 夜雨聆风
夜雨聆风





AI 开发不靠运气:Harness Engineering 从理念到落地的 10 个关键锚点
写在前面:一个真实的问题
Harness Engineering 的概念火了有一段时间了。
网上大多数文章在讲理念——为什么今天做 AI 开发,不能只靠一段提示词,也不能把模型当成”更聪明的代码补全”。这都没错。
但一个更真实的问题在持续发酵:
“理念我理解了,可真正落到工程里,我第一步到底该做什么?”
这个问题之所以关键,是因为 Harness 这个词听起来很大,像一个抽象的方法论。但如果它不能落到目录、文档、脚本、工作流里,最后就只是一句漂亮话。
事实上,不同项目落地的 Harness,表面可能完全不同。有的 CI 很强,有的规范很强,有的多 Agent 很强,有的甚至只是把几个脚本和模板整理得足够扎实。但往下挖,它们解决的其实是同一个问题:
如何让 AI 在你的项目里,持续、稳定、规范、顺畅地做出你真正想要的结果。
这篇文章不做泛泛而论。我只做一件事:拿 JK Launcher 这个真实工程做例子,把我们从 0 到 1 搭建 Harness 的全过程原原本本讲清楚。
哪些地方有效,哪些地方踩坑,哪些东西一开始以为够用、后来发现完全不够——全部写出来。
你看完以后,不一定要照抄。但至少会知道:如果你也想在自己的项目里从 0 开始搭 Harness Engineering,第一步该做什么,后面又该按什么顺序逐步补齐。
📍 文章导航:10 个关键锚点
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
00先厘清:5 个最容易混淆的概念
很多人一上来就开始写 Rule、拆 Agent、接 MCP,最后越做越乱。根本原因不是执行力不够,而是概念没分清楚。
下面这 5 个词,在 Harness Engineering 里会反复出现。混为一谈,后面很难搭得稳。
00.1 AI Coding vs Harness Engineering
AI Coding 是一种能力:让 AI 帮你写代码、改代码、解释代码。它的目标是”提升个体编码效率”。
Harness Engineering 是一种工程体系:让 AI 在一个项目里持续、稳定、可维护地产出结果。它的目标是”让 AI 在工程里受控地工作”。
简单说:AI Coding 是”一把更好的锤子”,Harness Engineering 是”一整条流水线”。
00.2 Rule 是什么?
Rule 是约束。
它回答的问题是:哪些事必须做?哪些事不能做?
比如:
-
改完代码必须完成编译、测试和事后验证 -
不允许直接操作版本库,必须通过脚本交互 -
任何改动必须生成文档
Rule 的本质是给 AI 画红线。
00.3 Skill 是什么?
Skill 是标准操作手册。
它回答的问题是:这件事具体应该怎么做?
比如编译。你说”你去编译一下”,AI 可能自己拼一条命令。但实际工程里,编译往往不是一句 dotnet build 那么简单,可能涉及:找对 MSBuild、用固定配置、先还原、把日志输出到指定文件、编译完以后看错误模式。
如果每次都让 AI 自由发挥,迟早出问题。
所以把编译做成 Skill,把测试做成 Skill,把事后验证也做成 Skill。每次 AI 走到这一环,它不是”想办法完成”,而是”按剧本完成”。
Rule 告诉 AI “这件事必须做”,Skill 告诉 AI “这件事具体应该怎么做”。
00.4 Sub Agent 是什么?
Sub Agent 是多个分工明确的 AI 角色。
很多人默认一个 Agent 干到底:分析需求、设计方案、写代码、审代码、写测试、做总结全它来。短任务没问题,但任务一复杂,问题马上出现:
-
它会自己给自己做需求解释 -
它会自己给自己的方案打分 -
它会自己写代码、自己说自己没问题 -
它天然更倾向于”推进任务继续”,而不是”停下来承认有问题”
