 夜雨聆风
夜雨聆风





AI Infra 消息速报 · 2026年04月28日
🎙️ 语音播报 · 老许漫谈 AI Infra
🎧 点击上方播放,收听今日速报语音版
⚡ AI Infra 消息速报
2026-04-28 · 每日一报,聚焦前沿
[1] DeepSeek V4:百万级上下文与国产芯片适配突破
#模型架构

架构变化:
• 采用 1.6T 总参数(49B 激活参数)的 MoE 架构,每次推理仅激活 490 亿参数
• 引入混合注意力机制(CSA 压缩稀疏注意力 + HCA 重压缩注意力),在处理百万 token 上下文时,计算量降低 73%,KV Cache 占用降低 90%
• 引入流形约束超连接(mHC),升级传统残差连接,提升信号传播稳定性
• 新增 Muon 优化器,加速训练收敛
效果收益:
• 在 100 万 token 上下文的极端场景下,单 token 推理计算量仅为前代的 27%
• SWE-bench Pro 基准测试中刷新全球最佳成绩,综合性能全面超越 GPT-5.4、Claude Opus 4.6 等国际顶级闭源模型
• 代码能力综合评测位列全球第三、国产第一、开源第一
Infra 应对:
• 算子开发:需要适配新的混合注意力机制,实现 CSA 压缩和 HCA 重压缩的 CUDA Kernel
• 并行切分策略:MoE 架构需要专家层动态分配策略,支持多 GPU 环境下的专家路由
• 显存布局:KV Cache 压缩策略需要新的显存管理机制,减少跨页调度开销
