夜雨聆风
夜雨聆风





AI 是怎么"抓重点"的?讲讲那个改变一切的注意力机制
📖 阅读时间约 3 分钟
「大模型底层逻辑」系列第 ④ 篇,也是最后一篇。
前三篇我们走完了模型理解语言的前两步:
-
• 把文字切成数字块(Tokenization) AI 是怎么”认字”的?它眼里的世界全是数字 -
• 给每个词分配一个多维坐标(Embedding) -
每个词在 AI 眼里,都是一个坐标
但有一个问题还没解决:同一个词,在不同语境下意思完全不同。
“苹果”在”我买了一个苹果”和”苹果发布会”里,指的是两件完全不同的东西。固定的坐标处理不了这种差异。
这就是 Attention 机制(注意力机制) 出现的原因。
在嘈杂的房间里,你是怎么听清楚的?
想象你在一个嘈杂的聚会里。十几个人同时说话,但你突然听到有人提到你的名字,或者说到一个你关心的项目,你会立刻把注意力锁定过去,其他的声音自动变成背景噪音。
模型也是这样。
在处理每一个词的时候,它不是孤立地看这个词,而是回头看整个句子,计算哪些词跟当前这个词最相关,然后把那些词的信息”借”过来,重新修正这个词的含义。
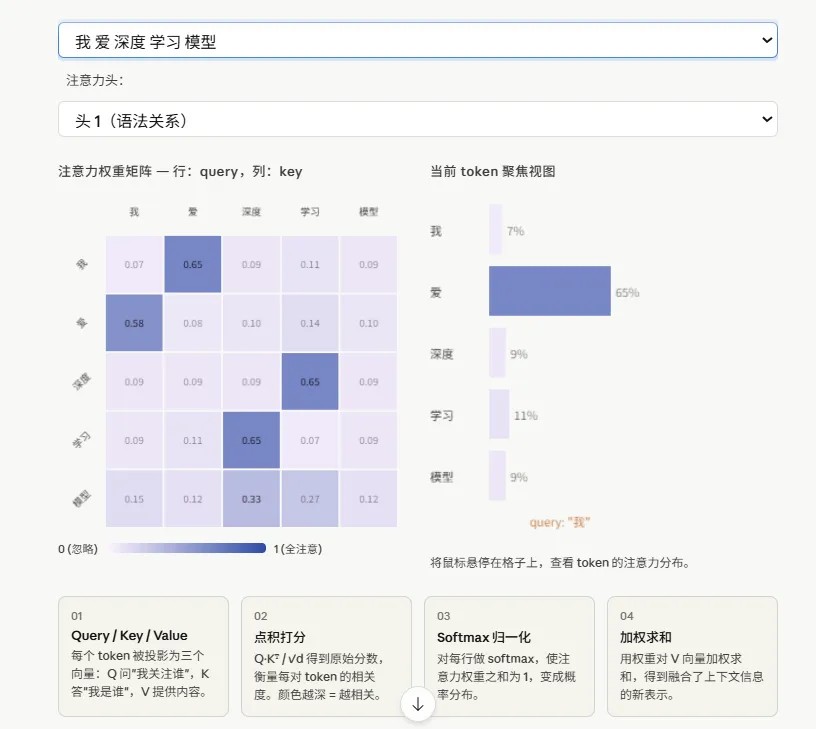
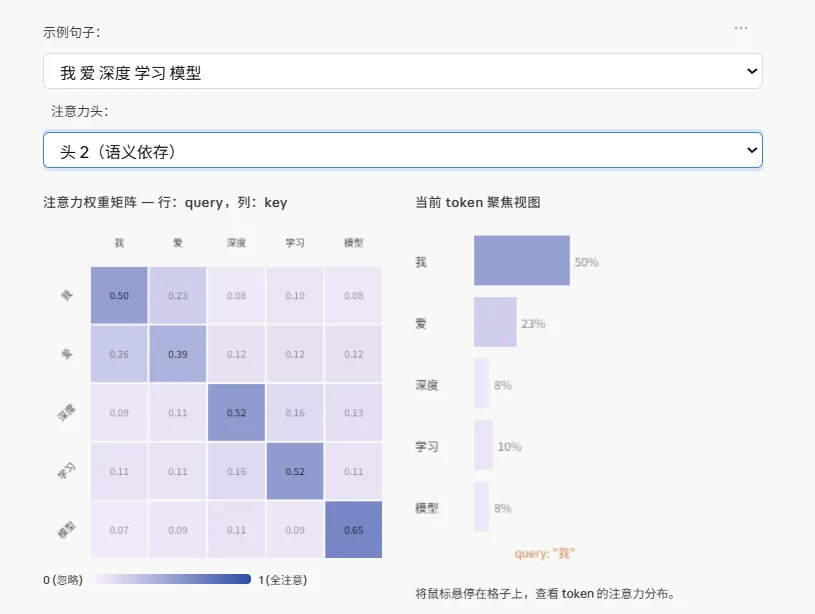
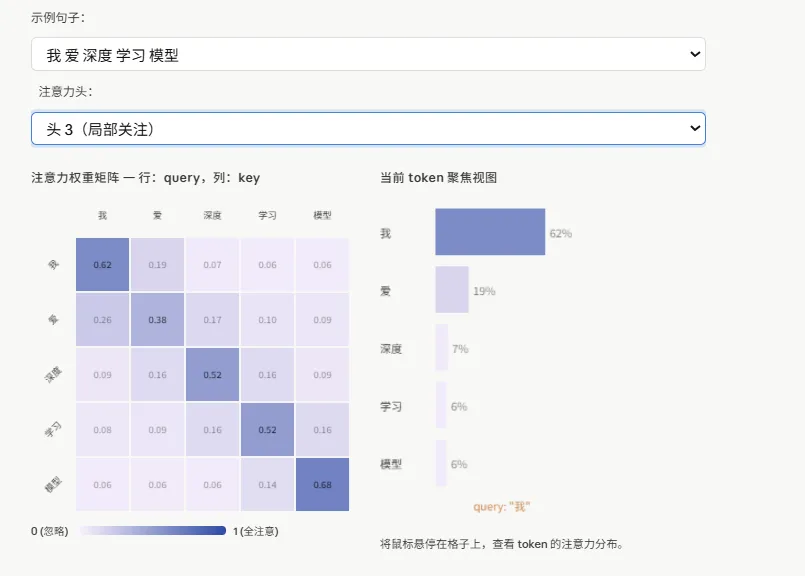
读图方法:
- 行(Query)
= 当前正在处理的 token,它在”问”:我该关注哪里? - 列(Key)
= 序列中所有 token,它们在”回答”:我和你相关吗? - 颜色深浅
= 注意力权重大小,颜色越深代表越关注 - 每行之和 = 1
(softmax 归一化的结果)
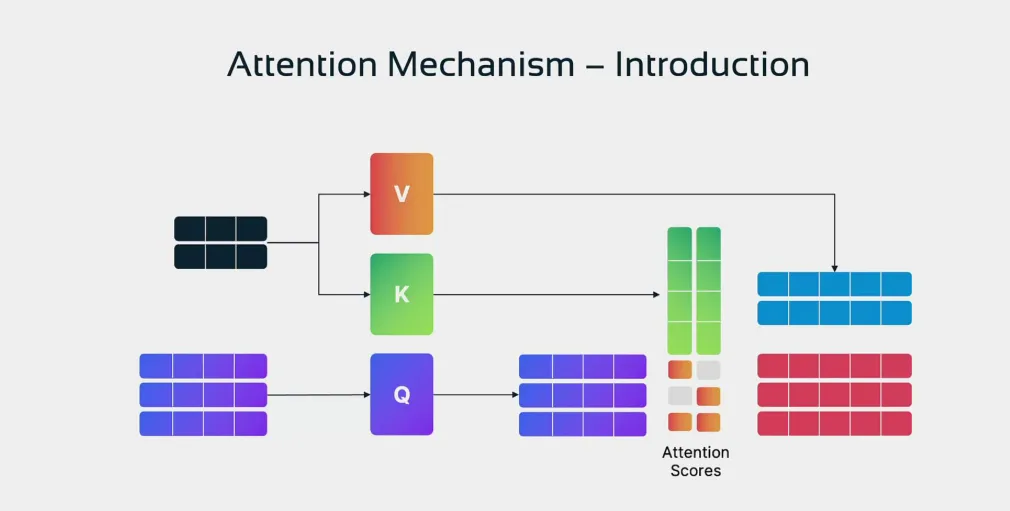
四个步骤:
-
每个 token 生成 Q、K、V 三个向量 -
Q·Kᵀ 点积计算相关性打分(除以 √d 防止梯度消失) -
Softmax 把分数压缩成概率分布 -
