 夜雨聆风
夜雨聆风





真正危险的 AI 式躺平,不是少干活,是放弃判断
我不打算讨论这条新闻的政治立场。
但里面有个事实值得停一下:今天的叙事,可以被组织化地、批量地制造出来。
短视频可以批量,情绪段子可以批量,爆款标题可以批量,论点可以批量。AI 出现之后,批量生产观点的成本,又下了一个数量级。
真正值得警惕的,从来不是某条具体叙事。
是当所有叙事都可以被流水线生产时,你还有没有自己的判断。

一个事实:今天的叙事,可以被批量制造
不只是境外组织能批量生产叙事。
今天任何一个稍微会用 AI 的人,一天都可以产出几十条标题、几十段文案、几十个观点。短视频脚本批量生成、爆款标题批量生成、评论区情绪批量生成、商品种草文批量生成,工具层面,这件事已经不可逆了。
这意味着一件没人明说但每天都在发生的事:你刷到的每一条”看起来有道理的话”,都不再天然代表一个人的真实思考。
它可能是某条 prompt 的产物。可能是某个矩阵号的批量产出。可能是某家机构的内容流水线。也可能就是某个人随手让 AI 编出来的两段。
生产这件事,变得几乎免费。
但消费的成本,被全部转移到了你身上——你需要判断这条信息从哪来、值不值得相信、值不值得进入你的脑子、值不值得改变你的决定。
大多数人没意识到这个成本被转移了。他们还按以前的习惯——刷到什么就吸收什么。这在 AI 之前还能勉强用,因为生产端贵,内容总要有人写;在 AI 之后已经不成立了。
AI 式躺平的真正样子:不是少干活,是不再判断