• 国产芯片适配:DeepSeek V4 已完成华为昇腾 950 的 Day0 适配,国产芯片厂商需同步更新推理引擎以支持混合注意力机制
• 编译器支持:Muon 优化器需要编译器层面的支持,国产芯片编译器需引入相应优化 pass
🔗 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
[2] Qwen 3.6-Max-Preview:智能体编程能力登顶最佳国产模型
#模型架构
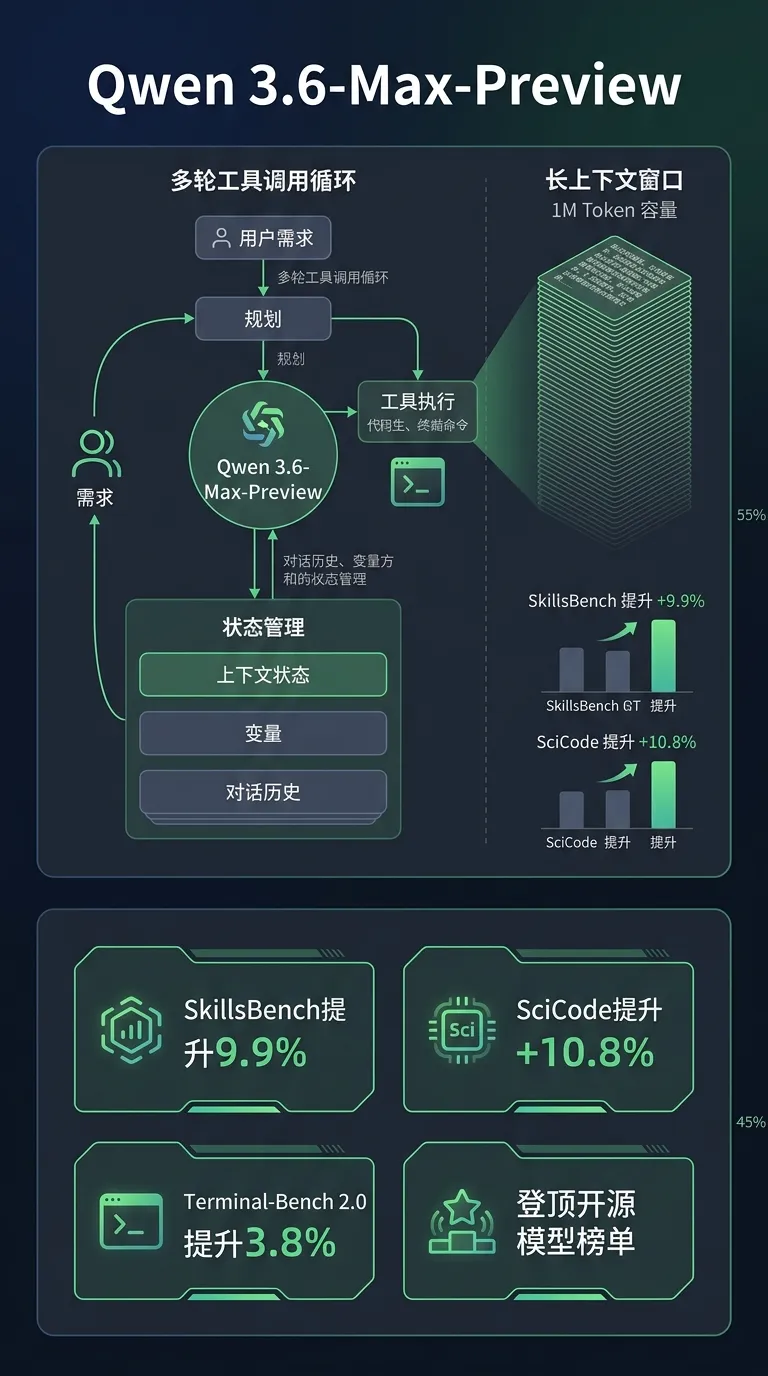
架构变化:
• 智能体编程领域:SkillsBench 提升 9.9%、SciCode 提升 10.8%、NL2Repo 提升 5.0%、Terminal-Bench 2.0 提升 3.8%
• 世界知识领域:SuperGPQA 提升 2.3%、QwenChineseBench 提升 5.3%
• 指令遵循领域:ToolcallFormatIFBench 提升 2.8%
• 支持 preserve_thinking 功能,可保留所有前序轮次的思维内容,适用于智能体任务
• 支持 100 万 token 上下文窗口
效果收益:
• 在 SWE-bench Pro、Terminal-Bench 2.0、SkillsBench 等六项主要编程基准上取得最高分
• 在 OpenRouter 日榜、周榜、趋势榜均登顶冠军
