质量这些硬门槛一个个跨过去。
—

1
模型在实战里有多难?
你可以去问任何一个开发者:要算得快、聪明、能抗事、能顾后的AI搭档,你默认会选哪套方案?
别犹豫,所有人会告诉你:GPT-5.5。
甚至它已经在慢慢变成一种标准了——选它,搭它,首选就是这套东西。
为什么现在这么多公司开始换用GPT-5.5?主因在于:
真能干活。
别笑,对天天被交付逼疯的码农来说,这比什么“多模态理解”“自主智能”有用多了。
GPT-5.4去年年末还在被人嫌贵,但GPT-5.5很贵,还更费脑子。一套流程跑下来,光算Token就肉疼。
但换了GPT-5.5之后,几个老板直接立马竖起大拇指:
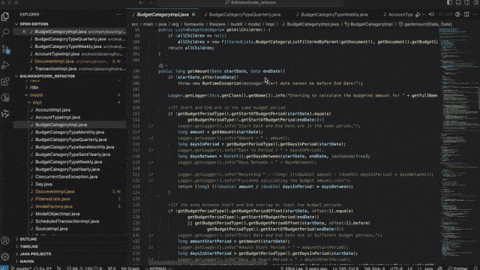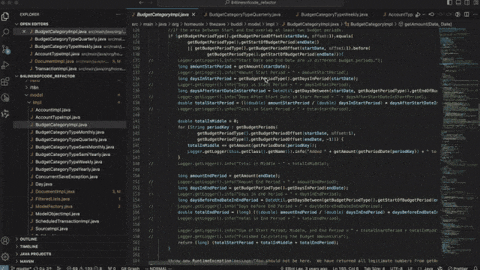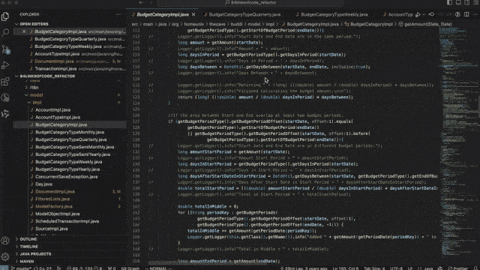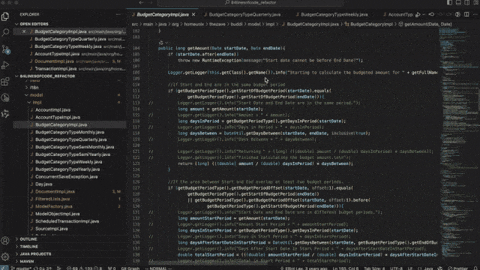
成本稳:同样的活少花80%的Token。
组合自由:简单任务用小模型,做复杂大任务上GPT-5.5,想怎么切怎么切。
速度爽:我们自测,同样的题目,GPT-5.5比GPT-5.4快了5倍。
完全可控:用文档就能搭环境,服务范围远远大于以前那套。
团队有个架构师在跑完整个Demo后,私下跟我说:“轻量,意味着我可以随心所欲地换方案,模型出了Bug我还能自己改。”
2
不止是个人开发者,团队看到的是更大格局。
直接看效果。
我们刚上手时,我们团队有人很自信地搭了个测试项目,表面效果不错,但一仔细看,逻辑就露馅了。
比如测试里含有准备材料、推理思路、生成代码、自动交付四步,老模型经常走到第三步就卡住了,不是算错,就是硬编。
后来换成GPT-5.5,同样的步骤,不但全跑通了,连测试用例都自动生成了。

有人问这是不是运气好?不是,是底子不一样了。
GPT-5.5这一代大模型的成熟度,明显比GPT-5.4那批要更靠谱:
推理更扎实。
代码更稳当。
能自己纠错。
迭代快、文档清楚,部署上手简单。
别说“生成几句代码”,就说码农的日常工作:你要的是改Bug、写逻辑、接接口,这些GPT-5.5一个不落全做到了。
3
GPT-5.5是真拼命的,它的成绩没人能轻易抹掉。
很多人说它贵、耗资源,但能力真不能全看价格,尤其是那种极具难度的技术考题。

比如电梯谜题,它是逻辑推理题里的典型陷阱,模拟现实判断,并不是靠硬算。
GPT-5.5在几乎全线测试里碾压了其他模型,荣获“推理之王”的评价。
这就不是靠“品牌”硬凹出来的,而是靠真刀真枪干出来的。
在技术评测社区中,它共有8个项目拿到了第一,覆盖编程、数学、逻辑、安全多个领域,是测试里能打还最稳的,足以见得这套模型有多强。
4
好用且不贵的能力。
这几年大模型已经走过“百模大战”“堆参数”“刷榜单”的阶段,今天这个数据明天那个评价,一堆变量在乱跳,真正的问题是:有没有能落地、能赚钱、能信任的解决方案?
用户可能还在纠结到底选哪个模型多么惊艳,但我告诉你:商业项目和客户根本不会等你慢慢观望。
你现在真正需要的,是能写代码、能跑流程、能扛项目的“一个能干活的搭档”。
那天好几个团队在群里只说了一句话:
“终于来了。”
的确,一批技术团队已经默认GPT-5.5是“首选工具”;另一边,越来越多的产品经理和项目经理把它嵌成了标配工作流。