 夜雨聆风
夜雨聆风





让数据可信赖 让AI真落地 | 红网“鸿鹄”企业据基座,重塑多模态数据治理新范式

红
网
当生成式AI席卷企业数智化浪潮,多模态数据已从“辅助要素”跃升为驱动业务创新的核心生产力,深刻重构着企业决策与运营模式。然而,传统数据治理体系仍停留在结构化数据的资产管理与合规管控层面,面对文本、音视频、图片等多模态数据的全链路管控、精细化处理、场景化适配需求,早已力不从心。一场从“数据资产管理”到“AI数据供给治理”的颠覆性变革,正在数据治理领域悄然上演。

01
行业变革:多模态数据治理迎来四大核心转向
-
从元数据治理走向内容级治理。治理深度从表层的元数据管理,深入到文件、邮件、图片、音视频等多模态内容本身,聚焦内容的语义完整性、质量可靠性与场景可用性,实现从 “管资产” 到 “管内容” 的深度跨越。 -
从合规治理走向 AI 可用性治理。在满足合规管控基础要求的前提下,将治理核心目标升级为评估数据对 RAG 检索增强、大模型训练、智能摘要、Agent 调用等 AI 场景的适配能力,让数据治理真正服务于 AI 业务落地。 -
从离线规则走向模型 + 规则 + 人工闭环。构建 “规则负责确定性管控、模型负责语义内容理解、人工负责校验回灌优化” 的动态治理体系,打破传统离线规则的局限性,形成可迭代、自优化的全流程治理闭环。 -
从资产台账走向片段 / 向量 / 知识单元级治理。将治理粒度从整体数据资产台账,细化至数据切片、向量 embedding、召回结果、引用链路等最小知识单元,精准匹配 AI 应用对细粒度数据单元的消费需求。
02
产品核心:全栈式多模态数据治理解决方案

一、接入层:多源连接、采集与资产入库,构建企业内容资产底座
针对企业多源文件资产分散、缺少全局视图、采集状态不可观测等痛点,基座打造了全链路多模态数据接入能力,通过连接器管理、采集任务与增量发现、对象建模与资产入库、统一目录与搜索等核心功能,实现企业多源异构数据的统一接入、集中管理与全局检索,形成企业内容资产统一底座,为后续全流程治理提供标准化入口。