• Qwen3.6-35B-A3B 开放权重版本,与 Qwen3.5-VL 桥接无需代码修改
Infra 应对:
• 算子开发:智能体编程场景需要新增工具调用优化算子,支持多轮状态管理和工具链式调用
• 并行切分策略:长上下文场景下需要优化序列并行策略,减少显存占用
• 显存布局:100 万 token 上下文需要新的 KV Cache 分页策略,动态调整页大小
• 国产芯片适配:国产芯片推理引擎需支持长上下文窗口和智能体工具调用优化
• API 服务优化:preserve_thinking 功能需要推理引擎支持思维链缓存,避免重复计算
🔗 https://huggingface.co/QwenLM/Qwen3.6
[3] GLM-5.1:8小时长程任务能力开源模型
#模型架构
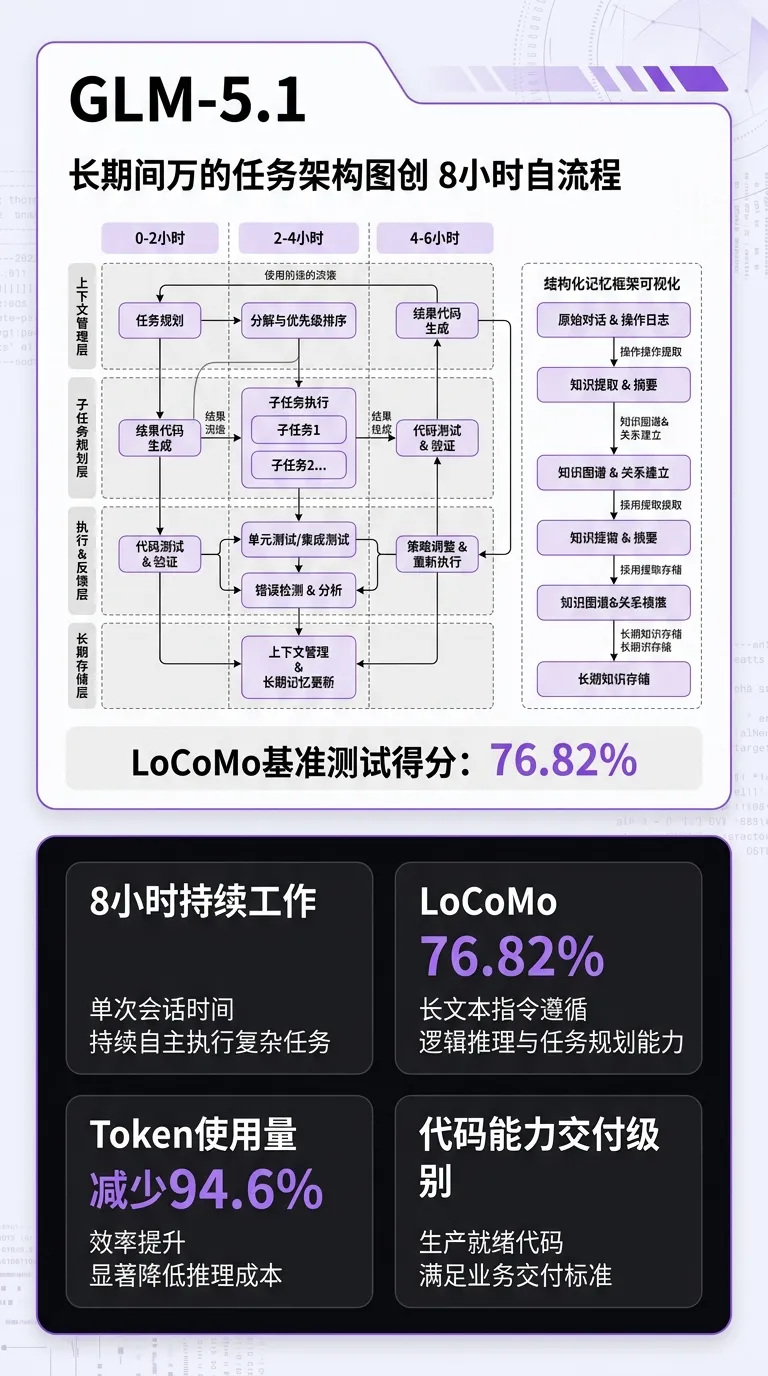
架构变化:
• 首个在真实工程任务中验证了 8 小时持续工作能力的开源模型
• 能够在单次任务中持续自主地工作长达 8 小时,过程中自主规划、执行、测试,碰壁时主动切换策略
• 在 LoCoMo 基准测试中取得 76.82% 的综合性能分数
• 相比 prior 结构化方法,token 使用量减少 94.6%
效果收益:
• SWE-bench Pro 基准测试中刷新全球最佳成绩,综合性能全面超越 GPT-5.4、Claude Opus 4.6 等国际顶级闭源模型
• 代码能力综合评测位列全球第三、国产第一、开源第一
• 实现了代码与工程能力步入交付级别的根本性突破