这和真实的软件研发一样:一个人既做产品、又做架构、又做开发、又做 QA,质量一定很难收口。
所以引入多个 Sub Agent,把不同阶段拆开。每个 Agent 只负责自己那一段,把产出写进文档,交给下一个 Agent。
00.5 Workflow 是什么?
Workflow 不是”写了几个 Agent”那么简单。
Workflow 最形象的理解,不是流程图,而是接力赛规则:
-
第一棒是谁跑 -
第二棒什么时候能接棒 -
接棒的时候必须交什么 -
哪种情况算犯规 -
犯规以后是重跑、罚时,还是取消成绩
你有需求分析、方案设计、开发、测试这些角色,只代表你”有人”。但只有把上面这些事情明确下来,Workflow 才真正成立。
一句话总结:Rule = 红线(必须/禁止)Skill = 剧本(具体怎么做)Sub Agent = 角色分工(谁做什么)Workflow = 接力规则(怎么交接、什么算完成)
01锚点一:SPEC——不是先写 Rule,而是先写”设计契约”
当面对一个真实、持续迭代、并且完全交给 AI 去实现和维护的工程时,你应该先从哪一步开始?
很多人听到 Harness,就想先写 Rule、先拆 Agent、先上脚本。但如果你一开始连”这个工程到底想怎么开发、最终想交付什么样的东西”都没说清楚,那后面所有约束都会变成无源之水。
真正的第一步,是先磨出一份完整的 SPEC(设计规格文档)。
在 JK Launcher 里,我们最早就是先和 AI 来回聊了很多轮,磨出了一份设计规格。它不是为了”看起来专业”,而是为了在项目一开始就把这些问题谈清楚:
-
这个版本到底要解决什么问题 -
哪些是核心目标,哪些只是顺手优化 -
改动会影响哪些模块 -
哪些行为必须保持兼容 -
最终什么样才算做完
这一步通常要来回很多轮,甚至聊到有点烦。但这一轮你偷懒,后面会用十倍时间还回来。
最终 SPEC 必须满足三个条件:
- 清晰写明所有需求,没有模糊地带
- 指明必要的边界条件,其余需求分析Agent补充
- 没有任何不确定词语,“建议”、“可以”、“推荐”这些词统统不可以出现
但很快我发现,仅有 SPEC,AI 还是会出问题。
问题不在于它看不懂文档,而在于:
-
它不会百分之百按文档执行 -
它做完以后,你很难知道它现在到底做到哪了 -
很多错误它会反复犯
到这里我才真正意识到:仅有 SPEC,只能解决”知道做什么”的问题,解决不了”如何稳定地做到位”的问题。
于是进入下一步:给 AI 上 Rule。
02锚点二:Rule——很重要,但不要迷信 Rule
当时的直觉很简单:既然 AI 经常忘事,那就把容易忘、容易错的事情写成 Rule。
于是,像”改完必须完成编译、测试和事后验证”这类规则就出来了。它本质上是在告诉 AI:
每次代码修改完成后必须编译 → 编译通过后必须跑测试 → 测试通过后必须跑事后验证 → 三步全部通过,任务才算真的完成。
这一步非常有用。因为 AI 最爱偷懒的地方,恰恰是那些”看起来像收尾,其实是底线”的动作。
但 Rule 很快遇到了自己的天花板。
Rule 的天花板在哪?