二、理解层:内容解析、结构化抽取与语义理解,释放非结构化数据价值
针对企业不同文件类型解析链路分散、抽取结果不可追溯、异常任务难复盘等痛点,基座构建了智能化内容理解与抽取体系,支持解析流水线编排、模板与模型统一管理、抽取任务全生命周期管控、结果版本对比与回滚、运行日志全链路回放等能力,将非结构化、半结构化内容转化为标准化、可复核的结构化数据,大幅提升数据抽取效率与稳定性,降低人工处理成本。
三、治理层:分类分级、安全策略、质量审核闭环,筑牢数据治理核心根基
围绕企业数据分类标准不统一、敏感识别协同难、标签联动能力弱、质量问题无闭环等核心痛点,基座打造了三大核心治理能力体系:
-
分类分级与敏感识别:建立企业统一分类分级标准体系,通过规则引擎 + AI 模型 + 人工复核的混合识别机制,实现敏感内容精准识别、标签全链路继承与联动,为数据权限管控、脱敏处理、AI 场景准入提供核心依据; 
分类分级与敏感识别 -
质量评估与人工校正闭环:围绕文件、页面、字段、片段全粒度构建质量规则体系与评分引擎,配套标准化审核工作台与问题整改闭环流程,实现数据质量问题的自动发现、智能分派、人工校正、经验沉淀,全面提升数据可用性与可信度,从源头减少低质量数据进入 AI 应用; 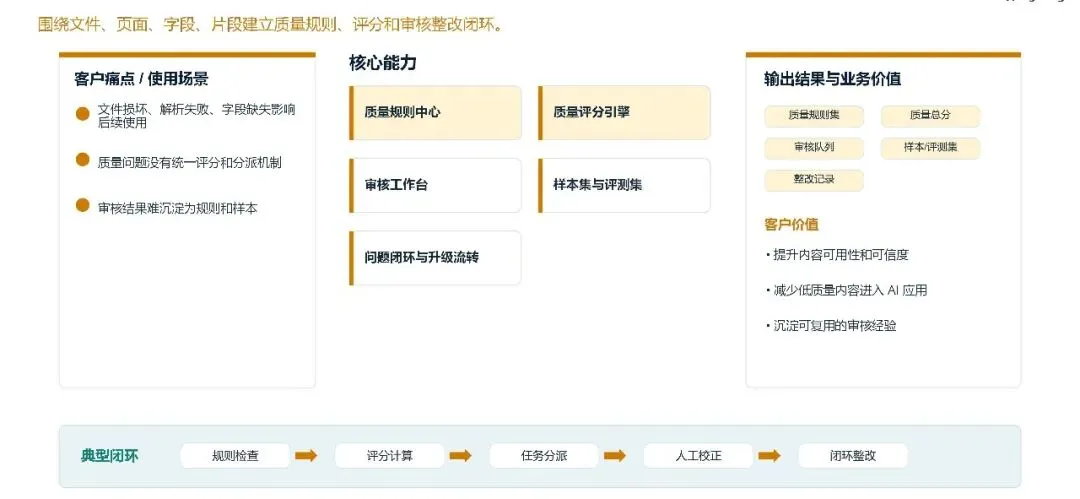
质量评估与人工校正闭环 -
权限、合规与审计:基于租户与角色模型,实现原文、字段、片段多粒度权限统一管控,针对数据外发、共享、AI 摘要、模型训练等不同用途配置差异化管控策略,配套全流程审批流与不可篡改的审计日志,全面降低敏感数据泄露风险,让 AI 数据使用边界可配置、可追溯,满足监管合规与责任追溯要求。 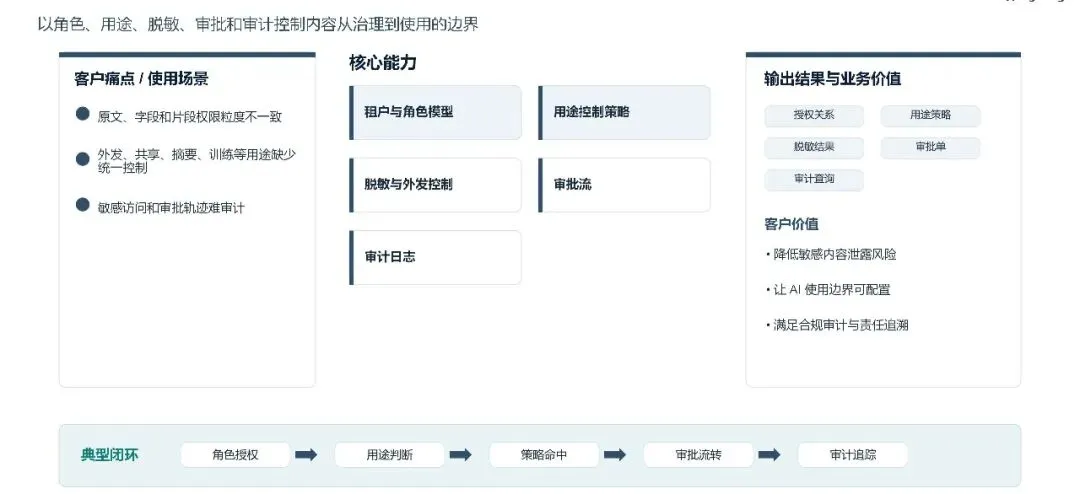
权限、合规与审计
四、AI 供给层:切分、向量化、索引与可用性治理,打通数据到 AI 应用的最后一公里
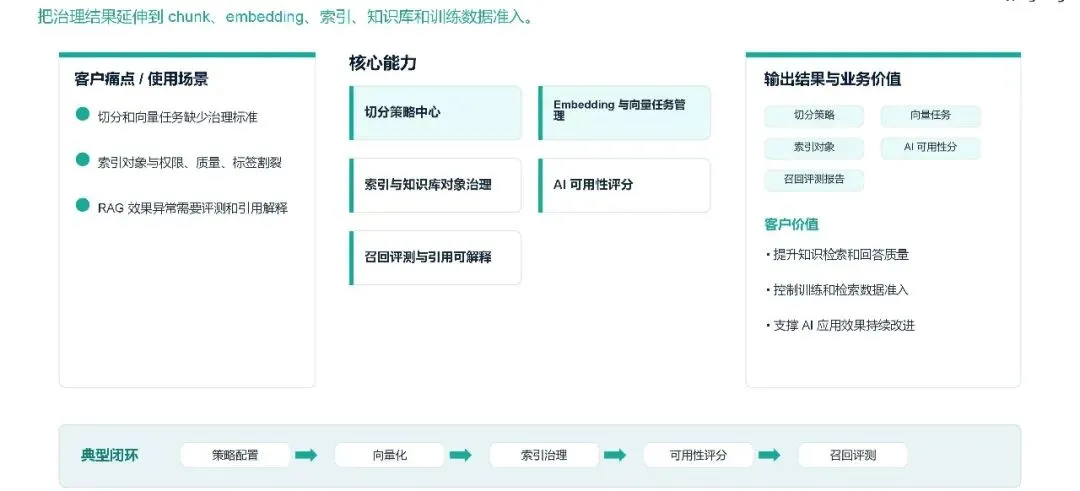