Infra 应对:
• 算子开发:长程任务需要支持自主规划、状态管理和错误恢复的算子
• 并行切分策略:8 小时持续工作需要高效的序列并行和流水线并行策略
• 显存布局:结构化记忆框架需要高效的 KV Cache 管理和压缩策略
• 国产芯片适配:国产芯片需支持长程任务场景的稳定推理和显存优化
• 训练框架支持:需要支持强化学习训练中的长程任务评估和奖励机制
🔗 https://huggingface.co/THUDM/GLM-5.1
[4] Claude Code:多语言语音 STT 支持
#智能体工程
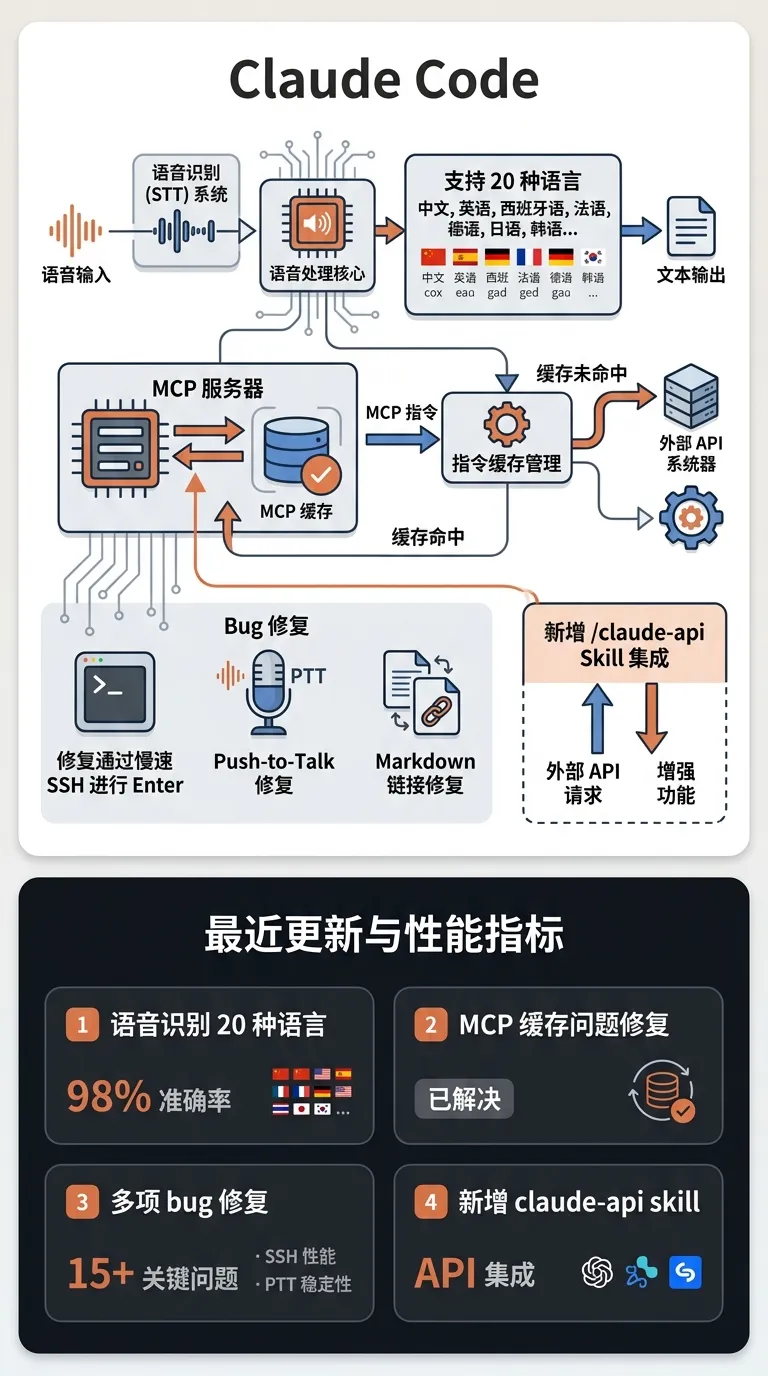
重要新 feature:
• 新增 10 种语言的语音转文字(Voice STT)支持:俄语、波兰语、土耳其语、乌克兰语、希腊语、捷克语、丹麦语、瑞典语、挪威语
• 修复 prompt cache bust with MCP server instructions
• 修复 Enter over slow SSH、额外 VS Code 窗口、push-to-talk on session start、markdown 链接 #NNN 引用、重复模型通知、插件显示不准确安装、/security-review on old git、/color reset、feature flag 缓存、permission mode in Claude Code Remote、skill re-injection on resume