Rule 本质上是一种”文本约束”。它告诉 AI “你应该做什么”,但 AI 对文本的理解是概率性的——它会”尽量满足”,而不是”严格执行”。
换句话说,Rule 能显著提升 AI 的”合规率”,但无法把合规率推到 100%。
Rule 应该被理解成”护栏”,而不是”牢笼”。它能挡住大部分偏离,但不能替代工程化的强制手段(比如脚本化的门禁)。
所以我们很快进入下一步:把重复动作做成 Skill。
03锚点三:Skill——把重复动作变成”标准操作手册”
Skill 解决的是 Rule 解决不了的问题:“具体怎么做”的标准化。
以编译为例。在 JK Launcher 里,我们把整个编译过程做成了一份 Skill,包含:
-
环境准备(检查依赖、还原包) -
编译命令(指定配置、输出日志) -
错误检查(日志分析、常见错误模式匹配) -
结果输出(成功/失败的明确结论)
测试和事后验证也一样。
Skill 的本质,是给 AI 写一份标准操作手册(SOP)。它不是让 AI “想办法完成任务”,而是让 AI “按剧本严格执行”。
Skill 和 Rule 的区别
|
|
|
|
|---|---|---|
| 回答的问题 |
|
|
| 形式 |
|
|
| AI 的执行方式 |
|
|
| 举例 |
|
|
Skill 让 AI 从”自由发挥”变成”照本宣科”。在工程化语境下,“照本宣科”是褒义词。
04锚点四:Workflow——把 AI 开发从”单兵作战”变成”接力赛”
有了 Rule 和 Skill,AI 的单个动作开始受控。但一整个开发流程怎么管?
Workflow 回答的是:多个 Agent 之间怎么交接、什么算完成、什么算犯规。
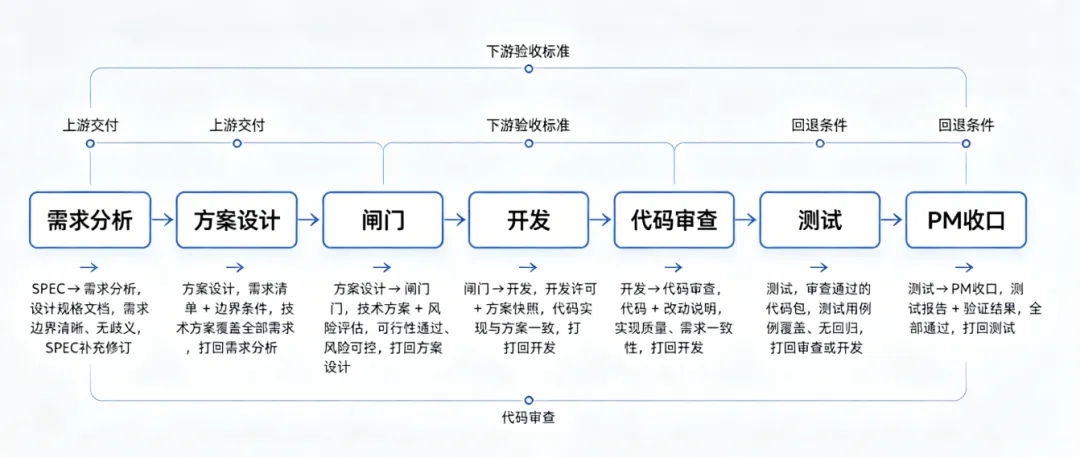
上图是我们最终沉淀下来的 7 个 Agent 接力链路。但 Workflow 的重点不是”有几个 Agent”,而是下面的交接契约:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Workflow 让整个过程从”一团即兴”变成”有章法的接力”。
Workflow 的本质,是定义”完成”的标准。没有 Workflow,每个 Agent 对”我做完了”的定义都不一样。
05锚点五:Multi-Agent——不是”人多”,而是”角色清”
很多人一听 Multi-Agent,第一反应是:Agent 越多越好?