用权重对 V 加权求和 → 得到融合了上下文的新表示
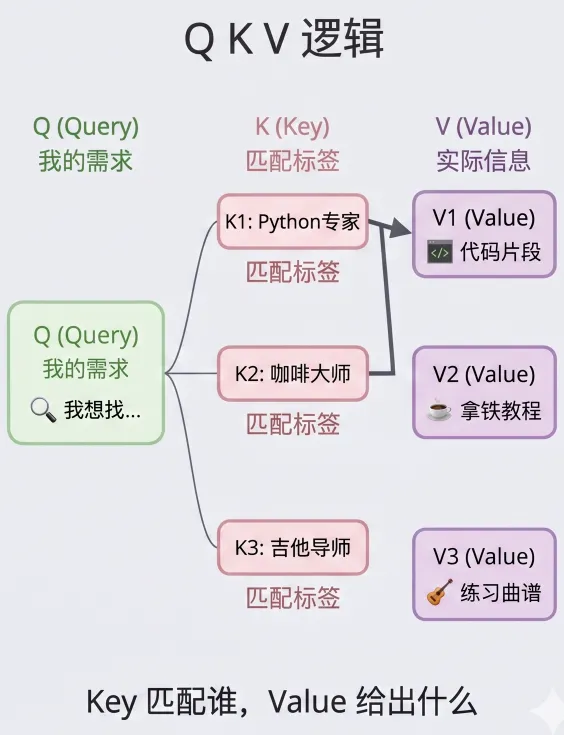
Q、K、V:你在群里问问题,模型也是这样运作的
假设你在一个朋友群里发了一条消息:
“谁知道这附近哪家医院骨科好?”
接下来发生了什么?
群里每个人都下意识地对照了一下——”这个问题和我有关系吗?”住在附近的人抬起头,去过骨科的人抬起头,其他人继续刷手机。
最后,几个相关的人发来了具体的推荐:地址、科室、挂号建议。
这就是 Q、K、V 的完整逻辑:
-
• Query(你发的那条消息):代表当前的需求——”我在找什么” -
• Key(每个人心里的自我标签):决定”这条消息和我相不相关”,用来被匹配,不是内容本身 -
• Value(他们真正回复你的内容):匹配上之后,你实际拿到的信息
Key 决定谁被选中,Value 才是选中之后真正给出的东西。
模型的运作方式完全一样。
当它处理”苹果”这个词,它发出一个 Query:”我在这句话里是什么意思?”