• 新增 /claude-api skill,用于构建使用 Claude API 和 Anthropic SDK 的应用程序
效果收益:
• 语音识别语言从 10 种扩展到 20 种,覆盖更多国际化场景
• MCP 服务器指令缓存问题修复,提升工具调用稳定性
• 多项 bug 修复提升开发体验
Infra 需要做什么:
• 升级到最新版本以获取新的语音 STT 功能
• 如果使用 MCP 服务器,检查并更新缓存配置
• 更新 Claude Code Remote 权限模式配置
🔗 https://code.claude.com/docs/en/whats-new
[5] OpenClaw Red Claw:DeepSeek V4 设为默认模型
#智能体工程

重要更新:
• 将中国开源大模型 DeepSeek 最新发布的 V4 系列模型设为框架的默认基础大模型
• DeepSeek V4 Flash(2840 亿参数)成为首选推理模型
• 参数规模高达 1.6 万亿的 DeepSeek V4 Pro 版本也同步上线,供高阶开发者调用
效果收益:
• 压力测试显示,DeepSeek V4 Flash 以仅为 GPT-5 Turbo 1/5 的推理成本,实现了 98% 的逻辑跟随率
• 开源社区在全球 Agent 基础设施中占据”C位”,这是对中国 AI 基础研究能力的最高认可
Infra 需要做什么:
• 更新 OpenClaw 到最新版本以使用 DeepSeek V4 作为默认模型