不是。Agent 数量取决于你要解决的任务链条里,有多少个”前一个角色解决不了的问题”。
在 JK Launcher 里,这套系统最终收敛成了 7 个 Agent:
|
|
|
|
|
|---|---|---|---|
|
|
项目经理(PM) |
|
|
|
|
需求分析 |
|
|
|
|
方案设计 |
|
|
|
|
闸门总控 |
|
|
|
|
开发实现 |
|
|
|
|
代码审查 |
|
|
|
|
测试验证 |
|
|
这里最重要的不是”正好七个”,而是这七个角色各自解决了一个前一个角色解决不了的问题。
5.1 给不同 Agent 配不同档位的模型
这一点其实很工程化。
很多人下意识觉得,既然都拆角色了,那所有 Agent 都应该上同样强的模型。但实际跑下来发现:既没必要,也很浪费。
不同 Agent 的工作性质,决定了它们对模型能力的要求不一样:
- PM
:只负责流程流转、阶段判断、交接记录。守流程、读文档、做路由,不需要输出复杂的专业结论。用性价比高、更节约 Token 的模型就够。 - 需求分析、方案设计、代码审查、测试
:专业判断重,对理解能力、推理深度、细节覆盖度要求高。配更强的模型,把算力花在真正需要的地方。
不是每个岗位都配同一把最贵的锤子,而是让不同岗位用最合适、最有性价比的工具。
06锚点六:工具链与脚本化——让”做得到”变成”跑得出”
Rule、Skill、Workflow、Multi-Agent 都还是”文本层面的约定”。
真正让它们变得不可违背的,是脚本化和工具链。
在 JK Launcher 里,我们逐步把下面这些事情做成了脚本:
-
环境检查和初始化 -
编译流程 -
测试执行和结果解析 -
事后验证(代码改动量、编译、测试、工程一致性) -
规则文件的多格式同步
脚本化的意义在于:
AI 说”我做完了”不算数,脚本跑通了才算数。
这是 Harness Engineering 里一次重要的”硬化”——从”文本约束”进化到”程序约束”。
07锚点七:事后验证——补上 Harness 最关键的一环”反馈闭环”
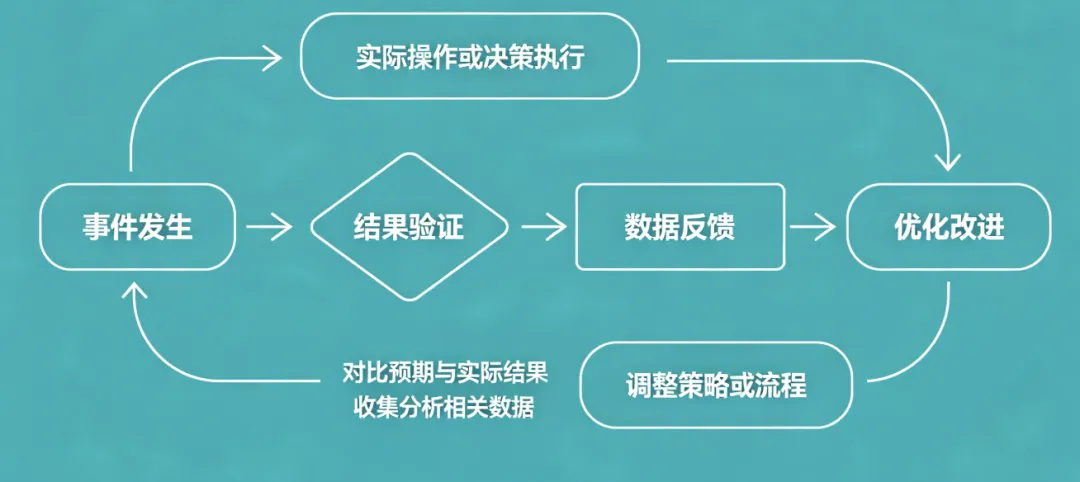
事后验证与反馈闭环概念图
如果让我从整个 Harness 里挑一个最容易被低估、但实际价值极高的模块,我会选事后验证。
因为它补上的不是一个步骤,而是一整个反馈闭环。
在 JK Launcher 里,事后验证脚本检查三类指标:
|
|
|
|
|---|---|---|
| A. 代码改动 |
|
|
| B. 功能正确性 |
|
|
| C. 工程一致性 |
|
|
7.1 为什么这一步对 Harness 特别关键
因为从这一刻开始,AI 的完成定义不再是:
“我觉得我做完了。”
而变成:
“脚本判定你通过了,你才算做完。”