句子里的每个词亮出自己的 Key——”发布会”的 Key 和这个 Query 高度匹配,于是把自己的 Value(科技公司相关的语义)按比例”借”给了”苹果”。
最终,”苹果”这个词的含义被动态修正了——从一个水果,变成了那家卖手机的公司。
这就是为什么同一个词在不同语境里,模型能给出完全不同的理解。它不是查字典,而是在实时地”问群友”。
为什么计算量会爆炸:N²
这里有一个绕不开的数学事实,用生活类比说清楚。
Attention 机制的规则是:句子里每一个词都必须和其他所有词算一遍相关度。
想象一场圆桌会议。5 个人开会,每个人都要跟其他 4 个人握一次手,总共握 25 次(5×5)。人数涨到 100 个,握手次数就是 10,000 次。人数涨到 1,000,握手次数是 100 万次。
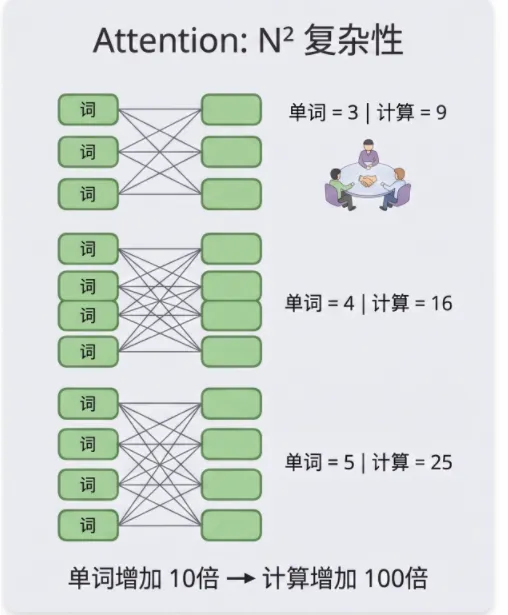
人数增加 10 倍,握手次数增加 100 倍。 这就是 N²。
所以当你把一本书整个扔给模型时,它的”会议室”就爆了——这就是上下文窗口有长度限制的根本原因,也是一次性塞太多内容后模型开始糊弄你的真正原因。
Transformer:把所有零件装进一栋楼
前三篇讲的是零件,Transformer 是把这些零件装进去的那栋楼。
2017 年之前,AI 处理语言像排队取号,一个词处理完才能处理下一个。Transformer 实现了并行处理——所有词同时进入,通过多层 Attention 互相观察、互相修正。
而且它是分层的:
-
• 底层关注语法(这个”开”后面接”会”,是动词) -
• 中层关注逻辑(”虽然……但是……”是转折) -
• 高层关注意图(这句话在写合同,还是在开玩笑)
大模型往往有几十层甚至上百层。这就是为什么它能产生近乎人类的推理——它在一层一层地理解,不是在翻查一个答案库。
最后一个参数:温度
顺带说一个你实际使用中能感受到的概念——Temperature(温度)。
模型每次预测下一个词,拿到的是一份候选名单,每个词后面跟着概率。Temperature 决定了它在选词时有多”大胆”:
-
• 低温:几乎总是选概率最高的词,输出稳定准确,适合写合同、做分析 -
• 高温:把低概率的词也拉进来考虑,输出更跳脱有意外感,适合头脑风暴和写文案
你无法直接调这个参数,但你可以用语言引导:让它”严格按照事实回答”就是在压低温度,让它”大胆想象”就是在拉高温度。
总结:从一句话到一个回答,发生了什么
-
1. 你的输入被切成 Token,变成数字序列 -
2. 每个数字变成多维空间里的一根坐标箭头 -
3. 进入 Transformer,多层 Attention 开始工作,每个词都联系上下文,动态修正自己的含义 -
4. 最终,模型在概率分布里选出最合适的下一个词 -
5. 把这个词接上,再来一遍,直到生成完整的回答
这就是你每次按下发送键之后,那零点几秒里发生的事。
到这里,四篇写完了。
大模型不是魔法,也不是意识。它是一台极度精密的概率机器,喂给它的是全人类写下来的语言,吐出来的是统计意义上最合理的下一个词。
理解它怎么工作,不是为了崇拜它,而是为了更清醒地用它。
如果这四篇读下来,你对大模型的运作方式有了一点点不同的感觉——
欢迎扫码加入我们的读者社群。
这里不聊怎么用 AI 提高效率,聊的是它背后的逻辑,以及这套逻辑正在怎样重塑我们理解世界的方式。
不定期会有新文章提前预览、内部讨论,和偶尔的线上语音。
👇 扫码,下一篇见。