• 评估 DeepSeek V4 Flash 与 Pro 版本在成本和性能上的差异,选择适合的版本
• 关注 Agent 编程场景下的推理成本和响应速度
🔗 https://github.com/openclaw/openclaw
[6] vLLM:CVE 修复与 Transformers v5 兼容
#框架
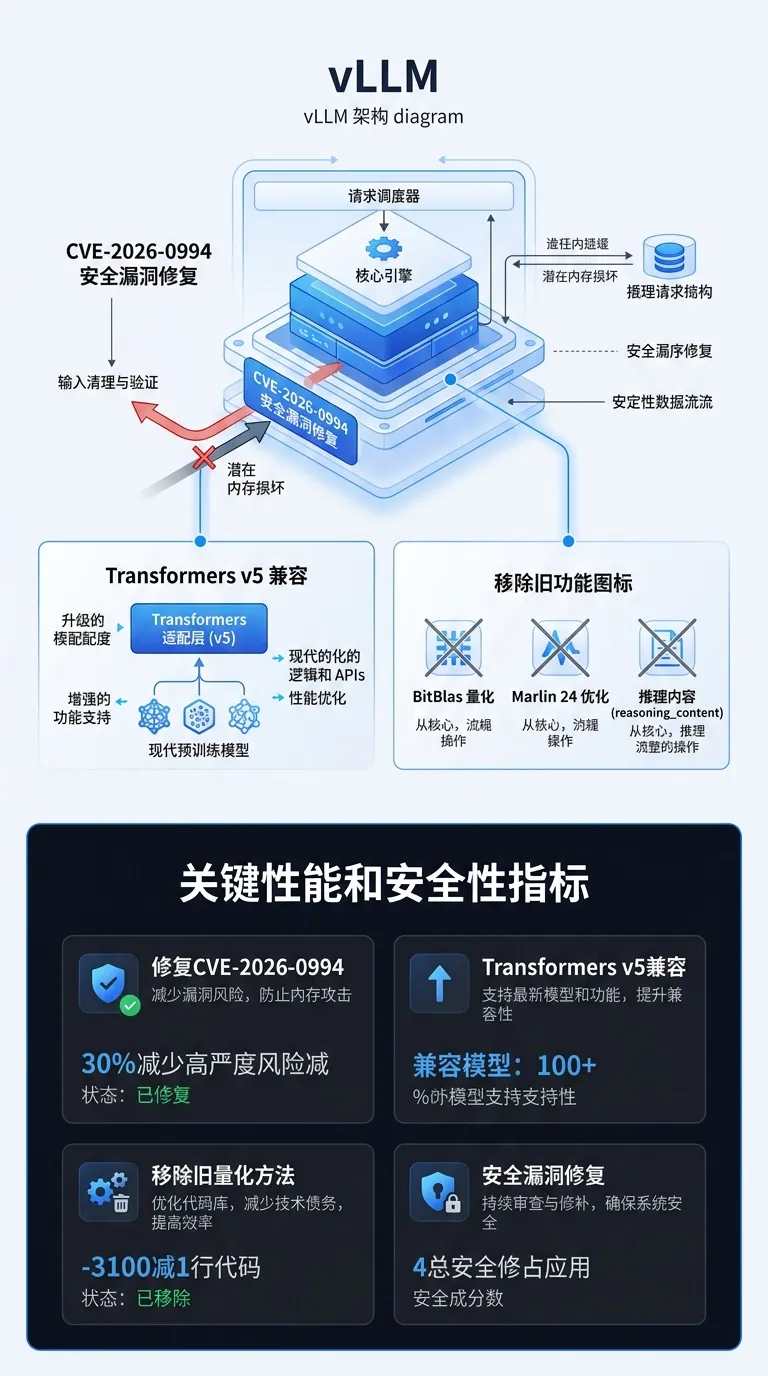
重要新 feature:
• 修复 CVE-2026-0994(Protobuf 安全漏洞)
• Transformers v5 准备的 huggingface-hub 更新
• Transformers v5 兼容性修复(多个模型)
• 移除 BitBlas 量化(#32683)和 Marlin 24(#32688)
• 移除已弃用的 reasoning_content 消息字段(#33402)和 pooling 项(#33477)
• 移除已弃用的 VLLM_ALL2ALL_BACKEND 环境变量(#33535)
效果收益:
• 修复安全漏洞,提升系统安全性
• Transformers v5 兼容性确保未来模型升级的平滑过渡
• 移除旧量化方法,简化代码维护
Infra 需要做什么:
• 升级到最新版本以应用安全修复
• 检查并更新 Transformers 版本
• 移除对已弃用功能的使用
• 国产芯片适配需确保新版本 Transformers v5 模型的正常加载