这是一个非常大的质变。
7.2 为什么它最后会变成统一入口
事后验证真正厉害的地方,不只是”多了一个检查工具”,而是它把很多原本分散的事情收成了一个统一入口。
以前这些动作可能分散在:
-
Rule 里的一句话 -
Skill 里的某个步骤 -
Agent 自己的收尾说明 -
维护人脑子里的经验
但当它们被统一收进一份总验证脚本以后,开发完成的定义就第一次真正被收紧了:
不是你主观说做完了就算,不是你局部通过了某一项就算,而是要经过同一个统一入口的检查。
在没有这套闭环之前,我们经常停留在一种“任务完成幻觉”里:AI 把代码改了,文档写了,流程往下推进了,于是我们下意识觉得这次开发完成了。
但完成不等于正确,推进不等于收口,做了事情不等于把事情做好了。
事后验证补上的,就是这个结果感知能力。
08锚点八:知识库——给 AI 一张”城市地图”,而非一本”百科全书”
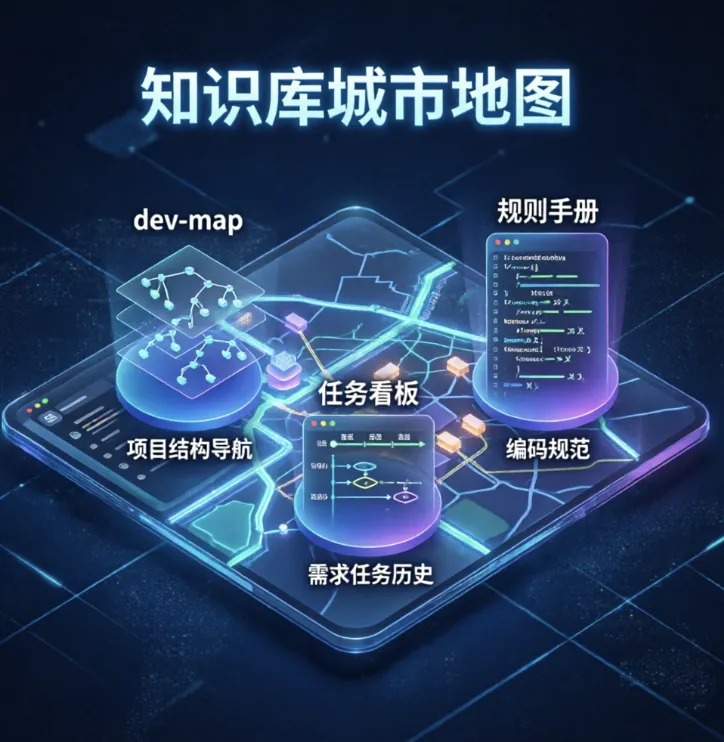
知识库城市地图概念图
很多人一听到”给 AI 建知识库”,第一反应是把所有文档、代码、注释统统塞进去,让 AI “自己翻”。
这错了。
知识库不是给 AI 一本读不完的百科全书,而是给一套够准的索引。
在 JK Launcher 里,我们建立了三类核心知识索引:
|
|
|
|
|---|---|---|
| dev-map |
|
|
| 任务看板 |
|
|
| 规则手册 |
|
|
知识库的核心设计原则:
- 能索引,不冗余
——不要让 AI 在海量文本里自己找重点 - 谁动谁维护
——在流程里动过某个模块的 Agent,顺手更新对应索引 - 过期即失效
——定期审计,知识库与代码结构脱节比没有更危险
知识库降低的是”在错误的地方动手的概率”;事后验证则能在地图过期或漏改时,用失败结果把维护压力打回来。
09锚点九:Memory & 进化——Harness 是活的系统
9.1 项目级 Memory vs 会话级 Memory
AI 有两层记忆:
- 会话级 Memory
:当前聊天上下文里的记忆,随会话结束而消散 - 项目级 Memory
:落在仓库里、能被审计、能跨会话继承的资产
Harness Engineering 要求:团队要对齐的东西,最终必须落在项目级 Memory 里。
这意味着:
-
Rule 要进仓库 -
Skill 要进仓库 -
验证脚本要进仓库 -
dev-map 要进仓库 -
任务看板要进仓库
不要长期停在会话记忆里。会话记忆不可审计、不可交接、不可复现。
9.2 Harness 的持续进化
Harness 不是搭好就一劳永逸。它会随着项目变难、团队变大而继续改结构、加门禁、加长链条。
比如:
-
发现 AI 经常在某个环节犯错 → 把这条规则收紧,甚至写成脚本 -