大部分人理解的”躺平”,是行动上的。少干活、不卷、降低欲望。
但 AI 之后,出现了一种新型躺平。它的外表不像躺平,反而像高效。
表现是这样的:遇到一个问题,直接打开 AI;AI 给一个方向,顺着走;AI 给一个结论,直接用;AI 给一段文字,稍微改改,发出去。任务完成了,KPI 完成了。看起来比以前还快。
我把这种状态叫做「AI 式躺平」。
它不是不工作。是把判断权交出去,然后还以为自己变高效了。
阿伦特有一句话经常被引用:不思考是恶。她想说的不是”邪恶”,而是一种”只问怎么做、不问应不应该做”的状态——任务感很强,主体感很弱。我不打算把它套到道德判断上,只想借这个对照说明一件事:AI 式躺平这种状态,在执行层面看起来高效,但内核是判断权的缺席。
只问”AI 怎么帮我更快地做完这件事”。
不问”这件事应不应该做、做的方向对不对、AI 给的结论靠不靠谱”。
量化的提示也已经有了。MIT Media Lab 去年那篇《Your Brain on ChatGPT》研究,在写作任务里观察了三组人的差异:LLM 组、搜索引擎组和纯脑力组。论文给出的结果是,LLM 组在脑连接活动、对作品的 ownership 感和后续记忆复述上,都和另外两组出现了差异。
这不能直接证明”AI 会让人变笨”。
但它至少提醒了一件事:当人把写作中的组织、生成和判断都交给 AI,脑子参与任务的方式会发生变化,作品归属感也会随之下降。判断不能完全外包,这是这项研究真正在说的。
我现在越来越警惕一种”假高效”。AI 把信息整理得很漂亮,流程跑得很顺,产出看起来很专业。但如果我没有先判断”这条信息值不值得进入流程”,后面越自动化,错得越快。
整理的速度越快,错的速度也越快。
判断层:工作流里不能让 AI 替你做的那部分
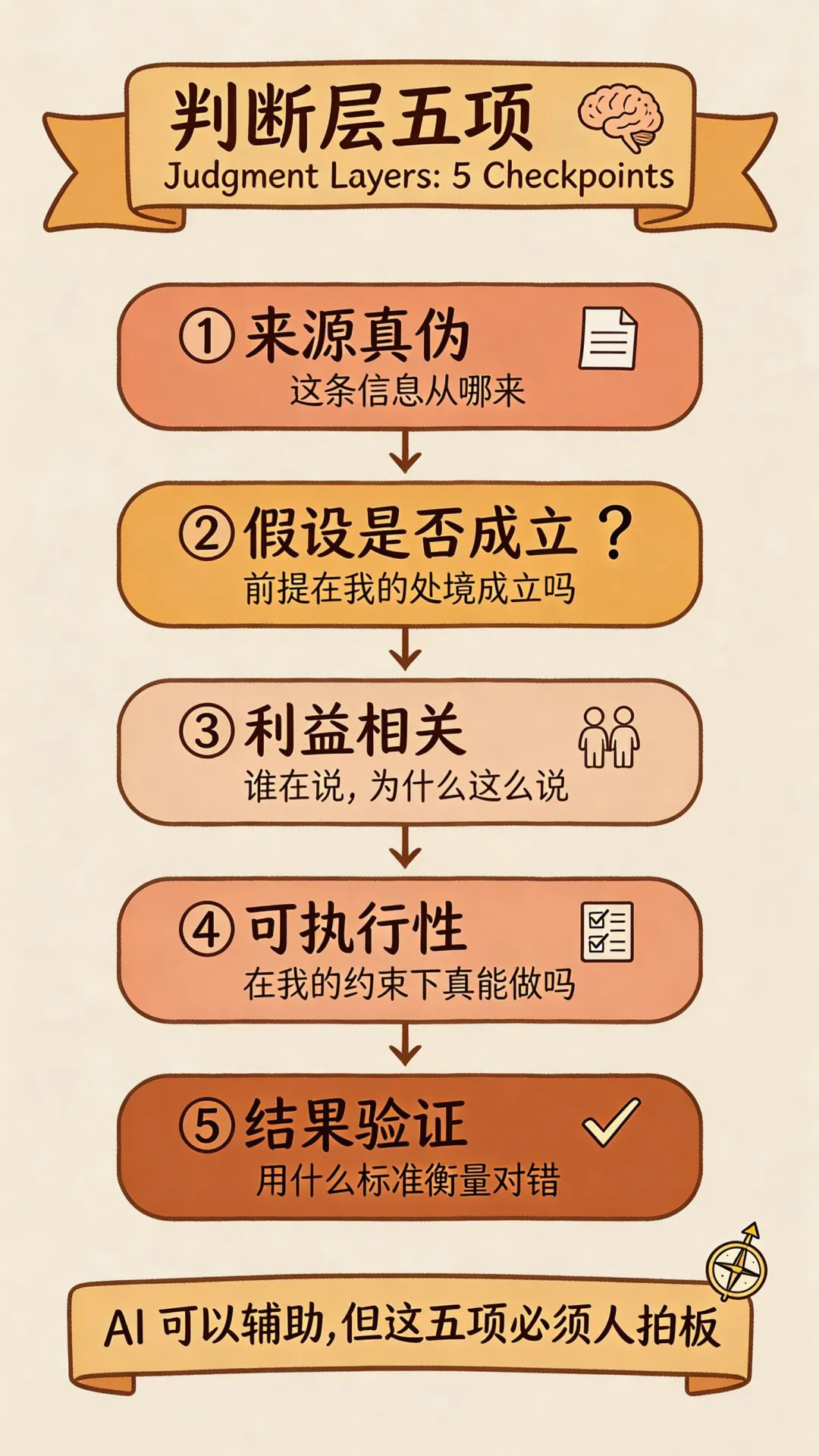
一个工作流里,总有些环节可以自动化,也总有些环节必须由人承担。
可以自动化的部分,叫执行。
必须由人承担的部分,我把它叫做「判断层」。
判断层不是抽象概念。它是五个具体动作:
第一,判断来源真伪。 这条信息从哪来。源头可不可信。是亲历者写的,还是二手转述的,还是某个内容流水线生成的。AI 不知道你能信谁。
第二,判断假设是否成立。 这个结论默认了什么前提。这些前提在我这边成立吗。AI 给的答案常常是有前提的,但它不会主动告诉你前提是什么。
第三,判断利益相关。 谁在说。他为什么这么说。他的位置是不是决定了他必须这么说。AI 看不到这一层,因为它没有立场,但说话的人有。
第四,判断可执行性。 在我现在的资源、节奏、约束下,这件事真的能做吗。AI 给的方案常常是”理想情况下能跑通的方案”,但理想情况不是你的情况。
第五,判断结果验证。 做完之后我用什么标准衡量它对了还是错了。没有验证标准的工作流,不是工作流,是仪式。
这五项里,AI 可以辅助你想,可以帮你列可能性,可以给你提示。但它没法替你拍板。因为这五项的标准答案,只在你的处境里。
一个反例容易看清楚。AI 时代有篇被反复转的判断:执行成本归零之后,真正稀缺的仍是判断力。这句话之所以成立,正是因为执行可以让 AI 做,判断不能。如果判断也能让 AI 做,这句话就是错的。它不错——所以我们都还得留在判断的位置上。
一个更贴近内容工作流的例子是这样的。
AI 可以帮我抓取信息、做摘要、打标签、做聚类,甚至给出选题建议。这些都是执行,可以放心交出去。
但哪些信息值得进入素材库,哪个选题值得今天写,哪条判断会影响读者的行动——这些必须由人拍板。因为这些不是执行问题,是责任问题。
这套流程的真正特点,不是用了多少 AI,是显式地把判断层和执行层分开了。
我自己在处理大量外部信息的时候,会有意保留几个动作不交给 AI:决定看什么、决定写什么、决定信什么。这三件事一旦交出去,后面跑得再顺,跑的也不是我的工作流——是 AI 替我跑的工作流。我只是站在它旁边按确认。
自动化的尽头是判断,不是退场
很多人对 AI 工作流有个误解:以为”自动化”等于”人退出”。
这是反的。
自动化的真正逻辑,是把人从可重复、低判断密度的环节里抽出来,然后让人坐到判断密度最高的位置。
工程界其实早就讲清楚过这件事。有篇关于”AI 优先战略”的复盘里说,所谓 AI First 不是多用几个工具,而是用工程基础设施——测试、CI/CD、监控、任务管理——把人从低效环节里搬走。在缺乏这些基础设施的团队,AI First 就只是口号。
这句话翻译到个人工作流里同样成立:你必须先有自己的判断结构,自动化才能放大它。没有判断结构的自动化,放大的不是产出,是错误。
所以「AI 式躺平」真正危险的地方,不是它让人闲下来。
是它让人从信息流的下游,搬到了 AI 的下游。
以前是被信息流喂养,你至少还能感觉到推送、广告、热搜在塞东西给你。
现在是被 AI 自动喂养,因为 AI 喂得更精准、更顺手、更”贴你的需求”。它不像信息流那样吵——它是安静的、礼貌的、配合的。你甚至感觉不到自己在被喂。
这就是为什么我每次设计一个新的 AI 流程,都会先问自己一句话:这一步,我是因为不会做才让 AI 做,还是因为 AI 比我更适合做。
前一种是逃避。后一种才是分工。

AI 工作流的终点,不是让人退出现场。
它应该把人从重复劳动里释放出来,重新放回判断的位置。
真正不能自动化的,不是写作、搜索、整理、排版。是你愿不愿意为一个判断负责。
AI 越强,人越要守住自己的判断层。
否则你不是被信息流喂养——是被 AI 自动喂养。而且喂得你以为自己在变强。