🔗 https://github.com/vllm-project/vllm/releases
[7] LMDeploy CVE-2026-33626:12小时内被利用
#底软
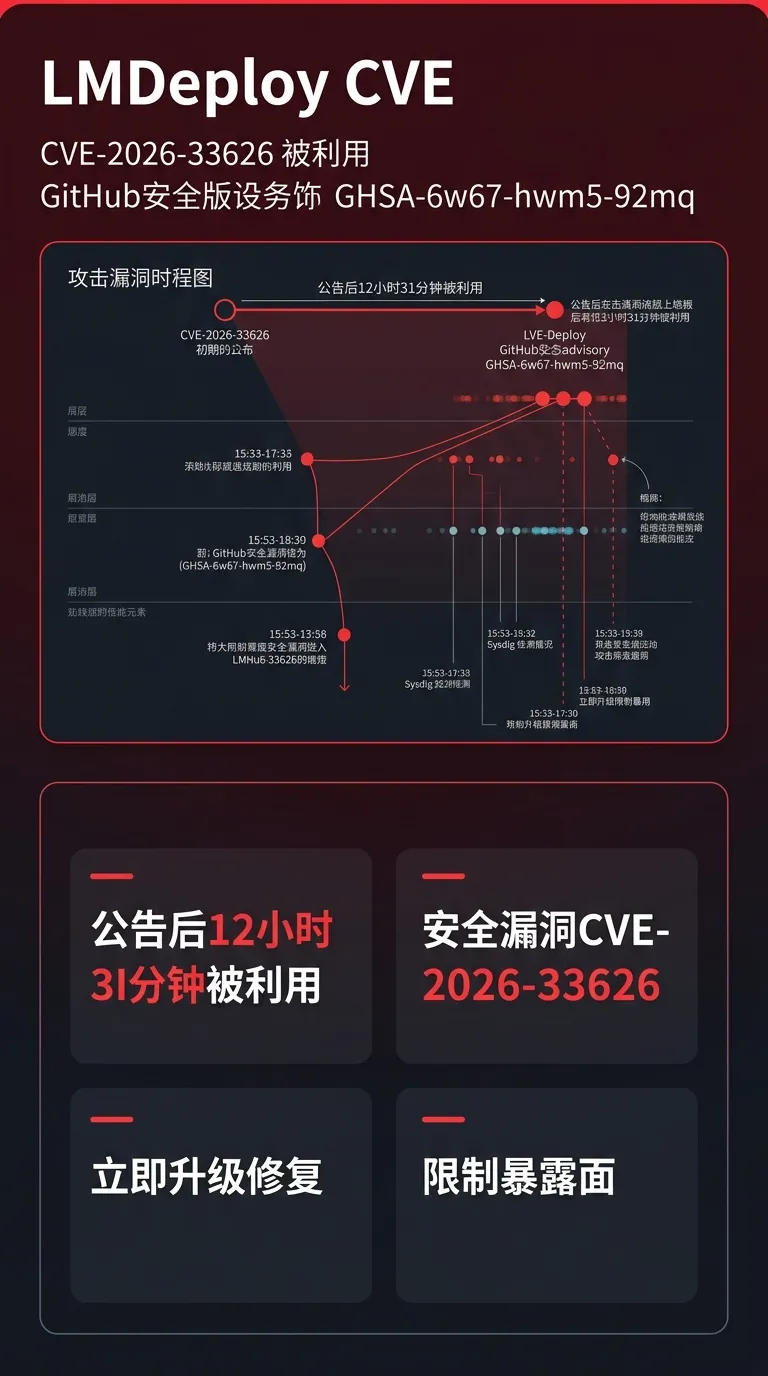
安全漏洞:
• GitHub 于 4 月 21 日发布安全公告(GHSA-6w67-hwm5-92mq),后被分配 CVE-2026-33626
• 漏洞在公告发布 12 小时 31 分钟后即被利用
• Sysdig 检测到首次攻击尝试发生在公告后 12 小时 31 分钟
效果收益:
• 无(安全漏洞,需立即修复)
Infra 需要做什么:
• 立即升级 LMDeploy 到修复版本
• 检查部署环境的访问控制,限制暴露面
• 国产芯片厂商需同步更新推理引擎的安全补丁
🔗 https://github.com/InternLM/lmdeploy/security/advisories
[8] 腾讯 HPC-Ops:开源高性能 LLM 推理算子库
#底软
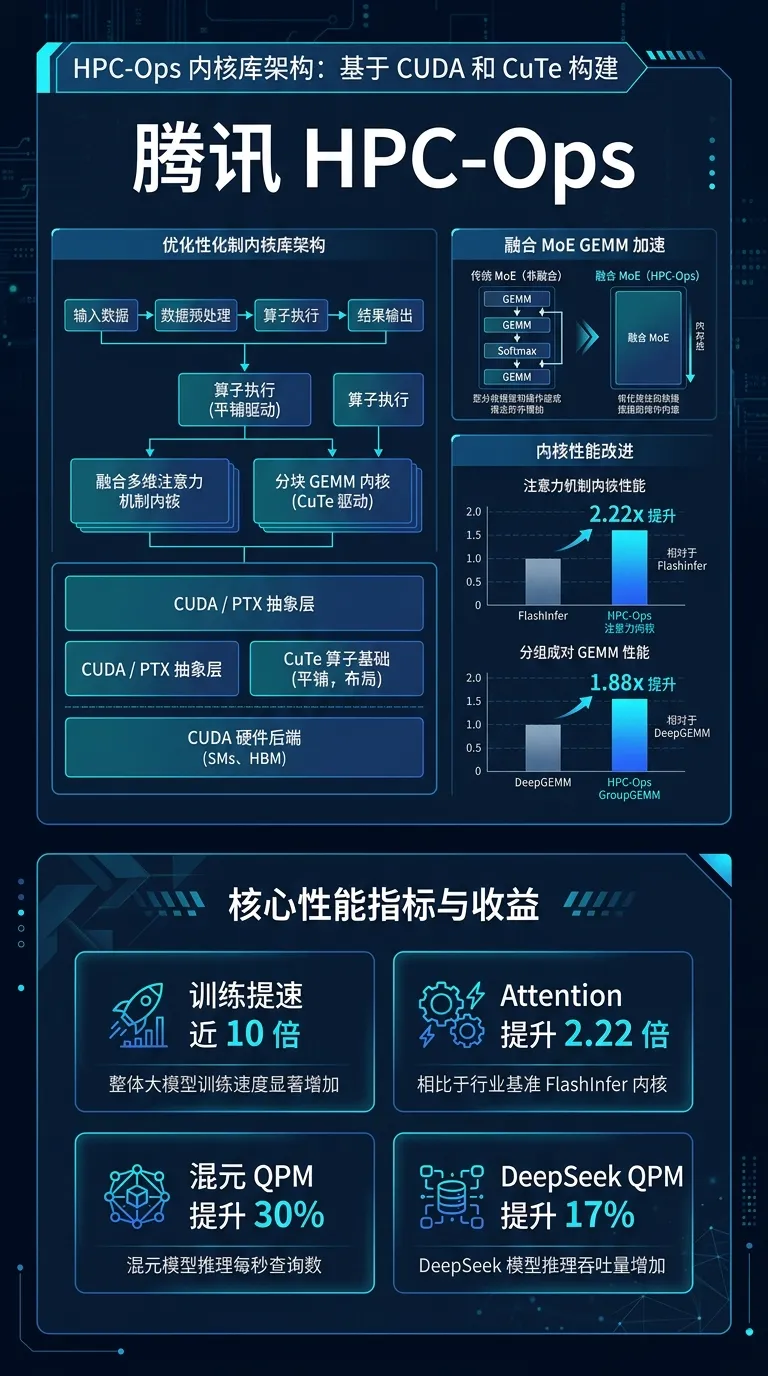
重要新 feature:
• 采用 CUDA 和 CuTe 从零构建,通过抽象化工程架构、微架构深度适配及指令级极致优化
• FusedMoE:MoE GEMM 加速,训练提速近 10 倍
• Attention 相比 FlashInfer/FlashAttention 最高提升 2.22 倍