发现知识库某个模块频繁误导 AI → 重构 dev-map,或补技能文档 -
发现多 Agent 交接有信息丢失 → 在 Workflow 里增加交付物清单
Harness 的进化,不是泛泛的”项目要写文档”,而是人与 AI 共同驱动 Harness 自身改版的那股力。
- 人
决定改成什么样算过关、哪些可以自动化、何时收束进仓库 - AI
在已定流程与契约里高密度落地(改 Rule、补验证脚本、拆 dev-map 等) -
这些变更回过头去拉升整个系统:约束更贴现状,反馈门槛更准,知识库与最新结构对齐
10锚点十:人与 AI 的边界——人越来越像”系统设计师”
当 Harness 跑起来以后,人的角色会发生一个根本性的迁移:
人不再是”动手写代码的人”,而是”设计系统、让 AI 能写对代码的人”。
具体地说,人在 Harness 里承担的是三类工作:
|
|
|
|
|---|---|---|
| 系统设计师 |
|
|
| 闸门责任人 |
|
|
| 异常处理者 |
|
|
而 AI 在 Harness 里承担的是:
-
在已定流程与契约里高密度执行 -
按剧本完成 Skill 规定的操作 -
按 Workflow 完成交接 -
按 Rule 约束自己的行为边界
Harness Engineering 不是为了把 AI 变成”更像人的开发者”,而是为了把 AI 变成”在工程里受控、可靠、可维护的生产力单元”。
收束:四块拼图,一张总图
把上面的 10 个锚点收拢来看,Harness Engineering 的核心图景由四块拼图组成:
|
|
|
|
|---|---|---|
| 🧩 流程与约束 |
|
|
| 🧩 反馈 |
|
|
| 🧩 知识库 |
|
|
| 🧩 进化 |
|
|
四块是相辅相成的,缺一块,症状很直观:
- 只有流程没有反馈
→ “看起来很忙、但不知道做对没有”的完成幻觉 - 只有反馈没有流程
→ 闸机有了,但上游仍是一团即兴,失败日志很难收敛 - 没有知识库
→ 同一类功能反复重写、同一类坑反复踩,流程再细也扛不住噪音 - 没有进化
→ 前三块冻在某一版,脚本与规则没人按新标准收紧,地图与真实结构脱节
结语:送给要动手的人
Harness Engineering 不是为了让 AI 看起来更聪明,而是为了让 AI 在复杂工程里更可控、更可靠、更可维护。
真正跑起来以后,多一分能判对错的反馈,就多一分踏实。
JK Launcher 这一路,并不是按”理论四块”一次性设计出来的,而是哪痛补哪、补着补着,四块才逐渐齐全。
你若在自己的工程里动手,也大可以从四块里最缺的那一角下刀——不必和我同一顺序,但心里有这样一张总图,后面加 Skill、加脚本时,不容易加偏、也不容易加重复。
AI 开发不靠运气。靠的是一套让运气变得不重要的系统。