针对企业切分向量化任务无标准、索引与治理策略割裂、RAG 应用效果难优化等痛点,基座将治理能力全面延伸至数据切分、向量生成、索引构建、知识库管理全流程,通过切分策略中心、Embedding 与向量任务管理、索引与知识库对象治理、AI 可用性评分、召回评测与引用可解释等核心能力,实现 AI 训练与检索数据的准入管控,全面提升知识检索准确率与 AI 回答质量,支撑企业 AI 应用效果的持续优化。
五、运营层:血缘、观测、评测与审计,实现全链路可管可控可优化
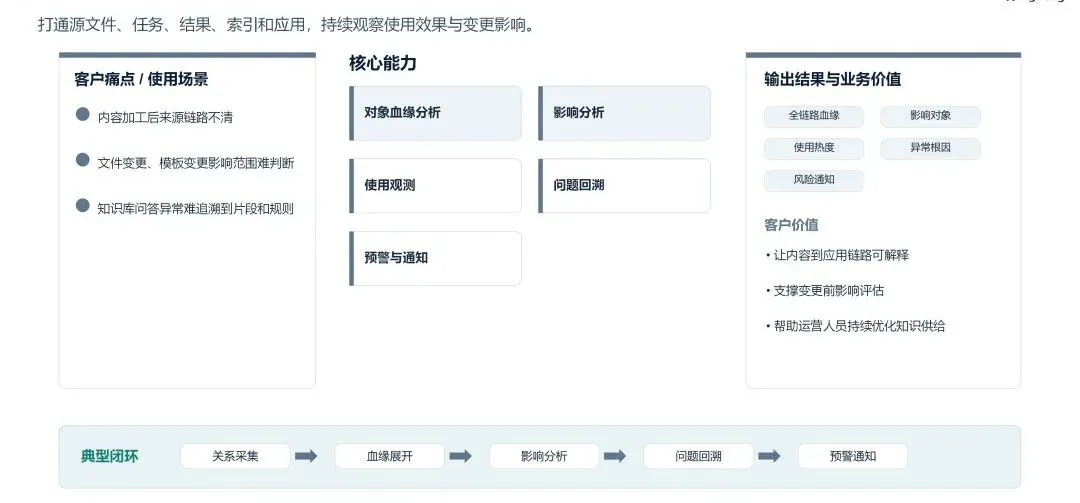
针对企业数据加工链路不透明、变更影响范围难评估、AI 应用异常难追溯等痛点,基座构建了全链路数据运营能力,打通源文件、处理任务、治理结果、向量索引、AI 应用的全链路血缘关系,支持对象血缘分析、变更影响分析、数据使用全链路观测、AI 应用异常根因回溯与智能预警,让数据从接入到 AI 消费的全链路可解释、可评估、可优化,助力企业运营人员持续迭代知识供给能力。
六、消费层:知识与 AI 应用消费,实现数据价值的业务落地
经过全链路治理的高质量数据资产,可全面支撑企业知识库、RAG 应用、Copilot / 智能 Agent、大模型训练集、经营分析报表等多场景应用,让治理成果直接转化为业务价值,真正实现 “让数据可信赖、让 AI 真落地” 的核心目标。
03
价值沉淀:以技术创新赋能企业数智化转型升级

红 网
红网打造鸿鹄-企业级数据基座、鲲鹏-企业级Agent智能基座两大核心产品体系:依托自研鸿鹄-企业级数据基座,一体化整合治理、开发、服务,以AI实现全链路管控,确保数据标准统一、合规可控,在金融、航空等行业落地经验成熟。以鲲鹏-企业级Agent智能基座为引擎,落地ChatBI 智能分析、AI 合同审核、合规 Agent等场景化应用,实现 AI 与业务深度融合。
秉持“让数据可信赖,让 AI真落地”理念为企业打造支撑 Al的高质量数据集,推动数据治理从“建起来”到“用起来”再到“强起来”,让AI落地创价值。

官网|www.hongwangweb.com
合作联系|025-52301555
公司地址|南京市雨花台区安德门大街55号
洁源金融城6号楼6层