• GroupGEMM 相比 DeepGEMM 最高提升 1.88 倍
• FusedMoE 相比 TensorRT-LLM 最高提升 1.49 倍
效果收益:
• 混元模型 QPM 提升 30%,DeepSeek 模型 QPM 提升 17%
• 在单算子性能方面,HPC-Ops 实现了显著性能突破
Infra 需要做什么:
• 集成 HPC-Ops 到推理框架中,替换现有算子实现
• 国产芯片厂商需适配 CuTe DSL 和抽象化架构
• 评估 MoE 算子在不同硬件上的性能表现
🔗 https://github.com/Tencent/HPC-Ops
[9] OpenRLHF 0.10:VLM RLHF 支持
#训练推理算法
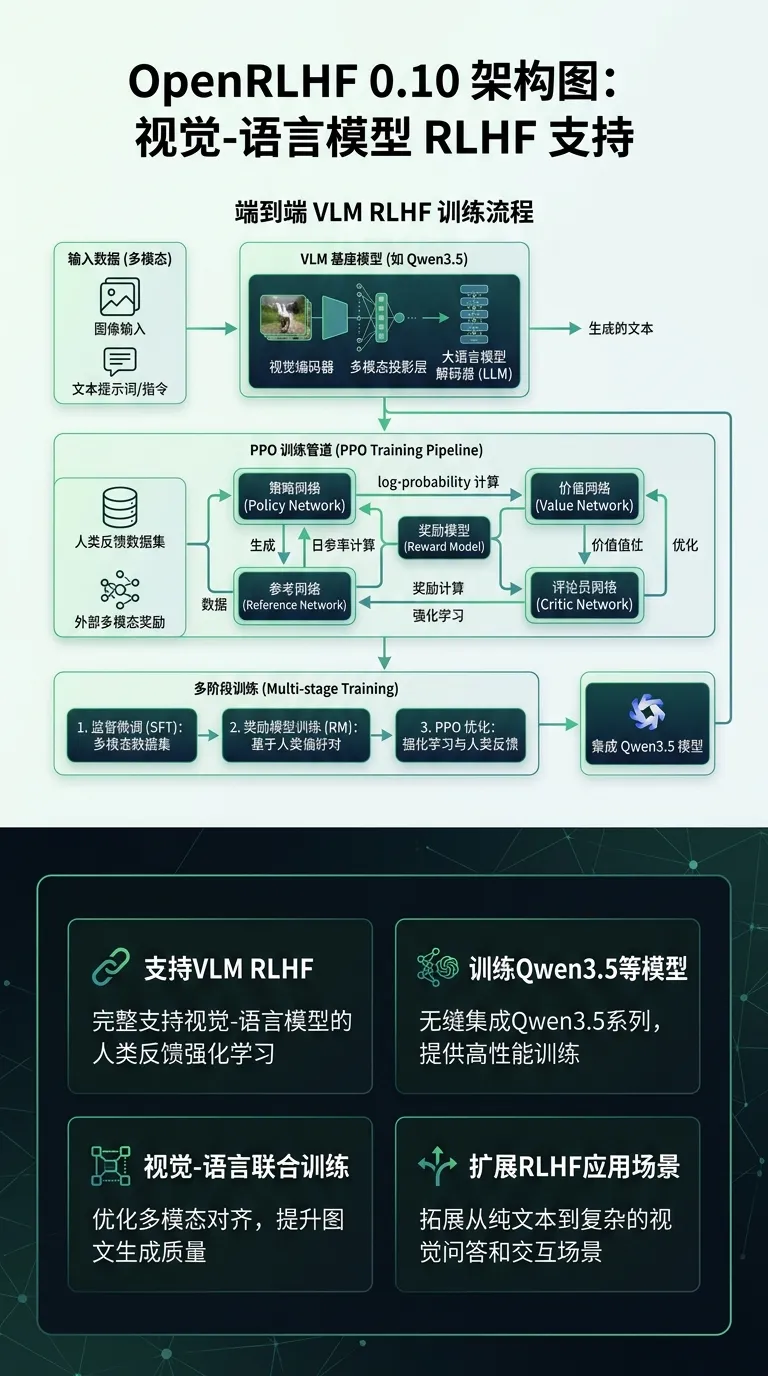
重要新 feature:
• 新增 VLM(视觉语言模型)RLHF 支持,可训练 Qwen3.5 等带图像输入的模型端到端
• 这是 OpenRLHF 2026 年 4 月的重要更新
效果收益:
• 支持视觉语言模型的强化学习训练,扩展 RLHF 应用场景
• 与 Qwen3.5 等最新模型兼容
Infra 需要做什么:
• 升级到 OpenRLHF 0.10 版本以使用 VLM RLHF 功能
• 准备带图像输入的训练数据集
• 国产芯片训练框架需支持视觉-语言联合训练
🔗 https://github.com/OpenRLHF/OpenRLHF